
BUAA OO 2021 Unit 1 总结
BUAA OO 2021 Unit 1 总结
Homework 1
本次作业需要实现一个简单的求导工具,且保证输入合法。由于项中仅有常数项与幂次项,因此每个项都可以化简为 \(a \cdot x^p\) 的形式,也方便进行同类项的合并、化简与处理。
程序结构分析
类图与分析
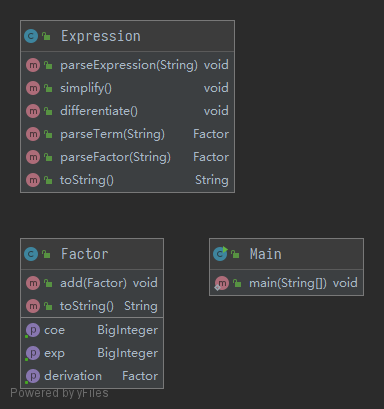
Factor:因子类(同时也是项类)。Expression:表达式类,一个表达式可以包含零个或更多个项。MainClass:主类,主函数入口在此。
方法复杂度
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expression.Expression(String) | 0 | 1 | 1 | 1 |
| Expression.differentiate() | 1 | 1 | 2 | 2 |
| Expression.parseExpression(String) | 4 | 1 | 3 | 3 |
| Expression.parseFactor(String) | 7 | 1 | 5 | 5 |
| Expression.parseTerm(String) | 1 | 1 | 2 | 2 |
| Expression.simplify() | 4 | 1 | 4 | 4 |
| Expression.toString() | 8 | 2 | 4 | 5 |
| Factor.Factor(BigInteger,BigInteger) | 0 | 1 | 1 | 1 |
| Factor.add(Factor) | 0 | 1 | 1 | 1 |
| Factor.getCoe() | 0 | 1 | 1 | 1 |
| Factor.getDerivation() | 0 | 1 | 1 | 1 |
| Factor.getExp() | 0 | 1 | 1 | 1 |
| Factor.toString() | 18 | 3 | 7 | 7 |
| Main.main(String[]) | 0 | 1 | 1 | 1 |
由于在 toString() 方法中有较多的输出化简逻辑,因此拥有较大的圈复杂度。
类复杂度
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expression | 3 | 5 | 21 |
| Factor | 2 | 7 | 12 |
| Main | 1 | 1 | 1 |
第一次作业的类中集成方法较多,但仍在可以接受的范围内。
优缺点分析
优点
- 高效完成了作业要求的任务,且获得了性能分的满分。
缺点
- 针对输入模式进行了特化处理,可扩展性不佳;
- 存储数据与管理对象的方式仍然有些面向过程。
BUG 分析
互测结果
未被发现 BUG,发现他人 BUG 一个(答案为 \(0\) 时会输出空串)。
数据与评测策略
本次基本采用了手动构造的方式进行互测,主要构造了如下数据:
0 -0 --0 ---0
x -x --x
-23333333333333333 * x ** 5
- + -5 * x ** 3 +-1*x**-5
20*x**120
-x+-5*x**6++2*x**2*x**4 + -5 * x**600400*200304 - -3*x**3*1*x**3
-+ -1*x **3
