算法常见
HASH 算法
我理解就是hash表数据结果中的hash函数用的那个东西 比如比如 MD5、SHA
哈希算法的定义和原理非常简单,基本上一句话就可以概括了。将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值。但是,要想设计一个优秀的哈希算法并不容易,总结了需要满足的几点要求:
从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法);
对输入数据非常敏感,哪怕原始数据只修改了一个 Bit,最后得到的哈希值也大不相同;
散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
哈希算法的应用非常非常多,主要安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储
跟分布式系统有关
负载均衡、那如何才能实现一个会话粘滞(session sticky)的负载均衡算法呢?也就是说,我们需要在同一个客户端上,在一次会话中的所有请求都路由到同一个服务器上。 1可以维护一个映射,但太麻烦 有很多弊端 ,我们可以通过哈希算法,对客户端 IP 地址或者会话 ID 计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。就跟散列表一样 比如一百个客户端 十台服务器, 小A客户端hash值算出来为13 。 13/10 取摸为3 但我服务器扩增呢 ,就是13/11 为2 就还是换机器了 需要用一致性哈希 需要划分范围//todo
数据分片、
分布式存储
递归
递归需要满足的三个条件
可以想想在电影院想知道自己在几排
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
或者上一个n级楼梯 可以迈一节或两节,总共有多少种走法
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}
1. 一个问题的解可以分解为几个子问题的解
2. 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
3. 存在递归终止条件
递归代码虽然简洁高效,但是,递归代码也有很多弊端。比如,堆栈溢出、重复计算、函数调用耗时多、空间复杂度高等,所以,在编写递归代码的时候,一定要控制好这些副作用。
排序

冒泡排序
// 冒泡排序,a表示数组,n表示数组大小 public void bubbleSort(int[] a, int n) { if (n <= 1) return; for (int i = 0; i < n; ++i) { // 提前退出冒泡循环的标志位 boolean flag = false; for (int j = 0; j < n - i - 1; ++j) { if (a[j] > a[j+1]) { // 交换 int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; flag = true; // 表示有数据交换 } } if (!flag) break; // 没有数据交换,提前退出 } }
