


算法 排序lowB三人组 冒泡排序 选择排序 插入排序
参考博客:基于python的七种经典排序算法 [经典排序算法][集锦] 经典排序算法及python实现
首先明确,算法的实质 是 列表排序。具体就是操作的列表,将无序列表变成有序列表!
一、排序的基本概念和分类
所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。排序算法,就是如何使得记录按照要求排列的方法。
排序的稳定性:
经过某种排序后,如果两个记录序号同等,且两者在原无序记录中的先后秩序依然保持不变,则称所使用的排序方法是稳定的,反之是不稳定的。
内排序和外排序
内排序:排序过程中,待排序的所有记录全部放在内存中
外排序:排序过程中,使用到了外部存储。
通常讨论的都是内排序。
影响内排序算法性能的三个因素:
- 时间复杂度:即时间性能,高效率的排序算法应该是具有尽可能少的关键字比较次数和记录的移动次数
- 空间复杂度:主要是执行算法所需要的辅助空间,越少越好。
- 算法复杂性。主要是指代码的复杂性。
根据排序过程中借助的主要操作,可把内排序分为:
- 插入排序
- 交换排序
- 选择排序
- 归并排序
按照算法复杂度可分为两类:
- 简单算法:包括冒泡排序、简单选择排序和直接插入排序
- 改进算法:包括希尔排序、堆排序、归并排序和快速排序
排序lowB三人组
为什么叫排序lowB三人组呢?因为冒泡排序,选择排序,插入排序 这三个经典算法时间复杂度都是O(n2)。空间复杂度为O(1)。
冒泡排序 Bubble sort
介绍:
