
大数据(4)---HDFS工作机制简述
一、name node管理元数据
元数据:hdfs的目录结构以及文件文件的块信息(块副本数量,存放位置等)。
Namenode把元数据存在内存中,以方便改动,同时也会在某个时间点上面将其写到磁盘上(fsimage镜像文件)。同时还会把引起元数据变化的操作记录在edits日志文件中。重新启动或者是服务挂了的时候,也可以从磁盘文件和日志文件中还原数据。
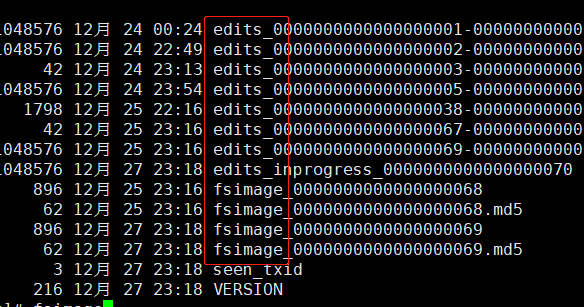
久而久之edits文件会越来越大,如果重启可能会花费很长时间。这个时候就有了Sencondary NameNode,Secondary NameNode定期合并fsimage和edits日志,把edits日志文件大小控制在一个限度下。因为内存需求和NameNode差不多,所以一般都是另外配置一台机器。
Sencondary NameNode整合完毕会将新的fsimages传回给namenode。这个过程叫做checkpoint。那么什么执行这个操作呢。默认的时一个小时,也可以通过参数配置
fs.checkpoint.period 设置checkpoint间隔时间
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。
dfs.namenode.checkpoint.dir Sencondary NameNode保存数据的位置
这个过程和redis的混合持久化有点点类似,RDB快照和AOF重放
二、读写文件过程

