
redis主从复制、主从延迟知几何
本篇章节主要从 redis 主从复制延迟相关知识及影响因素做简要论述。
1、配置:repl-disable-tcp-nodelay

也即是TCP 的 TCP_NODELAY 属性,决定数据的发送时机。
配置关闭:主节点产生的数据无论大小都会及时的发送给从节点。redis默认关闭此配置,以保障较小的主从延迟。当然,这需要主从间保持较好的网络状况。
配置打开:主节点会合并较小的TCP数据包以节省宽带,默认发送时间间隔由linux内核设置决定,默认一般40ms。虽然这样大大增加了主从之间的延迟,但是对于网络状况达不到条件或者对主从延迟不敏感的情况比较适用。
在实际应用中,我们可能也会遇到需要异地机房部署主从的情景,因此需要充分考虑对数据更新及时性及数据本身变动特性来决定具体的架构模式。
2、复制偏移量:master_repl_offset | slave_repl_offset
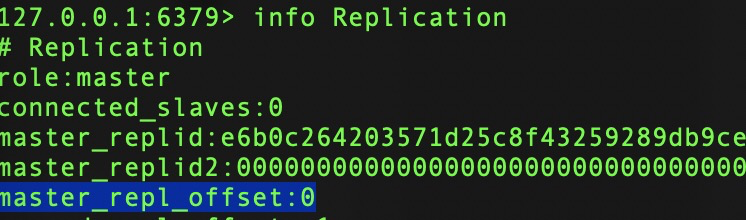