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
核心:
原理是临近的数字两两进行比较,如果反序则交换,直到没有反序记录为止。按照从小到大或者从大到小的顺序进行交换。
以从小到大排序为例:
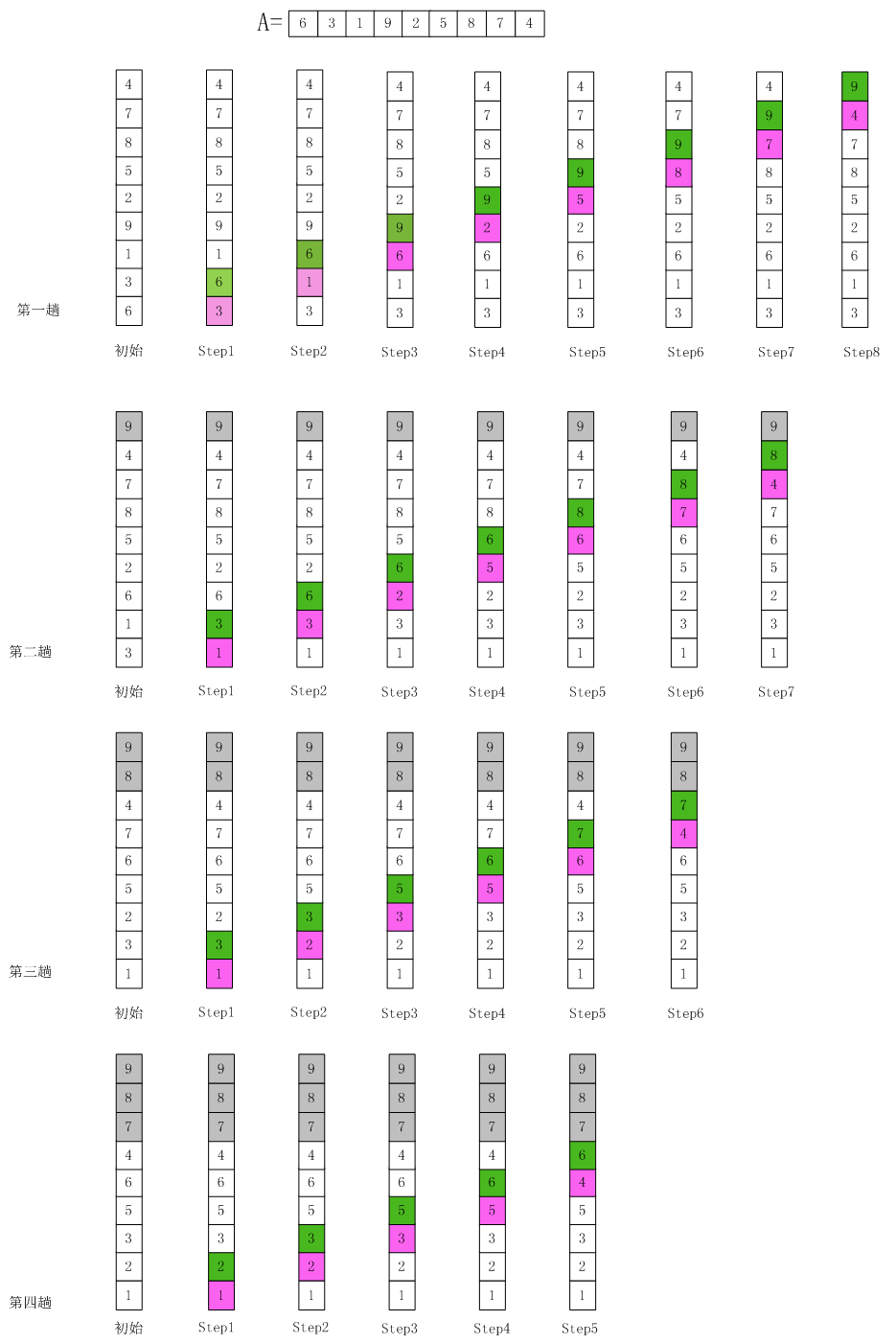
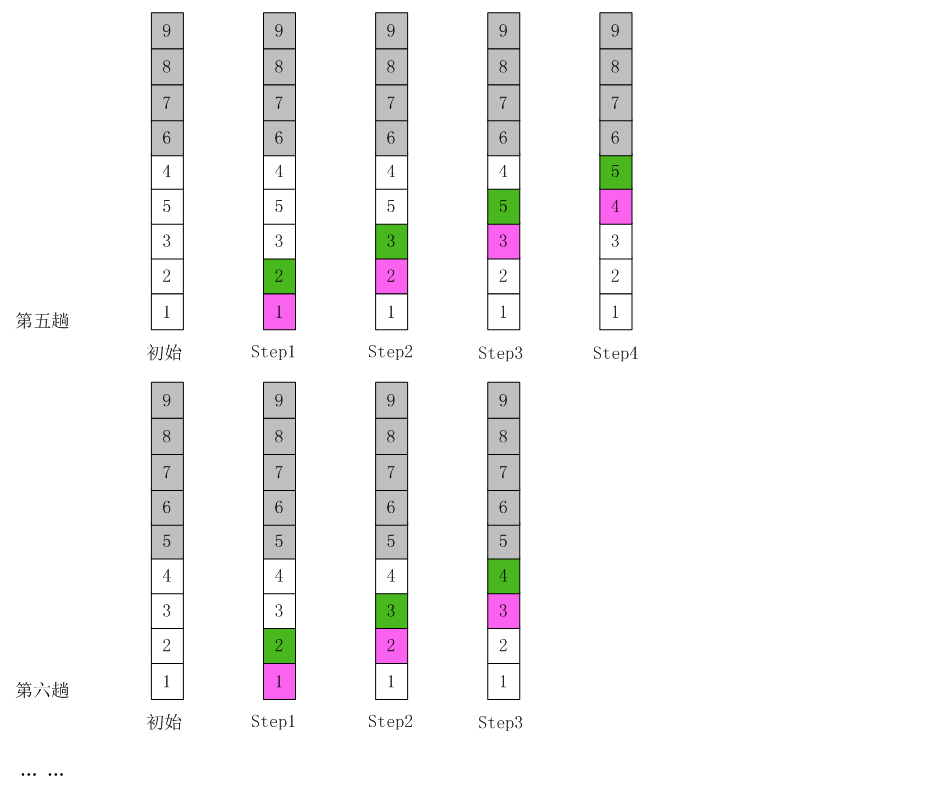
冒泡排序动画演示

算法实现
'''
冒泡排序
'''
def Dubble_sort(a):
"""
两数相比较,非相邻
"""
for i in range(len(a)):
for j in range(i+1,len(a)):
if a[i] > a[j]:
a[i],a[j] = a[j],a[i]
return a
def bubble_sort(li):
"""
两数相比较,相邻
"""
for i in range(len(li)-1):
for j in range(len(li)-i-1):
if li[j] > li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
return li
#冒泡排序-优化
#如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。
def bubble_sort_1(li):
for i in range(len(li)-1):
exchange = False
for j in range(len(li)-i-1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
