TypeScript入门与实践-读书笔记
TypeScript类型基础
类型注解
使用类型注解来明确标识类型。类型注解的语法由一个冒号“:”和某种具体类型“Type”组成;
:Type
TypeScript中的类型注解总是放在被修饰的实体之后;
TypeScript中的类型注解是可选的,编译器在大部分情况下都能够自动推断出表达式的类型。
const greeting: string = 'Hello, World!';
const greeting = 'Hello, World!';
类型检查
类型检查是验证程序中类型约束是否正确的过程。类型检查既可以在程序编译时进行,即静态类型检查;也可以在程序运行时进行,即动态类型检查。TypeScript支持静态类型检查,JavaScript支持动态类型检查。
为了满足不同用户的需求,TypeScript提供了两种静态类型检查模式:
- 非严格类型检查(默认方式)
- 严格类型检查
非严格类型检查
非严格类型检查是TypeScript默认的类型检查模式。在该模式下,类型检查的规则相对宽松。
例如,在非严格类型检查模式下不会对undefined值和null值做过多限制,允许将undefined值和null值赋值给string类型的变量。
当进行JavaScript代码到TypeScript代码的迁移工作时,非严格类型检查是一个不错的选择,因为它能够让我们快速地完成迁移工作。
严格类型检查
该模式下的类型检查比较激进,会尽可能地发现代码中的错误。
例如,在严格类型检查模式下不允许将undefined值和null值赋值给string类型的变量。
启用严格类型检查模式能够最大限度地利用TypeScript静态类型检查带来的益处。从长远来讲,使用严格类型检查模式对提高代码质量更加有利,因此建议在新的工程中启用严格类型检查。
从长远来讲,使用严格类型检查模式对提高代码质量更加有利,因此建议在新的工程中启用严格类型检查。
TypeScript提供了若干个与严格类型检查相关的编译选项,例如“--strictNullChecks”和“--noImplicitAny”等。关于严格类型检查编译选项的详细介绍请参考 “编译选项”。
原始类型
JavaScript语言中的每种原始类型都有与之对应的TypeScript类型。除此之外,TypeScript还对原始类型进行了细化与扩展,增加了枚举类型和字面量类型等。
TypeScript中的原始类型包含以下几种:
- boolean
- string
- number
- bigint
- symbol
- undefined
- null
- void
- 枚举类型
- 字面量类型
boolean
TypeScript中的boolean类型对应于JavaScript中的Boolean原始类型。该类型能够表示两个逻辑值:true和false。
// boolean类型使用boolean关键字来表示
const yes: boolean = true
const no: boolean = false;
string
TypeScript中的string类型对应于JavaScript中的String原始类型。
该类型能够表示采用Unicode UTF-16编码格式存储的字符序列。
string类型使用string关键字表示。我们通常使用字符串字面量或模板字面量来创建string类型的值。
const foo: string = 'foo';
const bar: string = `bar, ${foo}`;
number
TypeScript中的number类型对应于JavaScript中的Number原始类型。
该类型能够表示采用双精度64位二进制浮点数格式存储的数字。
// 二进制数
const bin: number = 0b1010;
// 八进制数
const oct: number = 0o744;
// 十进制数
const integer: number = 10;
const float: number = 3.14;
// 十六进制数
const hex: number = 0xffffff;
bigint
TypeScript中的bigint类型对应于JavaScript中的BigInt原始类型。
该类型能够表示任意精度的整数,但也仅能表示整数。
bigint采用了特殊的对象数据结构来表示和存储一个整数。
// bigint类型使用bigint关键字来表示。
// 二进制整数
const bin: bigint = 0b1010n;
// 八进制整数
const oct: bigint = 0o744n;
// 十进制整数
const integer: bigint = 10n;
// 十六进制整数
const hex: bigint = 0xffffffn;
symbol与unique symbol
TypeScript中的symbol类型对应于JavaScript中的Symbol原始类型。
该类型能够表示任意的Symbol值。
// symbol类型使用symbol关键字来表示
// 自定义Symbol
const key: symbol = Symbol();
// Well-Known Symbol
const symbolHasInstance: symbol = Symbol.hasInstance;
字面量能够表示一个固定值。例如,数字字面量“3”表示固定数值“3”;字符串字面量“'up'”表示固定字符串
“'up'”。symbol类型不同于其他原始类型,它不存在字面量形式。symbol类型的值只能通过“Symbol()”和“Symbol.for()”函数来创建或直接引用某个“Well-Known Symbol”值。
const s0: symbol = Symbol();
const s1: symbol = Symbol.for('foo');
const s2: symbol = Symbol.hasInstance;
const s3: symbol = s0;
为了能够将一个Symbol值视作表示固定值的字面量,TypeScript引入了“unique symbol”类型。“unique symbol”类型使用“unique symbol”关键字来表示。
const s0: unique symbol = Symbol();
const s1: unique symbol = Symbol.for('s1');
“unique symbol”类型的主要用途是用作接口、类等类型中的可计算属性名。因为如果使用可计算属性名在接口中添加了一个类型成员,那么必须保证该类型成员的名字是固定的,否则接口定义将失去意义。
下例中,允许将“unique symbol”类型的常量x作为接口的类型成员,而symbol类型的常量y不能作为接口的类型成员,因为symbol类型不止包含一个可能值:
const x: unique symbol = Symbol();
const y: symbol = Symbol();
interface Foo {
[x]: string; // 正确
[y]: string;
// ~~~
// 错误:接口中的计算属性名称必须引用类型为字面量类型
// 或'unique symbol'的表达式
}
关于"unique symbol"
实际上,“unique symbol”类型的设计初衷是作为一种变通方法,让一个Symbol值具有字面量的性质,即仅表示一个固定的值。“unique symbol”类型没有改变Symbol值没有字面量表示形式的事实。为了能够将某个Symbol值视作表示固定值的字面量,TypeScript对“unique symbol”类型和Symbol值的使用施加了限制。
TypeScript选择将一个Symbol值与声明它的标识符绑定在一起,并通过绑定了该Symbol值的标识符来表示“Symbol字面量”。这种设计的前提是要确保Symbol值与标识符之间的绑定关系是不可变的。因此,TypeScript中只允许使用const声明或readonly属性声明来定义“unique symbol”类型的值。
// 必须使用const声明
const a: unique symbol = Symbol();
interface WithUniqueSymbol {
// 必须使用readonly修饰符
readonly b: unique symbol;
}
class C {
// 必须使用static和readonly修饰符
static readonly c: unique symbol = Symbol();
}
此例第1行,常量a的初始值为Symbol值,其类型为“uniquesymbol”类型。在标识符a与其初始值Symbol值之间形成了绑定关系,并且该关系是不可变的。这是因为常量的值是固定的,不允许再被赋予其他值。标识符a能够固定表示该Symbol值,标识符a的角色相当于该Symbol值的字面量形式。
如果使用let或var声明定义“unique symbol”类型的变量,那么将产生错误,因为标识符与Symbol值之间的绑定是可变的。
let a: unique symbol = Symbol();
// ~
// 错误:'unique symbol' 类型的变量必须使用'const'
var b: unique symbol = Symbol();
// ~
// 错误:'unique symbol' 类型的变量必须使用'const'
“unique symbol”类型的值只允许使用“Symbol()”函数或“Symbol.for()”方法的返回值进行初始化,因为只有这样才能够“确保”引用了唯一的Symbol值。
const a: unique symbol = Symbol();
const b: unique symbol = Symbol('desc');
const c: unique symbol = a;
// ~
// 错误:a的类型与c的类型不兼容
const d: unique symbol = b;
// ~
// 错误:b的类型与d的类型不兼容
但是,我们知道使用相同的参数调用“Symbol.for()”方法实际上返回的是相同的Symbol值。因此,可能出现多个“unique symbol”类型的值实际上是同一个Symbol值的情况。由于设计上的局限性,TypeScript目前无法识别出这种情况,因此不会产生编译错误,开发者必须要留意这种特殊情况。
const a: unique symbol = Symbol.for('same');
const b: unique symbol = Symbol.for('same');
此例中,编译器会认为a和b是两个不同的Symbol值,而实际上两者是相同的。
在设计上,每一个“unique symbol”类型都是一种独立的类型。在不同的“unique symbol”类型之间不允许相互赋值;在比较两个“unique symbol”类型的值时,也将永远返回false。
const a: unique symbol = Symbol();
const b: unique symbol = Symbol();
if (a === b) {
// ~~~~~~~
// 该条件永远为false
console.log('unreachable code');
}
由于“unique symbol”类型是 symbol类型的子类型,因此可以将“unique symbol”类型的值赋值给symbol类型。
如果程序中未使用类型注解来明确定义是symbol类型还是“unique symbol”类型,那么TypeScript会自动地推断类型。
// a和b均为'symbol'类型,因为没有使用const声明
let a = Symbol();
let b = Symbol.for('');
// c和d均为'unique symbol'类型
const c = Symbol();
const d = Symbol.for('');
// e和f均为'symbol'类型,没有使用Symbol()或Symbol.for()初始化
const e = a;
const f = a;
Nullable
TypeScript中的Nullable类型指的是值可以为undefined或null的类型。
JavaScript中有两个比较特殊的原始类型,即Undefined类型和Null类型。两者分别仅包含一个原始值,即undefined值和null值,它们通常用来表示某个值还未进行初始化。
在TypeScript早期的版本中,没有提供与JavaScript中Undefined类型和Null类型相对应的类型。TypeScript允许将undefined值和null值赋值给任何其他类型。虽然在TypeScript语言的内部实现中确实存在这两种原始类型,但是之前没有将它们开放给开发者使用。
TypeScript 2.0版本的一个改变就是增加了undefined类型和null类型供开发者使用。
现在,在TypeScript程序中能够明确地指定某个值的类型是否为undefined类型或null类型。TypeScript编译器也能够对代码进行更加细致的检查以找出程序中潜在的错误。
undefined
undefined类型只包含一个可能值,即undefined值。undefined类型使用undefined关键字标识。
const foo: undefined = undefined;
null
null类型只包含一个可能值,即null值。null类型使用null关键字标识。
const foo: null = null;
--strictNullChecks
TypeScript 2.0还增加了一个新的编译选项“--strictNullChecks”,即严格的null检查模式。虽然该编译选项的名
字中只提及了null,但实际上它同时作用于undefined类型和null类型的类型检查。
在默认情况下,“--strictNullChecks”编译选项没有被启用。这时候,除尾端类型外的所有类型都是Nullable类型。也就是说,除尾端类型外所有类型都能够接受undefined值和null值。
在没有启用“--strictNullChecks”编译选项时,允许将undefined值和null值赋值给string类型等其他类型。
/**
* --strictNullChecks=false
*/
let m1: boolean = undefined;
let m2: string = undefined;
let m3: number = undefined;
let m4: bigint = undefined;
let m5: symbol = undefined;
let m6: undefined = undefined;
let m7: null = undefined;
let n1: boolean = null;
let n2: string = null;
let n3: number = null;
let n4: bigint = null;
let n5: symbol = null;
let n6: undefined = null;
let n7: null = null;
该模式存在一个明显的问题,就是无法检查出空引用的错误。例如,已知某一个变量的类型是string,于是通过访问其length属性来获取该变量表示的字符串的长度。但如果string类型的变量值可以为undefined或null,那么这段代码在运行时将产生错误。
/**
* --strictNullChecks=false
*/
let foo: string = undefined; // 正确,可以通过类型检查
foo.length; // 在运行时,将产生类型错误
// 运行结果:
// Error: TypeError: Cannot read property 'length'
// of undefined
此例中,将undefined值赋值给string类型的变量foo时不会产生编译错误。但是,在运行时尝试读取undefined值的length属性将产生类型错误。这个问题可以通过启用“--strictNullChecks”编译选项来避免。
当启用了“--strictNullChecks”编译选项时,undefined值和null值不再能够赋值给不相关的类型。例如,undefined值和null值不允许赋值给string类型。在该模式下,undefined值只能够赋值给undefined类型;同理,null值也只能赋值给null类型。更严谨的说法(赋值规则)是:undefined值和null值允许赋值给顶端类型(unkown 和 any ),同时undefined值也允许赋值给void类型。
当启用了“--strictNullChecks”编译选项时,undefined类型和null类型是不同的类型,它们必须被区分对待,不能互换使用。
/**
* --strictNullChecks=true
*/
const foo: undefined = null;
// ~~~
// 编译错误!类型 'null' 不能赋值给类型 'undefined'
const bar: null = undefined;
// ~~~
// 编译错误!类型 'undefined' 不能赋值给类型 'null'
枚举类型
枚举类型由零个或多个枚举成员构成,每个枚举成员都是一个命名的常量。
在TypeScript中,枚举类型是一种原始类型,它通过enum关键字来定义
按照枚举成员的类型可以将枚举类型划分为以下三类:
- 数值型枚举
- 字符串枚举
- 异构型枚举
数值型枚举
数值型枚举是最常用的枚举类型,是number类型的子类型,它由一组命名的数值常量构成。
enum Direction {
Up,
Down,
Left,
Right
}
const direction: Direction = Direction.Up;
此例中,我们使用enum关键字定义了枚举类型Direction,它包含了四个枚举成员Up、Down、Left和Right。在使用枚举成员时,可以像访问对象属性一样访问枚举成员。
每个数值型枚举成员都表示一个具体的数字。如果在定义枚举时没有设置枚举成员的值,那么TypeScript将自动计算枚举成员的值。根据TypeScript语言的规则,第一个枚举成员的值为0,其后每个枚举成员的值等于前一个枚举成员的值加1。
在定义数值型枚举时,可以为一个或多个枚举成员设置初始值。对于未指定初始值的枚举成员,其值为前一个枚举成员的值加1。
enum Direction {
Up, // 0
Down, // 1
Left, // 2
Right, // 3
}
enum Direction {
Up = 1, // 1
Down, // 2
Left = 10, // 10
Right, // 11
}
数值型枚举是number类型的子类型,因此允许将数值型枚举类型赋值给number类型。例如,下例中常量direction为number类型,可以使用数值型枚举Direction来初始化direction常量。
enum Direction {
Up,
Down,
Left,
Right
}
const direction: number = Direction.Up;
需要注意的是,number类型也能够赋值给枚举类型,即使number类型的值不在枚举成员值的列表中也不会产生错误。
enum Direction {
Up,
Down,
Left,
Right,
}
const d1: Direction = 0; // Direction.Up
const d2: Direction = 10; // 不会产生错误
字符串枚举
字符串枚举与数值型枚举相似。在字符串枚举中,枚举成员的值为字符串。字符串枚举成员必须使用字符串字面量或另一个字符串枚举成员来初始化。字符串枚举成员没有自增长的行为。
enum Direction {
Up = 'UP',
Down = 'DOWN',
Left = 'LEFT',
