
简单数论与简单博弈论
 基础数论的部分总结和基础博弈论来自acwing和自己一些小部分的刷题
基础数论的部分总结和基础博弈论来自acwing和自己一些小部分的刷题
数论博弈论
上下取整问题
证明:
a<b时证明较为容易不在此处提供。
关于ax+by的结论以及证明
这里给出2的证明,1的证明与之类似,后期补充完整。
反证法:假设c=ab-a-b能够被ax+by表示,则ax+by=ab-a-b,则移项合并得a(x+1)+b(y+1)=ab,因为x,y>=0,所以x+1,y+1>=1.
设m=x+1,n=y+1,得m,n>=1,则am+bn=ab,因为ab是a得倍数,am也是a的倍数,即a|am,a|ab,所以想要算式成立,
则需要a|bn,因为a,b互质,所以需要a|n,即n是a的倍数,那么n>a,那么nb>ab,那么am+bn>ab,则假设不成立。
证明了不可以被表示之外还需要证明>ab-a-b的数字一定可以被表示
即需要证明ax+by=ab-a-b+i(i>=1)
因为a,b互质,所以gcd(a,b)=1,则根据裴属定理可得ma+nb=1,假设m>0,n<0,ab-a-b+i(ma+nb) ----> ab-a-b+ima+inb
-----> (im-1)a+(a-1+in)b,根据i>=1,m>0可得im-1>0,只需要再证明出a-1+in>=0即可. ima+inb=i ---> ima=i-inb, 因为i>=1,b>0
n<0,所以inb<0,那么ima=i+|inb|,
必要性证明请参照数论:px+py 不能表示的最大数为pq-p-q的证明 - PIPIBoss - 博客园 (cnblogs.com)
暂时上方的必要性证明没有证明出来,简单查了一下也没看懂
九余数定理
一个数对9取余后的结果成为九余数
一个数每一位上的数字之和相加后的结果<10的数字称为这个数的九余数(如果每一位相加后>10,则继续拆分每一位继续相加)
和的模 等于 模的和再取模 (15+7)%9 = (15%9+7%9)%9
积的模 等于 模的积再取模 (157)%9 = (15%97%9)%9
所以由此可以得到一个数字每一位上的数相加后的结果(<10)等于该数字对9趋于的结果
秦九韶算法
针对于一元n次多项式的计算的优化
质数
质数定义:因子只包含1和其本身的数,称为质数.
一、试除法判定质数
/*
给定 n 个正整数 ai,判定每个数是否是质数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
共 n 行,其中第 i 行输出第 i 个正整数 ai 是否为质数,是则输出 Yes,否则输出 No。
数据范围
1≤n≤100,
1≤ai≤2^31−1
输入样例:
2
2
6
输出样例:
Yes
No
*/
#include <iostream>
using namespace std;
int n;
bool isprime(int x);
int main()
{
cin>>n;
while(n--)
{
int a;
cin>>a;
if(isprime(a))
puts("Yes");
else
puts("No");
}
return 0;
}
bool isprime(int x)
{
if(x<2)
return false;
for(int i=2;i<=x/i;++i)//遍历[2,sqrt(x)]区间判断是否有多的约数
{
if(x%i==0)
{
return false;
}
}
return true;
}
二、分解质因数
/*
给定 n 个正整数 ai,将每个数分解质因数,并按照质因数从小到大的顺序输出每个质因数的底数和指数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
对于每个正整数 ai,按照从小到大的顺序输出其分解质因数后,每个质因数的底数和指数,每个底数和指数占一行。
每个正整数的质因数全部输出完毕后,输出一个空行。
数据范围
1≤n≤100,
1≤ai≤2×109
输入样例:
2
6
8
输出样例:
2 1
3 1
2 3
*/
#include <iostream>
using namespace std;
void divide(int n);
int main()
{
int n;
cin>>n;
while(n--)
{
int a;
cin>>a;
divide(a);
}
return 0;
}
void divide(int n)
{
for(int i=2;i<=n/i;++i)
{
if(n%i==0)
{
int s=0;
while(n%i==0)//此处保证较小的质数全部除去,不会存在多余质因子构成合数
{
n/=i;
++s;
}
printf("%d %d\n",i,s);
}
}
if(n>1)//判断是否有大于sqrt(n)的质因子存在
printf("%d %d\n",n,1);
puts("");
}
三、筛质数(筛法)
/*
给定一个正整数 n,请你求出 1∼n 中质数的个数。
输入格式
共一行,包含整数 n。
输出格式
共一行,包含一个整数,表示 1∼n 中质数的个数。
数据范围
1≤n≤1e6
输入样例:
8
输出样例:
4
*/
①.朴素筛法(O(nlog n))
朴素筛法的主要思想:在遍历的过程中,将其倍数全部筛去,那么剩下的全是质数.
//朴素筛法
#include <iostream>
using namespace std;
const int N=1e6+10;
bool st[N];
int cnt,prime[N];
void get_prime(int n);
int main()
{
int n;
scanf("%d",&n);
get_prime(n);
printf("%d\n",cnt);
return 0;
}
void get_prime(int n)
{
for(int i=2;i<=n;++i)
{
if(!st[i])
{
prime[cnt++]=i;
}
for(int j=i+i;j<=n;j+=i)//将所有数得倍数删去
{
st[j]=true;
}
}
}
②.埃式筛法(优化版朴素筛法)(O(nloglog n))
埃式筛法的主要思想:将所有质数的倍数删去.