return
return li
选择排序 Selection sort
介绍:
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
另一种解释就是,直接从待排序数组里选择一个最小(或最大)的数字,每次都拿一个最小数字出来,顺序放入新数组,直到全部拿完。再简单点,对着一群数组说:你们谁最小出列,站到最前边;然后继续对剩余的无序数组说:你们谁最小出列,站到刚才那位的后边;再继续刚才的操作,一直到最后一个。现在数组有序了,从小到大
选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)。
通俗的说就是,对尚未完成排序的所有元素,从头到尾比一遍,记录下最小的那个元素的下标,也就是该元素的位置。再把该元素交换到当前遍历的最前面。其效率之处在于,每一轮中比较了很多次,但只交换一次。因此虽然它的时间复杂度也是O(n^2),但比冒泡算法还是要好一点。
思路:
一趟遍历记录最小的数,放到第一个位置;
再一趟遍历记录剩余列表中最小的数,继续放置;
假如,有一个无须序列A=[6,3,1,9,2,5,8,7,4],选择排序的过程应该如下:
第一趟:选择最小的元素,然后将其放置在数组的第一个位置A[0],将A[0]=6和A[2]=1进行交换,此时A=[1,3,6,9,2,5,8,7,4];
第二趟:由于A[0]位置上已经是最小的元素了,所以这次从A[1]开始,在剩下的序列里再选择一个最小的元素将其与A[1]进行交换。即这趟选择过程找到了最小元素A[4]=2,然后与A[1]=3进行交换,此时A=[1,2,6,9,3,5,8,7,4];
