

ORM框架
1.ORM框架:SQLALchemy
sqkalchemy是python编程语言下的一款ORM框架,该框架建立在数据库API上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
安装:pip3 install SQLAlchemy
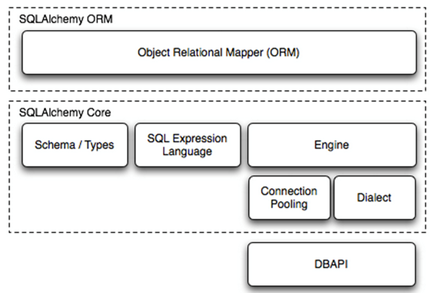
SQLalchemy本身无法操作数据库,其必须依赖pymsql等第三方插件。Dialect用于和数据API进行交流,
根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
pymysql:
mysql+pymsql://<username>:<password>@<host>/<dbname>[?<options>]
mysql+pymysql://root:@localhost:3306/db3?charset=utf8", max_overflow=5
作用:提供简单的规则、自动转换成SQL语句
-DB first:手动创建数据库以及表 ->ORM框架 –>自动生成类
-code first:手动创建类和数据库 ->ORM框架 –>以及表
2.ORM功能使用
-创建数据库表 -连接数据库 -类转换SQL语句 -操作数据行
1、创建表: 类--->是表 对象---->是数据行


from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,ForeignKey,UniqueConstraint,Index,CHAR,VARCHAR from sqlalchemy.orm import sessionmaker,relationship from sqlalchemy import create_engine Base=declarative_base() #创建表单 class UserType(Base): #继承Base类 __tablename__="usertype" id=Column(Integer,primary_key=True,autoincrement=True) title=Column(VARCHAR(32),nullable=True,index=True) user_type=relationship("UserType",backref="xx") #正向 #relationship 谁有外键加谁旁边 class Users(Base): #继承Base类 __tablename__="users" id=Column(Integer,primary_key=True,autoincrement=True) name=Column(VARCHAR(32),nullable=True,index=True) email=Column(VARCHAR(16),unique=True) user_type_id=Column(Integer,ForeignKey("usertype.id")) #建立索引值及联合唯一索引值 规则让这么写 # __table_args__ = ( # UniqueConstraint('id', 'name', name='uix_id_name'), # Index('ix_n_ex','name', 'email',), # ) engine=create_engine("mysql+pymysql://root:@localhost:3306/db3?charset=utf8",max_overflow=5) #找到所有继承Base的类,类—SQL语句在数据库创建表 # Base.metadata.create_all(engine) #找到所有继承Base的类,类—SQL语句在数据库删除表 # Base.metadata.drop_db(engine) #操作数据行:去引擎获取一个连接 Session=sessionmaker(bind=engine) session=Session()
2、操作表
增:
# obj1=UserType(title="普通用户") # session.add(obj1) #********多行增加******* objs=[ UserType(title="超级用户"), UserType(title="白金用户"), UserType(title="黑金用户") ] session.add_all(objs) session.commit()
查:
# *******查********* # print(session.query(UserType)) # user_type_list=session.query(UserType).all() #查看并取到用户信息 # for row in user_type_list: # print(row.id,row.title) #按照条件查询 # user_type_list=session.query(UserType.id,UserType.title).filter(UserType.id>1) # for row in user_type_list: # print(row.id,row.title)
删:
# *******删******* session.query(UserType.id,UserType.title).filter(UserType.id>2).delete() session.commit()
改:
# *******修改******* # session.query(UserType.id,UserType.title).filter(UserType.id>0).update({"title":"黑金"}) #第第一种修改 # session.query(UserType.id,UserType.title).filter(UserType.id>0).update({UserType.title:UserType.title+"x"}, # synchronize_session=False) #与前面的数据是一致,类型不一样,操作不一样 #session.query(UserType.id,UserType.title).filter(UserType.id>0).update({"num:Users.num+1},synchronize_session="evaluate") session.commit()
其他:
#条件 ret = session.query(Users).filter(Users.id.in_([1,3,4])).all() ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all() from sqlalchemy import and_, or_ ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() ret = session.query(Users).filter( or_( Users.id < 2, and_(Users.name == 'eric', Users.id > 3), Users.extra != "" )).all() # 通配符 ret = session.query(Users).filter(Users.name.like('e%')).all() ret = session.query(Users).filter(~Users.name.like('e%')).all() ~ 取非 # 分页 ret = session.query(Users)[1:2] # 排序 ret = session.query(Users).order_by(Users.name.desc()).all() ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() #分组 from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() #连表 # ret=session.query(Users).join(UserType) #第一种连表 inner join # print(ret # ret=session.query(Users).join(UserType,isouter=True) # 第二种 left join # print(ret) # 组合 q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union_all(q2).all()
#问题1:获取用户信息以及其关联的用户类型名称 FK,Relationship=>正向操作) # user_list=session.query(Users) # for row in user_list: # print(row.name,row.id,row.user_type.title)
# 问题2:获取用户类型 backref=’xx’ # type_list=session.query(UserType) # for row in type_list: #print(row.id,row.title,row.xx)