//埃式筛法
#include <iostream>
using namespace std;
const int N=1e6+10;
bool st[N];
int cnt,prime[N];
void get_prime(int n);
int main()
{
int n;
scanf("%d",&n);
get_prime(n);
printf("%d\n",cnt);
return 0;
}
void get_prime(int n)
{
for(int i=2;i<=n;++i)
{
if(!st[i])//若是质数则加入prime数组
{
prime[cnt++]=i;
for(int j=i+i;j<=n;j+=i)//将所有质数的倍数筛去
{
st[j]=true;
}
}
}
}
③.线性筛(欧拉筛法)(O(n))
线性筛的主要思想:让每个合数仅被最小质因子筛去.
//线性筛法(欧拉筛法)
#include <iostream>
using namespace std;
const int N=1e6+10;
int prime[N],cnt;
bool st[N];
void get_prime(int n);
int main()
{
int n;
scanf("%d",&n);
get_prime(n);
printf("%d\n",cnt);
return 0;
}
void get_prime(int n)
{
for(int i=2;i<=n;++i)
{
if(!st[i])
prime[cnt++]=i;
for(int j=0;i*prime[j]<=n;++j)
{
st[i*prime[j]]=true;//使得合数被最小质因子筛去
if(i%prime[j]==0)//如果该数字已经被筛则退出循环
break;
}
}
}
约数
①.试除法求约数
/*
给定 n 个正整数 ai,对于每个整数 ai,请你按照从小到大的顺序输出它的所有约数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出共 n 行,其中第 i 行输出第 i 个整数 ai 的所有约数。
数据范围
1≤n≤100,
2≤ai≤2×109
输入样例:
2
6
8
输出样例:
1 2 3 6
1 2 4 8
*/
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> getdivisors(int n);
int main()
{
int n;
cin>>n;
while(n--)
{
int x;
cin>>x;
auto res=getdivisors(x);
for(auto t:res)
{
cout<<t<<' ';
}
puts("");
}
return 0;
}
vector<int> getdivisors(int n)
{
vector<int> res;
for(int i=1;i<=n/i;++i)
{
if(n%i==0)
{
res.push_back(i);
if(i!=n/i)//若另一半约数相同,则只需存放一个
res.push_back(n/i);
}
}
sort(res.begin(),res.end());//将所有约数排序
return res;
}
②.约数个数
对于一个大于1正整数n可以分解质因数:(分解质因数方法参考前文)

则n的正约数的个数就是

/*
给定 n 个正整数 ai,请你输出这些数的乘积的约数个数,答案对 109+7 取模。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出一个整数,表示所给正整数的乘积的约数个数,答案需对 109+7 取模。
数据范围
1≤n≤100,
1≤ai≤2×109
输入样例:
3
2
6
8
输出样例:
12
*/
#include <iostream>
#include <algorithm>
#include <unordered_map>
using namespace std;
typedef long long LL;
const LL mod=1e9+7;
int main()
{
int n;
cin>>n;
unordered_map<int,int> primes;
while(n--)
{
int x;
cin>>x;
for(int i=2;i<=x/i;++i)
{
while(x%i==0)
{
primes[i]++;
x/=i;
}
}
if(x>1)//所有质因子分解完判断是否存在剩余的最后一个>sqrt(x)的因子
{
primes[x]++;
}
}
LL res=1;
for(auto t:primes)
{
res=res*(t.second+1)%mod;//根据公式在计算过程中取模以防溢出
}
cout<<res<<endl;
return 0;
}
③.约数之和
/*
给定 n 个正整数 ai,请你输出这些数的乘积的约数之和,答案对 109+7 取模。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数 ai。
输出格式
输出一个整数,表示所给正整数的乘积的约数之和,答案需对 109+7 取模。
数据范围
1≤n≤100,
1≤ai≤2×109
输入样例:
3
2
6
8
输出样例:
252
*/
#include <iostream>
#include <algorithm>
#include <unordered_map>
using namespace std;
typedef long long LL;
const LL mod=1e9+7;
int main()
{
int n;
cin>>n;
unordered_map<int,int> primes;
while(n--)//质因子分解并存储
{
int x;
cin>>x;
for(int i=2;i<=x/i;++i)
{
while(x%i==0)
{
primes[i]++;
x/=i;
}
}
if(x>1)
primes[x]++;
}
LL res=1;
for(auto t:primes)
{
LL p=t.first;
LL q=t.second;
LL tmp=1;
while(q--)
{
tmp=(tmp*p+1)%mod;//秦九韶算法
}
res=res*tmp%mod;
}
cout<<res<<endl;
return 0;
}
④.最大公约数(欧几里得算法(辗转相除法))
/*
给定 n 对正整数 ai,bi,请你求出每对数的最大公约数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个整数对 ai,bi。
输出格式
输出共 n 行,每行输出一个整数对的最大公约数。
数据范围
1≤n≤105,
1≤ai,bi≤2×109
输入样例:
2
3 6
4 6
输出样例:
3
2
*/
#include <iostream>
#include <algorithm>
using namespace std;
int gcd(int a,int b);
int main()
{
int n;
cin>>n;
while(n--)
{
int a,b;
cin>>a>>b;
cout<<gcd(a,b)<<endl;
//cout<<__gcd(a,b)<<endl;//这里是两个下划线
}
return 0;
}
int gcd(int a,int b)
{
return b?gcd(b,a%b):a;
/*
if(a<b)
swap(a,b);
int t;
while(a%b)
{
t=a%b;
a=b;
b=t;
}
return b;
*/
}
欧拉函数
对于一个大于1正整数n可以分解质因数:(分解质因数方法参考前文)
/*
给定 n 个正整数 ai,请你求出每个数的欧拉函数。
欧拉函数的定义参照上文.
