

第二章 data and sampling distributions
抽样和分布
random sampling and sample bias 随机抽样和抽样偏倚
- key terms
- sample : 抽样集
- subset from a larger dataset
- population:
- the larger data set of a dataset 众集
- random sampling:随机抽样
- draw elements into a sample at random
- 其中随机抽样里面还有又放回和无放回的抽样
- data quality > data quantity
- stratified sampling: 分层抽样,strata层
- devide the population into strata and randomly sample from each strata
- simple random sample: 不是分层抽样
- random sampling without stratifying the population
- sample bias: 坏的样本,无法描述整体的样本
- sample that misrepresents the population
- self-selection sampling bias
- 举的例子是:商品的评论reviews一般来说这个不能反应商品的真实水平,是因为大家写商品评论的动力比起商品多么多么好而言,更多的是因为收到的瑕疵品而对于商品有不满
- statistical bias: 可以等同于理解为“系统误差”
- systematic measurements/sampling errors 测量/抽样误差
- 分层抽样的例子:
- 政客调查支持率的时候会分人种:white,black,hispanics(西班牙裔的)
- sample mean vs. population mean
- 抽样平均和众集平均是两个不同的概念
selection bias 选择产生的bias
- key term
- regression to the mean: 连续观测会导致极端观测值之后的观测值会更偏向于mean
- involving successive measurements, extreme observations tend to be followed by more central ones
- 举例:rookie of the year, sophomore slump 年度最佳球员,第二年打回原形
sampling distribution of a statistic 随机值的抽样分布
- key term
- sampling distribution 抽样分布
- 是抽样结果的频率分布
- central limit theorem
- 抽样数越多,抽样分布就约接近正态分布
- standard error:
- 抽样value 的std
- 计算方法:SE = std/sqrt(n) ---> n:sample size
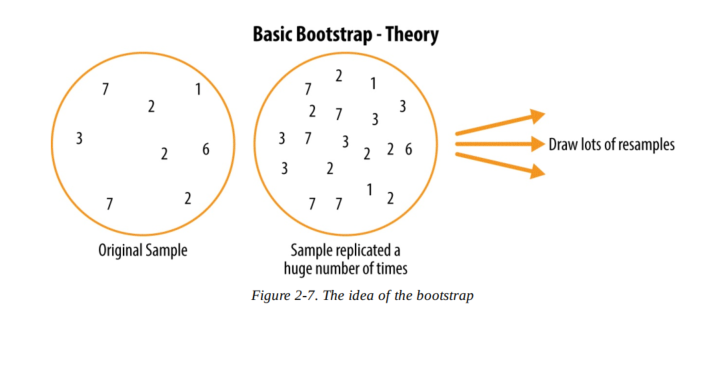
The Bootstrap:
- key term
- bootstrap: 有放回抽样
- 从已知的抽样sample set中,对自己再进行有放回的抽样,重新组成一个的抽样集
- 其中有放回的抽样还可以等效理解为:将自己sample set 自我复制几百万次然后无放回抽样
- bootstrap 算法:
- 抽样,记录,放回
- 重复n次
- 记录这n次的mean,std,median等参数
- 重复1-3 R次
- 用R 来:
- 计算这R个数据的std ----> 就是抽样过程的error/bias
- boxplot/histiogram
- 找confidence interval
- resampling vs. bootstrapping
- 可以理解为同义词,只不过resampling多一个permutation procedures
- 好处1是可以不用拟合复杂的模型就可以得到std
- 好处2是多个bootstrap集合(bagging)可以比单个模型效果好
confidence intervals 置信区间
- key term:
- bootstrap来计算置信区间:
- 有放回的的取n个data
- 计算这些data的特征数据:mean/std
- 重复1-2 R次
- 对于一个x%的置信区间,我们从两边减掉[(1-[x/100])/2]%的sample
- 剪枝点就是置信区间的两端点
- 置信区间的目的:
- 用区间来描述估计
- 看我们能tolerate多少
- 来判断我们estimate有没有可能的error
- 看看是不是需要larger sample
normal distribution 正态分布
- key term
- standardize: 正则化
- (x-x_mean)/x_std
- z-score:
- 正则一个点的结果
- standard normal:
- mean=0,std=1的normal distribution
- 95% confidence interval:
- 2std
long-tailed distribution长尾分布
- key term
- tail:
- extreme values occur at low frequency 极值很少,大多都集中在某个区域
- skew
- one tail is longer than the other 一个tail比另一个要长
student t-distribution学生t分布
- key term
- 90%的confidence interval在:
- x±t_(n-1)(.05)*(s/n) ----> s:std,n:sample size,t_(n-1):t-statistic
binomial distribution二项分布/伯努利分布
如果事件是要么是或者否,那么可以被Model成二项分布
poisson distribution 泊松分布
- key term
- exponential distribution:指数分布
- 时间/地点距离的分布,从一点到另一点,one event to the next event
- weibull distribution
- generalized version of exponential, event rate is allowed to shift over time
- lambda
- the rate at which events occur 事件发生的速率
小结:
- 很多工作都是将数据拟合到分布上,但是不是每个数据都是正态的,有一些规则来明确哪些数据适合那些分布。
- 如果事件发生间隔固定:poisson distribution
- 如果事件间隔在变化:weibull distribution(比如飞机硬件故障率)
联系方式:clarence_wu12@outlook.com