Right = 'RIGHT',
U = Up,
D = Down,
L = Left,
R = Right,
}
字符串枚举是string类型的子类型,因此允许将字符串枚举类型赋值给string类型。
但是反过来,不允许将string类型赋值给字符串枚举类型,这一点与数值型枚举是不同的。
enum Direction {
Up = 'UP',
Down = 'DOWN',
Left = 'LEFT',
Right = 'RIGHT',
}
const direction: string = Direction.Up;
enum Direction {
Up = 'UP',
Down = 'DOWN',
Left = 'LEFT',
Right = 'RIGHT',
}
const direction: Direction = 'UP';
// ~~~~~~~~~
// 编译错误!类型 'UP' 不能赋值给类型 'Direction'
异构型枚举
TypeScript允许在一个枚举中同时定义数值型枚举成员和字符串枚举成员,我们将这种类型的枚举称作异构型枚举。
异构型枚举在实际代码中很少被使用,虽然在语法上允许定义异构型枚举,但是不推荐在代码中使用异构型枚举。我们可以尝试使用对象来代替异构型枚举。
enum Color {
Black = 0,
White = 'White',
}
在定义异构型枚举时,不允许使用计算的值作为枚举成员的初始值。
enum Color {
Black = 0 + 0,
// ~~~~~
// 编译错误!在带有字符串成员的枚举中不允许使用计算值
White = 'White',
}
在异构型枚举中,必须为紧跟在字符串枚举成员之后的数值型枚举成员指定一个初始值。
enum ColorA {
Black,
White = 'White',
}
enum ColorB {
White = 'White',
Black,
// ~~~~~
// 编译错误!枚举成员必须有一个初始值
}
枚举成员映射
不论是哪种类型的枚举,都可以通过枚举成员名去访问枚举成员值。
enum Bool {
False = 0,
True = 1,
}
Bool.False; // 0
Bool.True; // 1
对于数值型枚举,不但可以通过枚举成员名来获取枚举成员值,也可以反过来通过枚举成员值去获取枚举成员名。
下例中,通过枚举成员值“Bool.False”能够获取其对应的枚举成员名,即字符串“'False'”
enum Bool {
False = 0,
True = 1,
}
Bool[Bool.False]; // 'False'
Bool[Bool.True]; // 'True'
对于字符串枚举和异构型枚举,则不能够通过枚举成员值去获取枚举成员名。
常量枚举成员与计算枚举成员
每个枚举成员都有一个值,根据枚举成员值的定义可以将枚举成员划分为以下两类:
- 常量枚举成员
- 计算枚举成员
常量枚举成员
若枚举类型的第一个枚举成员没有定义初始值,那么该枚举成员是常量枚举成员并且初始值为0。
若枚举成员没有定义初始值并且与之紧邻的前一个枚举成员值是数值型常量,那么该枚举成员是常量枚举成员并且初始值为紧邻的前一个枚举成员值加1。如果紧邻的前一个枚举成员的值不是数值型常量,那么将产生错误。
enum Foo {
A, // 0
B, // 1
}
enum Bar {
C = 'C',
D, // 编译错误
}
若枚举成员的初始值是常量枚举表达式,那么该枚举成员是常量枚举成员。常量枚举表达式是TypeScript表达式的子集,它能够在编译阶段被求值。常量枚举表达式的具体规则如下:
- 常量枚举表达式可以是数字字面量、字符串字面量和不包含替换值的模板字面量。
- 常量枚举表达式可以是对前面定义的常量枚举成员的引用。
- 常量枚举表达式可以是用分组运算符包围起来的常量枚举表达式。
- 常量枚举表达式中可以使用一元运算符“+” “-” “~”,操作数必须为常量枚举表达式。
- 常量枚举表达式中可以使用二元运算符“+” “-” “*” “**” “/” “%” “<<” “>>” “>>>” “&” “|” “^”,两个操作数必须为常量枚举表达式。
enum Foo {
A = 0, // 数字字面量
B = 'B', // 字符串字面量
C = `C`, // 无替换值的模板字面量
D = A, // 引用前面定义的常量枚举成员
}
enum Bar {
A = -1, // 一元运算符
B = 1 + 2, // 二元运算符
C = (4 / 2) * 3, // 分组运算符(小括号)
}
字面量枚举成员是常量枚举成员的子集。字面量枚举成员是指满足下列条件之一的枚举成员,具体条件如下:
- 枚举成员没有定义初始值。
- 枚举成员的初始值为数字字面量、字符串字面量和不包含替换值的模板字面量。
- 枚举成员的初始值为对其他字面量枚举成员的引用。
enum Foo {
A,
B = 1,
C = -3,
D = 'foo',
E = `bar`,
F = A
}
计算枚举成员
除常量枚举成员之外的其他枚举成员都属于计算枚举成员。
使用示例
枚举表示一组有限元素的集合,并通过枚举成员名来引用集合中的元素。
有时候,程序中并不关注枚举成员值。在这种情况下,让TypeScript去自动计算枚举成员值是很方便的。
enum Direction {
Up,
Down,
Left,
Right,
}
function move(direction: Direction) {
switch (direction) {
case Direction.Up:
console.log('Up');
break;
case Direction.Down:
console.log('Down');
break;
case Direction.Left:
console.log('Left');
break;
case Direction.Right:
console.log('Right');
break;
}
}
move(Direction.Up); // 'Up'
move(Direction.Down); // 'Down'
程序不依赖枚举成员值时,能够降低代码耦合度,使程序易于扩展。例如,我们想给Direction枚举添加一个名为None的枚举成员来表示未知方向。
enum Direction {
None,
Up,
Down,
Left,
Right,
}
function move(direction: Direction) {
switch (direction) {
case Direction.None:
console.log('None');
break;
case Direction.Up:
console.log('Up');
break;
case Direction.Down:
console.log('Down');
break;
case Direction.Left:
console.log('Left');
break;
case Direction.Right:
console.log('Right');
break;
}
}
move(Direction.Up); // 'Up'
move(Direction.Down); // 'Down'
move(Direction.None); // 'None'
此例中,枚举成员Up、Down、Left和Right的值已经发生了改变,Up的值由0变为1,以此类推。由于move()函数的行为不直接依赖枚举成员的值,因此本次代码修改对move()函数的已有功能不产生任何影响。
但如果程序中赖了枚举成员的具体值,那么这次代码修改就会破坏现有的代码。
enum Direction {
None,
Up,
Down,
Left,
Right,
}
function move(direction: Direction) {
switch (direction) {
// 不会报错,但是逻辑错误,Direction.Up的值已经不是数字0
case 0:
console.log('Up');
break;
// 省略其他代码
}
}
联合枚举类型
当枚举类型中的所有成员都是字面量枚举成员时,该枚举类型成了联合枚举类型。
联合枚举成员类型
联合枚举类型中的枚举成员除了能够表示一个常量值外,还能够表示一种类型,即联合枚举成员类型。
下例中,Direction枚举是联合枚举类型,Direction枚举成员Up、Down、Left和Right既表示数值常量,也表示联合枚举成员类型:
enum Direction {
Up,
Down,
Left,
Right,
}
08 const up: Direction.Up = Direction.Up;
此例第8行,第一个“Direction.Up”表示联合枚举成员类型,第二个“Direction.Up”则表示数值常量0。
联合枚举成员类型是联合枚举类型的子类型,因此可以将联合枚举成员类型赋值给联合枚举类型。
enum Direction {
Up,
Down,
Left,
Right,
}
const up: Direction.Up = Direction.Up;
const direction: Direction = up;
此例中,常量up的类型是联合枚举成员类型“Direction.Up”,常量direction的类型是联合枚举类型Direction。由于“Direction.Up”类型是Direction类型的子类型,因此可以将常量up赋值给常量direction。
联合枚举类型
联合枚举类型是由所有联合枚举成员类型构成的联合类型。
enum Direction {
Up,
Down,
Left,
Right,
}
type UnionDirectionType =
| Direction.Up
| Direction.Down
| Direction.Left
| Direction.Right;
此例中,Direction枚举是联合枚举类型,它等同于联合类型UnionDirectionType,其中“|”符号是定义联合类型的语法。
由于联合枚举类型是由固定数量的联合枚举成员类型构成的联合类型,因此编译器能够利用该性质对代码进行类型检查。
enum Direction {
Up,
Down,
Left,
Right,
}
function f(direction: Direction) {
if (direction === Direction.Up) {
// Direction.Up
} else if (direction === Direction.Down) {
// Direction.Down
} else if (direction === Direction.Left) {
// Direction.Left
} else {
// 能够分析出此处的direction为Direction.Right
direction;
}
}
此例中,编译器能够分析出Direction联合枚举类型只包含四种可能的联合枚举成员类型。在“if-else”语句中,编译器能够根据控制流分析出最后的else分支中direction的类型为“Direction.Right”。
下面再来看另外一个例子。Foo联合枚举类型由两个联合枚举成员类型“Foo.A”和“Foo.B”构成。编译器能够检查出在第7行if条件判断语句中的条件表达式结果永远为true,因此将产生编译错误。
01 enum Foo {
02 A = 'A',
03 B = 'B',
04 }
05
06 function bar(foo: Foo) {
07 if (foo !== Foo.A || foo !== Foo.B) {
08 // ~~~~~~~~~~~~~
09 // 编译错误:该条件永远为'true'
10 }
11 }
下例中,由于Foo联合枚举类型等同于联合类型“Foo.A | Foo.B”,因此它是联合类型“'A' | 'B'”的子类型。
01 enum Foo {
02 A = 'A',
03 B = 'B',
04 }
05
06 enum Bar {
07 A = 'A',
08 }
09
10 enum Baz {
11 B = 'B',
12 C = 'C',
13 }
14
15 function f1(x: 'A' | 'B') {
16 console.log(x);
17 }
18
19 function f2(foo: Foo, bar: Bar, baz: Baz) {
20 f1(foo);
21 f1(bar);
22
23 f1(baz);
24 // ~~~
25 // 错误:类型 'Baz' 不能赋值给参数类型'A' | 'B'
26 }
此例第15行,f1函数接受“'A' | 'B'”联合类型的参数x。第20行,允许使用Foo枚举类型的参数foo调用函数f1,因为Foo枚举类型是“'A' | 'B'”类型的子类型。第21行,允许使用Bar枚举类型的参数bar调用函数f1,因为Bar枚举类型是'A'类型的子类型,显然也是“'A' | 'B'”类型的子类型。第23行,不允许使用Baz枚举类型的参数baz调用函数f1,因为Baz枚举类型是“'B' | 'C'”类型的子类型,显然与“'A' | 'B'”类型不兼容,所以会产生错误。
const枚举类型
枚举类型是TypeScript对JavaScript的扩展,JavaScript语言本身并不支持枚举类型。在编译时,TypeScript编译器会将枚举类型编译为JavaScript对象。
enum Direction {
Up,
Down,
Left,
Right,
}
const d: Direction = Direction.Up;
上面的代码编译后生成的JavaScript代码如下所示,为了支持枚举成员名与枚举成员值之间的正、反向映射关系,TypeScript还生成了一些额外的代码:
"use strict";
var Direction;
(function (Direction) {
Direction[Direction["Up"] = 0] = "Up";
Direction[Direction["Down"] = 1] = "Down";
Direction[Direction["Left"] = 2] = "Left";
Direction[Direction["Right"] = 3] = "Right";
})(Direction || (Direction = {}));
const d = Direction.Up;
有时候我们不会使用枚举成员值到枚举成员名的反向映射,因此没有必要生成额外的反向映射代码,只需要生成如下代码就能够满足需求:
01 "use strict";
02 var Direction;
03 (function (Direction) {
04 Direction["Up"] = 0;
05 Direction["Down"] = 1
06 Direction["Left"] = 2
07 Direction["Right"] = 3
08 })(Direction || (Direction = {}));
09
10 const d = Direction.Up;
更进一步讲,如果我们只关注第10行枚举类型的使用方式就会发现,完全不需要生成与Direction对象相关的代码,只需要将“Direction.Up”替换为它所表示的常量0即可。经过此番删减后的代码量将大幅减少,并且不会改变程序的运行结果,如下所示:
"use strict";
const d = 0;
const枚举类型具有相似的效果。const枚举类型将在编译阶段被完全删除,并且在使用了const枚举类型的地方会直接将const枚举成员的值内联到代码中。
const enum Directions {
Up,
Down,
Left,
Right,
}
const directions = [
Directions.Up,
Directions.Down,
Directions.Left,
Directions.Right,
];
//代码经过TypeScript编译器编译后生成的JavaScript代码
"use strict";
const directions = [
0 /* Up */,
1 /* Down */,
2 /* Left */,
3 /* Right */
];
为了便于代码调试和保持代码的可读性,TypeScript编译器在内联了const枚举成员的位置还额外添加了注释,注释的内容为枚举成员的名字。
字面量类型
TypeScript支持将字面量作为类型使用,我们称之为字面量类型。每一个字面量类型都只有一个可能的值,即字面量本身。
boolean字面量类型
boolean字面量类型只有以下两种:
- true字面量类型
- false字面量类型
原始类型boolean等同于由true字面量类型和false字面量类型构成的联合类型
true字面量类型只能接受true值;同理,false字面量类型只能接受false值
boolean字面量类型是boolean类型的子类型,因此可以将boolean字面量类型赋值给boolean类型。
const a: true = true;
const b: false = false;
let c: boolean;
c = a;
c = b;
string字面量类型
字符串字面量和模板字面量都能够创建字符串。字符串字面量和不带参数的模板字面量可以作为string字面量类型使用。
string字面量类型是string类型的子类型,因此可以将string字面量类型赋值给string类型。
const a: 'hello' = 'hello';
const b: `world` = `world`;
let c: string;
c = a;
c = b;
数字字面量类型
数字字面量类型包含以下两类:
- number字面量类型
- bigint字面量类型
所有的二进制、八进制、十进制和十六进制数字字面量都可以作为数字字面量类型。
除了正数数值外,负数也可以作为数字字面量类型。
number字面量类型和bigint字面量类型分别是number类型和bigint类型的子类型,因此可以进行赋值操作。
const a0: 0b1 = 1;
const b0: 0o1 = 1;
const c0: 1 = 1;
const d0: 0x1 = 1;
const a1: 0b1n = 1n;
const b1: 0o1n = 1n;
const c1: 1n = 1n;
const d1: 0x1n = 1n;
const a0: -10 = -10;
const b0: 10 = 10;
const a1: -10n = -10n;
const b1: 10n = 10n;
const one: 1 = 1;
const num: number = one;
const oneN: 1n = 1n;
const numN: bigint = oneN;
枚举成员字面量类型
之前介绍了联合枚举成员类型。我们也可以将其称作枚举成员字面量类型,因为联合枚举成员类型使用枚举成员字面量形式表示。
enum Direction {
Up,
Down,
Left,
Right,
}
const up: Direction.Up = Direction.Up;
const down: Direction.Down = Direction.Down;
const left: Direction.Left = Direction.Left;
const right: Direction.Right = Direction.Right;
单元类型
单元类型(Unit Type)也叫作单例类型(Singleton Type),指的是仅包含一个可能值的类型。由于这个特殊的性质,编译器在处理单元类型时甚至不需要关注单元类型表示的具体值。
TypeScript中的单元类型有以下几种:
- undefined类型
- null类型
- unique symbol类型
