
先存两个包在电脑上,
apache-hive-1.2.1-bin.tar
链接:https://pan.baidu.com/s/19koILx8FCa2D65vbK5lIaw
提取码:1kqz
mysql-connector-java-5.1.40.tar
链接:https://pan.baidu.com/s/14OJIHXJoylvMj9M8Axcomw
提取码:ddtc
因两个包是windows里,此时可用共享文件夹方式将两个包挂载到linux系统虚拟机。共享文件夹创建方式可见virtualBox虚拟机Ubuntu系统与主机Windows共享文件夹 - 蚂蚁力量 - 博客园 (cnblogs.com)
在linux命令终端输入 sudo mount -t vboxsf share /mnt/bdshare 完成挂载,进入bdshare文件夹可见文件夹挂载成功

输入 sudo tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local 对apache-hive进行解压并移至/usr/local目录,进入/usr/local目录可见文件解压移动成功
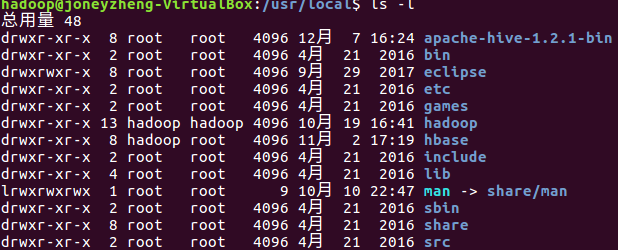
输入sudo mv apache-hive-1.2.1-bin hive 将文件名改为hive,如下所示
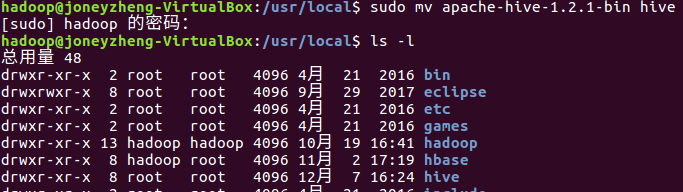
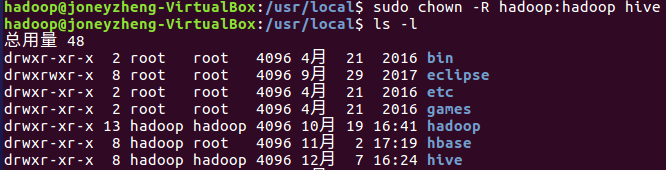
输入sudo chown -R hadoop:hadoop hive 修改文件夹权限
环境变量配置
gedit或者vim bashrc文件,本例使用gedit,输入gedit ~/.bashrc打开配置文件编辑
加入以下两条信息,保存并退出
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
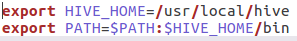
输入source ~/.bashrc使配置立刻生效

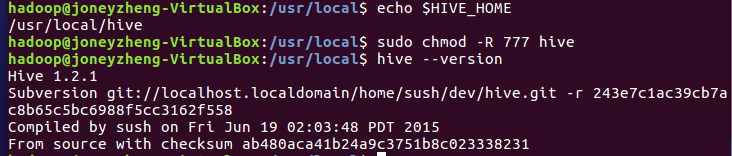
修改配置文件
进入/usr/local/hive/conf文件夹,输入cp hive-default.xml.template hive-default.xml复制文件并重命名
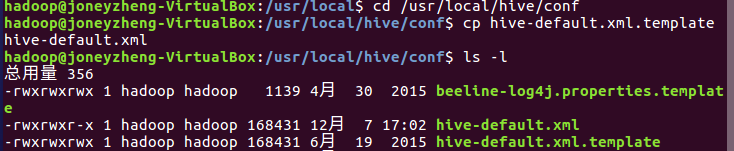
新建一个hive-site.xml文件,内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> </configuration>
mysql配置
输入netstat -tap | grep mysql 查看mysql是否配置,如图进程,已配置

进入共享文件夹对mysql-connector进行解压
tar -zxvf mysql-connector-java-5.1.40.tar.gz
输入cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib将文件复制到/usr/local/hive/lib下