-x**2 - x**3 - x**4 - x**5 + x ** 6 - x ** 7
用于检测 BigInteger 的使用、同类项合并、负数项提前优化、x**2 -> x*x 优化。
Homework 2
本次作业相较第一次作业增加了三角函数与表达式因子。为了方便管理类,因此进行了整体代码的重构,并增加了因子项父类对幂函数与三角函数这两种函数进行处理。同时在本次作业中,将读入的解析改为了递归下降,为之后的表达式因子提供了可能的扩展能力。
具体地说,本次重构内容包括:
- 增加
Factor父类管理各类因子; - 使用递归下降方法解析表达式,具有良好的可扩展性;
- 采用多态,对不同的因子类采取不同的化简方式;
- 增加了拆包机制,即
(((x))) -> x去除表达式因子中最外层的冗余括号(需要递归进行)。
程序结构分析
类图与分析
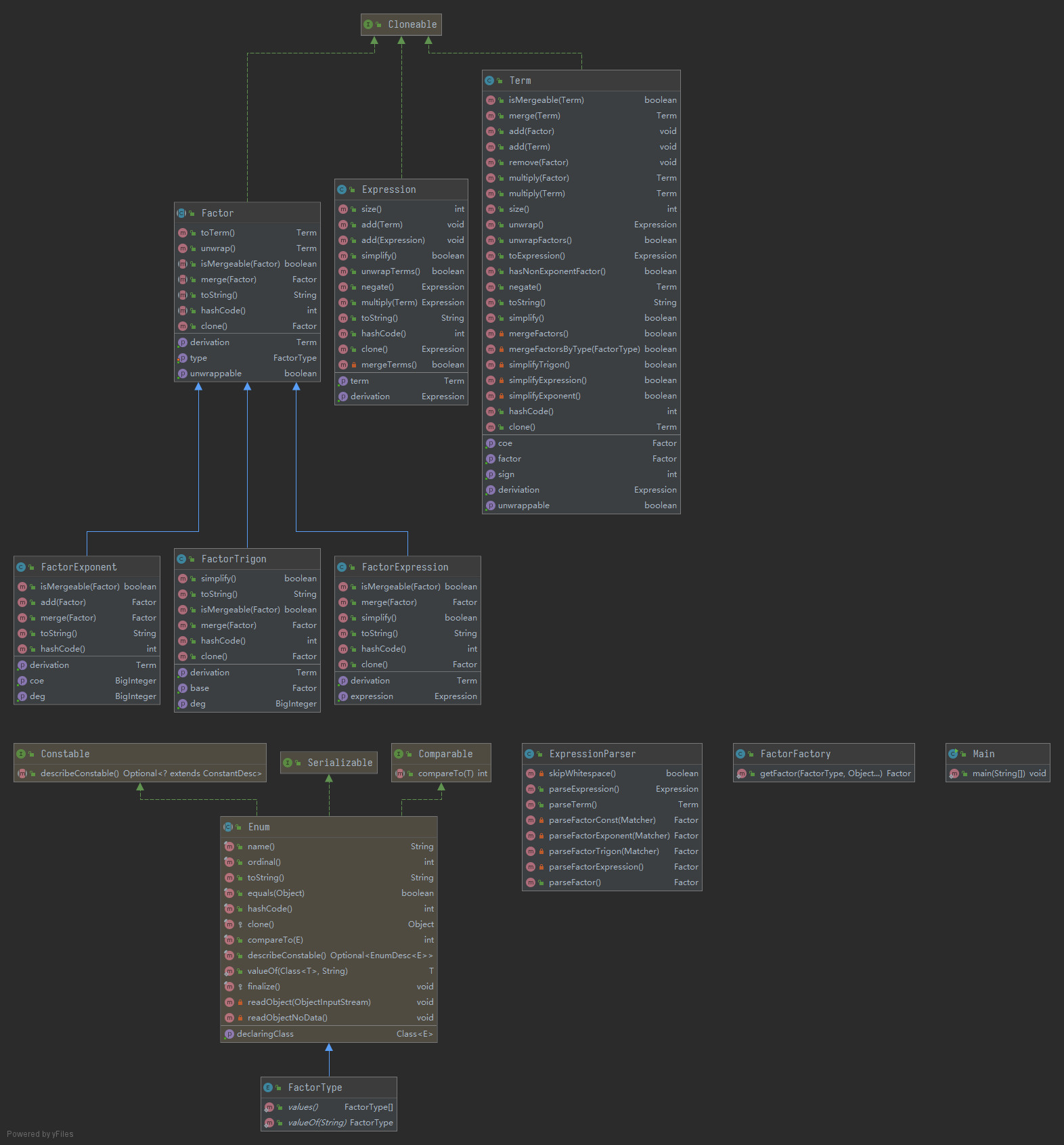
Factor:因子抽象类,所有因子都继承自该父类。Term:项类,一个项可以包含零个或更多个因子。Expression:表达式类,一个表达式可以包含零个或更多个项。FactorType:枚举类,标记因子的种类。因子种类有四种:指数EXPONENT、三角函数SIN与COS、表达式因子EXPRESSION。FactorTrigon:三角函数因子类。FactorExponent:指数函数因子类。FactorExpression:表达式因子类。FactorFactory:因子工厂,存在唯一的静态方法,能根据传入的参数返回对应的因子对象。ExpressionParser:表达式解析类。MainClass:主类,主函数入口在此。
方法复杂度
由于篇幅有限,因此此处仅展示与分析数值较大的方法,隐去复杂度较低的方法。
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.toString() | 16 | 3 | 12 | 14 |
| Expression.toString() | 12 | 3 | 8 | 10 |
| FactorExponent.toString() | 18 | 1 | 7 | 7 |
| Expression.mergeTerms() | 15 | 3 | 7 | 7 |
| Term.mergeFactorsByType(FactorType) | 15 | 3 | 7 | 7 |
| ExpressionParser.parseFactorTrigon(Matcher) | 14 | 3 | 3 | 10 |
| ExpressionParser.parseExpression() | 11 | 3 | 5 | 8 |
| ExpressionParser.parseTerm() | 11 | 3 | 5 | 8 |
| Term.getDeriviation() | 8 | 2 | 6 | 6 |
| Term.simplifyExponent() | 5 | 4 | 5 | 7 |
| ExpressionParser.parseFactorExpression() | 8 | 3 | 2 | 6 |
| Expression.simplify() | 7 | 3 | 4 | 5 |
| Term.simplifyTrigon() | 6 | 1 | 5 | 5 |