参与复制角色自身维护的复制偏移量。
主节点每次处理完写操作,会把命令的字节长度累加到master_repl_offset中。
从节点在接收到主节点发送的命令后,会累加记录子什么偏移量信息slave_repl_offset,同时,也会每秒钟上报自身的复制偏移量到主节点,以供主节点记录存储。
在实际应用中,可以通过对比主从复制偏移量信息来监控主从复制健康状况。
3、复制积压缓冲:repl_backlog_*
关于redis内存分析,内存优化 介绍过复制积压缓冲内存占用,主节点保持的一个固定长度队列,默认大小1M,当主节点有从节点连接时,主节点在把写操作发送给从节点的同时,也会写入一份到复制积压缓冲区。

复制积压缓冲队列,先进先出,主要用于增量复制及丢失命令补救等。
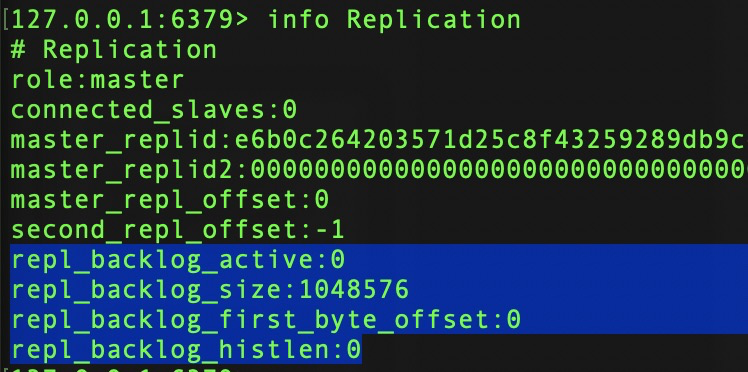
repl_backlog_active:0 | 1 关闭 | 开启复制积压缓冲区标志
repl_backlog_size:缓冲区最大长度
