
python模块selenium使用
python模块selenium使用
我使用的是python2.7
可以直接用pip install 安装
这里记录一下,我使用这个模块编写爬虫的学习
做爬虫,我之前都是使用requests 模块写的,如果简单的爬虫,用这个模块确实可以,但是,如果我们要爬取一些比较复杂的网站,如果直接用这个模块写的话,那么就要匹配很多数据,也比较容易出错,或者说是没有那么方便(写是可以写的,只是时间的问题,如果有简单的,肯定是用简单的,当然无论复杂或简单都是学一下)。如果使用requests模块的话,要考虑更多的东西,但是也可以让你更了解整个过程
言归正传:
还是拿之前写的发斗鱼弹幕的代码来讲解(只是简单记录一下,没有详细讲代码)
在安装好上面的模块之后,还要下载一个驱动,因为我们是要打开浏览器,然后用代码实现鼠标的点击和输入

我这里使用的是Chrome浏览器,所以要下载这个浏览器的一个驱动(我称那个东东叫驱动...)
先看一下Chrome浏览器的版本
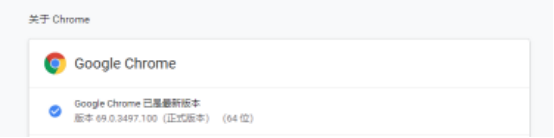
我用的是最新版的
可以到这里下载驱动
http://chromedriver.chromium.org/
需要FQ才能访问
我的是最新版,所以直接下载最新的就可以,建议直接将chrome浏览器更新到最新的,然后直接下载最新版就可以了
下载好之后,将那个压缩包解压到一个文件夹里面(我是直接解压到Chrome的安装路径上面了)


然后将这个路径加入到环境变量里面

然后再启动代码就不会提示没有驱动了
Selenium的基本使用
先加载一个浏览器

然后再请求一个网址

运行代码就会自动打开一个新的Chrome浏览器,然后跳转到指定的网址
最好在代码写一个不断循环的,
不然就会一跳到这个网址,然后就关闭了
因为代码运行完就会停止掉代码
基本使用就是那些了,还有很多功能,等用到了,再继续记录了
下面写一下怎样不打开界面
因为我们做爬虫,我们希望代码执行,然后输出一系列的数据,如果执行代码,弹出一个浏览器,这样子有点不好,不但占内存,也影响效率
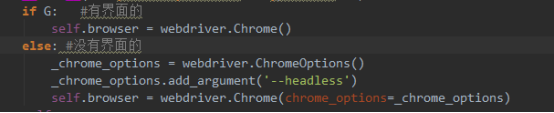
上面的代码就是有界面和没有界面的配置
有时候我们需要设置一个请求头:

上面只是简单地写一下,记录一下,如果想结合代码学习的话,可以到GitHub看我的代码
GitHub地址:https://github.com/niechaojun/Douyu_Barrage