启动并登录mysql shell
service mysql start
mysql -u root -p
新建hive数据库
create database hive;
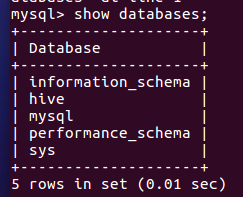
配置mysql允许hive接入
grant all on *.* to hive@localhost identified by 'hive' ;
flush privileges;

启动hive
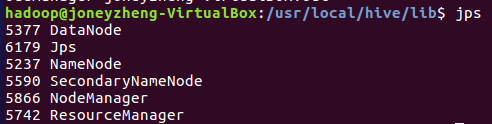
启动hive之前,先启动hadoop集群
start-all.sh
输入hive,若启动不成功则输schematool -dbType mysql -initSchema
我输了后依然没成功,查看错误

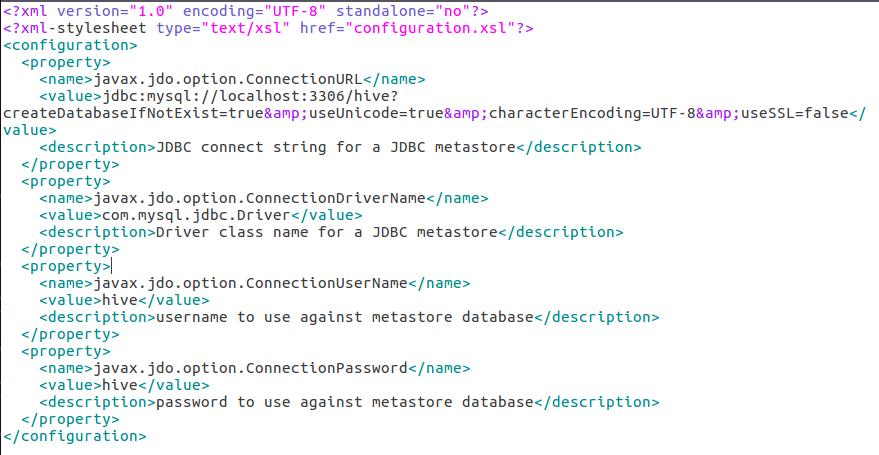
此时进入/usr/local/hive/conf里修改hive-site.xml,修改成如下(在原先基础上添加&useUnicode=true&characterEncoding=UTF-8&useSSL=false)
再次hive成功进入shell

输入exit;即可退出hive shell

关闭hadoop集群
stop-all.sh

二、Hive操作
- hive创建与查看数据库
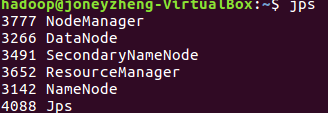
(1)先开启hadoop集群,start-all.sh,jps查看环境是否开启
(2)进入hive环境