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 ai。
输出格式
输出共 n 行,每行输出一个正整数 ai 的欧拉函数。
数据范围
1≤n≤100,
1≤ai≤2×109
输入样例:
3
3
6
8
输出样例:
2
2
4
*/
#include <iostream>
#include <algorithm>
using namespace std;
int euler(int x);
int main()
{
int n;
cin>>n;
while(n--)
{
int x;
cin>>x;
cout<<euler(x)<<endl;
}
return 0;
}
int euler(int x)
{
int res=x;//保证答案初始乘上x
for(int i=2;i<=x/i;++i)//质因子分解的同时计算欧拉函数
{
if(x%i==0)
{
res=res/i*(i-1);//防止(1-1/i)发生整除
while(x%i==0)
{
x/=i;
}
}
}
if(x>1)
{
res=res/x*(x-1);
}
return res;
}
/*
给定一个正整数 n,求 1∼n 中每个数的欧拉函数之和。
输入格式
共一行,包含一个整数 n。
输出格式
共一行,包含一个整数,表示 1∼n 中每个数的欧拉函数之和。
数据范围
1≤n≤106
输入样例:
6
输出样例:
12
*/
#include <iostream>
#include <algorithm>
using namespace std;
const int N=1e6+10;
typedef long long LL;
int primes[N],idx,phi[N];
bool st[N];
void get_euler(int n);
int main()
{
int n;
cin>>n;
get_euler(n);
LL res=0;
for(int i=1;i<=n;++i)
{
res+=phi[i];
}
cout<<res<<endl;
return 0;
}
void get_euler(int n)
{
phi[1]=1;
for(int i=2;i<=n;++i)
{
if(!st[i])
{
primes[idx++]=i;
phi[i]=i-1;
}
for(int j=0;primes[j]<=n/i;++j)
{
st[primes[j]*i]=true;
if(i%primes[j]==0)
{
phi[primes[j]*i]=primes[j]*phi[i];
break;
}
phi[primes[j]*i]=phi[i]*(primes[j]-1);
}
}
}
快速幂
/*
给定 n 组 ai,bi,pi,对于每组数据,求出 ai^bi mod pi 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含三个整数 ai,bi,pi。
输出格式
对于每组数据,输出一个结果,表示 ai^bi mod pi 的值。
每个结果占一行。
数据范围
1≤n≤100000,
1≤ai,bi,pi≤2×109
输入样例:
2
3 2 5
4 3 9
输出样例:
4
1
*/
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
LL qmi(int a,int b,int p);
int main()
{
int n;
scanf("%d",&n);
while(n--)
{
int a,b,p;
scanf("%d%d%d",&a,&b,&p);
printf("%d\n",qmi(a,b,p));
}
return 0;
}
LL qmi(int a,int b,int p)
{
LL res=1;
while(b)
{
if(b&1)
{
res=res*a%p;
}
a=a*(LL)a%p;
b>>=1;
}
return res;
}
/*
给定 n 组 ai,pi,其中 pi 是质数,求 ai 模 pi 的乘法逆元,若逆元不存在则输出 impossible。
注意:请返回在 0∼p−1 之间的逆元。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个数组 ai,pi,数据保证 pi 是质数。
输出格式
输出共 n 行,每组数据输出一个结果,每个结果占一行。
若 ai 模 pi 的乘法逆元存在,则输出一个整数,表示逆元,否则输出 impossible。
数据范围
1≤n≤105,
1≤ai,pi≤2∗109
输入样例:
3
4 3
8 5
6 3
输出样例:
1
2
impossible
*/
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
LL qmi(int a,int b,int p);
int main()
{
int n;
cin>>n;
while(n--)
{
int a,p;
cin>>a>>p;
if(a%p==0)
puts("impossible");
else
cout<<qmi(a,p-2,p)<<endl;
}
return 0;
}
LL qmi(int a,int b,int p)
{
LL res=1;
while(b)
{
if(b&1)
res=res*a%p;
a=a*(LL)a%p;
b>>=1;
}
return res;
}
拓展欧几里得算法


/*
给定 n 对正整数 ai,bi,对于每对数,求出一组 xi,yi,使其满足 ai*xi+bi*yi=gcd(ai,bi)。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含两个整数 ai,bi。
输出格式
输出共 n 行,对于每组 ai,bi,求出一组满足条件的 xi,yi,每组结果占一行。
本题答案不唯一,输出任意满足条件的 xi,yi 均可。
数据范围
1≤n≤105,
1≤ai,bi≤2×109
输入样例:
2
4 6
8 18
输出样例:
-1 1
-2 1
*/
#include <iostream>
using namespace std;
int exgcd(int a,int b,int &x,int &y);
int main()
{
int n;
scanf("%d",&n);
while(n--)
{
int a,b,x,y;
scanf("%d%d",&a,&b);
exgcd(a,b,x,y);
printf("%d %d\n",x,y);
}
return 0;
}
int exgcd(int a,int b,int &x,int &y)
{
if(b==0)
{
x=1,y=0;//b的系数为0,a的系数为1.