可以发现 ExpressionParser 类的方法和 toString() 方法的 ev 值较高,前者是因为递归下降过程中结构化程度较低,后者是因为将表达式输出化简的部分集成到了 toString() 方法中。一种可能的解决方式是,将 ExpressionParser 采用更加结构化的方法进行编写,同时将过长的逻辑拆分为多个互相正交的模块,以降低耦合度。
类复杂度
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expression | 2.8 | 9 | 42 |
| ExpressionParser | 4.11 | 9 | 37 |
| Factor | 1.17 | 2 | 7 |
| FactorExponent | 1.89 | 7 | 17 |
| FactorExpression | 1 | 1 | 9 |
| FactorFactory | 6 | 6 | 6 |
| FactorTrigon | 2.1 | 5 | 21 |
| FactorType | n/a | n/a | 0 |
| Main | 1 | 1 | 1 |
| Term | 2.9 | 8 | 84 |
可以看出工厂类里的平均循环复杂度较高,这是因为其涉及到的其他类数量也较多。同时,Term 类里有较多面向过程的方法用于化简表达式,因此总循环复杂度也较高。
优缺点分析
优点
- 采用递归下降解析表达式,能够有效处理表达式因子嵌套的情况,也为第三次作业增加 WF 判定提供了良好的扩展余地。
- 采用继承与多态特性,使得不同类型的因子便于管理。
- 采用工厂模式,统一管理了
Factor类的对象产生,而不需要关注具体类的生成过程。 - 没有进一步抽象操作符类(如加减法、幂次操作、乘法等),因此在表达式化简上具有天然的优势。
缺点
- 类内的方法逻辑复杂,尤其是
Term类中集成了针对各类因子的化简方式,使得 WMC 值较大。 - 由于因子的存储方式设计不佳(直接采用了 ArrayList 顺序存储所有因子),因此化简过程并不够自然,且需要轮询检查能否化简,整体时间复杂度较高。
BUG 分析
互测结果
被发现一个 BUG,发现他人 BUG 一个。
该 BUG 是合并 Term 同类项与合并 Factor 同类项中,采用了相同的 hashCode() 方法进行同类项判断而导致了出错,即会把 (x + sin(x)) 与 (2 * x + sin(x)) 判定为同类项。解决方法是针对不同的哈希值需求,提供不同的哈希接口使用,以避免重名复用导致与预期结果不同。
BUG 出现在整体循环复杂度最高的 Term 类内,可见当类的复杂度提升时,该类产生 BUG 的概率也会提升。
数据与评测策略
本次作业采用了评测机进行随机测试,因此可以更大量地进行自己构造过的数据测试,也可以进行随机测试,有效提升了找到自己与他人 BUG 的概率(事实上也是这样)。
同时,本次针对化简过程中拆括号与冗余项消除的情况,制造了许多样例来测试程序的化简功能与正确性,而这些数据也成功帮助本人找到了不少化简过程中出现的 BUG。
(cos(x))*(sin(x))
(cos(x)*sin(x)
(sin(x))*(cos(x))
sin(x) - sin(x)
-((sin(x) - sin(x)) * (cos(x) - cos(x))) * -1
(sin(x))
(x) * (sin(x))
(2 + 4) * x
(0 + 3 - 3) * x ** 2
(3 - 3) * x ** 2
(3 - 3) * x
(-2 * x + 0) * x ** 2
(-2 * x + 1) * x ** 2