插入排序
// 插入排序,a表示数组,n表示数组大小 public void insertionSort(int[] a, int n) { if (n <= 1) return; for (int i = 1; i < n; ++i) { int value = a[i]; int j = i - 1; // 查找插入的位置 for (; j >= 0; --j) { if (a[j] > value) { a[j+1] = a[j]; // 数据移动 } else { break; } } a[j+1] = value; // 插入数据 } }
从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个
这个只是我们非常理论的分析,为了实验,针对上面的冒泡排序和插入排序的 Java 代码,我写了一个性能对比测试程序,随机生成 10000 个数组,每个数组中包含 200 个数据,然后在我的机器上分别用冒泡和插入排序算法来排序,冒泡排序算法大约 700ms 才能执行完成,而插入排序只需要 100ms 左右就能搞定!
所以,虽然冒泡排序和插入排序在时间复杂度上是一样的,都是 O(n2),但是如果我们希望把性能优化做到极致,那肯定首选插入排序。插入排序的算法思路也有很大的优化空间,我们只是讲了最基础的一种。如果你对插入排序的优化感兴趣,可以自行学习一下希尔排序。
归并排序和快速排序
冒泡排序、插入排序、选择排序这三种排序算法,它们的时间复杂度都是 O(n2),比较高,适合小规模数据的排序。今天,我讲两种时间复杂度为 O(nlogn) 的排序算法,归并排序和快速排序
归并排序
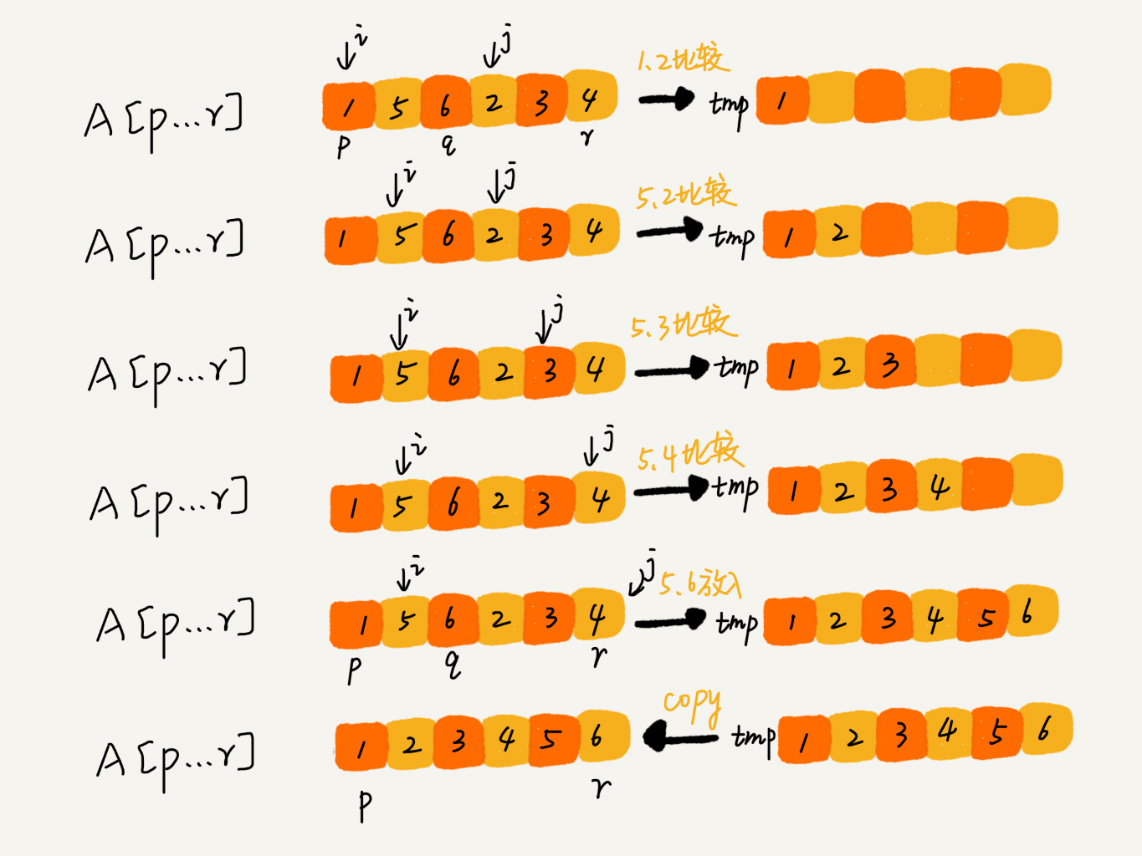
// 归并排序算法, A是数组,n表示数组大小 merge_sort(A, n) { merge_sort_c(A, 0, n-1) } // 递归调用函数 merge_sort_c(A, p, r) { // 递归终止条件 if p >= r then return // 取p到r之间的中间位置q q = (p+r) / 2 // 分治递归 merge_sort_c(A, p, q) merge_sort_c(A, q+1, r) // 将A[p...q]和A[q+1...r]合并为A[p...r] merge(A[p...r], A[p...q], A[q+1...r]) }
merge(A[p...r], A[p...q], A[q+1...r]) {
var i := p,j := q+1,k := 0 // 初始化变量i, j, k
var tmp := new array[0...r-p] // 申请一个大小跟A[p...r]一样的临时数组
while i<=q AND j<=r do {
if A[i] <= A[j] {
tmp[k++] = A[i++] // i++等于i:=i+1
} else {
tmp[k++] = A[j++]
}
}
// 判断哪个子数组中有剩余的数据
var start := i,end := q