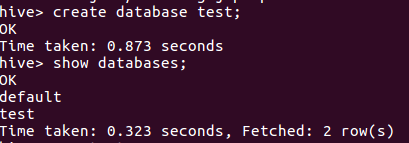
(3)输入create database test;创建数据库test,并show databases;查看数据库
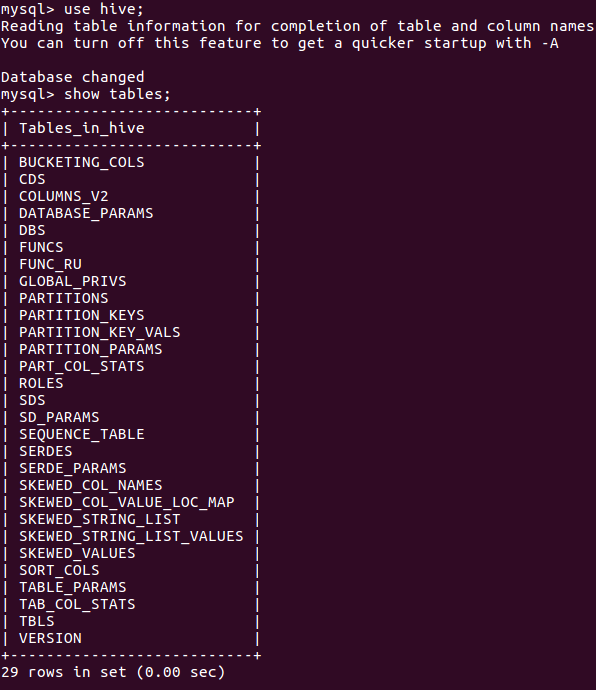
2.mysql查看hive元数据表DBS
输入use hive;
输入show tables;查看表
输入select * from TBLS;查看hive元数据表DBS
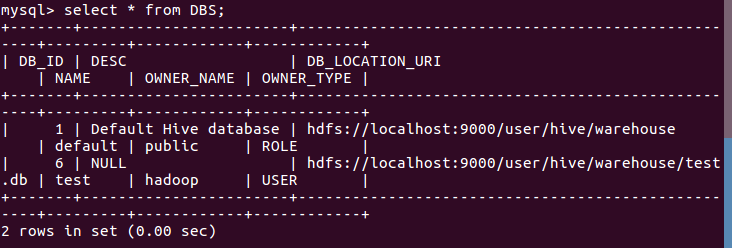
3.hive创建与查看表
输入use test;进入test数据库
输入create table test(id int);创建test表
输入show tables;查看表
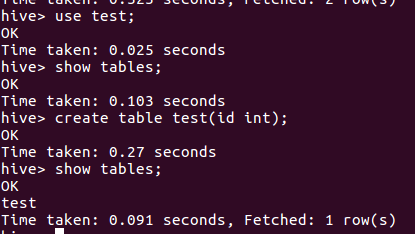
4.mysql查看hive元数据表TBLS
输入select * from TBLS;
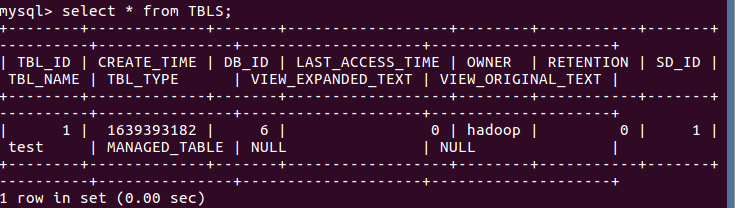
5.hdfs查看表文件位置
输入hdfs dfs -ls /user/hive/warehouse

或 在浏览器输入localhost:50070在菜单栏的Utilities-browse the file system中的搜索框输入/user/hive/warehouse/,点击go
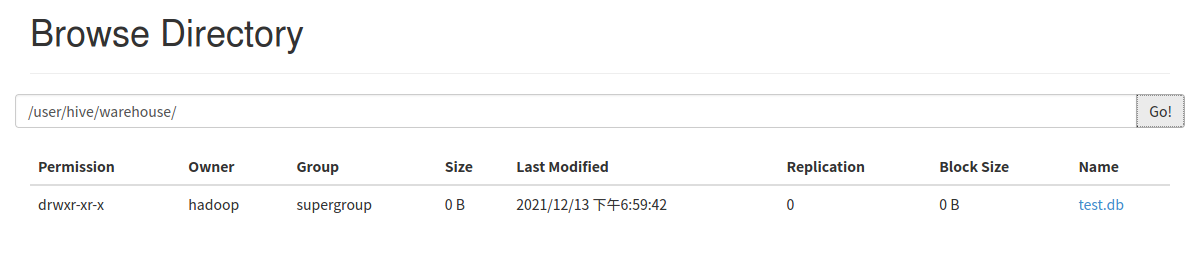
6.hive删除表
输入drop table test;
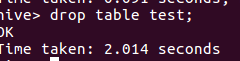
7.mysql查看hive元数据表TBLS
输入select × from TBLS;显示为空