(-2 * x + 1) * x
(2 * x + 1) * x = 2 * x ^ 2 + x = 4 * x + 1
(((sin(x)) * x ** 2) * 1)
(((cos(x)) * x ** 2) * 1)
(-1 + x ** 233) * sin(x)
(-1 + x) * sin(x)
(x + 1) * sin(x)
-1 * sin(x) + (-1 + x ** 2) * sin(x) * cos(x)
1*x*(sin(x)+cos(x)**0)
x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x
sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)*sin(x)
sin(x)*cos(x)
(x + 1 - 1) * x
x * 2 * sin(x) ** 3 + (sin(x) * sin(x) ** 2 * 2 * x)
-x * 2 * sin(x) ** 3 + (sin(x) * sin(x) ** 2 * 2 * x)
(sin(x) ** 2 + cos(x) ** 2) * 1
(sin(x) ** 2 + cos(x) ** 2) * sin(x)
(sin(x) ** 2 + cos(x) ** 2) * x
2 *(sin(x) * sin(x) ** 2 * 2 * x)
主要策略包括:
- 构造常数之和为 \(0\)
- 构造复杂的括号嵌套
- 构造看上去截然不同的同类项合并
Homework 3
本次作业相较于第二次作业,增加了 WF 的判定以及三角函数中表达式因子的嵌套。由于第二次作业架构中较好,因此能够顺利处理 WF 以及表达式因子的修改(第二次中三角函数的内层函数就已经是一个因子了),很快完成了整体修改。
程序结构分析
类图与分析
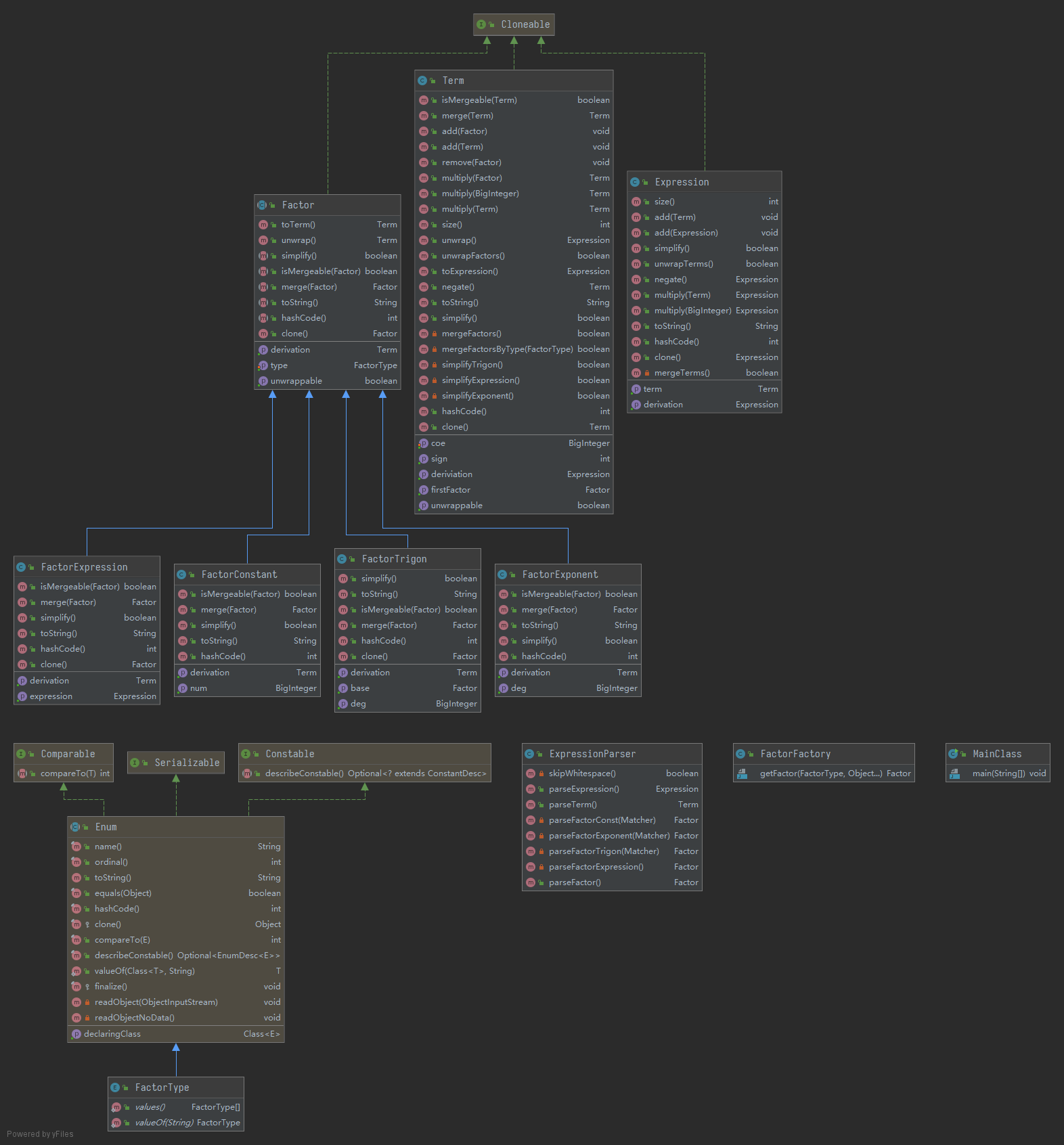
本次作业比第二次作业增加了一个 FactorConstant 类,用于管理常数因子(而不是将其作为指数函数因子的一个特例),有效解决了表达式化简过程中需要时常特殊判断常数项的需求,也便于进行因子管理。
方法复杂度
由于篇幅有限,因此此处仅展示与分析数值较大的方法,隐去复杂度较低的方法。
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| ExpressionParser.parseFactorTrigon(Matcher) | 17 | 10 | 4 | 14 |
| Expression.toString() | 13 | 4 | 8 | 11 |
| Term.toString() | 13 | 5 | 6 | 9 |
| Expression.mergeTerms() | 15 | 3 | 7 | 7 |
| Term.mergeFactorsByType(FactorType) | 15 | 3 | 7 | 7 |
| ExpressionParser.parseExpression() | 12 | 4 | 5 | 9 |
| ExpressionParser.parseTerm() | 10 | 5 | 5 | 9 |
| ExpressionParser.parseFactorExpression() | 9 | 5 | 2 | 7 |
| Term.getDeriviation() | 8 | 3 | 6 | 6 |
