
Zookeeper(4)---ZK集群部署和选举
一、集群部署
1.准备三台机器,安装好ZK。强烈建议奇数台机器,因为zookeeper 通过判断大多数节点的存活来判断整个服务是否可用。3个节点,挂掉了2个表示整个集群挂掉,而用偶数4个,挂掉了2个也表示其并不是大部分存活,因此也会挂掉,这样反而觉得多浪费了一台机器资源。
2.修改配置文件
固定语法格式:server.节点ID=ip:数据同步端口:选举端口
节点ID:服务id手动指定1至125之间的数字,并写到对应服务节点的 {dataDir}/myid 文件中。
IP地址:节点的远程IP地址
数据同步端口:主从同步数据复制端口。
远举端口:主节点挂了,选举新的主节点的通信端口。
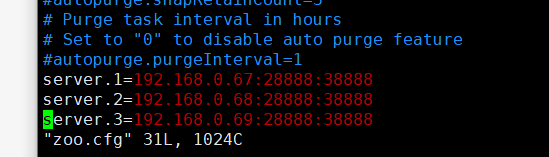
如:
server.1=192.168.0.67:28888:38888
server.2=192.168.0.68:28888:38888
server.3=192.168.0.69:28888:38888
三台机器都是一样的内容:
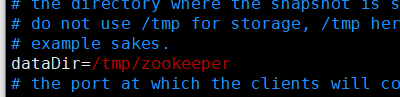
3.配置文件中指定的dataDir目录下面创建myid文件并写入配置中的对应值
我的dataDir目录是/tmp/zookeeper
对应配置中的IP对应的节点ID写入
192.168.0.67:

192.168.0.68:

192.168.0.69:
4.各自使用配置文件启动服务
./zkServer.sh start ../conf/zoo.cfg

5.查看各自的节点的状态
./zkServer.sh status
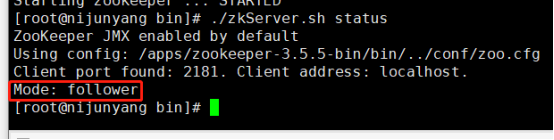
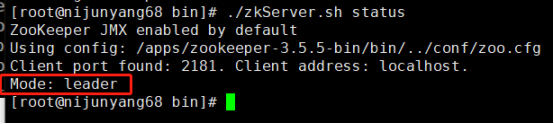
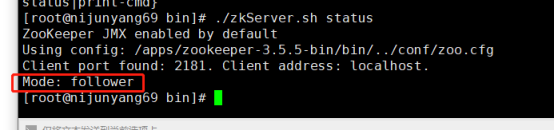
我们可以看到有两台是follower 一台是leader
6.连接集群
连接任意一台节点即可连接集群,也可以每一台都去连接,使用,分割
zkCli.sh 后加参数-server 表示连接指定IP与端口
./zkCli.sh -server 192.168.0.67:2181
连接集群67节点 写入数据,然后再连接68一样可以看到写入的数据,说明数据同步了


