cpu指令重排序的原理
目录:
1.重排序场景
2.追根溯源
3.缓存一致性协议
4.重排序原因
一、重排序场景
class ResortDemo { int a = 0; boolean flag = false; public void writer() { a = 1; //1 flag = true; //2 } Public void reader() { if (flag) { //3 int i = a * a; //4 …… } } }
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
为了提升计算性能,CPU 从单核升级到了多核甚至用到了超线程技术最大化提高 CPU 的处理性能。CPU增加了高速缓存,操作系统增加了进程、线程,通过CPU时间片的切换最大化的提升CPU的使用率。
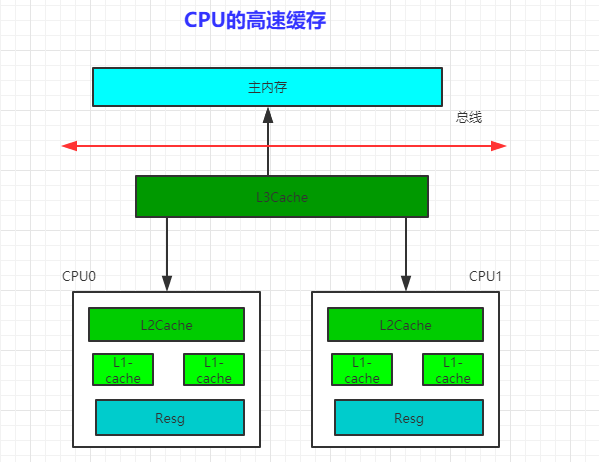
通过高速缓存的存储交互很好的解决了处理器与内存的速度矛盾,但是也为计算机系统带来了更高的复杂度,因为它引入了一个新的问题,缓存一致性。
三、缓存一致性协议
同一份数据可能会被缓存到多个 CPU 中,如果在不同 CPU 中运行的不同线程看到同一份内存的缓存值不一样就会存在缓存不一致的问题。为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有MSI,MESI,MOSI 等。最常见的就是 MESI 协议。
接下来
给大家简单讲解一下 MESI。
MESI 表示缓存行的四种状态,分别是
1. M(Modify) 表示共享数据只缓存在当前 CPU 缓存中,
并且是被修改状态,也就是缓存的数据和主内存中的数
据不一致 2. E(Exclusive) 表示缓存的独占状态,数据只缓存在当前
CPU 缓存中,并且没有被修改
3. S(Shared) 表示数据可能被多个 CPU 缓存,并且各个缓存中的数据和主内存数据一致
4. I(Invalid) 表示缓存已经失效

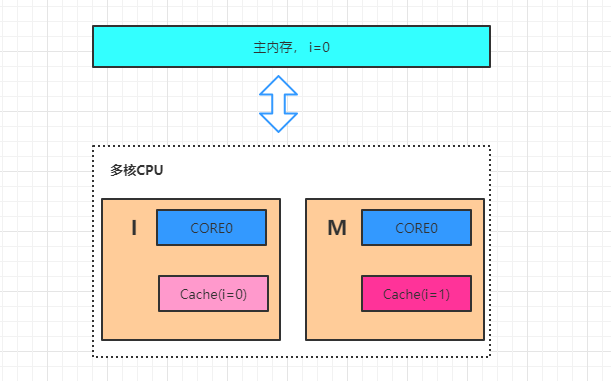
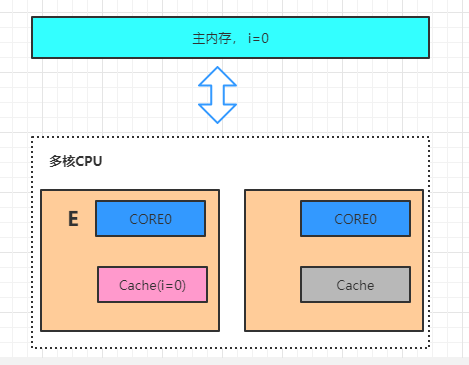
对于 MESI 协议,从 CPU 读写角度来说会遵循以下原则:
CPU 读请求:缓存处于 M、E、S 状态都可以被读取,I 状态 CPU 只能从主存中读取数据。
CPU 写请求:缓存处于 M、E 状态才可以被写。对于 S 状态的写,需要将其他 CPU 中缓存行置为无效才可写。
四、重排序原因
MESI 协议虽然可以实现缓存的一致性,但是也会存在一些问题。
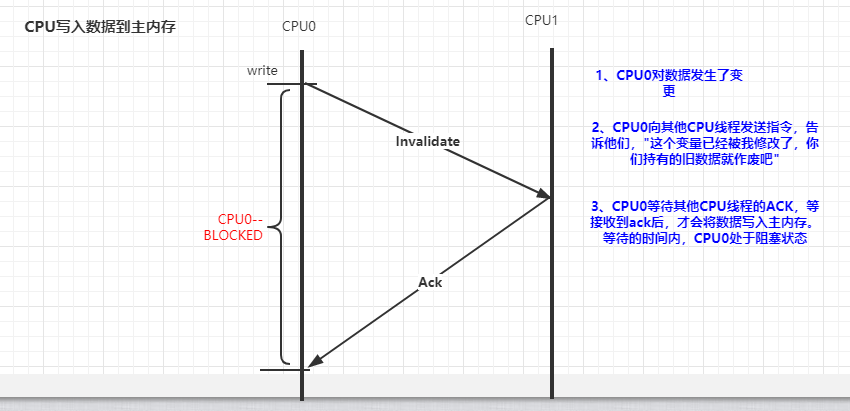
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其
他指令。当收到其他所有 CPU 发送了 invalidate acknowledge 消息时,再将 store bufferes 中的数据数据存储至 cache line中。最后再从缓存行同步到主内存。

这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号