8.hive删除数据库
输入drop database test;
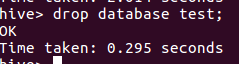
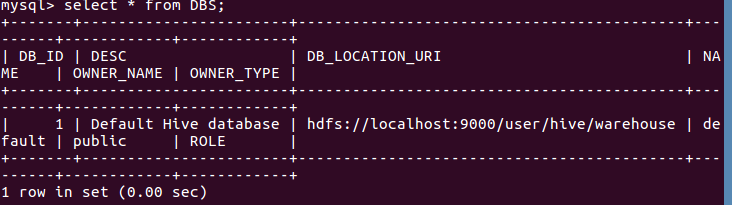
9.mysql查看hive元数据表DBS
输入select * from DBS;
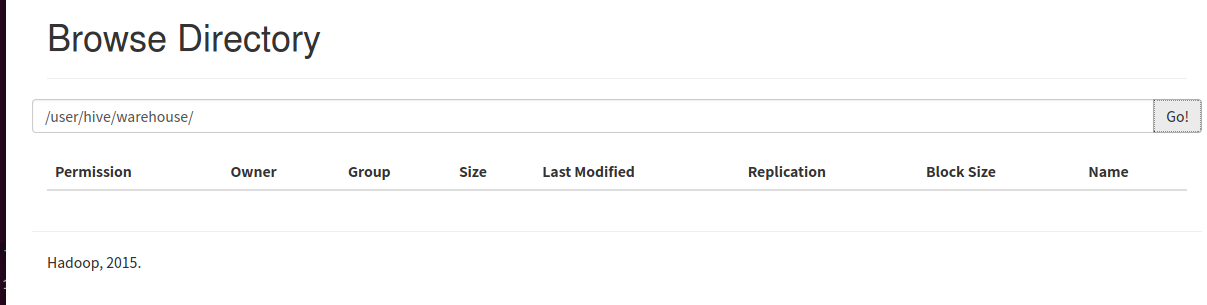
10.hdfs查看表文件夹变化
输入hdfs dfs -ls /user/hive/warehouse显示为空

浏览器上看看
三、hive进行词频统计
- 准备txt文件
准备一个文本文件f1.txt,放置在wc目录,f1.txt内容如下:

2.启动hadoop,启动hive
输入start-all.sh启动hadoop,输入hive启动hive
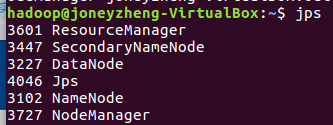

3.创建并查看文本表 create table
输入create table wc(line string);创建表wc,此时表因无指定数据库,默认放在default数据库下。


4.导入文件的数据到文本表中 load data local inpath
(1)输入load data local inpath '/home/hadoop/wc/f1.txt' into table wc;

(2)输入 select * from wc;查看
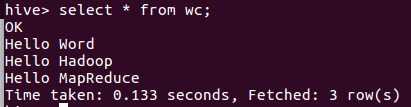
5.分割文本 split
输入select split(line,'') from wc;分割文本查看

6.行转列explode
输入select explode(split(line,'')) from wc;或select explode(split(line,'')) as word from wc;查看
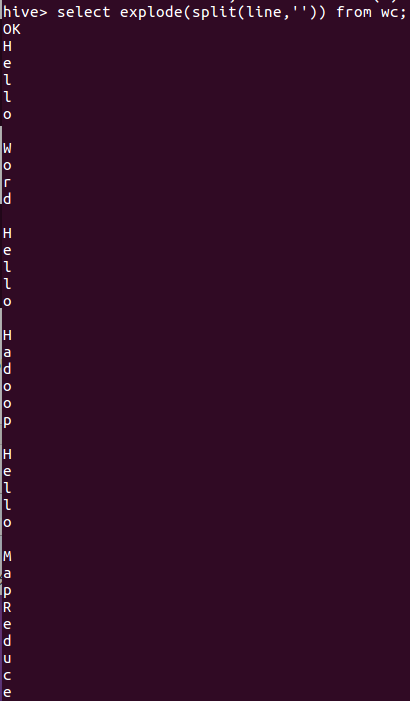