- void类型
- 字面量类型
- 联合枚举成员类型
顶端类型
顶端类型是一种通用类型,有时也称为通用超类型,因为在类型系统中,所有类型都是顶端类型的子类型,或
者说顶端类型是所有其他类型的父类型。顶端类型涵盖了类型系统中所有可能的值。
TypeScript中有以下两种顶端类型:
- any
- unknown
any
在TypeScript中,所有类型都是any类型的子类型。我们可以将任何类型的值赋值给any类型。
需要注意的是,虽然any类型是所有类型的父类型,但是TypeScript允许将any类型赋值给任何其他类型( never类型例外 )。
在any类型上允许执行任意的操作而不会产生编译错误。例如,我们可以读取any类型的属性或者将any类型当作函数调用,就算any类型的实际值不支持这些操作也不会产生编译错误。
在程序中,我们使用any类型来跳过编译器的类型检查。如果声明了某个值的类型为any类型,那么就相当于告诉编译器:“不要对这个值进行类型检查。”当TypeScript编译器看到any类型的值时,也会对它开启“绿色通道”,让其直接通过类型检查。
在将已有的JavaScript程序迁移到TypeScript程序的过程中,使用any类型来暂时绕过类型检查是一项值得掌握的技巧。
从长远来看,我们应该尽量减少在代码中使用any类型。因为只有开发者精确地描述了类型信息,TypeScript编译器才能够更加准确有效地进行类型检查,这也是我们选择使用TypeScript语言的主要原因之一。
--noImplicitAny
TypeScript中的类型注解是可选的。若一个值没有明确的类型注解,编译器又无法自动推断出它的类型,那么这个值的默认类型为any类型。
function f1(x) {
// ~
// 参数x的类型为any
console.log(x);
}
function f2(x: any) {
console.log(x);
}
此例中,函数f1的参数x没有使用类型注解,编译器也无法从代码中推断出参数x的类型。于是,函数f1的参数x将隐式地获得any类型。最终,函数f1的类型等同于函数f2的类型。在这种情况下,编译器会默默地忽略对参数x的类型检查,这会导致编译器无法检查出代码中可能存在的错误。
在大多数情况下,我们想要避免上述情况的发生。因此,TypeScript提供了一个“--noImplicitAny”编译选项来控制该行为。当启用了该编译选项时,如果发生了隐式的any类型转换,那么会产生编译错误,注意:如果显示注解为 any 类型,不会产生编译错误。
function f(x) {
// ~
// 编译错误!参数'x'具有隐式的'any'类型
console.log(x);
}
unknown
TypeScript 3.0版本引入了另一种顶端类型unknown。unknown类型使用unknown关键字作为标识。
任何其他类型都能够赋值给unknown类型,该行为与any类型是一致的。
unknown类型是比any类型更安全的顶端类型,因为unknown类型只允许赋值给any类型和unknown类型,而不允许赋值给任何其他类型,该行为与any类型是不同的。
同时,在unknown类型上也不允许执行绝大部分操作。
在程序中使用unknown类型时,我们必须将其细化为某种具体类型,否则将产生编译错误。
let x: unknown;
// 错误
x + 1;
x.foo;
x();
function f1(message: any) {
return message.length;
// ~~~~~~
// 无编译错误 但执行可能会报错
}
f1(undefined);
function f2(message: unknown) {
return message.length;
// ~~~~~~
// 编译错误!属性'length'不存在于'unknown'类型上 执行也可能会报错
}
f2(undefined);
我们使用typeof运算符去检查参数message是否为字符串,只有当message是一个字符串时,我们才会去读取其length属性。这样修改之后,既不会产生编译错误,也不会产生运行时错误。
function f2(message: unknown) {
if (typeof message === 'string') {
return message.length;
}
}
f2(undefined);
小结
下面我们将对两者进行简单的对比与总结:
- TypeScript中仅有any和unknown两种顶端类型。
- TypeScript中的所有类型都能够赋值给any类型和unknown类型,相当于两者都没有写入的限制。
- any类型能够赋值给任何其他类型,唯独不包括马上要介绍的never类型。
- unknown类型仅能够赋值给any类型和unknown类型。
- 在使用unknown类型之前,必须将其细化为某种具体类型,而使用any类型时则没有任何限制。
- unknown类型相当于类型安全的any类型。这也是在有了any类型之后,TypeScript又引入unknown类型的根本原因
在程序中,我们应尽量减少顶端类型的使用,因为它们是拥有较弱类型约束的通用类型。如果在编码时确实无法知晓某个值的类型,那么建议优先使用unknown类型来代替any类型,因为它比any类型更加安全。
尾端类型
在类型系统中,尾端类型(Bottom Type)是所有其他类型的子类型。由于一个值不可能同时属于所有类型,例如一个值不可能同时为数字类型和字符串类型,因此尾端类型中不包含任何值。尾端类型也称作0类型或者空类型。
TypeScript中只存在一种尾端类型,即never类型。
never
TypeScript 2.0版本引入了仅有的尾端类型—never类型。never类型使用never关键字来标识,不包含任何可能值。
function f(): never {
throw new Error();
}
根据尾端类型的定义,never类型是所有其他类型的子类型。所以,never类型允许赋值给任何类型,尽管并不存在never类型的值。
let x: never;
let a: boolean = x;
let b: string = x;
let c: number = x;
let d: bigint = x;
let e: symbol = x;
let f: void = x;
let g: undefined = x;
let h: null = x;
正如尾端类型其名,它在类型系统中位于类型结构的最底层,没有类型是never类型的子类型。因此,除never类型自身外,所有其他类型都不能够赋值给never类型。
需要注意的是,就算是类型约束最宽松的any类型也不能够赋值给never类型。
let x: never;
let y: never;
// 正确
x = y;
// 错误
x = true;
x = 'hi';
x = 3.14;
x = 99999n;
x = Symbol();
x = undefined;
x = null;
x = {};
x = [];
x = function () {};
let x: any;
let y: never = x;
// ~
// 编译错误:类型'any'不能赋值给类型'never'
应用场景
never类型主要有以下几种典型的应用场景。
场景一
never类型可以作为函数的返回值类型,它表示该函数无法返回一个值。我们知道,如果函数体中没有使用return语句,那么在正常执行完函数代码后会返回一个undefined值。在这种情况下,函数的返回值类型是void类型而不是never类型。只有在函数根本无法返回一个值的时候,函数的返回值类型才是never类型。
一种情况就是函数中抛出了异常,这会导致函数终止执行,从而不会返回任何值。在这种情况下,函数的返回值类型为never类型。
function throwError(): never {
throw new Error();
// <- 该函数永远无法执行到末尾,返回值类型为'never'
}
若函数中的代码不是直接抛出异常而是间接地抛出异常,那么函数的返回值类型也是never类型。
function throwError(): never {
throw new Error();
}
function fail(): never {
return throwError();
}
除了抛出异常之外,还有一种情况函数也无法正常返回一个值,即如果函数体中存在无限循环从而导致函数的执行永远也不会结束,那么在这种情况下函数的返回值类型也为never类型。
此例中,infiniteLoop函数的执行永远也不会结束,这意味着它无法正常返回一个值。因此,该函数的返回值类型为never类型。
function infiniteLoop(): never {
while (true) {
console.log('endless...');
}
}
场景二
在“条件类型”中常使用never类型来帮助完成一些类型运算。例如,“Exclude<T, U>”类型是TypeScript内置的工具类型之一,它借助于never类型实现了从类型T中过滤掉类型U的功能。
type Exclude<T, U> = T extends U ? never : T;
//我们使用“Exclude<T, U>”工具类型从联合类型“boolean | string”中剔除了string类型,最终得到的结果类型为boolean类型。
type T = Exclude<boolean | string, string>; // boolean
场景三
最后一个要介绍的never类型的应用场景与类型推断功能相关。在TypeScript编译器执行类型推断操作时,如果发现已经没有可用的类型,那么推断结果为never类型。
function getLength(message: string) {
if (typeof message === 'string') {
message; // string
} else {
message; // never
}
}
在if语句中使用typeof运算符来判断message是否为string类型。若参数message为string类型,则执行该分支内的代码。因此,第3行中参数message的类型为string类型。
在else分支中参数message的类型应该是非string类型。由于函数声明中定义了参数message的类型是string类型,因此else分支中已经不存在其他可选类型。在这种情况下,TypeScript编译器会将参数message的类型推断为never类型,表示不存在这样的值。
数组类型
数组是十分常用的数据结构,它表示一组有序元素的集合。在TypeScript中,数组值的数据类型为数组类型。
数组类型定义
TypeScript提供了以下两种方式来定义数组类型:
- 简便数组类型表示法
- 泛型数组类型表示法
简便数组类型表示法
简便数组类型表示法借用了数组字面量的语法,通过在数组元素类型之后添加一对方括号“[]”来定义数组类型
TElement[]
该语法中,TElement代表数组元素的类型,方括号“[]”代表数组类型。在TElement与“[]”之间不允许出现换行符号。
如果数组中元素的类型为复合类型,则需要在数组元素类型上使用分组运算符,即小括号。
const red: (string | number)[] = ['f', f, 0, 0, 0, 0];
泛型数组类型表示法
泛型数组类型表示法是另一种表示数组类型的方法。顾名思义,泛型数组类型表示法就是使用泛型来表示数组类型。
Array<TElement>
该语法中,Array代表数组类型;“<TElement>”是类型参数的语法,其中TElement代表数组元素的类型。
在使用泛型数组类型表示法时,就算数组中元素的类型为复合类型也不需要使用分组运算符。
const red: Array<string | number> = ['f', 'f', 0, 0,0, 0];
两种方法比较
简便数组类型表示法和泛型数组类型表示法在功能上没有任何差别,两者只是在编程风格上有所差别。
数组元素类型
在定义了数组类型之后,当访问数组元素时能够获得正确的元素类型信息。
const digits: number[] = [0, 1, 2, 3, 4, 5, 6, 7, 8,9];
const zero = digits[0];
// ~~~~
// number类型
虽然没有给常量zero添加类型注解,但是TypeScript编译器能够从数组类型中推断出zero的类型为number类型。
我们知道,当访问数组中不存在的元素时将返回undefined值。TypeScript的类型系统无法推断出是否存在数组访问越界的情况,因此即使访问了不存在的数组元素,还是会得到声明的数组元素类型。
const digits: number[] = [0, 1, 2, 3, 4, 5, 6, 7, 8,9];
// 没有编译错误
const out: number = digits[100];
只读数组
只读数组与常规数组的区别在于,只读数组仅允许程序读取数组元素而不允许修改数组元素。
TypeScript提供了以下三种方式来定义一个只读数组:
- 使用“ReadonlyArray<T>”内置类型。
- 使用readonly修饰符
- 使用“Readonly<T>”工具类型
以上三种定义只读数组的方式只是语法不同,它们在功能上没有任何差别。
ReadonlyArray<T>
在TypeScript早期版本中,提供了“ReadonlyArray<T>”类型专门用于定义只读数组。在该类型中,类型参数T表示数组元素的类型。
const red: ReadonlyArray<number> = [255, 0, 0];
readonly
TypeScript 3.4版本中引入了一种新语法,使用readonly修饰符能够定义只读数组。在定义只读数组时,将readonly修饰符置于数组类型之前即可。
const red: readonly number[] = [255, 0, 0];
readonly修饰符不允许与泛型数组类型表示法一起使用。
const red: readonly Array<number> = [255, 0, 0];
// ~~~~~~~~
// 编译错误
Readonly<T>
“Readonly<T>”是TypeScript提供的一个内置工具类型,用于定义只读对象类型。该工具类型能够将类型参数T的所有属性转换为只读属性
// 工具实现原理
type Readonly<T> = {
readonly [P in keyof T]: T[P];
};
const red: Readonly<number[]> = [255, 0, 0];
类型参数T的值为数组类型“number[]”,而不是数组元素类型number。在这一点上,它与“ReadonlyArray<T>”类型是有区别的。
注意事项
我们可以通过数组元素索引来访问只读数组元素,但是不能修改只读数组元素。
在只读数组上也不支持任何能够修改数组元素的方法,如push和pop方法等。
在进行赋值操作时,允许将常规数组类型赋值给只读数组类型,但是不允许将只读数组类型赋值给常规数组类型。换句话说,不能通过赋值操作来放宽对只读数组的约束。
元组类型
元组(Tuple)表示由有限元素构成的有序列表。在JavaScript中,没有提供原生的元组数据类型。TypeScript对此进行了补充,提供了元组数据类型。由于元组与数组之间存在很多共性,因此TypeScript使用数组来表示元组。
在TypeScript中,元组类型是数组类型的子类型。元组是长度固定的数组,并且元组中每个元素都有确定的类型。
元组的定义
定义元组类型的语法与定义数组字面量的语法相似
[T0, T1, ..., Tn]
该语法中的T0、T1和Tn表示元组中元素的类型,针对元组中每一个位置上的元素都需要定义其数据类型。
元组中每个元素的类型不必相同。
元组的值实际上是一个数组,在给元组类型赋值时,数组中每个元素的类型都要与元组类型的定义保持兼容。例如,对于“[number,number]”类型的元组,它只接受包含两个number类型元素的数组。
若数组元素的类型与元组类型的定义不匹配,则会产生编译错误。
let point: [number, number];
point = [0, 'y']; // 编译错误
point = ['x', 0]; // 编译错误
point = ['x', 'y']; // 编译错误
在给元组类型赋值时,还要保证数组中元素的数量与元组类型定义中元素的数量保持一致,否则将产生编译错误。
let point: [number, number];
point = [0]; // 编译错误
point = [0, 0, 0]; // 编译错误
只读元组
元组可以定义为只读元组,这与只读数组是类似的。只读元组类型是只读数组类型的子类型。定义只读元组有以下两种方式:
- 使用readonly修饰符
- 使用“Readonly<T>”工具类型
以上两种定义只读元组的方式只是语法不同,它们在功能上没有任何差别。
readonly
TypeScript 3.4版本中引入了一种新语法,使用readonly修饰符能够定义只读元组。在定义只读元组时,将readonly修饰符置于元组类型之前即可。
const point: readonly [number, number] = [0, 0];
Readonly<T>
由于TypeScript 3.4支持了使用readonly修饰符来定义只读元组,所以从TypeScript 3.4开始可以使用“Readonly<T>”工具类型来定义只读元组。
const point: Readonly<[number, number]> = [0, 0];
此例中,point是包含两个元素的只读元组。在“Readonly<T>”类型中,类型参数T的值为元组类型“[number, number]”。
注意事项
在给只读元组类型赋值时,允许将常规元组类型赋值给只读元组类型,但是不允许将只读元组类型赋值给常规元组类型。换句话说,不能通过赋值操作来放宽对只读元组的约束。
const a: [number] = [0];
const ra: readonly [number] = [0];
const x: readonly [number] = a; // 正确
const y: [number] = ra; // 编译错误
访问元组中的元素
由于元组在本质上是数组,所以我们可以使用访问数组元素的方法去访问元组中的元素。在访问元组中指定位置上的元素时,编译器能够推断出相应的元素类型。
const score: [string, number] = ['math', 100];
const course = score[0]; // string
const grade = score[1]; // number
const foo: boolean = score[0];
// ~~~
// 编译错误!类型 'string' 不能赋值给类型 'boolean'
const bar: boolean = score[1];
// ~~~
// 编译错误!类型 'number' 不能赋值给类型 'boolean'
当访问数组中不存在的元素时不会产生编译错误。与之不同的是,当访问元组中不存在的元素时会产生编译错误。
const score: [string, number] = ['math', 100];
const foo = score[2];
// ~~~~~~~~
// 编译错误!该元组类型只有两个元素,找不到索引为'2'的元素
修改元组元素值的方法与修改数组元素值的方法相同。
元组类型中的可选元素
在定义元组时,可以将某些元素定义为可选元素。定义元组可选元素的语法是在元素类型之后添加一个问号“?”。
如果元组中同时存在可选元素和必选元素,那么可选元素必须位于必选元素之后。
[T0, T1?, ..., Tn?]