return a;
}
else
{
int d=exgcd(b,a%b,y,x);//传入(b,a%b,y,x)方便推到计算
y-=a/b*x;
return d;
}
}
/*
给定 n 组数据 ai,bi,mi,对于每组数求出一个 xi,使其满足 ai*xi≡bi(mod mi),如果无解则输出 impossible。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组数据 ai,bi,mi。
输出格式
输出共 n 行,每组数据输出一个整数表示一个满足条件的 xi,如果无解则输出 impossible。
每组数据结果占一行,结果可能不唯一,输出任意一个满足条件的结果均可。
输出答案必须在 int 范围之内。
数据范围
1≤n≤105,
1≤ai,bi,mi≤2×109
输入样例:
2
2 3 6
4 3 5
输出样例:
impossible
-3
*/
#include <iostream>
using namespace std;
typedef long long LL;
int exgcd(int a,int b,int &x,int &y);
int main()
{
int n;
scanf("%d",&n);
while(n--)
{
int a,b,m;
int x,y;
scanf("%d%d%d",&a,&b,&m);
int d=exgcd(a,m,x,y);
if(b%d)
puts("impossible");
else
printf("%d\n",(LL)x*b/d %m);//扩大b/d倍并且模到0-m的范围内
}
return 0;
}
int exgcd(int a,int b,int &x,int &y)
{
if(b==0)
{
x=1,y=0;
return a;
}
else
{
int d=exgcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
}
中国剩余定理
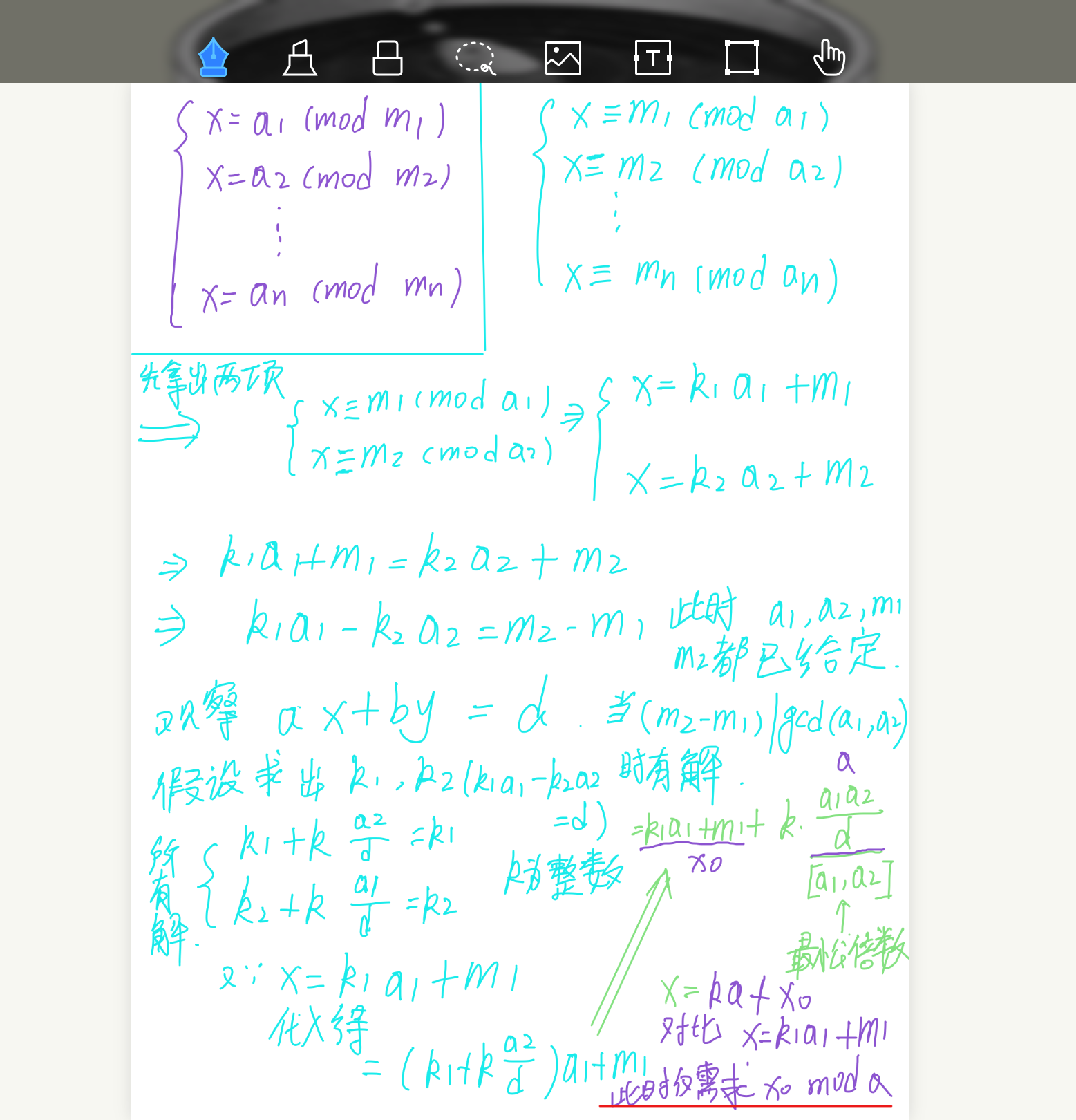
/*
给定 2n 个整数 a1,a2,…,an 和 m1,m2,…,mn,求一个最小的非负整数 x,满足 ∀i∈[1,n],x≡mi(mod ai)。
输入格式
第 1 行包含整数 n。
第 2…n+1 行:每 i+1 行包含两个整数 ai 和 mi,数之间用空格隔开。
输出格式
输出最小非负整数 x,如果 x 不存在,则输出 −1。
如果存在 x,则数据保证 x 一定在 64 位整数范围内。
数据范围
1≤ai≤231−1,
0≤mi<ai
1≤n≤25
输入样例:
2
8 7
11 9
输出样例:
31
*/
#include <iostream>
#include <cmath>
using namespace std;
typedef long long LL;
LL exgcd(LL a,LL b,LL &x,LL &y);
int main()
{
int n;
cin>>n;
LL a1,m1;
cin>>a1>>m1;
bool flag=true;
for(int i=0;i<n-1;++i)
{
LL a2,m2;
cin>>a2>>m2;
LL k1,k2;
LL d=exgcd(a1,a2,k1,k2);
if((m2-m1)%d)
{
flag=false;
break;
}
k1*=((m2-m1)/d);
LL t=a2/d;
k1=(k1%t+t)%t;
m1=a1*k1+m1;
a1=abs(a1/d*a2);
//a1=abs(a1*a2/d);
}
if(flag)
cout<<(m1%a1+a1)%a1<<endl;
else
puts("-1");
return 0;
}
LL exgcd(LL a,LL b,LL &x,LL &y)
{
if(b==0)
{
x=1,y=0;
return a;
}
else
{
LL d=exgcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
}
高斯消元
/*
输入一个包含 n 个方程 n 个未知数的线性方程组。
方程组中的系数为实数。
求解这个方程组。(参考上方方程组)
输入格式
第一行包含整数 n。
接下来 n 行,每行包含 n+1 个实数,表示一个方程的 n 个系数以及等号右侧的常数。
输出格式
如果给定线性方程组存在唯一解,则输出共 n 行,其中第 i 行输出第 i 个未知数的解,结果保留两位小数。
如果给定线性方程组存在无数解,则输出 Infinite group solutions。
如果给定线性方程组无解,则输出 No solution。
数据范围
1≤n≤100,
所有输入系数以及常数均保留两位小数,绝对值均不超过 100。
