

EDA-探索性数据分析
前言:想要从事DA/DS行业的一个很重要的工作部分貌似就是处理数据,处理数据有很多概念:data engineering(DE), data mining(DM) ,data cleaning(DC)又或者是Exploratory Data Analysis。以前我对这些名称都特别迷糊,不知道是什么意思,但是看了一些博客和自己用Python写了一些东西以后就大概懂了一点。最大的概念可以是EDA,其中包括了DE/DM/DC作为预处理的部分。
EDA和传统分析的区别:
EDA是可视化分析输入数据的关联性---->然后预处理---->最后再建模。
传统分析是简单预处理---->然后直接建模(假设正态分布)---->然后分析这个模型的特性,是否拟合,效果怎么样。
预处理基本操作 Data Cleaning
缺省值有吗?
- 检测:看有没有NaN
- 解决方法:
- 可以drop,就完全删掉这行
- 可以fill mean,median,most frequence value,可以用均值,模数或者最大频数来填充,看每个人的想法
有异常值吗?Outlier? Abnormality?
- 检测:用箱型图或者计算出1/4Quantile----3/4Quantile然后看有没有在外面的数字
- 解决方法:
- 可以简单drop
- 如果不是特别奇葩的outlier可以保留
样本是否均衡?normal distributed?
- 检测:画histogram看是不是基本符合正态分布
- 解决方法:
- 如果特别不均衡,我们可以normalize使它均衡,但是这样很可能会丢失某些原始信息,得好好考虑。
样本是否重复? duplicated row?
- 检测:value_count?如果是数据内部的错误导致多复制了一列。
- 解决方法:
- drop_duplicate
是否需要重新抽样?resample?
- 理由:比如说我们有一个365天的时间序列,经典的气候模型数据,我们想知道每个月的平均天气,那么我们就要降频率,重新抽每个月的第一天,或者简单计算每个月的均值。
- 解决方法:
- pandas里面将datestamp拆开成年月日小时分钟秒,然后将月单独新增一个attribute然后aggregate().apply(np.mean)
类型是否需要转换?type convertion?
- 场景:
- 数值型:int->float/float->int?是否需要取整?
- 字符型categorical:我们需要将文字转成数字,才能来给我们建模/ml
- 时间序列:我们需要将时间也拆成数字 - 解决方法:
- 数值型:各种np方法