该语法中的T0表示必选元素的类型,T1和Tn表示可选元素的类型
const tuple: [boolean, string?, number?] = [true,'yes', 1];
在给元组赋值时,可以不给元组的可选元素赋值。
let tuple: [boolean, string?, number?] = [true, 'yes',1];
tuple = [true];
tuple = [true, 'yes'];
tuple = [true, 'yes', 1];
元组类型中的剩余元素
在定义元组类型时,可以将最后一个元素定义为剩余元素。
[...T[]]
该语法中,元组的剩余元素是数组类型,T表示剩余元素的类型。
const tuple: [number, ...string[]] = [0, 'a', 'b'];
如果元组类型的定义中含有剩余元素,那么该元组的元素数量是开放的,它可以包含零个或多个指定类型的剩余元素。
let tuple: [number, ...string[]];
tuple = [0];
tuple = [0, 'a'];
tuple = [0, 'a', 'b'];
tuple = [0, 'a', 'b', 'c'];
元组的长度
对于经典的元组类型,即不包含可选元素和剩余元素的元组而言,元组中元素的数量是固定的。也就是说,元组拥有一个固定的长度。TypeScript编译器能够识别出元组的长度并充分利用该信息来进行类型检查。
function f(point: [number, number]) {
// 编译器推断出length的类型为数字字面量类型2
const length = point.length;
if (length === 3) { // 编译错误!条件表达式永远为 false
// ...
}
}
此例第3行,TypeScript编译器能够推断出常量length的类型为数字字面量类型2。第5行在if条件表达式中,数字字面量类型2与数字字面量类型3没有交集。因此,编译器能够分析出该比较结果永远为false。在这种情况下,编译器将产生编译错误。
当元组中包含了可选元素时,元组的长度不再是一个固定值。编译器能够根据元组可选元素的数量识别出元组所有可能的长度,进而构造出一个由数字字面量类型构成的联合类型来表示元组的长度。
const tuple: [boolean, string?, number?] = [true,'yes', 1];
let len = tuple.length; // 1 | 2 | 3
len = 1;
len = 2;
len = 3;
len = 4; // 编译错误!类型'4'不能赋值给类型'1 | 2 | 3'
若元组类型中定义了剩余元素,那么该元组拥有不定数量的元素。因此,该元组length属性的类型将放宽为number类型。
const tuple: [number, ...string[]] = [0, 'a'];
const len = tuple.length; // number
元组类型与数组类型的兼容性
元组类型是数组类型的子类型,只读元组类型是只读数组类型的子类型。在进行赋值操作时,允许将元组类型赋值给类型兼容的元组类型和数组类型。
const point: [number, number] = [0, 0];
const nums: number[] = point; // 正确
const strs: string[] = point; // 编译错误
元组类型允许赋值给常规数组类型和只读数组类型,但只读元组类型只允许赋值给只读数组类型。
const t: [number, number] = [0, 0];
const rt: readonly [number, number] = [0, 0];
let a: number[] = t;
let ra: readonly number[];
ra = t;
ra = rt;
由于数组类型是元组类型的父类型,因此不允许将数组类型赋值给元组类型。
const nums: number[] = [0, 0];
let point: [number, number] = nums;
// ~~~~~
// 编译错误
对象类型
在JavaScript中存在这样一种说法,那就是“一切皆为对象”。有这种说法是因为JavaScript中的绝大多数值都可以使用对象来表示。例如,函数、数组和对象字面量等本质上都是对象。对于原始数据类型,如String类型,JavaScript也提供了相应的构造函数来创建能够表示原始值的对象。
在某些操作中,原始值还会自动地执行封箱[1]操作,将原始数据类型转换为对象数据类型。例如,在字符串字面量上直接调用内置的“toUpperCase()”方法时,JavaScript会先将字符串字面量转换为对象类型,然后再调用字符串对象上的“toUpperCase()”方法。
前面已经介绍过的数组类型、元组类型以及后面章节中将介绍的函数类型、接口等都属于对象类型。由于对象类型的应用非常广泛,因此TypeScript提供了多种定义对象类型的方式。
在本节中,我们将首先介绍三种基本的对象类型:
- Object类型(首字母为大写字母O)
- object类型(首字母为小写字母o)
- 对象类型字面量
Object
这里的 Object 指的是Object类型,而不是JavaScript内置的 “Object()” 构造函数。
请读者一定要注意区分这两者,Object类型表示一种类型,而“Object()”构造函数则表示一个值。
因为“Object()”构造函数是一个值,因此它也有自己的类型。
但要注意的是,“Object()”构造函数的类型不是Object类型。
“Object()”构造函数
为了更好地理解Object类型,让我们先了解一下“Object()”构造函数。
JavaScript提供了内置的“Object()”构造函数来创建一个对象。
const obj = new Object();
在实际代码中,使用“Object()”构造函数来创建对象的方式并不常用。在创建对象时,我们通常会选择使用更简洁的对象字面量。虽然不常使用“Object()”构造函数来创建对象,但是“Object()”构造函数提供了一些非常常用的静态方法,例如“Object.assign()”方法和“Object.create()”方法等
让我们深入分析一下TypeScript源码中对“Object()”构造函数的类型定义。
interface ObjectConstructor {
readonly prototype: Object;
// 省略了其他成员
}
declare var Object: ObjectConstructor;
由该定义能够直观地了解到“Object()”构造函数的类型是ObjectConstructor类型而不是Object类型,它们是不同的类型。
第3行,prototype属性的类型为Object类型。构造函数的prototype属性值决定了实例对象的原型。
此外,“Object.prototype”是一个特殊的对象,它是JavaScript中的公共原型对象。也就是说,如果程序中没有刻意地修改一个对象的原型,那么该对象的原型链上就会有“Object.prototype”对象,因此也会继承“Object.prototype”对象上的属性和方法。
现在,我们可以正式地引出Object类型。Object类型是特殊对象“Object.prototype”的类型,该类型的主要作用是描述JavaScript中几乎所有对象都共享(通过原型继承)的属性和方法。Object类型的具体定义如下所示(取自TypeScript源码):
interface Object {
/**
* The initial value of Object.prototype.constructor
* is the standard built-in Object constructor
*/
constructor: Function;
/**
* Returns a string representation of an object.
*/
toString(): string;
/**
* Returns a date converted to a string using the
* current locale.
*/
toLocaleString(): string;
/**
* Returns the primitive value of the specified object.
*/
valueOf(): Object;
/**
* Determines whether an object has a property with
* the specified name.
* @param v A property name.
*/
hasOwnProperty(v: PropertyKey): boolean;
/**
* Determines whether an object exists in another
* object's prototype chain.
*/
isPrototypeOf(v: Object): boolean;
/**
* Determines whether a specified property is enumerable.
* @param v A property name.
*/
propertyIsEnumerable(v: PropertyKey): boolean;
}
通过该类型定义能够了解到,Object类型里定义的方法都是通用的对象方法,如“valueOf()”方法。
类型兼容性
Object类型有一个特点,那就是除了undefined值和null值外,其他任何值都可以赋值给Object类型。
let obj: Object;
// 正确
obj = { x: 0 };
obj = true;
obj = 'hi';
obj = 1;
// 编译错误
obj = undefined;
obj = null;
对象能够赋值给Object类型是理所当然的,但为什么原始值也同样能够赋值给Object类型呢?
实际上,这样设计正是为了遵循JavaScript语言的现有行为。我们在本章开篇处介绍了 JavaScript语言中存在自动封箱操作。当在原始值上调用某个方法时,JavaScript会对原始值执行封箱操作,将其转换为对象类型,然后再调用相应方法。
Object类型描述了所有对象共享的属性和方法,而JavaScript允许在原始值上直接访问这些方法,因此TypeScript允许将原始值赋值给Object类型。
常见错误
在使用Object类型时容易出现的一个错误是,将Object类型应用于自定义变量、参数或属性等的类型。
const point: Object = { x: 0, y: 0 };
此例中,将常量point的类型定义为Object类型。虽然该代码不会产生任何编译错误,但它是一个明显的使用错误。
原因刚刚介绍过,Object类型的用途是描述“Object.prototype”对象的类型,即所有对象共享的属性和方法。在描述自定义对象类型时有很多更好的选择,完全不需要使用Object类型,例如接下来要介绍的object类型和对象字面量类型等。
object
在TypeScript 2.2版本中,增加了一个新的object类型表示非原始类型。
object类型使用object关键字作为标识,object类型名中的字母全部为小写。
const point: object = { x: 0, y: 0 };
object类型的关注点在于类型的分类,它强调一个类型是非原始类型,即对象类型。
object类型的关注点不是该对象类型具体包含了哪些属性,例如对象类型是否包含一个名为name的属性,因此,不允许读取和修改object类型上的自定义属性。
const obj: object = { foo: 0 };
// 编译错误!属性'foo'不存在于类型'object'上
obj.foo;
// 编译错误!属性'foo'不存在于类型'object'上
obj.foo = 0;
在object类型上仅允许访问对象的公共属性和方法,也就是Object类型中定义的属性和方法。
const obj: object = {};
obj.toString();
obj.valueOf();
类型兼容性
JavaScript中的数据类型可以划分为原始数据类型和对象数据类型两大类。针对JavaScript中的每一种原始数据类型,TypeScript都提供了对应的类型:
- boolean
- string
- number
- bigint
- symbol
- undefined
- null
但是在以前的版本中,TypeScript唯独没有提供一种类型用来表示非原始类型,也就是对象类型 ,上一节介绍的Object类型无法表示非原始类型,因为允许将原始类型赋值给Object类型。
新的object类型填补了这个功能上的缺失。object类型能够准确地表示非原始类型,因为原始类型不允许赋给object类型。
let nonPrimitive: object;
// 下列赋值语句均会产生编译错误
nonPrimitive = true;
nonPrimitive = 'hi';
nonPrimitive = 1;
nonPrimitive = 1n;
nonPrimitive = Symbol();
nonPrimitive = undefined;
nonPrimitive = null;
只有非原始类型,也就是对象类型能够赋给object类型 。
let nonPrimitive: object;
// 正确
nonPrimitive = {};
nonPrimitive = { x: 0 };
nonPrimitive = [0];
nonPrimitive = new Date();
nonPrimitive = function () {};
object类型仅能够赋值给以下三种类型 :
- 顶端类型any和unknown。
- Object类型。
- 空对象类型字面量“{}”
由于所有类型都是顶端类型的子类型,所以object类型能够赋值给顶端类型any和unknown。
Object类型描述了所有对象都共享的属性和方法,所以很自然地表示对象类型的object类型能够赋值给Object类型。
object类型也能够赋值给空对象类型字面量“{}”。我们将在下节中介绍空对象类型字面量。
实例应用
在JavaScript中,有一些内置方法只接受对象作为参数。例如,我们前面提到的“Object.create()”方法,该方法的第一个参数必须传入对象或者null值作为新创建对象的原型。如果传入了原始类型的值,例如数字1,那么将产生运行时的类型错误。
// 正确
const a = Object.create(Object.prototype);
const b = Object.create(null);
// 类型错误
const c = Object.create(1);
在没有引入object类型之前,没有办法很好地描述“Object.create()”方法签名的类型。TypeScript也只好将该方法第一个参数的类型定义为any类型。如此定义参数类型显然不够准确,而且对类型检查也没有任何帮助。
interface ObjectConstructor {
create(o: any, ...): any;
// 省略了其他成员
}
在引入了object类型之后,TypeScript更新了“Object.create()”方法签名的类型,使用object类型来替换any类型。
interface ObjectConstructor {
create(o: object | null, ...): any;
// 省略了其他成员
}
对象类型字面量
对象类型字面量是定义对象类型的方法之一。下例中,我们使用对象类型字面量定义了一个对象类型。
01 const point: { x: number; y: number } = { x: 0, y: 0};
02 // ~~~~~~~~~~~~~~~~~~~~~~~~
03 // 对象类型字面量
基础语法
对象类型字面量的语法与对象字面量的语法相似。在定义对象类型字面量时,需要将类型成员依次列出。
{
TypeMember;
TypeMember;
...