输入样例:
3
1.00 2.00 -1.00 -6.00
2.00 1.00 -3.00 -9.00
-1.00 -1.00 2.00 7.00
输出样例:
1.00
-2.00
3.00
*/
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
const double eps=1e-6;
const int N=110;
double a[N][N];
int n;
int gauss();
int main()
{
cin>>n;
for(int i=0;i<n;++i)
for(int j=0;j<n+1;++j)
cin>>a[i][j];
int t=gauss();
if(t==0)//返回0代表有唯一的解
{
for(int i=0;i<n;++i)
{
printf("%.2lf\n",a[i][n]);
}
}
else if(t==1)
puts("Infinite group solutions");
else
puts("No solution");
return 0;
}
int gauss()
{
int c,r;
for(c=0,r=0;c<n;++c)
{
int t=r;
for(int i=r;i<n;++i)
{
if(fabs(a[i][c])>fabs(a[r][c]))
t=i;
}
if(fabs(a[t][c])<eps)
continue;
for(int i=0;i<n+1;++i)
swap(a[r][i],a[t][i]);
for(int i=n;i>=0;--i)
a[r][i]/=a[r][c];
for(int i=r+1;i<n;++i)
{
if(fabs(a[i][c])>eps)
{
for(int j=n;j>=c;--j)
{
a[i][j]-=(a[r][j]*a[i][c]);
}
}
}
++r;
}
if(r<n)
{
for(int i=r;i<n;++i)
{
if(fabs(a[i][n])>eps)
return 2;
}
return 1;
}
for(int i=n-1;i>=0;--i)
{
for(int j=i+1;j<n;++j)
{
a[i][n]-=(a[j][n]*a[i][j]);
}
}
return 0;
}
/*
输入一个包含 n 个方程 n 个未知数的异或线性方程组。
方程组中的系数和常数为 0 或 1,每个未知数的取值也为 0 或 1。
求解这个方程组。
异或线性方程组示例如下:
M[1][1]x[1] ^ M[1][2]x[2] ^ … ^ M[1][n]x[n] = B[1]
M[2][1]x[1] ^ M[2][2]x[2] ^ … ^ M[2][n]x[n] = B[2]
…
M[n][1]x[1] ^ M[n][2]x[2] ^ … ^ M[n][n]x[n] = B[n]
其中 ^ 表示异或(XOR),M[i][j] 表示第 i 个式子中 x[j] 的系数,B[i] 是第 i 个方程右端的常数,取值均为 0 或 1。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含 n+1 个整数 0 或 1,表示一个方程的 n 个系数以及等号右侧的常数。
输出格式
如果给定线性方程组存在唯一解,则输出共 n 行,其中第 i 行输出第 i 个未知数的解。
如果给定线性方程组存在多组解,则输出 Multiple sets of solutions。
如果给定线性方程组无解,则输出 No solution。
数据范围
1≤n≤100
输入样例:
3
1 1 0 1
0 1 1 0
1 0 0 1
输出样例:
1
0
0
*/
#include <iostream>
#include <algorithm>
using namespace std;
const int N=110;
int a[N][N];
int n;
int gauss();
int main()
{
cin>>n;
for(int i=0;i<n;++i)
{
for(int j=0;j<n+1;++j)
{
cin>>a[i][j];
}
}
int t=gauss();
if(!t)
{
for(int i=0;i<n;++i)
cout<<a[i][n]<<endl;
}
else if(t==1)
puts("Multiple sets of solutions");
else
puts("No solution");
return 0;
}
int gauss()
{
int r,c;
for(c=0,r=0;c<n;++c)
{
int t=r;
for(int i=r;i<n;++i)
{
if(a[i][c])
{
t=i;
break;