- 字符型:one-hot encoding/frequency encoding/其他我不知道的encoding
- 时间序列:拆成年月日/直接作为index
是否需要添加新的特征?new attribute?
- 理由:很有必要,这我个人认为是EDA的精华所在,也是提高之后ML准确率的非常关键的一点,但是很多时候这需要我们大胆的猜想,以及对于数据相关度的分析证明了我们的猜想。
- 解决方法:这里存在的太多我知道的太少
- 上面说的时间序列拆年月日
- 分区间(比如工资3000-8000可以分5档分别是0-4)
- 很多domain knowledge,比如说根据人体数据来预测60岁是否患癌,懂医学的朋友可能可以一些参数算出另一个更重要的参数(比如:血小板数)
- 等等 - 这一步和之后的data engineering是互相迭代的过程,可能我们之后发现了一些新的想法可以加进来,所以其实数据处理并没有严格的先后顺序。
数据可视化分析 data engineering
这里大家貌似用pandas的时候都约定俗成的做一些相同的操作,那么我们也就把这个作为一个分析的步骤来看吧。
然后这个著名的图:
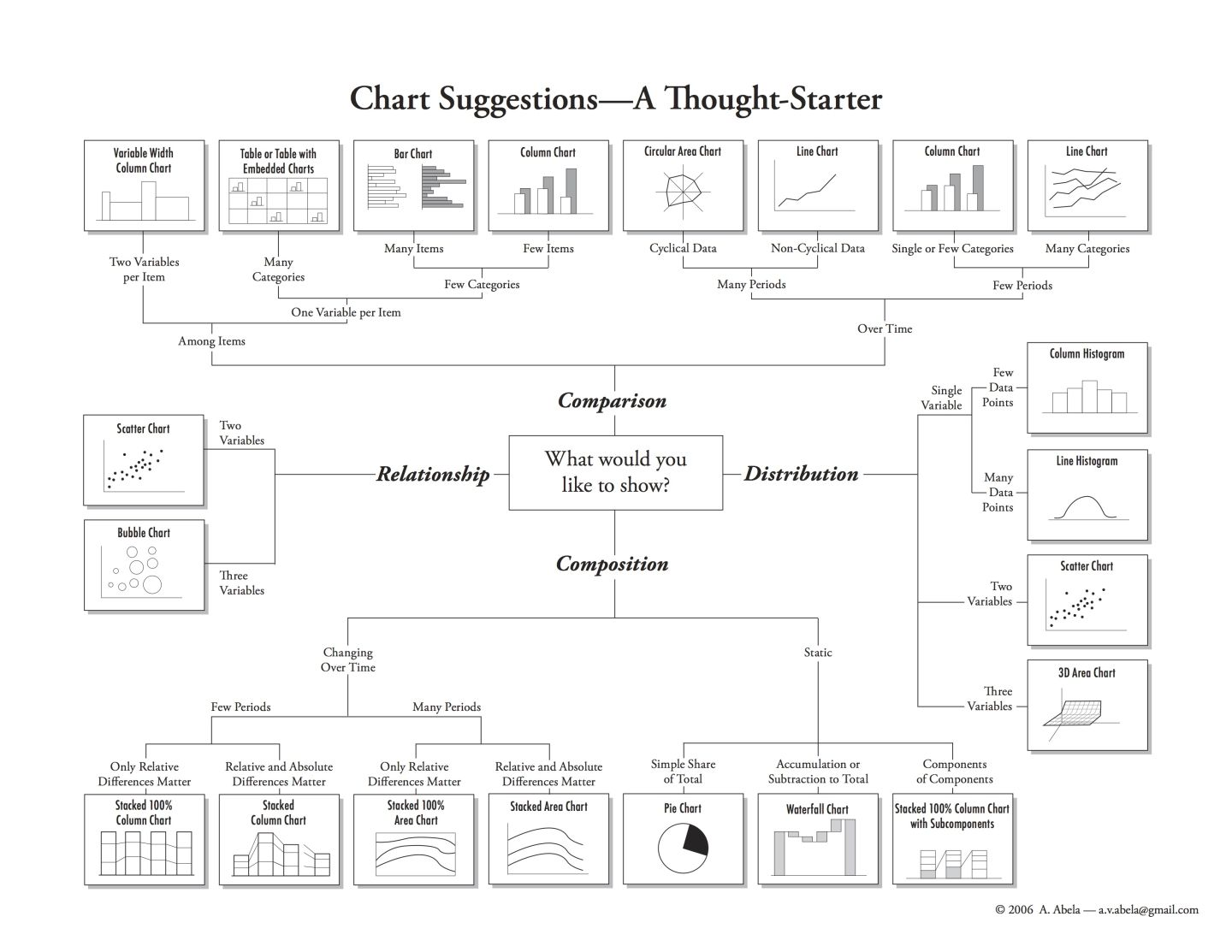
步骤
- 第一印象:df.head() ---> 看index是什么,column names是什么,看每个特征里面有哪些值,哪些是数值还是字符型等等
- 看数据的整体情况:df.shape,df.dtypes,df.info(),df.describe() 【profile data数据质量】
- 检查缺省值,异常值,重复值等预处理操作的可能数据问题 【wrangle data清理数据】
- 探索每个变量的统计分布 【individual variable单独数据的分布】
- 分析方法:单变量峰度和偏度分析(左偏还是右偏)/直接plot视觉观察
- 数据变换操作:取log
- 确定自变量(variable)和应变量(target),并探索两个变量之间的关系---->可以用heatmap/scatter plot【relationship】
- 确定自变量之间的关系(variable)---->可以用heatmap/scatter plot【relationship】
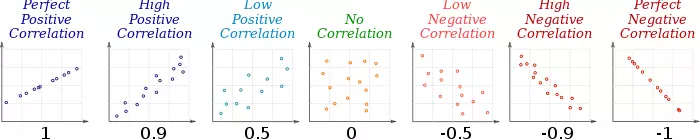
- 数据按不同维度切分成新表---->比如同一国家(地理),同一时间段(时间)等等
小结
关键在于有对于数据domain的知识,按照步骤分析,并且适当的建立新的特征。pandas,seaborn的具体应用待做。
联系方式:clarence_wu12@outlook.com