7.统计词频group by
输入select word,count(1) as count from (select explode(split(line,''))as word from wc)w group by word order by word;
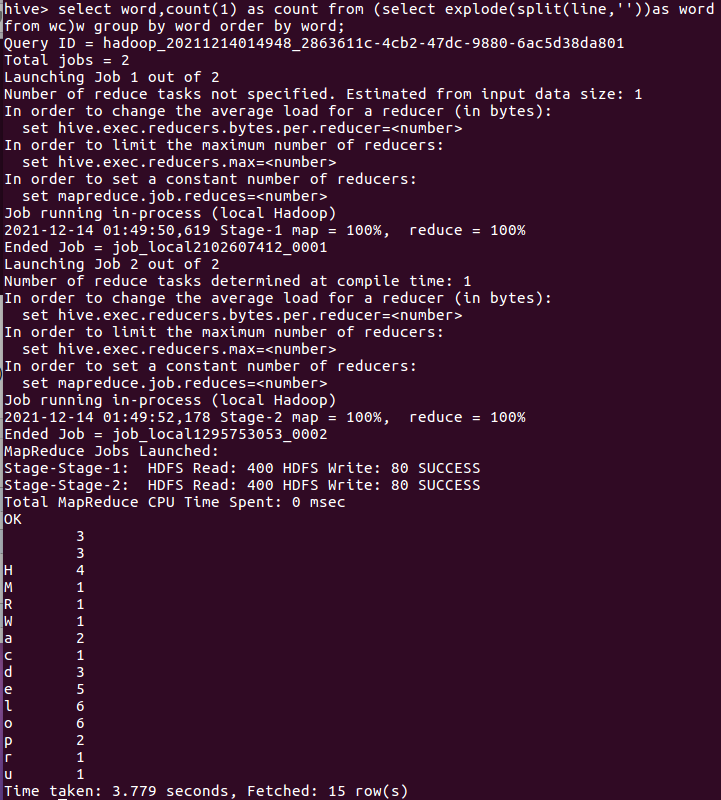
1.准备txt文件
准备f2.txt放于wc目录中

2.上传文件至hdfs
输入 start-all.sh启动hadoop
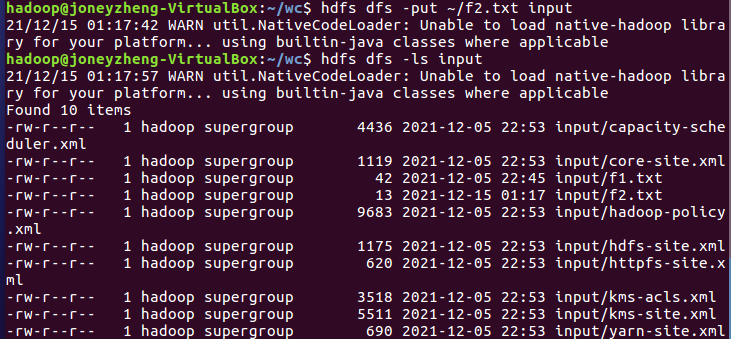
输入hdfs dfs -put ~/f2.txt input上传文件至hdfs,输入hdfs dfs -ls input查看
3.从hdfs导入文件内容到表wctext, 并查看hdfs源文件,hdfs数据库文件
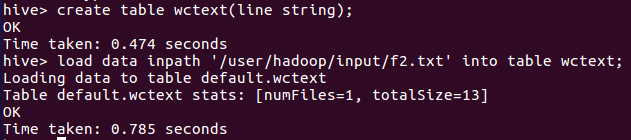
进入hive shell,创建一个wctext表(line string表示行字符串),输入load data inpath '/user/hadoop/input/f2.txt' into table wctext;导入文件内容
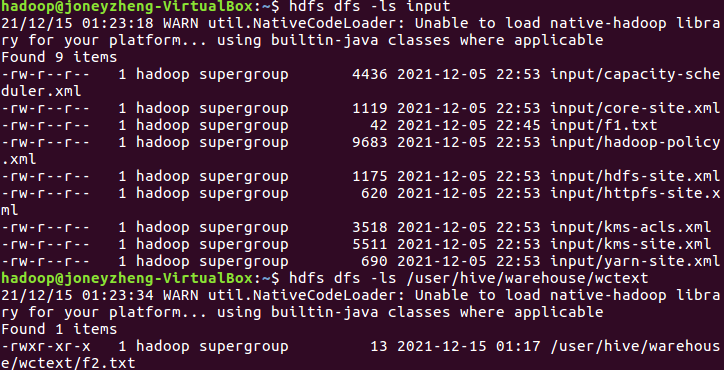
输入hdfs dfs -ls input查看hdfs数据库文件,输入hdfs dfs -ls /user/hive/warehouse/wctext查看hdfs源文件
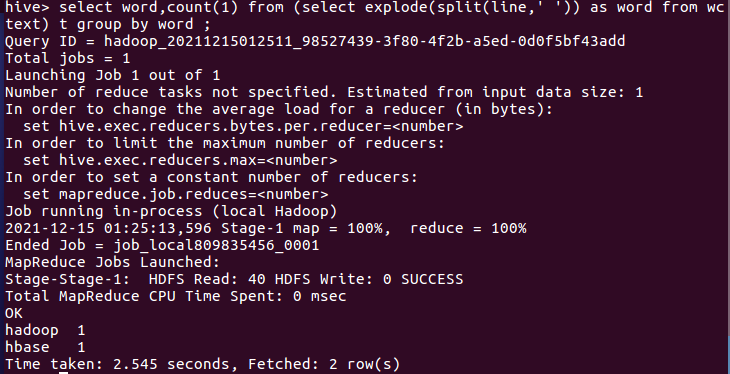
4.统计词频
输入select word,count(1) from (select explode(split(line,' ')) as word from wctext) t group by word ;统计词频,如图所示,
5.词频统计结果存到数据表里,并查看表和文件
输入create table wc as select word,count(1) as count from (select explode(split(line,' ')) as word from wctext) w group by word order by word;把统计结果存入数据表wc,输入show tables;和select * from wc;查看表和文件
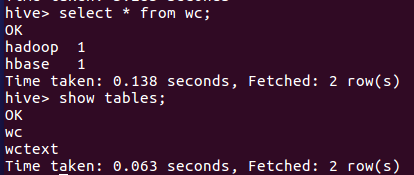
hdfs查看
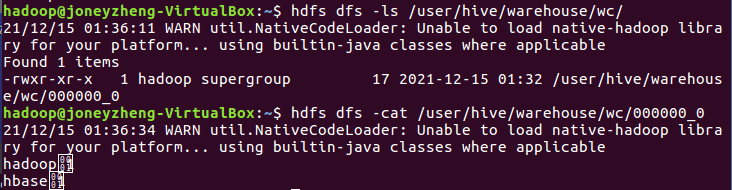
6.本地调用本地hql文件进行词频统计,将结果保存为本地文件
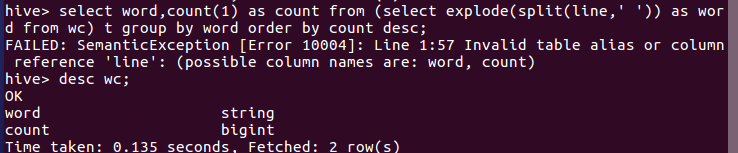
本地创建一个wc.hql文件,将以下语句写进文件:select word,count(1) as count from (select explode(split(word,' ')) as word from wc) t group by word order by count desc;