}
在该语法中,TypeMember表示对象类型字面量中的类型成员,类型成员置于一对大括号“{}”之内。
在各个类型成员之间,不但可以使用分号“;”进行分隔,还可以使用逗号“,”进行分隔,这两种分隔符不存在功能上的差异。
对象类型字面量的类型成员可分为以下五类:
- 属性签名
- 调用签名
- 构造签名
- 方法签名
- 索引签名
下面我们将以属性签名为例来介绍对象类型字面量的使用方法,其他种类的类型成员将在 函数类型 和 接口 中进行详细介绍。
属性签名
属性签名声明了对象类型中属性成员的名称和类型
{
PropertyName: Type;
}
在该语法中,PropertyName表示对象属性名,可以为标识符、字符串、数字和可计算属性名;Type表示该属性的类型。
属性签名中的属性名可以为可计算属性名,但需要该可计算属性名满足以下条件之一:
- 可计算属性名的类型为string字面量类型或number字面量类型
- 可计算属性名的类型为“unique symbol”类型
- 可计算属性名符合“Symbol.xxx”的形式。
const a: 'a' = 'a';
const b: 0 = 0;
let obj: {
[a]: boolean;
[b]: boolean;
['c']: boolean;
[1]: boolean;
};
const s: unique symbol = Symbol();
let obj: {
[s]: boolean;
};
let obj: {
[Symbol.toStringTag]: string;
};
在属性签名的语法中,表示类型的Type部分是可以省略的,允许只列出属性名而不定义任何类型。在这种情况下,该属性的类型默认为any类型**。
可选属性
在默认情况下,通过属性签名定义的对象属性是必选属性。如果在属性签名中的属性名之后添加一个问号“?”,那么将定义一个可选属性。
在给对象类型赋值时,可选属性可以被忽略。
let point: { x: number; y: number; z?: number };
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// Point对象类型
point = { x: 0, y: 0 };
point = { x: 0, y: 0, z: 0 };
在“--strictNullChecks”模式下,TypeScript会自动在可选属性的类型定义中添加undefined类型。
{
x: number;
y: number;
z?: number;
};
// 等同于:
{
x: number;
y: number;
z?: number | undefined;
};
在“--strictNullChecks”模式下,null类型与undefined类型是区别对待的。下例中,不允许给属性z赋予null值
let point: { x: number; y: number; z?: number };
point = {
x: 0,
y: 0,
z: null,
// ~
// 编译错误!类型'null'不能赋值给类型'number | undefined'
};
在非“--strictNullChecks”模式下,null值与undefined值均可以赋值给可选属性。因为在该模式下,null值与undefined值几乎可以赋值给任意类型。
在操作对象类型的值时,只允许读写对象类型中已经定义的必选属性和可选属性。若访问了未定义的属性,则会产生编译错误。
只读属性
在属性签名定义中添加readonly修饰符能够定义对象只读属性
只读属性的值在初始化后不允许再被修改
空对象类型字面量
如果对象类型字面量没有定义任何类型成员,那么它就成了一种特殊的类型,即空对象类型字面量“{}”。
空对象类型字面量表示不带有任何属性的对象类型,因此不允许在“{}”类型上访问任何自定义属性。
const point: {} = { x: 0, y: 0 };
point.x;
// ~
// 编译错误!属性 'x' 不存在于类型 '{}'
point.y;
// ~
// 编译错误!属性 'y' 不存在于类型 '{}'
在空对象类型字面量“{}”上,允许访问对象公共的属性和方法,也就是Object类型上定义的方法和属性。
现在,读者可能会发现空对象类型字面量“{}”与Object类型十分相似。而事实上也正是如此,单从行为上来看两者是可以互换使用的。
例如,除了undefined值和null值外,其他任何值都可以赋值给空对象类型字面量“{}”和Object类型。
同时,空对象类型字面量“{}”和Object类型之间也允许互相赋值。
let a: Object = 'hi';
let b: {} = 'hi';
a = b;
b = a;
两者的区别主要在于语义上。
全局的Object类型用于描述对象公共的属性和方法,它相当于一种专用类型,因此程序中不应该将自定义变量、参数等类型直接声明为Object类型。
空对象类型字面量“{}”强调的是不包含属性的对象类型,同时也可以作为Object类型的代理来使用。
最后,也要注意在某些场景中新的object类型可能是更加合适的选择。
弱类型
弱类型(Weak Type)是TypeScript 2.4版本中引入的一个概念。弱类型指的是同时满足以下条件的对象类型:
- 对象类型中至少包含一个属性。
- 对象类型中所有属性都是可选属性。
- 对象类型中不包含字符串索引签名、数值索引签名、调用签名和构造签名
let config: {
url?: string;
async?: boolean;
timeout?: number;
};
多余属性
对象多余属性可简单理解为多出来的属性。
多余属性会对类型间关系的判定产生影响。
例如,一个类型是否为另一个类型的子类型或父类型,以及一个类型是否能够赋值给另一个类型。
显然,多余属性是一个相对的概念,只有在比较两个对象类型的关系时谈论多余属性才有意义。
假设存在源对象类型和目标对象类型两个对象类型,那么当满足以下条件时,我们说源对象类型相对于目标对象类型存在多余属性,具体条件如下:
- 源对象类型是一个“全新(Fresh)的对象字面量类型”。
- 源对象类型中存在一个或多个在目标对象类型中不存在的属性。
全新的对象字面量类型
“全新的对象字面量类型”指的是由对象字面量推断出的类型。
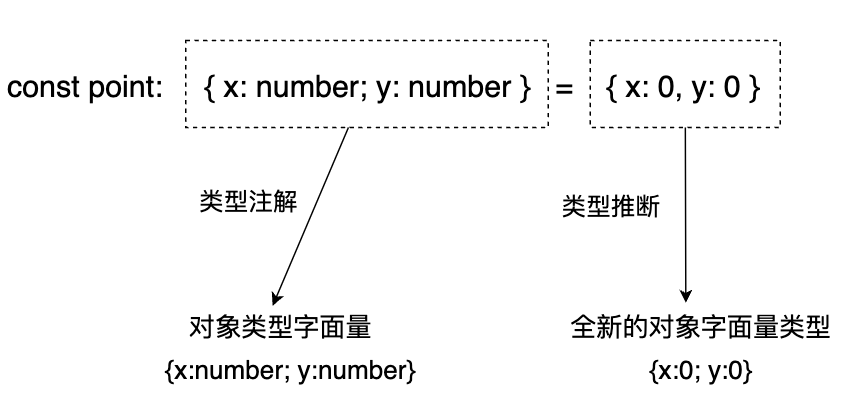
此例中,由赋值语句右侧的对象字面量“{ x: 0, y: 0 }”推断出的类型为全新的对象字面量类型“{ x: 0, y: 0 }”。
同时也要注意区分,赋值语句左侧类型注解中的“{ x: number, y: number }”不是全新的对象字面量类型。如果我们将赋值语句右侧的类型视作源对象类型,将赋值语句左侧的类型视作目标对象类型,那么不存在多余属性。
const point: { x: number; y: number } = {
x: 0,
y: 0,
z: 0,
// ~~~~06 // z是多余属性
};
我们为赋值语句右侧的对象字面量增加了一个z属性。
这时,赋值语句右侧的类型仍为全新的对象字面量类型。
若仍将“{ x: number,y: number }”视为目标对象类型,那么源对象类型“{ x: 0, y: 0,z: 0 }”存在一个多余属性z。
目标对象类型中的可选属性与必选属性是被同等对待的。
例如,下例中point的类型为弱类型,而赋值语句右侧源类型中的属性z仍然是多余属性:
const point: { x?: number; y?: number } = {
x: 0,
y: 0,
z: 0,
// ~~~~
// z是多余属性
};
多余属性检查
多余属性检查是TypeScript 1.6引入的功能。
多余属性会影响类型间的子类型兼容性以及赋值兼容性,也就是说编译器不允许在一些操作中存在多余属性。
例如,将对象字面量赋值给变量或属性时,或者将对象字面量作为函数参数来调用函数时,编译器会严格检查是否存在多余属性。若存在多余属性,则会产生编译错误。
let point: {
x: number;
y: number;
} = { x: 0, y: 0, z: 0 };
// ~~~~
// 编译错误!z是多余属性
function f(point: { x: number; y: number }) {}
f({ x: 0, y: 0, z: 0 });
// ~~~~
// 编译错误!z是多余属性
在了解了多余属性检查的基本原理之后,让我们来思考一下它背后的设计意图。
在正常的使用场景中,如果我们直接将一个对象字面量赋值给某个确定类型的变量,那么通常没有理由去故意添加多余属性。
const point: { x: number; y: number } = {
x: 0,
y: 0,
z: 0,
// ~~~~
// z是多余属性
};
此例中明确定义了常量point的类型是只包含两个属性x和y的对象类型。
在使用对象字面量构造该类型的值时,自然而然的做法是构造一个完全符合该类型定义的值,即只包含两个属性x和y的对象,完全没有理由再添加多余的属性。
让我们再换一个角度,从类型可靠性的角度来看待多余属性检查。
当把对象字面量赋值给目标对象类型时,若存在多余属性,那么将意味着对象字面量本身的类型彻底丢失了
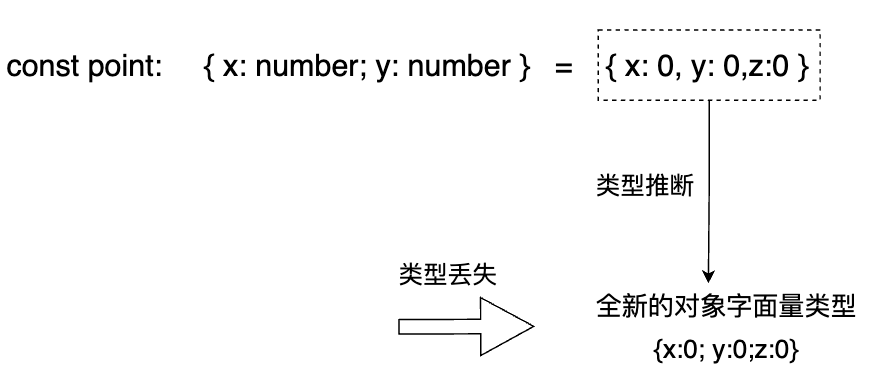
此例中,将包含多余属性的对象字面量赋值给类型为“{ x:number; y: number }”的point常量后,程序中就再也无法引用对象字面量“{ x: 0, y: 0, z: 0 }”的类型了。
从类型系统的角度来看,该赋值操作造成了类型信息的永久性丢失,因此编译器认为这是一个错误。
多余属性检查能够带来的最直接的帮助是发现属性名的拼写错误。
01 const task: { canceled?: boolean } = { cancelled: true};
02 // ~~~~~~~~~~~~~~~
03 // 编译错误!对象字面量只允许包含已知属性
04 // 'cancelled'不存在于'{ canceled?: boolean }'类型中
05 // 是否指的是'canceled'属性
此例中,常量task的类型为“{ canceled?: boolean }”。其中,canceled属性是可选属性,因此允许不设置该属性的值。
如果编译器能够执行多余属性检查,那么它能够识别出对象字面量中的cancelled属性是一个多余属性,从而产生编译错误。
更好的是,编译器不但能够提示多余属性的错误,还能够根据算法来推测可能的属性名。这也是为什么在第5行中,编译器能够提示出“是否指的是'canceled'属性?”这条消息。
允许多余属性
多余属性检查在绝大多数场景中都是合理的,因此推荐在程序中尽可能地利用这个功能。但如果确定不想让编译器对代码进行多余属性检查,那么有多种方式能够实现这个效果。
const point: { x: number } = { x: 0, y: 0 };
// ~~~~
// y是多余属性
能够忽略多余属性检查的方法如下:
使用类型断言,这是推荐的方法
类型断言能够对类型进行强制转换。
例如,我们可以将对象字面量“{x: 0, y: 0 }”的类型强制转换为“{ x: number }”类型。关于类型断言的详细介绍请参考类型断言。类型断言能够绕过多余属性检查的真正原因是,处于类型断言表达式中的对象字面量将不再是“全新的对象字面量类型”,因此编译器也就不会对其进行多余属性检查,下例中的第5行代码能够证明这一点
// 无编译错误
const p0: { x: number } = { x: 0, y: 0 } as { x:number };
// 无编译错误
const p1: { x: number } = { x: 0, y: 0 } as { x: 0; y:
};
启用“--suppressExcessPropertyErrors”编译选项
启用该编译选项能够完全禁用整个TypeScript工程的多余属性检查,但同时也将完全失去多余属性检查带来的帮助。我们可以在tsconfig.json配置文件中或命令行上启用该编译选项。
使用“// @ts-ignore”注释指令
该注释指令能够禁用针对某一行代码的类型检查。
// @ts-ignore
const point: { x: number } = { x: 0, y: 0 };
为目标对象类型添加索引签名
若目标对象类型上存在索引签名,那么目标对象可以接受任意属性,因此也就谈不上多余属性。
const point: {
x: number;
[prop: string]: number; // 索引签名
} = { x: 0, y: 0 };
最后一种方法也许不是很好理解
如果我们先将对象字面量赋值给某个变量,然后再将该变量赋值给目标对象类型,那么将不会执行多余属性检查。这种方法能够生效的原理与类型断言类似,那就是令源对象类型不为“全新的对象字面量类型”,于是编译器将不执行多余属性检查。下面代码的第4行,赋值语句右侧不是对象字面量,而是一个标识符,因此temp的类型不是“全新的对象字面量类型”
const temp = { x: 0, y: 0 };
// 无编译错误
const point: { x: number } = temp;
函数类型
将介绍如何为函数添加类型,包括参数类型、返回值类型、this类型以及函数重载等
常规参数类型
在函数形式参数列表中,为参数添加类型注解就能够定义参数的类型。
针对函数表达式和匿名函数,我们也可以使用相同的方法来定义参数的类型。
如果在函数形式参数列表中没有明确指定参数类型,并且编译器也无法推断参数类型,那么参数类型将默认为any类型。
注意,如果启用了“--noImplicitAny”编译选项。我们必须指明参数的类型,如果期望的类型就是any类型,则需要使用类型注解来明确地标注,否则会产生编译错误。
可选参数类型
在JavaScript中,函数的每一个参数都是可选参数,而在TypeScript中,默认情况下函数的每一个参数都是必选参数。
在调用函数时,编译器会检查传入实际参数的个数与函数定义中形式参数的个数是否相等。
如果两者不相等,则会产生编译错误。如果一个参数是可选参数,那么就需要在函数类型定义中明确指定。
在函数形式参数名后面添加一个问号“?”就可以将该参数声明为可选参数。也可以同时定义多个可选参数。
函数的可选参数必须位于函数参数列表的末尾位置。在可选参数之后不允许再出现必选参数,否则将产生编译错误。
如果函数的某个参数是可选参数,那么在调用该函数时既可以传入对应的实际参数,也可以完全不传入任何实际参数。
在“--strictNullChecks”模式下,TypeScript会自动为可选参数添加undefined类型。TypeScript允许给可选参数传入一个undefined值。