if j<=r then start := j, end:=r
// 将剩余的数据拷贝到临时数组tmp
while start <= end do {
tmp[k++] = A[start++]
}
// 将tmp中的数组拷贝回A[p...r]
for i:=0 to r-p do {
A[p+i] = tmp[i]
}
}
快速排序
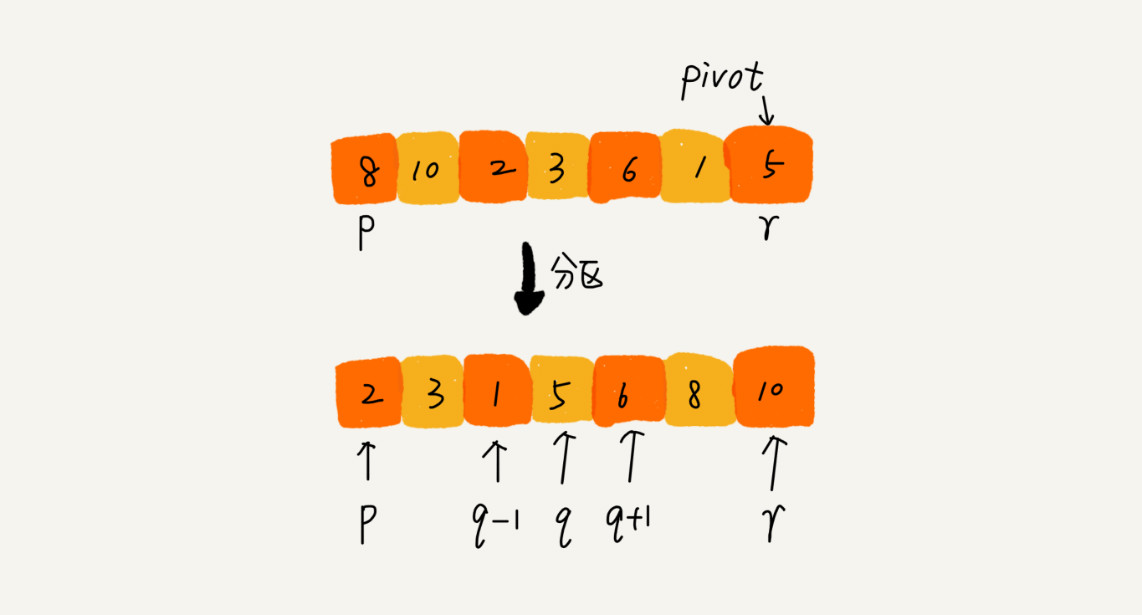

可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
桶排序、计数排序、基数排序
主要原因是,这三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
3 种线性时间复杂度的排序算法,有桶排序、计数排序、基数排序。它们对要排序的数据都有比较苛刻的要求,应用不是非常广泛。但是如果数据特征比较符合这些排序算法的要求,应用这些算法,会非常高效,线性时间复杂度可以达到 O(n)。桶排序和计数排序的排序思想是非常相似的,都是针对范围不大的数据,将数据划分成不同的桶来实现排序。基数排序要求数据可以划分成高低位,位之间有递进关系。比较两个数,我们只需要比较高位,高位相同的再比较低位。而且每一位的数据范围不能太大,因为基数排序算法需要借助桶排序或者计数排序来完成每一个位的排序工作。
二分查找
二分查找的核心思想理解起来非常简单,有点类似分治思想。即每次都通过跟区间中的中间元素对比,将待查找的区间缩小为一半,直到找到要查找的元素,或者区间被缩小为 0。但是二分查找的代码实现比较容易写错。你需要着重掌握它的三个容易出错的地方:循环退出条件、mid 的取值,low 和 high 的更新。
二分查找虽然性能比较优秀,但应用场景也比较有限。底层必须依赖数组,并且还要求数据是有序的。对于较小规模的数据查找,我们直接使用顺序遍历就可以了,二分查找的优势并不明显。二分查找更适合处理静态数据,也就是没有频繁的数据插入、删除操作。
字符串匹配算法
BF 算法和 RK 算法 BM KMP算法
。。。
贪心算法
分治算法
(divide and conquer)的核心思想其实就是四个字,分而治之 ,也就是将原问题划分成 n 个规模较小,并且结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
回溯算法
尽管回溯算法的原理非常简单,但是却可以解决很多问题,比如我们开头提到的深度优先搜索、八皇后、0-1 背包问题、图的着色、旅行商问题、数独、全排列、正则表达式匹配等等。如果感兴趣的话,你可以自己搜索研究一下,最好还能用代码实现一下。如果这几个问题都能实现的话,你基本就掌握了回溯算法。
动态规划
淘宝的“双十一”购物节有各种促销活动,比如“满 200 元减 50 元”。假设你女朋友的购物车中有 n 个(n>100)想买的商品,她希望从里面选几个,在凑够满减条件的前提下,让选出来的商品价格总和最大程度地接近满减条件(200 元),这样就可以极大限度地“薅羊毛”。作为程序员的你,能不能编个代码来帮她搞定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号