创建测试数据 存储过程:
delimiter // create procedure sp_generate_data() begin set @i := 1; while @i<=500000 do set @created_time := date_add('2017-01-01',interval @i second); set @modified_time := @created_time; set @item_name := concat('a',@i); insert into t_source values (@i,@created_time,@modified_time,@item_name,'other'); set @i:=@i+1; end while; commit; set @last_insert_id := 500000; insert into t_source select item_id + @last_insert_id, created_time, date_add(modified_time,interval @last_insert_id second), item_name, 'other' from t_source; end // delimiter ; call sp_generate_data();
创建一个相同结构的表:
create table t_target like t_source;
将100万条数据中50万重复数据去重,插入新的表中;
set @a:='0000-00-00 00:00:00'; -- 设置变量 set @b:=' '; truncate t_target; -- 清空表 insert into t_target select * from t_source force index (idx_sort) where (@a!=created_time or @b!=item_name) and (@a:=created_time) is not null and (@b:=item_name) is not null order by created_time,item_name; commit;
分析查询语句:explain + 语句;
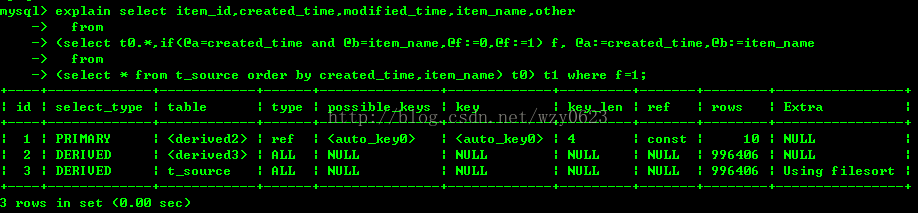
分析结果解释:
(1)最内层的查询扫描t_source表的100万行,并使用文件排序,生成导出表derived3。
(2)第二层查询要扫描derived3的100万行,生成导出表derived2,完成变量的比较和赋值,并自动创建一个导出列f上的索引auto_key0。
(3)最外层使用auto_key0索引扫描derived2得到去重的结果行。
分析数据库表结构,并给出建议,表中数据量越大建议越明确;
select column from table_name procedure analyse();
PROCEDURE ANALYSE 通过分析select查询结果对现有的表的每一列给出优化的建议。
PROCEDURE ANALYSE的语法如下:
SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])
max_elements (默认值256) analyze查找每一列不同值时所需关注的最大不同值的数量.
analyze还用这个值来检查优化的数据类型是否该是ENUM,如果该列的不同值的数量超过了
max_elements值ENUM就不做为建议优化的数据类型。
max_memory (默认值8192) analyze查找每一列所有不同值时可能分配的最大的内存数量
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。
复制表:
2、只复制表结构到新表 CREATE TABLE 新表SELECT * FROM 旧表WHERE 1=2 或CREATE TABLE 新表LIKE 旧表 3、复制旧表的数据到新表(假设两个表结构一样) INSERT INTO 新表SELECT * FROM 旧表 4、复制旧表的数据到新表(假设两个表结构不一样) INSERT INTO 新表(字段1,字段2,.......) SELECT 字段1,字段2,...... FROM 旧表 5、可以将表1结构复制到表2 SELECT * INTO 表2 FROM 表1 WHERE 1=2 6、可以将表1内容全部复制到表2 SELECT * INTO 表2 FROM 表1 7、 show create table 旧表; 这样会将旧表的创建命令列出。我们只需要将该命令拷贝出来,更改table的名字,就可以建立一个完全一样的表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号