需要注意的是,为参数添加undefined类型不等同于该参数是可选参数。若省略了“?”符号,则参数将成为必选参数,在调用时必须传入一个实际参数值。
默认参数类型
函数默认参数类型可以通过类型注解定义,也可以根据默认参数值自动地推断类型。
function add(x: number = 0, y = 0) {
return x + y;
}
如果函数定义了默认参数,并且默认参数处于函数参数列表末尾的位置,那么该参数将被视为可选参数,在调用该函数时可以不传入对应的实际参数值。
在语法上,同一个函数参数不允许同时声明为可选参数和默认参数,否则将产生编译错误。
function f(x?: number = 0) {
// ~
// 编译错误!参数不能同时使用?符号和初始化值
}
如果默认参数之后存在必选参数,那么该默认参数不是可选的参数,在调用函数时必须传入对应的实际参数值。
剩余参数类型
必选参数、可选参数和默认参数处理的都是单个参数,而剩余参数处理的则是多个参数。
如果函数定义中声明了剩余参数,那么在调用函数时会将多余的实际参数收集到剩余参数列表中。因此,剩余参
数的类型应该为数组类型或元组类型。
数组类型的剩余参数
最常见的做法是将剩余参数的类型声明为数组类型。
function f(...args: number[]) {}
在调用定义了剩余参数的函数时,剩余参数可以接受零个或多个实际参数。
元组类型的剩余参数
剩余参数的类型也可以定义为元组类型。
如果剩余参数的类型为元组类型,那么编译器会将剩余参数展开为独立的形式参数声明,主要包括以下几种情况:
- 常规元组类型
- 带有可选元素的元组类型
- 带有剩余元素的元组类型
// 常规元素类型
function f0(...args: [boolean, number]) {}
// 等同于:
function f1(args_0: boolean, args_1: number) {}
// 带有可选元素的元组类型
function f0(...args: [boolean, string?]) {}
// 等同于:
function f1(args_0: boolean, args_1?: string) {}
// 带有剩余元素的元组类型
function f0(...args: [boolean, ...string[]]) {}
// 等同于:
function f1(args_0: boolean, ...args_1: string[]) {}
解构参数类型
我们可以使用类型注解为解构参数添加类型信息
function f0([x, y]: [number, number]) {}
f0([0, 1]);
function f1({ x, y }: { x: number; y: number }) {}
f1({ x: 0, y: 1 });
返回值类型
在函数形式参数列表之后,可以使用类型注解为函数添加返回值类型。
在绝大多数情况下,TypeScript能够根据函数体内的return语句等自动推断出返回值类型,因此我们也可以省略返回值类型。
在TypeScript的原始类型里有一个特殊的空类型void,该类型唯一有意义的使用场景就是作为函数的返回值类型。
如果一个函数的返回值类型为void,那么该函数只能返回undefined值。这意味着函数明确地返回了一个undefined值,或者函数没有调用return语句,在这种情况下函数默认返回undefined值。
如果没有启用“--strictNullChecks”编译选项,那么void返回值类型也允许返回null值。
函数类型字面量
函数类型字面量是定义函数类型的方法之一,它能够指定函数的参数类型、返回值类型以及泛型类型参数。函数类型字面量的语法与箭头函数的语法相似。
(ParameterList) => Type
在该语法中,ParameterList表示可选的函数形式参数列表;Type表示函数返回值类型;形式参数列表与返回值类型之间使用胖箭头“=>”连接。
在函数类型字面量中定义函数参数的类型时,必须包含形式参数名,不允许只声明参数的类型。
函数类型字面量中的返回值类型必须明确指定,不允许省略。如果函数没有返回值,则需要指定void类型作为返回值类型。
调用签名
函数在本质上是一个对象,但特殊的地方在于函数是可调用的对象。因此,可以使用对象类型来表示函数类型。若在对象类型中定义了调用签名类型成员,那么我们称该对象类型为函数类型。
{
(ParameterList): Type
}
在该语法中,ParameterList表示函数形式参数列表类型,Type表示函数返回值类型,两者都是可选的。
实际上,上一节介绍的函数类型字面量完全等同于仅包含一个类型成员并且是调用签名类型成员的对象类型字面量。换句话说,函数类型字面量是仅包含单个调用签名的对象类型字面量的简写形式,
{ ( ParameterList ): Type }
// 简写为:
( ParameterList ) => Type
函数类型字面量的优点是简洁,而对象类型字面量的优点是具有更强的类型表达能力。
我们知道函数是一种对象,因此函数可以拥有自己的属性。
下例中,函数f除了可以被调用以外,还提供了一个version属性
function f(x: number) {
console.log(x);
}
f.version = '1.0';
f(1); // 1
f.version; // '1.0'
构造函数类型字面量
在面向对象编程中,构造函数是一类特殊的函数,它用来创建和初始化对象。JavaScript中的函数可以作为构造函数使用,在调用构造函数时需要使用new运算符。
构造函数类型字面量是定义构造函数类型的方法之一,它能够指定构造函数的参数类型、返回值类型以及泛型类型参数。
new ( ParameterList ) => Type
在该语法中,new是关键字,ParameterList表示可选的构造函数形式参数列表类型,Type表示构造函数返回值类型。
构造签名
构造签名的用法与调用签名类似。若在对象类型中定义了构造签名类型成员,那么我们称该对象类型为构造函数类型。
{
new (ParameterList): Type
}
在该语法中,new是运算符关键字,ParameterList表示构造函数形式参数列表类型,Type表示构造函数返回值类型,两者都是可选的
构造函数类型字面量完全等同于仅包含一个类型成员并且是构造签名类型成员的对象类型字面量。换句话说,构造函数类型字面量是仅包含单个构造签名的对象类型字面量的简写形式。
{ new ( ParameterList ): Type }
// 简写为:
new ( ParameterList ) => Type
调用签名与构造签名
有一些函数被设计为既可以作为普通函数使用,同时又可以作为构造函数来使用。例如,JavaScript内置的“Number()”函数和“String()”函数等都属于这类函数。
若在对象类型中同时定义调用签名和构造签名,则能够表示既可以被直接调用,又可以作为构造函数使用的函数类型。
{
new (x: number): Number; // <- 构造签名
(x: number): number; // <- 调用签名
}
重载函数
重载函数是指一个函数同时拥有多个同类的函数签名。
例如,一个函数拥有两个及以上的调用签名,或者一个构造函数拥有两个及以上的构造签名。当使用不同数量和类型的参数调用重载函数时,可以执行不同的函数实现代码。
TypeScript中的重载函数与其他编程语言中的重载函数略有不同。
首先,让我们看一个重载函数的例子。下例中定义了一个重载函数add。它接受两个参数,若两个参数的类型为number,则返回它们的和;若两个参数的类型为数组,则返回合并后的数组。在调用add函数时,允许使用这两个调用签名之一并且能够得到正确的返回值类型。
function add(x: number, y: number): number;
function add(x: any[], y: any[]): any[];
function add(x: number | any[], y: number | any[]):any {
if (typeof x === 'number' && typeof y ==='number') {
return x + y;
}
if (Array.isArray(x) && Array.isArray(y)) {
return [...x, ...y];
}
}
const a: number = add(1, 2);
const b: number[] = add([1], [2]);
在使用函数声明定义函数时能够定义重载函数。重载函数的定义由以下两部分组成:
- 一条或多条函数重载语句
- 一条函数实现语句
函数重载
不带有函数体的函数声明语句叫作函数重载。
function add(x: number, y: number): number;
函数重载的语法中不包含函数体,它只提供了函数的类型信息。函数重载只存在于代码编译阶段,在编译生成JavaScript代码时会被完全删除,因此在最终生成的JavaScript代码中不包含函数重载的代码。
函数重载允许存在一个或多个,但只有多于一个的函数重载才有意义,因为若只有一个函数重载,则可以直接定义函数实现。
不允许使用默认参数。函数重载应该位于函数实现(将在下一节中介绍)之前,每一个函数重载中的函数名和函数实现中的函数名必须一致。
同时需要注意,在各个函数重载语句之间以及函数重载语句与函数实现语句之间不允许出现任何其他语句,否则将产生编译错误**。
函数实现
函数实现包含了实际的函数体代码,该代码不仅在编译时存在,在编译生成的JavaScript代码中同样存在。
每一个重载函数只允许有一个函数实现,并且它必须位于所有函数重载语句之后,否则将产生编译错误。
TypeScript中的重载函数最令人迷惑的地方在于,函数实现中的函数签名不属于重载函数的调用签名之一,只有函数重载中的函数签名能够作为重载函数的调用签名。
function add(x: number, y: number): number;
function add(x: any[], y: any[]): any[];
function add(x: number | any[], y: number | any[]):any {
// 省略了实现代码
}
因此,我们可以使用两个number类型的值来调用add函数,或者使用两个数组类型的值来调用add函数。
但是,不允许使用一个number类型和一个数组类型的值来调用add函数,尽管在函数实现的函数签名中允许这种调用方式。
// 正确的调用方式
add(1, 2);
add([1], [2]);
// 错误的调用方式
add(1, [2]);
add([1], 2);
函数实现需要兼容每个函数重载中的函数签名,函数实现的函数签名类型必须能够赋值给函数重载的函数签名类型。
function foo(x: number): boolean;
// ~~~
// 编译错误:重载签名与实现签名的返回值类型不匹配
function foo(x: string): void;
// ~~~
// 编译错误:重载签名与实现签名的参数类型不匹配
function foo(x: number): void {
// 省略函数体代码
}
此例中,重载函数foo可能的参数类型为number类型或string类型,同时返回值类型可能为boolean类型或void类型。因此,在函数实现中的参数x必须同时兼容number类型和string类型,而返回值类型则需要兼容boolean类型和void类型。
在其他一些编程语言中允许存在多个函数实现,并且在调用重载函数时编程语言负责选择合适的函数实现执行。在TypeScript中,重载函数只存在一个函数实现,开发者需要在这个唯一的函数实现中实现所有函数重载的功能。
这就需要开发者自行去检测参数的类型及数量,并根据判断结果去执行不同的操作。
function add(x: number, y: number): number;
function add(x: any[], y: any[]): any[];
function add(x: number | any[], y: number | any[]):any {
if (typeof x === 'number' && typeof y ==='number') {
return x + y;
}
if (Array.isArray(x) && Array.isArray(y)) {
return [...x, ...y];
}
}
TypeScript不支持为不同的函数重载分别定义不同的函数实现。从这点上来看,TypeScript中的函数重载不是特别便利
函数重载解析顺序
当程序中调用了一个重载函数时,编译器将首先构建出一个候选函数重载列表。
一个函数重载需要满足如下条件才能成为本次函数调用的候选函数重载:
- 函数实际参数的数量不少于函数重载中定义的必选参数的数量。
- 函数实际参数的数量不多于函数重载中定义的参数的数量。
- 每个实际参数的类型能够赋值给函数重载定义中对应形式参数的类型。
候选函数重载列表中的成员将以函数重载的声明顺序作为初始顺序,然后进行简单的排序,将参数类型中包含字面量类型的函数重载排名提前。
function f(x: string): void; // <- 函数重载1
function f(y: 'specialized'): void; // <- 函数重载2
function f(x: string) {
// 省略函数体代码
}
f('specialized');
此例第7行,使用字符串参数'specialized'调用重载函数f时,函数重载1和函数重载2都满足候选函数重载的条件,因此两者都在候选函数重载列表中。但是因为函数重载2的函数签名中包含字面量类型,所以比函数重载1的优先级更高。
若候选函数重载列表中存在一个或多个函数重载,则使用列表中第一个函数重载。
因此,此例中将使用函数重载2。
如果构建的候选函数重载列表为空列表,则会产生编译错误。
f(1); // 编译错误
通过以上的介绍我们能够知道,函数重载的解析顺序依赖于函数重载的声明顺序以及函数签名中是否包含字面量类型。
因此,TypeScript中的函数重载功能可能没有其他一些编程语言那么“智能”。这就要求开发者在编写函数重载代码时一定要将最精确的函数重载定义放在最前面,因为它们定义的顺序将影响函数调用签名的选择。
function f(x: any): number; // <- 函数重载1
function f(x: string): 0 | 1; // <- 函数重载2
function f(x: any): any {
// ...