| FactorExponent.toString() | 8 | 1 | 4 | 4 |
| FactorTrigon.simplify() | 6 | 1 | 5 | 5 |
| Term.simplifyTrigon() | 6 | 1 | 5 | 5 |
| ExpressionParser.parseFactor() | 4 | 4 | 4 | 4 |
| Expression.simplify() | 6 | 3 | 3 | 4 |
本次作业相较于第二次作业并无过多修改,因此复杂度上差异不大,但同样都较高。
优点
- 由于第二次作业的良好扩展性,第三次作业的 WF 判定和表达式因子修改可以很快完成;
- 增加了基于表达式哈希值的同类项合并,能有效将看上去很长的同类项进行合并;
- 针对不同的因子类型,编写了不同类型的表达式化简方案,因此获得了较好的性能分。
缺点
- 并没有将第二次作业中复杂度较大的方法进行向下分配,导致类与方法复杂度过高,产生 BUG 的几率增加;
- 所有针对 Term 中的表达式化简全都集成在 Term 类中,而这部分功能实际可以下发至不同的 Factor 类中实现,有效降低 Term 类的方法个数与复杂度,更好地实现低耦合。
BUG 分析
互测结果
未被发现 BUG,发现他人 BUG 一个。
数据与评测策略
由于进行了第二次作业的回归测试,因此第三次作业的数据构造集中在 WF 的判定上。为此构造了如下数据进行测试:
sin(x) ** x
sin(x) ** * x
sin(x) ** -3 -> 这是正确的
sin(x) ** * -3
sin(x) ** 0 * x -> 这是正确的
s in(x) ** 0 * x
sin(x) * * 3
sin(())
(cos(x ** 2) + (x ** 2) * sin(x)) * sin(x) -> 可能输出 sin(x * x),这是不对的
(3 + 5 * 6 - 4) * sin(x) -> 这是合法的
sin((x) ** 3)
sin() ** 0
sin (x) ** 0 -> 这是正确的
sin (x) ** -51
sin (x) ** 0 )
sin ( ( x )
( ( x )
+-+1 -> 这是正确的
+-+ 1
+-+x
+-+ x
sin((cos(x) * x)) -> 这是正确的
sin(cos(x) * x)
sin(cos(x) + x)
sin(cos(x)) -> 这是正确的
sin(2 * x)
sin((2 * x)) -> 这是正确的
sin(x * x)
sin((x * x)) -> 这是正确的
sin(x ** 2) -> 这是正确的
主要策略包括:
- 构造
()()这样的括号匹配 - 构造括号完全不匹配的情况
- 构造一些想当然是对的,但是没法被形式化表述推出来的情况
心得体会
本次作业是一次迭代开发的过程,将能完成简单功能的程序出发,逐步将其实现为更有扩展性与新功能的程序,并进一步体会面对对象的本质。在本次作业中,我学习到了工厂模式、正则表达式的基础使用、Java 的容器使用、递归下降方法、面对对象的设计方法等,也从第二第三次作业中逐步感受到面对对象设计的好处与可扩展性。
此外,设计架构也是一门大学问。可以说,良好的架构设计应当是具有可扩展性的,也是具有不断迭代修改的工程中需要的。如果架构已经不足以支撑当前的功能,应当及时重新设计架构,推倒重来。同时,设计架构的过程也需要考虑到未来的可扩展性。