repl_backlog_first_byte_offset:缓冲区起始偏移量
repl_backlog_hislen:已存储的数据长度。
可用偏移量范围:[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset + repl_backlog_hislen]
4、redis 实例运行id:run_id:
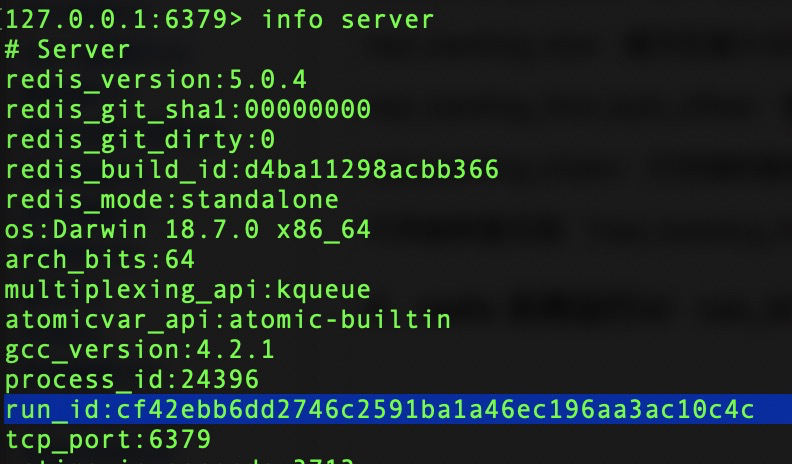
用以网络中唯一标识区别redis运行实例。
需要注意的是redis重启之后run_id会随之改变,如下:

通常我们需要同一个redis实例保持唯一不变的运行ID,以保障主从复制数据安全性。
在需要重新加载配置时通常可以通过执行 debug reload 命令操作:

需要注意的是,debug reload 是阻塞操作,执行时首先生成本地RDB快照,然后清空数据再加载RDB数据。
5、主从复制:sync | psync