}
const a: 0 | 1 = f('hi');
// ~
// 编译错误!类型 'number' 不能赋值给类型 '0 | 1'
此例中,函数重载2比函数重载1更加精确,但函数重载2是在函数重载1之后定义的。
由于函数重载2的参数中不包含字面量类型,因此编译器不会对候选函数重载列表进行重新排序。
第7行,当使用字符串调用函数f时,函数重载1位于候选函数重载列表的首位,并被选为最终使用的函数重载。
我们能看到“f('hi')”的返回值类型为number类型,而不是更精确的“0 | 1”联合类型。
若想要修复这个问题,只需将函数重载1和函数重载2的位置互换即可。
因为TypeScript语言的自身特点,所以它提供的函数重载功能可能不如其他编程语言那样便利。
实际上在很多场景中我们并不需要声明重载函数,尤其是在函数返回值类型不变的情况下。
function foo(x: string): boolean;
function foo(x: string, y: number): boolean;
function foo(x: string, y?: number): boolean {
// ...
}
const a = foo('hello');
const b = foo('hello', 2);
function bar(x: string, y?: number): boolean {
// ...
}
const c = bar('hello');
const d = bar('hello', 1);
此例中,foo函数是重载函数,而bar函数则为普通函数声明。
两个函数在功能上以及可接受的参数类型和函数返回值类型都是相同的。
但是,bar函数的声明代码更少也更加清晰。
重载函数的类型
重载函数的类型可以通过包含多个调用签名的对象类型来表示。
function f(x: string): 0 | 1;
function f(x: any): number;
function f(x: any): any {
// ...
}
我们可以使用如下对象类型字面量来表示重载函数f的类型。
在该对象类型字面量中,定义了两个调用签名类型成员,分别对应于重载函数的两个函数重载。
{
(x: string): 0 | 1;
(x: any): number;
}
在定义重载函数的类型时,有以下两点需要注意:
- 函数实现的函数签名不属于重载函数的调用签名之一。
- 调用签名的书写顺序是有意义的,它决定了函数重载的解析顺序,一定要确保更精确的调用签名位于更靠前的位置。
对象类型字面量以及后面会介绍的接口都能够用来定义重载函数的类型,但是函数类型字面量无法定义重载函数的类型,因为它只能够表示一个调用签名。
构造函数重载
构造函数也支持重载并且与本节介绍的重载函数是类似的,请参考 类类型。
函数中this值的类型
this是JavaScript中的关键字,它可以表示调用函数的对象或者实例对象等。
本节将介绍函数声明和函数表达式中this值的类型。
在默认情况下,编译器会将函数中的this值设置为any类型,并允许程序在this值上执行任意的操作。
因为,编译器不会对any类型进行类型检查。
function f() {
// 以下语句均没有错误
this.a = true;
this.b++;
this.c = () => {};
}
--noImplicitThis
将this值的类型设置为any类型对类型检查没有任何帮助。
因此,TypeScript提供了一个“--noImplicitThis”编译选项。
当启用了该编译选项时,如果this值默认获得了any类型,那么将产生编译错误;
如果函数体中没有引用this值,则没有任何影响。
/**
* --noImplicitThis=true
*/
function f0() {
this.a = true; // 编译错误
this.b++; // 编译错误
this.c = () => {}; // 编译错误
}
// 没有错误
function f1() {
const a = true;
}
函数中this值的类型可以通过一个特殊的this参数来定义。下面我们将介绍这个特殊的this参数。
函数的this参数
TypeScript支持在函数形式参数列表中定义一个特殊的this参数来描述该函数中this值的类型。
function foo(this: { name: string }) {
this.name = 'Patrick';
this.name = 0;
// ~~~~~~~~~
// 编译错误!类型 0 不能赋值给类型 'string'
}
this参数固定使用this作为参数名。
this参数是一个可选的参数,若存在,则必须作为函数形式参数列表中的第一个参数。
this参数的类型即为函数体中this值的类型。
this参数不同于常规的函数形式参数,它只存在于编译阶段,在编译生成的JavaScript代码中会被完全删除,在运行时的代码中不存在这个this参数。
如果我们想要定义一个纯函数或者是不想让函数代码依赖于this的值,那么在这种情况下可以明确地将this参数定义为void类型。
这样做之后,在函数体中就不允许读写this的属性和方法。
function add(this: void, x: number, y: number) {
this.name = 'Patrick';
// ~~~~
// 编译错误:属性 'name' 不存在于类型 'void'
}
当调用定义了this参数的函数时,若this值的实际类型与函数定义中的期望类型不匹配,则会产生编译错误。
function foo(this: { bar: string }, baz: number) {
// ...
}
// 编译错误
// 'this'类型为'void',不能赋值给 '{ bar: string }' 类型的this
foo(0);
foo.call({ bar: 'hello' }, 0); // 正确
接口
类似于对象类型字面量,接口类型也能够表示任意的对象类型。
不同的是,接口类型能够给对象类型命名以及定义类型参数。接口类型无法表示原始类型,如boolean类型等。
接口声明只存在于编译阶段,在编译后生成的JavaScript代码中不包含任何接口代码。
接口声明
interface InterfaceName
{
TypeMember;
TypeMember;
...
}
在该语法中,interface是关键字,InterfaceName表示接口名,它必须是合法的标识符,TypeMember表示接口的类型成员,所有类型成员都置于一对大括号“{}”之内。
从语法的角度来看,接口声明就是在对象类型字面量之前添加了interface关键字和接口名。
同样地,接口类型的类型成员也分为以下五类:
- 属性签名
- 调用签名
- 构造签名
- 方法签名
- 索引签名
在对象类型中已经介绍了属性签名,函数类型中已经介绍了调用签名和构造签名;这三种类型成员同样适用于接口类型,将简单介绍。这里将重点介绍索引签名和方法签名。
属性签名
属性签名声明了对象类型中属性成员的名称和类型。
PropertyName: Type;
在该语法中,PropertyName表示对象属性名,可以为标识符、字符串、数字和可计算属性名;Type表示该属性的类型。
interface Point {
x: number;
y: number;
}
关于属性签名的详细介绍请参考
对象类型字面量。
调用签名
调用签名定义了该对象类型表示的函数在调用时的类型参数、参数列表以及返回值类型。
(ParameterList): Type
在该语法中,ParameterList表示函数形式参数列表类型;Type表示函数返回值类型,两者都是可选的。
interface ErrorConstructor {
(message?: string): Error;
}
关于调用签名的详细介绍请参考
调用签名。
构造签名
构造签名定义了该对象类型表示的构造函数在使用new运算符调用时的参数列表以及返回值类型。
new (ParameterList): Type
在该语法中,new是运算符关键字;ParameterList表示构造函数形式参数列表类型;Type表示构造函数返回值类型,两者都是可选的。
interface ErrorConstructor {
new (message?: string): Error;
}
关于调用签名的详细介绍请参考
构造签名。
方法签名
方法签名是声明函数类型的属性成员的简写。
PropertyName(ParameterList): Type
在该语法中,PropertyName表示对象属性名,可以为标识符、字符串、数字和可计算属性名;ParameterList表示可选的方法形式参数列表类型;Type表示可选的方法返回值类型。
从语法的角度来看,方法签名是在调用签名之前添加一个属性名作为方法名。
方法签名是声明函数类型的属性成员的简写
PropertyName(ParameterList): Type
//等同于
PropertyName: { (ParameterList): Type }
在改写后的语法中,属性名保持不变并使用对象类型字面量和调用签名来表示函数类型。
由于该对象类型字面量中仅包含一个调用签名,因此也可以使用函数类型字面量来代替对象类型字面量。
PropertyName: (ParameterList) => Type
下面我们通过一个真实的例子来演示这三种可以互换的接口定义方式:
interface A {
f(x: boolean): string; // 方法签名
}
interface B {
f: { (x: boolean): string }; // 属性签名和对象类型字面量
}
interface C {
f: (x: boolean) => string; // 属性签名和函数类型字面量
}
方法签名中的属性名可以为可计算属性名,这一点与属性签名中属性名的规则是相同的。
若接口中包含多个名字相同但参数列表不同的方法签名成员,则表示该方法是重载方法。
interface A {
f(): number;
f(x: boolean): boolean;
f(x: string, y: string): string;
}
索引签名
JavaScript支持使用索引去访问对象的属性,即通过方括号“[]”语法去访问对象属性。
一个典型的例子是数组对象,我们既可以使用数字索引去访问数组元素,也可以使用字符串索引去访问数组对象上的属性和方法。
接口中的索引签名能够描述使用索引访问的对象属性的类型。索引签名只有以下两种:
- 字符串索引签名
- 数值索引签名
字符串索引签名
[IndexName: string]: Type
在该语法中,IndexName表示索引名,它可以为任意合法的标识符。索引名只起到占位的作用,它不代表真实的对象属性名;在字符串索引签名中,索引名的类型必须为string类型;Type表示索引值的类型,它可以为任意类型。
interface A {
[prop: string]: number;
}
一个接口中最多只能定义一个字符串索引签名。字符串索引签名会约束该对象类型中所有属性的类型。
例如,下例中的字符串索引签名定义了索引值的类型为number类型。那么,该接口中所有属性的类型必须能够赋值给number类型。
interface A {
[prop: string]: number;
a: number;
b: 0;
c: 1 | 2;
}
此例中,属性a、b和c的类型都能够赋值给字符串索引签名中定义的number类型,因此不会产生错误。
interface B {
[prop: string]: number;
a: boolean; // 编译错误
b: () => number; // 编译错误
c(): number; // 编译错误
}
此例中,字符串索引签名中定义的索引值类型依旧为number类型。属性a的类型为boolean类型,它不能赋值给number类型,因此产生编译错误。属性b和方法c的类型均为函数类型,不能赋值给number类型,因此也会产生编译错误 。
数值索引签名
[IndexName: number]: Type
在该语法中,IndexName表示索引名,它可以为任意合法的标识符。索引名只起到占位的作用,它不代表真实的对象属性名;在数值索引签名中,索引名的类型必须为number类型;Type表示索引值的类型,它可以为任意类型。
interface A {
[prop: number]: string;
}
一个接口中最多只能定义一个数值索引签名。数值索引签名约束了数值属性名对应的属性值的类型。
interface A {
[prop: number]: string;
}
const obj: A = ['a', 'b', 'c'];
obj[0]; // string
若接口中同时存在字符串索引签名和数值索引签名,那么数值索引签名的类型必须能够赋值给字符串索引签名的类型。
因为在JavaScript中,对象的属性名只能为字符串(或Symbol)。虽然JavaScript也允许使用数字等其他值作为对象的索引,但最终它们都会被转换为字符串类型。因此,数值索引签名能够表示的属性集合是字符串索引签名能够表示的属性集合的子集。
可选属性与方法
在默认情况下,接口中属性签名和方法签名定义的对象属性都是必选的。
在给接口类型赋值时,如果未指定必选属性则会产生编译错误。
interface Foo {
x: string;
y(): number;
}
const a: Foo = { x: 'hi' };
// ~
// 编译错误!缺少属性 'y'
const b: Foo = { y() { return 0; } };
// ~
// 编译错误!缺少属性 'x'
// 正确
const c: Foo = {
x: 'hi',
y() { return 0; }
};
我们可以在属性名或方法名后添加一个问号“?”,从而将该属性或方法定义为可选的。
PropertyName?: Type
PropertyName?(ParameterList): Type
关于可选属性的详细介绍请参考
对象类型字面量。
如果接口中定义了重载方法,那么所有重载方法签名必须同时为必选的或者可选的。
// 正确
interface Foo {
a(): void;
a(x: boolean): boolean;
b?(): void;
b?(x: boolean): boolean;
}
interface Bar {
a(): void;
a?(x: boolean): boolean;
// ~
// 编译错误:重载签名必须全部为必选的或可选的
}
只读属性与方法
在接口声明中,使用readonly修饰符能够定义只读属性。readonly修饰符只允许在属性签名和索引签名中使用
readonly PropertyName: Type;
readonly [IndexName: string]: Type
readonly [IndexName: number]: Type
interface A {
readonly a: string;
readonly [prop: string]: string;
readonly [prop: number]: string;
}
若接口中定义了只读的索引签名,那么接口类型中的所有属性都是只读属性。
interface A {
readonly [prop: string]: number;
}
const a: A = { x: 0 };06
a.x = 1; // 编译错误!不允许修改属性值
如果接口中既定义了只读索引签名,又定义了非只读的属性签名,那么非只读的属性签名定义的属性依旧是非只读的,除此之外的所有属性都是只读的。
interface A {
readonly [prop: string]: number;
x: number;
}
const a: A = { x: 0, y: 0 };
a.x = 1; // 正确
a.y = 1; // 错误
接口的继承
接口可以继承其他的对象类型,这相当于将继承的对象类型中的类型成员复制到当前接口中。
接口可以继承的对象类型如下:
- 接口
- 对象类型的类型别名
- 类
- 对象类型的交叉类型
本节将通过接口与接口之间的继承来介绍接口继承的具体使用方法。关于类型别名的详细介绍请参考
类型别名。关于类的详细介绍请参考类。关于交叉类型的详细介绍请参考交叉类型。
接口的继承需要使用extends关键字。
interface Shape {
name: string;
}
interface Circle extends Shape {
radius: number;
}
一个接口可以同时继承多个接口,父接口名之间使用逗号分隔。
interface Style {
color: string;
}
interface Shape {
name: string;
}
interface Circle extends Style, Shape {
radius: number;
}
当一个接口继承了其他接口后,子接口既包含了自身定义的类型成员,也包含了父接口中的类型成员。
interface Style {
color: string;
}
interface Shape {
name: string;
}
interface Circle extends Style, Shape {
radius: number;
}
const c: Circle = {
color: 'red',
name: 'circle',
radius: 1
};
如果子接口与父接口之间存在同名的类型成员,那么子接口中的类型成员具有更高的优先级。
同时,子接口与父接口中的同名类型成员必须是类型兼容的。也就是说,子接口中同名类型成员的类型需要能够赋值给父接口中同名类型成员的类型,否则将产生编译错误。
interface Style {
color: string;
}
interface Shape {
name: string;
}
interface Circle extends Style, Shape {
name: 'circle'; // 此时name类型为字面量类型 'circle'而非 string;子接口的类型成员的优先级更高
color: number;
// ~~~~~~~~~~~~~
// 编译错误:'color' 类型不兼容,