老师的是select word,count(1) as count from (select explode(split(line,' ')) as word from wc) t group by word order by count desc;但我会报错,如图所示,查看wc表结构,故将line改成word(注:此处应在wc.hql文件中输入命令,不必在hive shell中输入!)
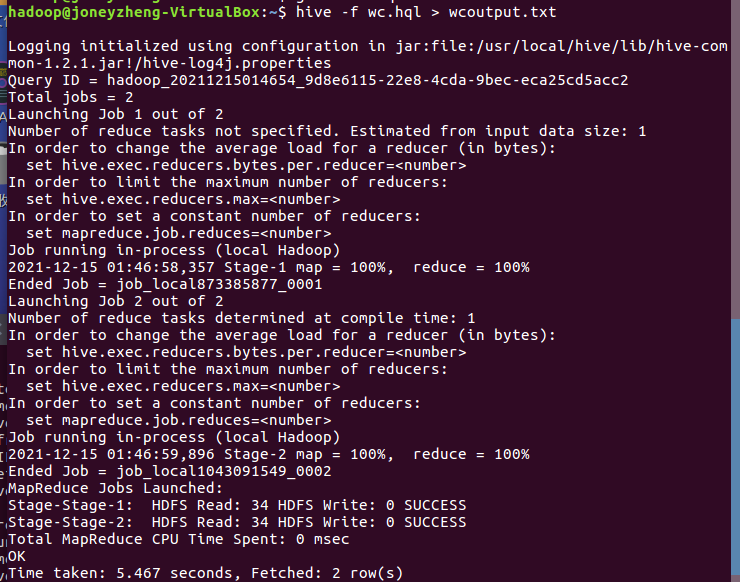
输入hive -f wc.hql > wcoutput.txt将文件映射生成文本文件wcoutput.txt
输入cat wcoutput.txt查看文件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号