}
}
if(!a[t][c])
continue;
for(int i=c;i<n+1;++i)
{
swap(a[t][i],a[r][i]);
}
for(int i=r+1;i<n;++i)
{
if(a[i][c])
{
for(int j=c;j<n+1;++j)
{
a[i][j]^=a[r][j];
}
}
}
++r;
}
if(r<n)
{
for(int i=r;i<n;++i)
{
if(a[i][n])
return 2;
}
return 1;
}
for(int i=n-1;i>=0;--i)
{
for(int j=i+1;j<n;++j)
{
a[i][n]^=(a[i][j]&a[j][n]);
}
}
return 0;
}
组合数

/*
给定 n 组询问,每组询问给定两个整数 a,b,请你输出 C(a,b)mod(109+7) 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a 和 b。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤10000,
1≤b≤a≤2000
输入样例:
3
3 1
5 3
2 2
输出样例:
3
10
1
*/
#include <iostream>
#include <algorithm>
using namespace std;
const int N=2e3+10,mod=1e9+7;
int c[N][N];
void init();
int main()
{
init();
int n;
scanf("%d",&n);
while(n--)
{
int a,b;
scanf("%d%d",&a,&b);
printf("%d\n",c[a][b]);
}
return 0;
}
void init()
{
for(int i=0;i<N;++i)
{
for(int j=0;j<=i;++j)
{
if(!j)
c[i][j]=1;
else
c[i][j]=(c[i-1][j]+c[i-1][j-1])%mod;
}
}
}
/*
给定 n 组询问,每组询问给定两个整数 a,b,请你输出 C(a,b)mod(109+7) 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a 和 b。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤10000,
1≤b≤a≤105
输入样例:
3
3 1
5 3
2 2
输出样例:
3
10
1
*/
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N=1e5+10,mod=1e9+7;
int fact[N],infact[N];
int qmi(int a,int k,int p);
void init();
int main()
{
init();
int n;
scanf("%d",&n);
while(n--)
{
int a,b;
scanf("%d%d",&a,&b);
printf("%d\n",(LL)fact[a]*infact[b]%mod*infact[a-b]%mod);
}
return 0;
}
int qmi(int a,int k,int p)
{
LL res=1;
while(k)
{
if(k&1)
res=(LL)res*a%p;
a=(LL)a*a%p;
k>>=1;
}
return res;
}
void init()
{
fact[0]=infact[0]=1;
for(int i=1;i<N;++i)
{
fact[i]=(LL)fact[i-1]*i%mod;
infact[i]=(LL)infact[i-1]*qmi(i,mod-2,mod)%mod;
}
}
/*
给定 n 组询问,每组询问给定三个整数 a,b,p,其中 p 是质数,请你输出 C(a,b)modp 的值。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一组 a,b,p。
输出格式
共 n 行,每行输出一个询问的解。
数据范围
1≤n≤20,
1≤b≤a≤1018,
1≤p≤105,
输入样例:
3
5 3 7
3 1 5
6 4 13
输出样例:
3
3
2
*/
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
int p;
int qmi(int a,int k);
LL C(int a,int b);
LL lucas(LL a,LL b);
int main()
{
int n;
cin>>n;
while(n--)
{