第三趟:由于A[0]、A[1]已经有序,所以在A[2]~A[8]里再选择一个最小元素与A[2]进行交换,然后将这个过程一直循环下去直到A里所有的元素都排好序为止。这就是选择排序的精髓。因此,我们很容易写出选择排序的核心代码部分,即选择的过程,就是不断的比较、交换的过程。
整个选择的过程如下图所示:
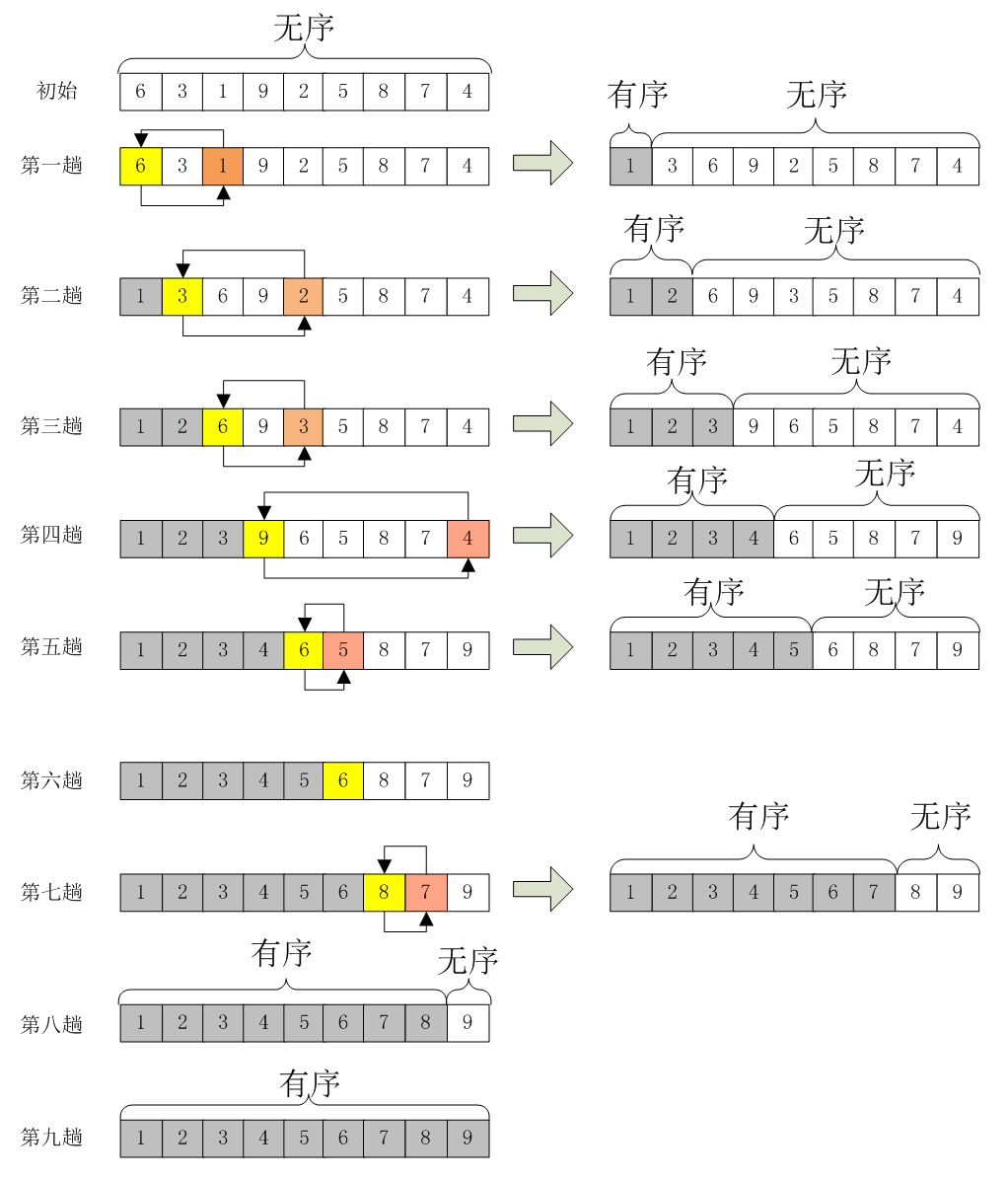
选择排序动画展示:

算法实现:
'''
选择排序
'''
def select_sort(li):
for i in range(len(li) - 1):
min_loc = i
for j in range(i+1, len(li)):
if li[j] < li[min_loc]:
min_loc = j
if min_loc != i:
li[i], li[min_loc] = li[min_loc], li[i]
return li
插入排序 Insertion sort
介绍:
有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法。
插入排序的基本操作就是将一个数据插入到已经排好序的有序数组中,从而得到一个新的、个数加一的有序数组,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。
插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