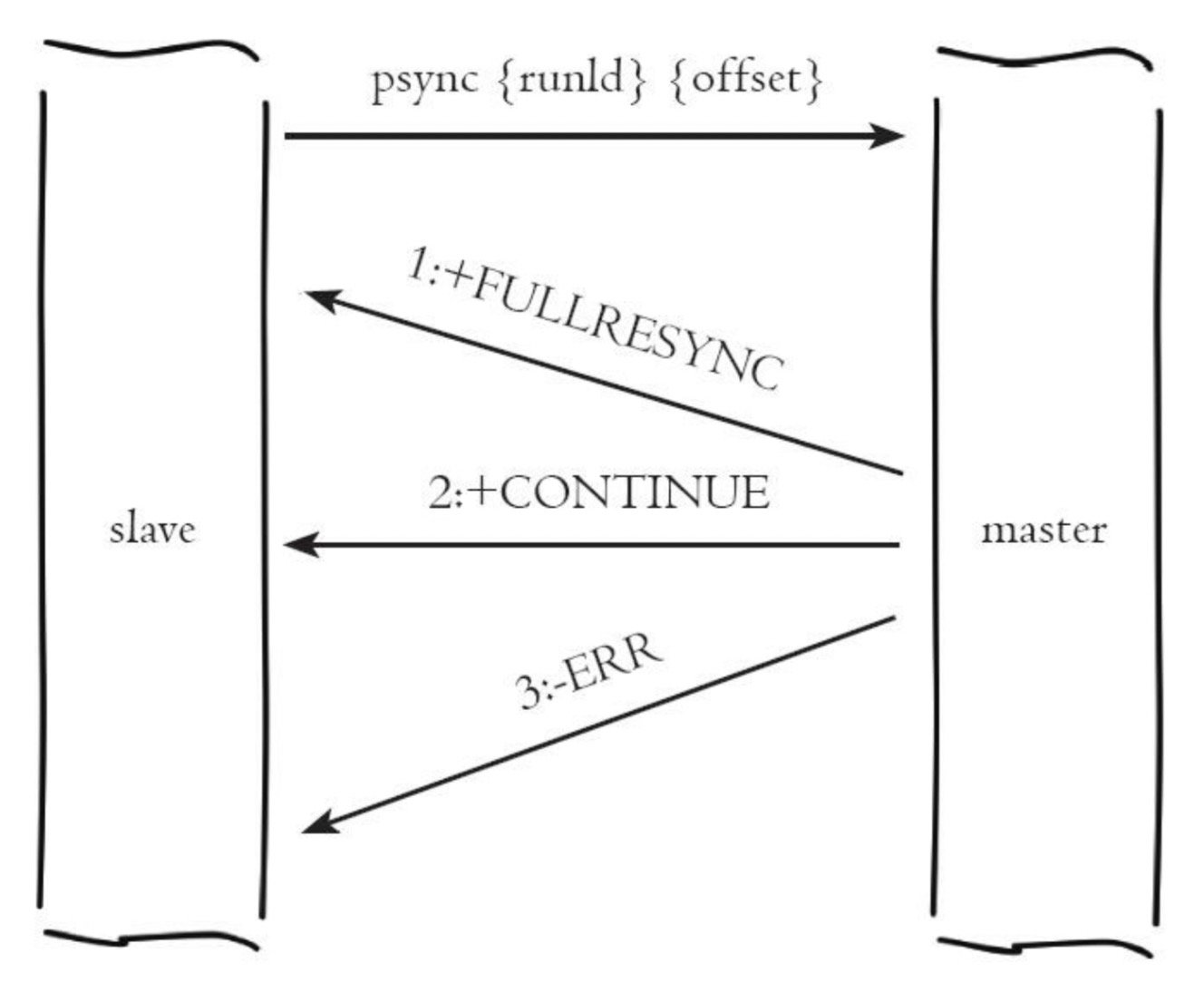
run_id就是上面我们所说的run_id,offset则是复制偏移量。
psync是v2.8版本之后的命令。
FULLRESYNC:全量复制
CONTINUE:部分复制
ERR:从节点版本限制无法识别psync命令。
全量复制:

部分复制:
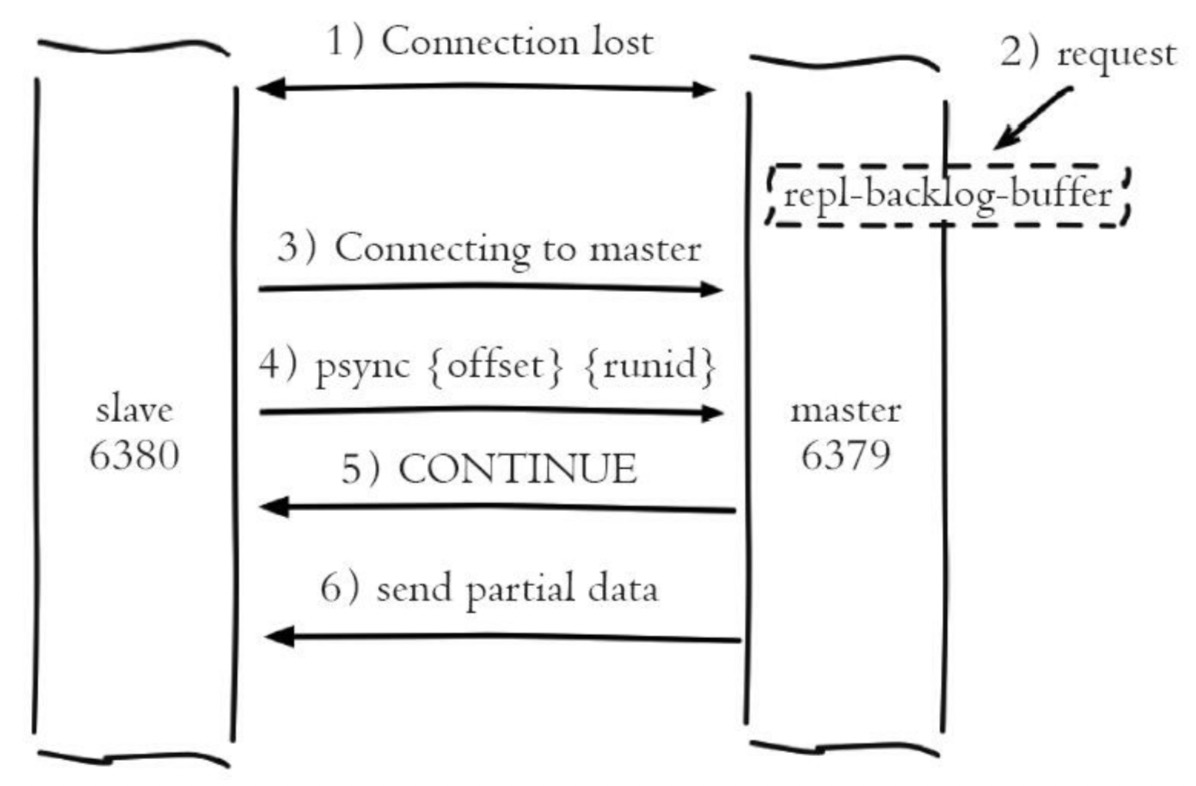
6、主从心跳
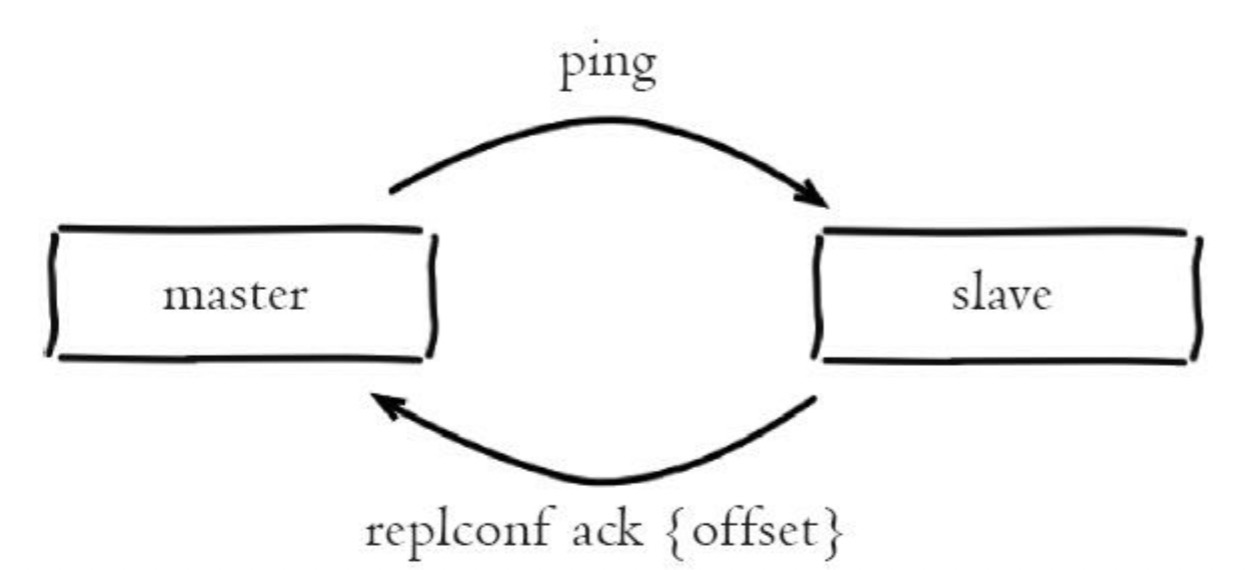
主从之间维持长连接发送信条信息。
主节点每隔10s发送ping命令检测从节点存活。配置:repl-ping-slave-period
![]()
从节点每隔1s发送 repconfig 命令,上报复制偏移量。
关于repconfig:
实时检测主从节点网络状况。
上报复制偏移量,检查数据复制状况。
维护从节点数据量(min-slaves-to-write)及延迟性功能(min-slaves-max-lag)。
7、附加订阅