如果我们停掉一台机器,集群仍然可用,如果停掉的是leader,那么集群会选举新的leader,选举的时候整个集群是不可用的。如果停掉两台机器,集群就会不可用了。
二、集群角色
前面通过./zkServer.sh status 指令我们看到了集群角色中的leader和follower,还有一个observer
|
leader |
主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。 |
|
follower |
子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并用拥有投票权。 |
|
observer |
次级子节点,又名观察者。用于读取数据,与follower区别在于没有投票权,不能选为主节点。并且在计算集群可用状态时不会将observer计算入内。 |
observer配置:
只要在集群配置中加上observer后缀即可,示例如下:
server.3=192.168.0.69:2889:3889:observer
三、集群选举
前面我们通过./zkServer.sh status 指令已经看到68机器的leader, 67和69是follower
为什么68是leader呢?集群选举的时候,第一轮全部投给自己,后面每次都递增投给比自己myid大的相邻结点。如果票数过半选举结束。
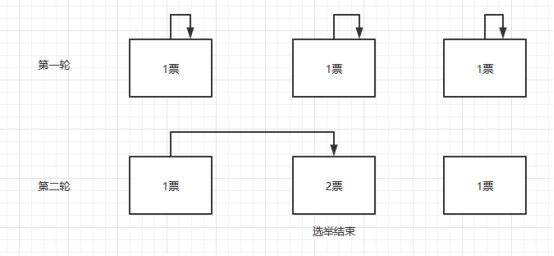
假如是四个节点还会进行第三轮选举,第三轮第一个节点会投给第三个节点,所以如果是4个节点那么leader就会是第三个节点。
集群节点中出现选举有两种情况,一种是节点启动,另一种是半数以上节点无法和leader建立连接。
当节点初始起动时会在集群中寻找Leader节点,如果找到则与Leader建立连接,其自身状态变化follower或observer。如果没有找到Leader,当前节点状态将变化LOOKING,进入选举流程。
在集群运行其间如果有follower或observer节点宕机只要不超过半数并不会影响整个集群服务的正常运行。但如果leader宕机,将暂停对外服务,所有follower将进入LOOKING 状态,进入选举流程。
四、数据同步
zookeeper的数据同步是为了保证各节点中数据的一致性。一个是正常客户端数据提交,另一个是服务宕机恢复之后的数据同步。之前的操作我们也看见了在一台机器上面写入数据之后,在其他的机器上面也是有数据的。
数据写入时,请求可能是发送给follower的,这个时候会将请求转发给leader
1.client向zk中的server发送写请求,如果该server不是leader,则会将该写请求转发给leader server,leader将请求事务以proposal形式分发给follower;
2.当follower收到收到leader的proposal时,根据接收的先后顺序处理proposal;
3.当Leader收到follower针对某个proposal过半的ack后,则发起事务提交,重新发起一个commit的proposal
4.Follower收到commit的proposal后,记录事务提交,并把数据更新到内存数据库;当写成功后,反馈给client。
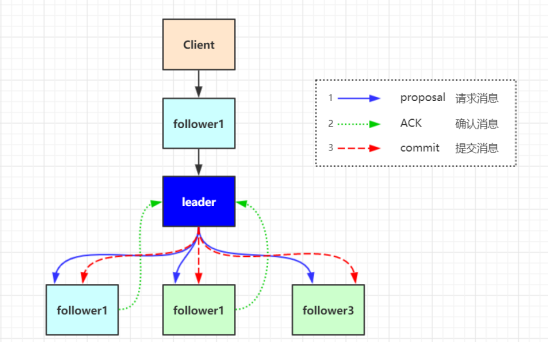
在集群运行过程当中如果有一个follower节点宕机,由于宕机节点没过半,集群仍然能正常服务。当leader 收到新的客户端请求,此时无法同步给宕机的节点。造成数据不一至。为了解决这个问题,当节点启动时,第一件事情就是找当前的Leader,比对数据是否一至。不一至则开始同步,同步完成之后在进行对外提供服务。
那么zk是怎么来确认数据版本呢,是通过前面介绍过的Zxid,来进行对比的。能参与leader选举的节点也是zxid最新的节点(最新zxid数据是完整的)
Zxid是一个长度64位的数字,其中低32位是按照数字递增,任何数据的变更都会导致,低32位的数字简单加1。高32位是leader周期编号,每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。
简单来说就是选举会让zxid的高32的数据加1,每次数据变更会让zxid的低32位数据加1,所以zxid最大的节点数据永远是最完整的一个。
五、集群运维指令
Zk提供了一些运维相关的指令,可以通过telnet或nc向zk发出命令。这些命令都有4个字母组成又叫四字运维命令。
默认这些指令是关闭的,通过配置文件中配置4lw.commands.whitelist来开启这些命令
部分开启:4lw.commands.whitelist=stat, conf, isro,envi
全部开启:4lw.commands.whitelist=*
可能需要安装Netcat工具:
yum install -y nc
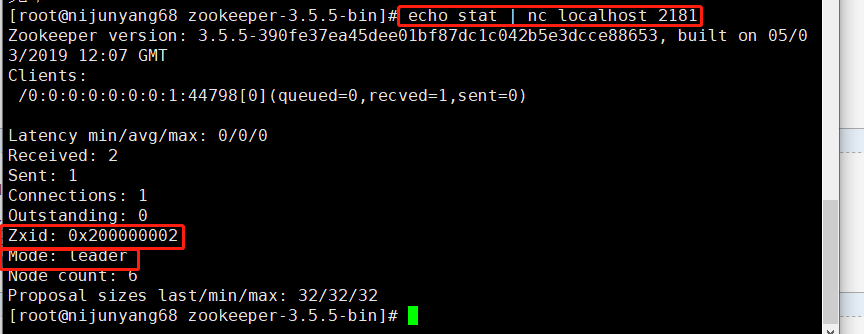
查看服务器及客户端连接状态:
echo stat | nc localhost 2181
1.conf:3.3.0中的新增功能:打印有关服务配置的详细信息。
2.crst:3.3.0中的新增功能:重置所有连接的连接/会话统计信息。
3.dump:列出未完成的会话和临时节点。这仅适用于leader。
4.envi:打印有关服务环境的详细信息
6.ruok:测试服务器是否以非错误状态运行。如果服务器正在运行,它将以imok响应。否则,它将完全不响应。响应“ imok”不一定表示服务器已加入仲裁,只是服务器进程处于活动状态并绑定到指定的客户端端口。使用“ stat”获取有关状态仲裁和客户端连接信息的详细信息。
7.srst:重置服务器统计信息。
8.srvr:3.3.0中的新功能:列出服务器的完整详细信息。
9.stat:列出服务器和连接的客户端的简要详细信息。
10.wchs:3.3.0中的新增功能:列出有关服务器监视的简要信息。
11.wchc:3.3.0中的新增功能:按会话列出有关服务器监视的详细信息。这将输出具有相关监视(路径)的会话(连接)列表。请注意,根据watch的数量,此操作可能会很昂贵(即影响服务器性能),请小心使用。
12.dirs:3.5.1中的新增功能:以字节为单位显示快照和日志文件的总大小
13.wchp:3.3.0中的新增功能:按路径列出有关服务器监视的详细信息。这将输出具有关联会话的路径(znode)列表。请注意,根据手表的数量,此操作可能会很昂贵(即影响服务器性能),请小心使用。
14.mntr:3.4.0中的新增功能:输出可用于监视集群运行状况的变量列表。