总结如下:
0、可以形象的理解为整理扑克牌!假设你拿到手的一套顺序很乱的牌,当你梳理的时候就想当于是在做 插入排序 操作。
1、插入排序就是每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕。
2、把列表分为有序区和无序区两个部分。最初有序区只有一个元素。
3、每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空。
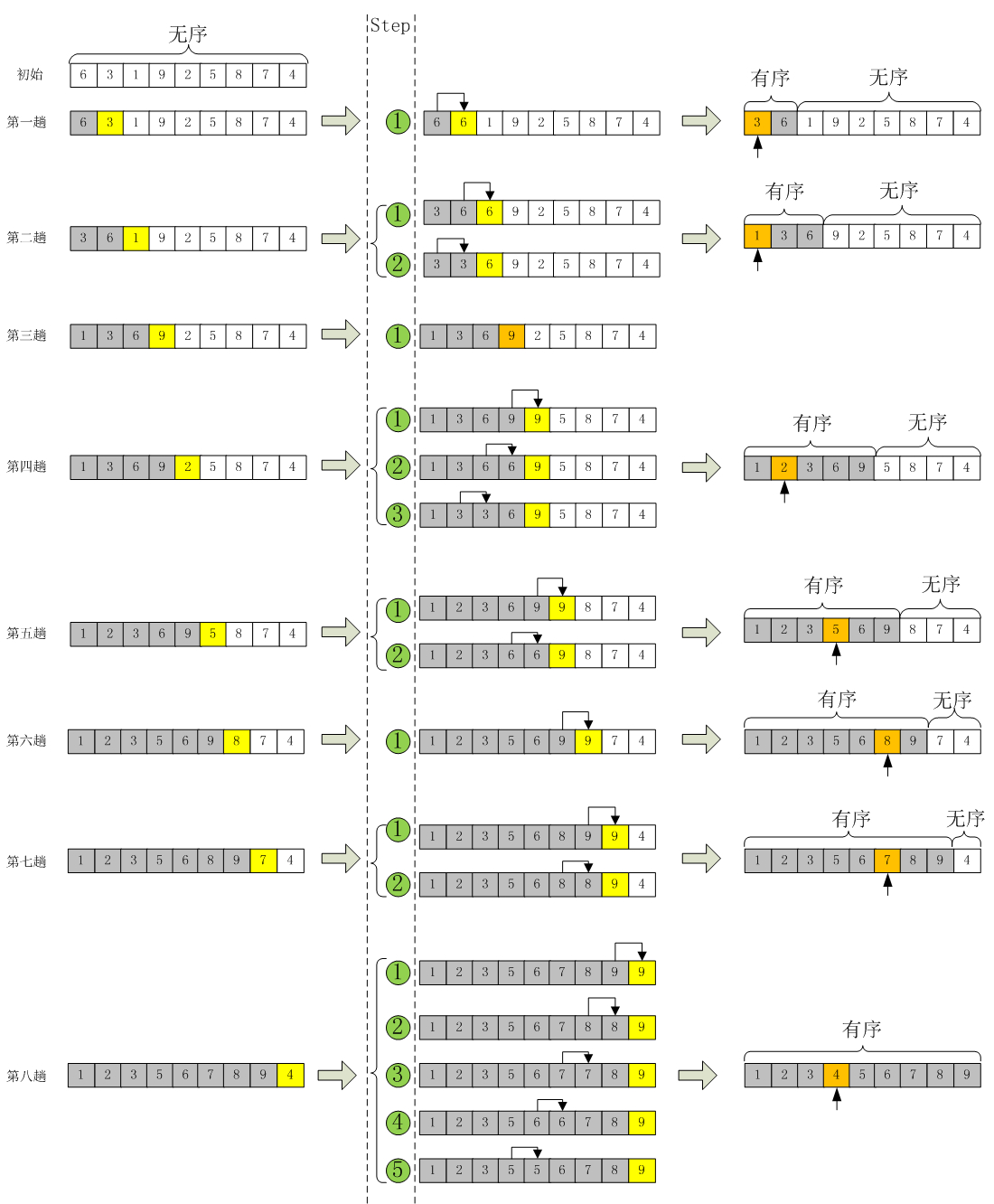
算法实现:
"""
插入排序 (一般都会选取第一个数为起始数,同时索引查找也不能越界)
"""
def insert_sort(li):
"""
数据换来换取的方法
"""
for i in range(1, len(li)):
tmp = li[i]
j = i - 1
while j >= 0 and tmp < li[j]:
li[j + 1] = li[j]
j = j - 1
li[j + 1] = tmp
return li
def Insertion_sort(a):
"""
按照索引插来插去的办法
"""
for i in range(1,len(a)):
j = i
while j>0 and a[j-1]>a[i]:
j -= 1
a.insert(j,a[i])
a.pop(i+1)
return a
该算法需要一个记录的辅助空间。最好情况下,当原始数据就是有序的时候,只需要一轮对比,不需要移动记录,此时时间复杂度为O(n)。然而,这基本是幻想。