LL a,b;
cin>>a>>b>>p;
cout<<lucas(a,b)<<endl;
}
return 0;
}
int qmi(int a,int k)
{
LL res=1;
while(k)
{
if(k&1)
res=(LL)res*a%p;
a=(LL)a*a%p;
k>>=1;
}
return res;
}
LL C(int a,int b)
{
if(b>a)
return 0;
LL res=1;
for(int i=1,j=a;i<=b;++i,--j)
{
res=(LL)res*j%p;
res=res*qmi(i,p-2)%p;
}
return res;
}
LL lucas(LL a,LL b)
{
if(a<p&&b<p)
return C(a,b);
return (LL)C(a%p,b%p)*lucas(a/p,b/p)%p;
}
/*
输入 a,b,求 C(a,b) 的值。
注意结果可能很大,需要使用高精度计算。
输入格式
共一行,包含两个整数 a 和 b。
输出格式
共一行,输出 C(a,b) 的值。
数据范围
1≤b≤a≤5000
输入样例:
5 3
输出样例:
10
*/
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int N=5010;
int primes[N],idx,sum[N];
bool st[N];
void get_primes(int n);
int get(int n,int p);
vector<int> mul(vector<int> a,int b);
int main()
{
int a,b;
cin>>a>>b;
get_primes(a);
for(int i=0;i<idx;++i)
{
int p=primes[i];
sum[i]=get(a,p)-get(b,p)-get(a-b,p);
}
vector<int> res;
res.push_back(1);
for(int i=0;i<idx;++i)
{
for(int j=0;j<sum[i];++j)
{
res=mul(res,primes[i]);
}
}
for(int i=res.size()-1;i>=0;--i)
{
cout<<res[i];
}
puts("");
return 0;
}
void get_primes(int n)
{
for(int i=2;i<=n;++i)
{
if(!st[i])
{
primes[idx++]=i;
}
for(int j=0;primes[j]<=n/i;++j)
{
st[primes[j]*i]=true;
if(i%primes[j]==0)
break;
}
}
}
int get(int n,int p)
{
int res=0;
while(n)
{
res+=n/p;
n/=p;
}
return res;
}
vector<int> mul(vector<int> a,int b)
{
vector<int> c;
int t=0;
for(int i=0;i<a.size();++i)
{
t+=a[i]*b;
c.push_back(t%10);
t/=10;
}
while(t)
{
c.push_back(t%10);
t/=10;
}
return c;
}
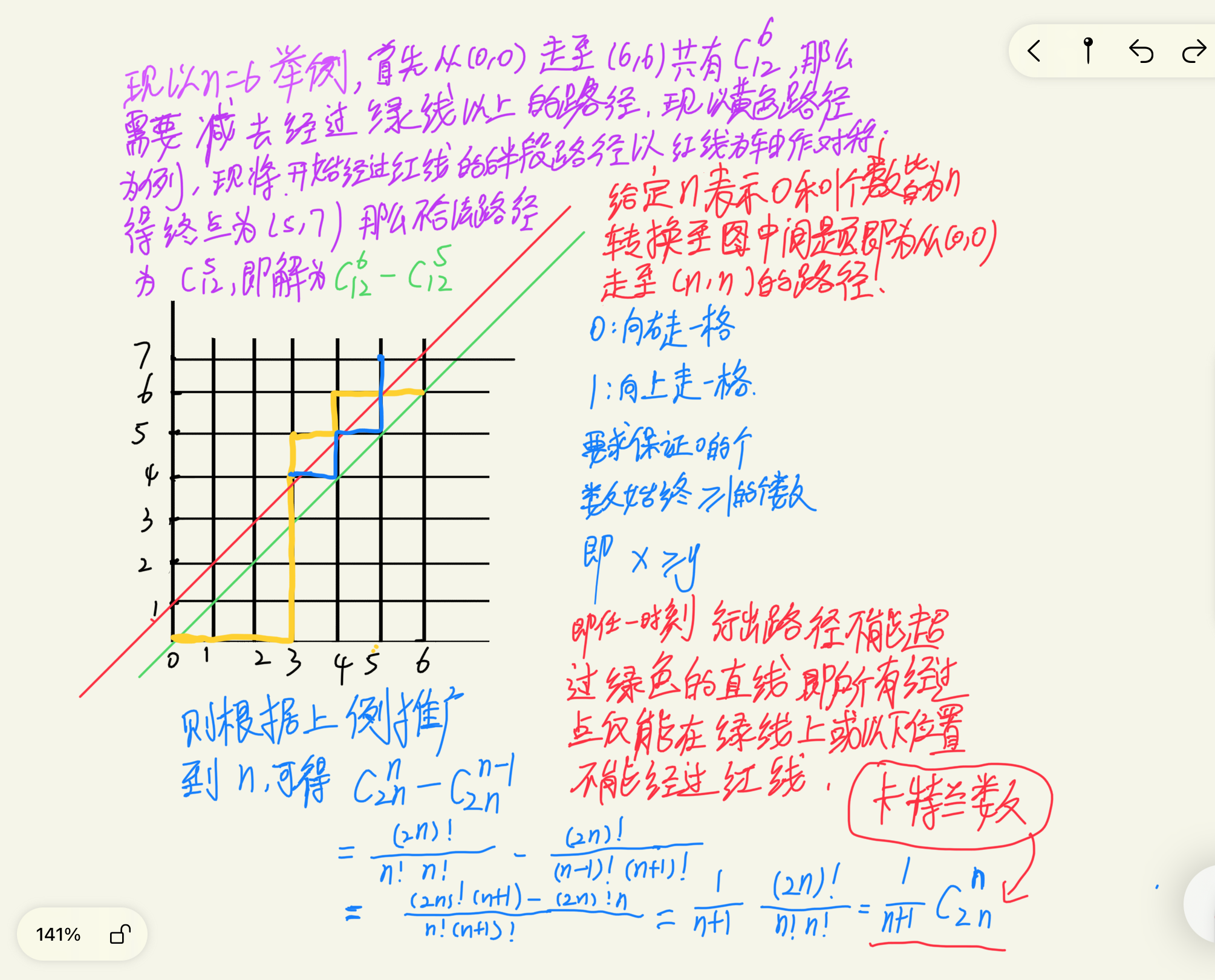
/*
给定 n 个 0 和 n 个 1,它们将按照某种顺序排成长度为 2n 的序列,求它们能排列成的所有序列中,能够满足任意前缀序列中 0 的个数都不少于 1 的个数的序列有多少个。
输出的答案对 109+7 取模。
输入格式
共一行,包含整数 n。
输出格式
共一行,包含一个整数,表示答案。
数据范围
1≤n≤105
输入样例:
3
输出样例:
5
/*
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int mod=1e9+7;
int qmi(int a,int k,int p);
int main()
{
int n;
cin>>n;
int a=2*n,b=n;
LL res=1;
for(int i=a;i>=a-b+1;--i)
{
res=(LL)res*i%mod;
}
for(int i=b;i>0;--i)
{
res=(LL)res*qmi(i,mod-2,mod)%mod;
}
res=(LL)res*qmi(n+1,mod-2,mod)%mod;
cout<<res<<endl;
return 0;
}
int qmi(int a,int k,int p)
{
LL res=1;
while(k)
{
if(k&1)
{
res=(LL)res*a%p;
