

撰写理由
很多情况下,发现自己的理论知识特别薄弱,一些基本的实用统计学操作和值的含义都不懂。这里基于《Practical Statistics for Data Scientist》这本书,来学习和归纳实用统计学的基本概念和常见操作
Central Tendency:中心趋向性
常见的key term有:
- mean:
- 意思:sum(values)/len(values)
- weighted mean
- 意思:sum(values*weights)/len(values)
- median
- 意思:先对values进行sort,然后再取中位数。 values.sort()[len(values)/2]
- 近义词: 50-percentile
- weighted median
- 意思:先对于每个value*weight,第二步sort,第三步取这个数,使得这个数前面所有数的sum和后面所有数的sum相等
- trimmed mean
- 意思:去除极值之后的mean
- 近义词: truncated mean
- robust
- 意思:not sensitive to extreme values
- outlier
- 意思:异常值
原文标题estimation of location
感觉有点意义不明,但是下面有一小段话解释了我的疑惑:
- statisticians estimate, data scientists measure,也就是说上面这些key term,统计学家将他们称为estimation(期望),而数据学家称之为metrics(度量)。体现了两个学科侧重点的不同,统计学侧重于数据本身的uncertainty,而数据科学侧重于怎么度量数据来符合应用场景。
estimation of variability离散程度:
key terms:
- Deviations:
- 解释:true_value-estimate_value
- Variance:
- 解释:sum((values-mean)^2)/(len(values)-1) --------------> 注意这里是n-1
- 近义词:mean-squared-error
- standard deviation:
- 解释: sqrt(variance)
- 近义词:l2-norm, euclidean-norm
- mean-absolute-deviation:
- 解释:sum(abs(values-mean))/len(values)
- 近义词:l1-norm,Manhatten-norm
- median absolute deviation from the median:
- 解释:median(abs(values-mean))
- range:
- 解释:largest_val-smallest_val
- order statistics:
- 解释:metrics based on the sorted ascending data (small ---> big)
- 近义词: ranks
- percentile:
- 解释:P percent of values take on this value (所有数里面P%的数在这个数下面)------> 有时候需要取中间值
- 近义词:quantile
- interquartile range:
- 解释:75th_percentile - 25th_percentile
- 近义词:IQR
Exploring the Data Distribution可视化数据分布:
1. boxplot:
示例来自wiki:
+-----+-+
* o |-------| + | |---|
+-----+-+
+---+---+---+---+---+---+---+---+---+---+ 分数
0 1 2 3 4 5 6 7 8 9 10
我们可以读出以下的数值:
- Max:10
- Min:5
- Median:8.5
- Q1(25-Quantile):7
- Q3(75-Quantile):9
- IQR:Q3-Q1=2
- Outlier所在区域:
- 大于Q3+1.5IQR = 11
- 或者Q1-1.5IQR = 4
一般来说制作boxplot的方法是:
- 计算median,Q1,Q3
- 计算IQR
- 计算outlier区域
- 划分了Outlier以后我们再选择剩下的min,max
2. histogram 频数直方图
- 解释:bins on the x-axis, and count/proportion on the y-axis
- 注:statistical moments:
- 1. moment:location/central tendency 平均
- 2. moment:variability 离散
- 3. moment:skewness 偏置度(skewed to larger/smaller values)
- 4. moment:kurtosis 峰度 (propensity of data to have extreme values,有异常值的可能性)
3. density estimation 概率密度函数估计
(光滑的histogram拟合曲线)---> 需要一些base function
exploring binary/categorical data字符型数据
key terms:
- mode:
- 解释:出现次数最多的值
- expected value:
- 解释:sum(values * probability of occurance)
- bar charts/pie charts:
- 解释:画饼图/柱状图来描述 ----> 在这里x-axis由于是categorical,是没有order的
- numerical-to-categorical:
- 解释:数值转成字符型,能够reduce complexity,不用插值?
Correlation 相关性
key terms:
- correlation coefficient:
- 解释:(-1,1)表示负相关到正相关,0表示不相关
- 计算方法:sum((x-x_mean)(y-y_mean))/((N-1)x_std*y_std)
- correlation matrix:
- 解释:相当于热图就是表示两两variable的相关性
- scatterplot:
- 注:随机数可能会呈现相关性
exploring two or more variables 多参数探索
key terms:
- univariate analysis: look at variables one at a time 单变量分析比如mean,variance
- bivariate analysis/correlation analysis: 双变量分析
- multivariate analysis: 多变量分析
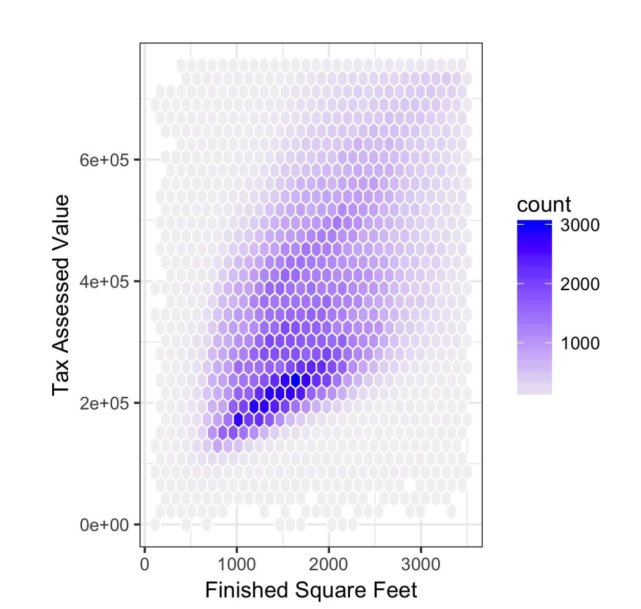
- hexagonal binning:蜂巢链接:比起普通的scatter plot,它将一大堆重叠的点置于一个小格子里面然后用颜色表明其中的count,可以看出哪里最密集
联系方式:clarence_wu12@outlook.com

