MapReduce 基础学习
一、什么是MapReduce?
-
mapreduce 是一种软件框架
-
mapreduce job将任务分解为独立的块儿到不同的 map task,进行并行处理;
-
map 任务输出会做相应的排序处理,并作为 reduce 任务输入;
-
框架能很好的处理定时任务,进行监控并能够重新执行失败的任务。
二、计算和存储:mapreduce 和 haddoop:
通常来讲,计算节点和存储节点是同一个,即 mapreduce 框架和 hadoop 分布式文件系统运行在相同的节点集群,使得任务调度更加高效,网络带宽更聚合。
mapreduce 框架包括一个单一的 ResourceManager,每个集群节点一个 NodeManager,每个应用一个 MRAppMaster 节点。
三、基本使用:
=》客户应用设置输入和输出位置
=》提供实现 map 和 reduce 方法
=》haddoop 任务客户端提交任务,同时向 ResourceManager 提交配置。
ResourceManager 负责将提交的任务配置项从节点分发,调度任务,监控任务,向客户端提供任务状态及诊断信息。
四、数据形式:
mapreduce 框架以 k-v 形式操作数据,输入输出处理;
-
key 和 value 需要被序列化,通过实现 Writable 接口,以支持序列化;
-
key 对象还需要实现 WritableComparable 接口,以支持排序需求。
-
基本处理流程:(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
五、Mapper:
将输入的 k-v 键值对映射转换到中间 k-v 键值对,转换为单独的任务,中间类型和输入类型可以不同,一个输入键值对可能映射转换为0个或多个输出键值对。
map结果并不直接存储磁盘,会利用缓存做一些与排序处理,调用 combiner,压缩,按 key 分区,排序等,尽量减少结果的大小。map 完成后通知 task,reduce 进行处理。
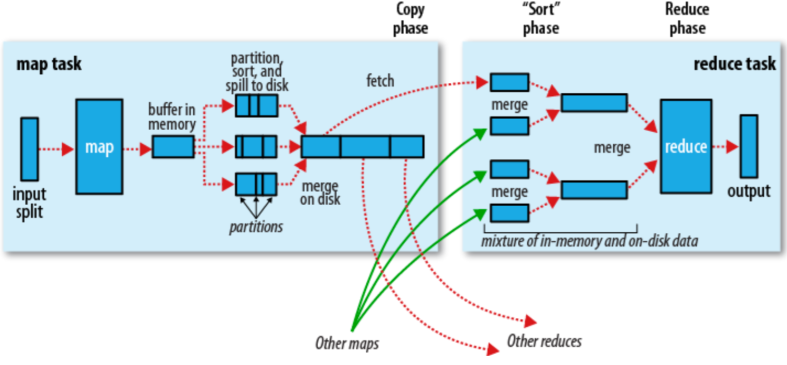
-
每个map拥有一个循环内缓冲区(默认100m),容量达到80%,则后台线程开始将内容写入磁盘文件,不妨碍 map 继续写入缓冲,缓冲区满,则等待。
-
写文件使用round-robin方式,写入文件前,将数据按照reduce分区,对于每个分区,根据 key 排序,可能的话,执行 combiner 操作。
-
每次到达缓冲区阈值,都会创建一个文件,map 结束前,会执行文件合并(数量不超过3个)和排序。或者压缩(减少数据大小)。
-
如果从未达到阈值,则不创建文件,直接使用内存。这样最高效。配置可能合适大小的缓冲区(io.file.buffer.size,默认4kb)。
-
map完成,通知任务管理器,reduce可以开始复制结果数据进行使用。
六、Reducer:
结果写入到 hdfs 中,归并处理为小批量结果
-
shuffle:从 mapper 获取相关的结果,排序输出到 reduce,http。分配尽可能多的内存
-
sort:将 reduce 的输入分组
-
reduce:执行 reduce 方法,处理输入;reduce 的数量应为0.95~1.75*节点数。0.95使得所有的 reduce 可以被全部启动执行;1.75使得执行最快的节点开始执行第二轮,第三轮...;数值越大,负载越大,增加了负载均衡需求,降低了失败成本;reducetask 设置为0,则直接跳过 reduce 阶段,map结果直接输出到 FileSystem 中
哈希分区是默认的分区类型:HashPartitioner is the default Partitioner.
七、job:
提交任务,跟踪处理,访问任务报告,日志获取 mapreduce 集群状态。
job 提交过程:
-
检查输入输出
-
计算 InputSplit values
-
为 DistributedCache 设置必要的计算信息
-
复制jar及配置到 mapreduce 系统文件夹
-
提交任务到 ResourceManager,监控状态
八、InputSplit:
-
代表一个逻辑分片,并没有真正的存储数据,提供了如何将数据分片的方法。
-
内部有 Location 信息,利于数据局部化。
-
一个 InputSplit 给一个单独的 map 处理
-
mapper 处理的键值对象,默认为 FileSplit。
-
byte-oriented view;由 RecordReader 处理成 record-oriented view。
通常一个 split 对应一个 block,使得 map 可以在存储由当前数据的节点上运行当本地任务,不需要通过网络跨节点调度任务。
大小配置: mapred.min.split.size, mapred.max.split.size, block.size
获取文件在 hdfs 上的路径及 block 信息,根据 splitsize 对文件进行切分,默认splitsize = blocksize = 64m
九、RecordReader:
将InputSplit 拆分为k-v 键值对。
CombineFileInputFormat:将若干个 InputSplit 打包,避免过多的 map 任务(split 数目决定了 map 任务数),
OutputFormat:验证输出配置;写输出文件。
DistributedCache 是 mapreduce 提供的一项机制,用于缓存应用需要的文件(文本,压缩包,jar等)
应用通过url(hdfs://url)配置需要缓存的文件;DistributedCache 嘉定需要缓存的文件都已经在FileSystem中。
在从节点执行任务之前,mapreduce会将需要的文件拷贝到相应节点,
DistributedCache会跟踪相应文件的更改时间戳,缓存的文件在任务运行期间不可以被应用或者外部更改。
DistributedCache可以被用作文件分发。运行jar,配置等
mapreduce.job.cache.file=file1,file2
mapreduce.job.cache.archive=
private:本地私有文件;针对相应的job使用;public:公共全局文件夹,被所有任务共享使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号