}
a=(LL)a*a%p;
k>>=1;
}
return res;
}
容斥原理
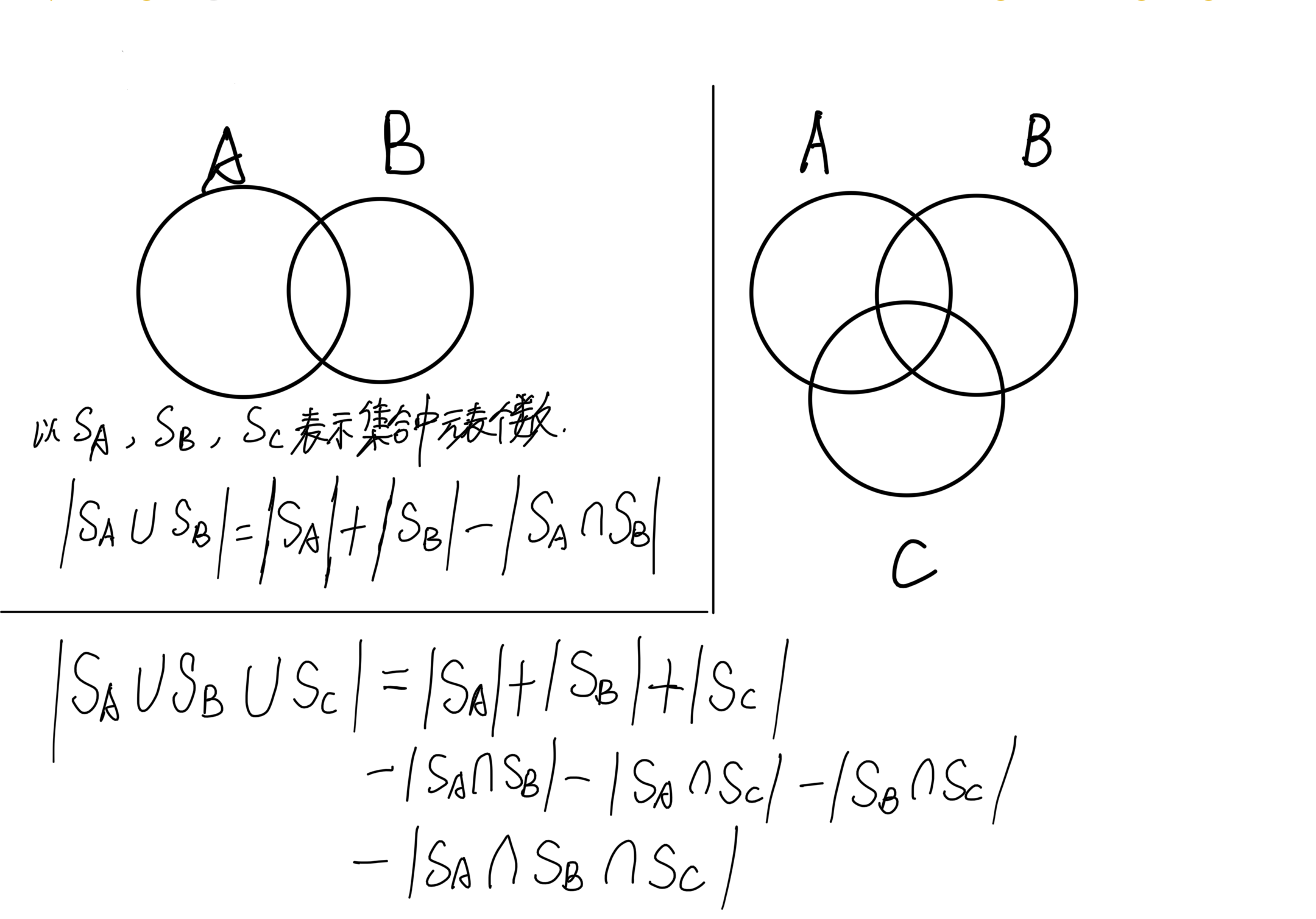
/*
给定一个整数 n 和 m 个不同的质数 p1,p2,…,pm。
请你求出 1∼n 中能被 p1,p2,…,pm 中的至少一个数整除的整数有多少个。
输入格式h
第一行包含整数 n 和 m。
第二行包含 m 个质数。
输出格式
输出一个整数,表示满足条件的整数的个数。
数据范围
1≤m≤16,
1≤n,pi≤109
输入样例:
10 2
2 3
输出样例:
7
*/
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N=20;
int p[N],n,m;
int main()
{
cin>>n>>m;
for(int i=0;i<m;++i)
{
cin>>p[i];
}
int res=0;
for(int i=1;i<1<<m;++i)
{
int t=1,cnt=0;
for(int j=0;j<m;++j)
{
if(i>>j&1)
{
++cnt;
if((LL)t*p[j]>n)
{
t=-1;
break;
}
t*=p[j];
}
}
if(t==-1)
continue;
if(cnt%2)
res+=n/t;
else
res-=n/t;
}
cout<<res<<endl;
return 0;
}
博弈论
/*
给定 n 堆石子,两位玩家轮流操作,每次操作可以从任意一堆石子中拿走任意数量的石子(可以拿完,但不能不拿),最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 n。
第二行包含 n 个数字,其中第 i 个数字表示第 i 堆石子的数量。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n≤105,
1≤每堆石子数≤109
输入样例:
2
2 3
输出样例:
Yes
*/
#include <iostream>
using namespace std;
int main()
{
int n;
scanf("%d",&n);
int res=0;
while(n--)
{
int x;
scanf("%d",&x);
res^=x;
}
if(res)
puts("Yes");
else
puts("No");
return 0;
}
/*
给定 n 堆石子以及一个由 k 个不同正整数构成的数字集合 S。
现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合 S,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式
第一行包含整数 k,表示数字集合 S 中数字的个数。
第二行包含 k 个整数,其中第 i 个整数表示数字集合 S 中的第 i 个数 si。
第三行包含整数 n。
第四行包含 n 个整数,其中第 i 个整数表示第 i 堆石子的数量 hi。
输出格式
如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
1≤n,k≤100,
1≤si,hi≤10000
输入样例:
2
2 5
3
2 4 7
输出样例:
Yes
*/
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_set>
using namespace std;
const int N=110,M=10010;
int s[N],f[M];
int k,n;
int sg(int x);
int main()
{
scanf("%d",&k);
for(int i=0;i<k;++i)
{
scanf("%d",&s[i]);
}
memset(f,-1,sizeof f);
scanf("%d",&n);
int res=0;
for(int i=0;i<n;++i)
{
int x;
scanf("%d",&x);
res^=sg(x);
}
if(res)
puts("Yes");
else
puts("No");
return 0;
}
int sg(int x)
{
if(f[x]!=-1)
return f[x];
unordered_set<int> S;
for(int i=0;i<k;++i)
{
int sum=s[i];
if(x>=sum)
S.insert(sg(x-sum));
}
for(int i=0;;++i)
{
if(!S.count(i))
return f[x]=i;
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~