// 'number' 类型不能赋值给 'string' 类型
}
此例中,Circle接口同时继承了Style接口和Shape接口。Circle接口与父接口之间存在同名的属性name和color。
Circle接口中name属性的类型为字符串字面量类型'circle',它能够赋值给Shape接口中string类型的name属性,因此是正确的。
而Circle接口中color属性的类型为number,它不能够赋值给Style接口中string类型的color属性,因此产生编译错误
如果仅是多个父接口之间存在同名的类型成员,而子接口本身没有该同名类型成员,那么父接口中同名类型成员的类型必须是完全相同, 否则将产生编译错误。
interface Style {
draw(): { color: string };
}
interface Shape {
draw(): { x: number; y: number };
}
interface Circle extends Style, Shape {}
// ~~~~~~
// 编译错误
解决这个问题的一个办法是,在Circle接口中定义一个同名的draw方法。这样Circle接口中的draw方法会拥有更高的优先级,从而取代父接口中的draw方法。这时编译器将不再进行类型合并操作,因此也就不会发生合并冲突。但是要注意,Circle接口中定义的draw方法一定要与所有父接口中的draw方法是类型兼容的。
类型别名
如同接口声明能够为对象类型命名,类型别名声明则能够为TypeScript中的任意类型命名。
类型别名声明
type AliasName = Type
在该语法中,type是声明类型别名的关键字;AliasName表示类型别名的名称;Type表示类型别名关联的具体类型。
类型别名的名称必须为合法的标识符。
由于类型别名表示一种类型,因此类型别名的首字母通常需要大写。
同时需要注意,不能使用TypeScript内置的类型名作为类型别名的名称,例如boolean、number和any等。
类型别名引用的类型可以为任意类型,例如原始类型、对象类型、联合类型和交叉类型等。
在类型别名中,也可以引用其他类型别名。
类型别名不会创建出一种新的类型,它只是给已有类型命名并直接引用该类型。
在程序中,使用类型别名与直接使用该类型别名引用的类型是完全等价的。
因此,在程序中可以直接使用类型别名引用的类型来替换掉类型别名。
递归的类型别名
一般情况下,在类型别名声明中赋值运算符右侧的类型不允许引用当前定义的类型别名。
因为类型别名对其引用的类型使用的是及早求值的策略,而不是惰性求值的策略。
因此,如果类型别名引用了自身,那么在解析类型别名时就会出现无限递归引用的问题。
type T = T;
// ~
// 编译错误!类型别名 'T' 存在循环的自身引用
在TypeScript 3.7版本中,编译器对类型别名的解析进行了一些优化。
在类型别名所引用的类型中,使用惰性求值的策略来解析泛型类型参数。
因此,允许在泛型类型参数中递归地使用类型别名。
总结起来,目前允许在以下场景中使用递归的类型别名:
- 若类型别名引用的类型为接口类型、对象类型字面量、函数类型字面量和构造函数类型字面量,则允许递归引用类型别名。
type T0 = { name: T0 };
type T1 = () => T1;
type T2 = new () => T2;
- 若类型别名引用的是数组类型或元组类型,则允许在元素类型中递归地引用类型别名。
type T0 = Array<T0>;
type T1 = T1[];
type T3 = [number, T3];
- 若类型别名引用的是泛型类或泛型接口,则允许在类型参数中递归的引用类型别名。
interface A<T> {
name: T;
}
type T0 = A<T0>;
class B<T> {
name: T | undefined;
}
type T1 = B<T1>;
类型别名与接口
类型别名与接口相似,它们都可以给类型命名并通过该名字来引用表示的类型。
虽然在大部分场景中两者是可以互换使用的,但类型别名和接口之间还是存在一些差别。
区别之一,类型别名能够表示非对象类型,而接口则只能表示对象类型。
因此,当我们想要表示原始类型、联合类型和交叉类型等类型时只能使用类型别名。
type NumericType = number | bigint;
区别之二,接口可以继承其他的接口、类等对象类型,而类型别名则不支持继承。
若要对类型别名实现类似继承的功能,则需要使用一些变通方法。
例如,当类型别名表示对象类型时,可以借助于交叉类型来实现继承的效果。
此例中的方法只适用于表示对象类型的类型别名。如果类型别名表示非对象类型,则无法使用该方法。
type Shape = { name: string };
type Circle = Shape & { radius: number };
function foo(circle: Circle) {
const name = circle.name;
const radius = circle.radius;
}
区别之三,接口名总是会显示在编译器的诊断信息(例如,错误提示和警告)和代码编辑器的智能提示信息中,而类型别名的名字只在特定情况下才会显示出来。
只有当类型别名表示数组类型、元组类型以及类或接口的泛型实例类型时,才会在相关提示信息中显示类型别名的名字。
区别之四,接口具有声明合并的行为,而类型别名则不会进行声明合并。
关于声明合并的详细介绍请参考
声明合并
类
类的定义
虽然JavaScript语言支持了类,但其本质上仍是函数,类是一种语法糖。
TypeScript语言对JavaScript中的类进行了扩展,为其添加了类型支持,如实现接口、泛型类等。
定义一个类需要使用class关键字。类似于函数定义,类的定义也有以下两种方式:
- 类声明
- 类表达式
类声明
class ClassName {
// ...
}
在该语法中,class是关键字;ClassName表示类的名字。
在类声明中的类名是必选的。按照惯例,类名的首字母应该大写。
与函数声明不同的是,类声明不会被提升,因此必须先声明后使用。
在使用类声明时,不允许声明同名的类,否则将产生错误。
const c0 = new Circle(); // 错误
class Circle {
radius: number;
}
const c1 = new Circle(); // 正确
类表达式
const Name = class ClassName {
// ...
};
在该语法中,class是关键字;Name表示引用了该类的变量名;ClassName表示类的名字。
在类表达式中,类名ClassName是可选的。
如果在类表达式中定义了类名,则该类名只能够在类内部使用,在类外不允许引用该类名。
const A = class B {
name = B.name;
};
const b = new B(); // 错误
成员变量
在类中定义成员变量的方法如下所示:
class Circle {
radius: number = 1;
}
此例中,Circle类只包含一个成员变量。其中,radius是成员变量名,成员变量名之后的类型注解定义了该成员变量的类型。最后,我们将该成员变量的初始值设置为1。
除了在成员变量声明中设置初始值,我们还可以在类的构造函数中设置成员变量的初始值。
class Circle {
radius: number;
constructor() {
this.radius = 1;
}
}
此例中,在构造函数里将radius成员变量的值初始化为1。
同时注意,在构造函数中引用成员变量时需要使用this关键字。
--strictPropertyInitialization
虽然为类的成员变量设置初始值是可选的,但是对成员变量进行初始化是一个好的编程实践,它能够有效避免使用未初始化的值而引发的错误。
因此,TypeScript提供了“--strictPropertyInitialization”编译选项来帮助严格检查未经初始化的成员变量。当启用了该编译选项时,成员变量必须在声明时进行初始化或者在构造函数中进行初始化,否则将产生编译错误。
需要注意的是,“--strictPropertyInitialization”编译选项必须与“--strictNullChecks”编译选项同时启用,否则“--strictPropertyInitialization”编译选项将不起作用。
若启用了“--strictPropertyInitialization”编译选项并且仅在构造函数中对成员变量进行了初始化操作,那么需要在构造函数中直接进行赋值操作。
如果通过在构造函数中调用某个方法,进而在该方法中间接地初始化成员变量,那么编译器将无法检测到该初始化操作,因此会产生编译错误。
/**
* --strictNullChecks=true
* --strictPropertyInitialization=true
*/
class A {
// 编译错误!未初始化
a: number;
init() {
this.a = 0;
}
constructor() {
this.init();
}
}
在一些场景中,我们确实想要通过调用某些方法来初始化类的成员变量。这时可以使用非空类型断言“!”来通知编译器该成员变量已经进行初始化,以此来避免产生编译错误。
/**
* --strictNullChecks=true
* --strictPropertyInitialization=true
*/
class A {
a!: number;
// ~
// 非空类型断言
init() {
this.a = 0;
}
constructor() {
this.init();
}
}
readonly属性
在声明类的成员变量时,在成员变量名之前添加readonly修饰符能够将该成员变量声明为只读的。
只读成员变量必须在声明时初始化或在构造函数里初始化。
class A {
readonly a = 0;
readonly b: number;
readonly c: number; // 编译错误
constructor() {
this.b = 0;
}
}
不管是在类的内部还是外部,都不允许修改只读成员变量的值。
关于类只读成员变量的一个最佳实践是,若类的成员变量不应该被修改,那么应该为其添加readonly修饰符。
就算不确定是否允许修改类的某个成员变量,也可以先将该成员变量声明为只读的,当发现需要对该成员变量进行修改时再将readonly修饰符去掉。
成员函数
成员函数也称作方法,声明成员函数与在对象字面量中声明方法是类似的。
在成员函数中,需要使用this关键字来引用类的其他成员。
class Circle {
radius: number = 1;
area(): number {
return Math.PI * this.radius * this.radius;
}
}
成员存取器
成员存取器由get和set方法构成,并且会在类中声明一个属性。
成员存取器的定义方式与对象字面量中属性存取器的定义方式是完全相同的。
如果一个类属性同时定义了get方法和set方法,那么get方法的返回值类型必须与set方法的参数类型一致,否则将产生错误。
如果一个类属性同时定义了get方法和set方法,那么get方法和set方法必须具有相同的可访问性。
class C {
/**
* 正确
*/
private _foo: number = 0;
get foo(): number {
return this._foo;
}
set foo(value: number) {}
/**
* 错误!'get' 和 'set' 存取器必须具有相同的类型
*/
private _bar: string = '';
get bar(): string {
return this._bar;
}
set bar(value: number) {}
}
存取器是实现数据封装的一种方式,它提供了一层额外的访问控制。
类可以将成员变量的访问权限制在类内部,在类外部通过存取器方法来间接地访问成员变量。
在存取器方法中,还可以加入额外的访问控制等处理逻辑。
索引成员
类的索引成员会在类的类型中引入索引签名。
索引签名包含两种,分别为字符串索引签名和数值索引签名。
在实际应用中,定义类的索引成员并不常见。
类中所有的属性和方法必须符合字符串索引签名定义的类型。
同时,只有当类具有类似数组的行为时,数值索引签名才有意义。
类的索引成员与接口中的索引签名类型成员具有完全相同的语法和语义,这里不再重复。
class A {
x: number = 0;
[prop: string]: number;
[prop: number]: number;
}
在类的索引成员上不允许定义可访问性修饰符,如public和private等。
成员可访问性
成员可访问性定义了类的成员允许在何处被访问。
TypeScript为类成员提供了以下三种可访问性修饰符:
- public
- protected
- private
这三种可访问性修饰符是TypeScript语言对JavaScript语言的补充。
在JavaScript语言中不支持这三种可访问性修饰符。
public
类的公有成员没有访问限制,可以在当前类的内部、外部以及派生类的内部访问。
类的公有成员使用public修饰符标识。
在默认情况下,类的所有成员都是公有成员。
因此,在定义公有成员时也可以省略public修饰符。
protected
类的受保护成员允许在当前类的内部和派生类的内部访问,但是不允许在当前类的外部访问。
类的受保护成员使用protected修饰符标识
class Base {
protected x: string = '';
a() {
this.x; // 允许访问
}
}
class Derived extends Base {
b() {
this.x; // 允许访问
}
}
const base = new Base();
base.x; // 不允许访问
private
类的私有成员只允许在当前类的内部被访问,在当前类的外部以及派生类的内部都不允许访问。
类的私有成员使用private修饰符标识。
class Base {
private x: string = '';
a() {
this.x; // 允许访问
}
}
class Derived extends Base {
b() {
this.x; // 不允许访问
}
}
const base = new Base();
base.x; // 不允许访问
const derived = new Derived();
derived.x; // 不允许访问
私有字段
2020年1月,ECMAScript标准引入了一个新特性,那就是允许在类中定义私有字段。
这意味着JavaScript语言将原生地支持类的私有成员。
TypeScript语言也从3.8版本开始支持该特性。
在ECMAScript标准中,类的私有字段使用一种新的语法来定义,即在字段标识符前添加一个“#”符号。
不论是在定义私有字段时还是在访问私有字段时,都需要在私有字段名前添加一个“#”符号。
class Circle {
#radius: number;
constructor() {
this.#radius = 1;
}
}
const circle = new Circle();
circle.#radius; // 不允许访问
此例中,“#radius”定义了一个私有字段radius。不论是在定义私有字段时还是在访问私有字段时,都必须在字段标识符前添加一个“#”符号。
构造函数
构造函数用于创建和初始化类的实例。
当使用new运算符调用一个类时,类的构造函数就会被调用。
构造函数以constructor作为函数名。
class Circle {
radius: number;
constructor(r: number) {
this.radius = r;
}
}
const c = new Circle(1);
与普通函数相同,在构造函数中也可以定义可选参数、默认值参数和剩余参数。
但是构造函数不允许定义返回值类型,因为构造函数的返回值类型永远为类的实例类型。
在构造函数上也可以使用可访问性修饰符。它描述的是在何处允许使用该类来创建实例对象。
在默认情况下,构造函数是公有的。如果将构造函数设置成私有的,则只允许在类的内部创建该类的对象。
例如,下例中Singleton类的构造函数是私有的,因此只允许在Singleton类内部创建该类的实例对象。
第15行,在Singleton类外部创建其实例对象时将产生编译错误。
class Singleton {
private static instance?: Singleton;
private constructor() {}
static getInstance() {
if (!Singleton.instance) {
// 允许访问
Singleton.instance = new Singleton();
}
return Singleton.instance;
}
}
new Singleton(); // 编译错误
与函数重载类似,构造函数也支持重载。
我们将没有函数体的构造函数声明称为构造函数重载,同时将定义了函数体的构造函数声明称为构造函数实现。构造函数重载可以存在零个或多个,而构造函数实现只能存在一个。
class A {
constructor(x: number, y: number);
constructor(s: string);
constructor(xs: number | string, y?: number) {}
}
const a = new A(0, 0);
const b = new A('foo');
参数成员
TypeScript提供了一种简洁语法能够把构造函数的形式参数声明为类的成员变量,它叫作参数成员。
在构造函数参数列表中,为形式参数添加任何一个可访问性修饰符或者readonly修饰符,该形式参数就成了参数成员,进而会被声明为类的成员变量。
class A {
constructor(public x: number) {}
}
const a = new A(0);
a.x; // 值为0
此例在类A的构造函数中,参数x是一个参数成员,因此会在类A中声明一个public的成员变量x。
第5行,使用实际参数0来实例化类A时会自动将成员变量x的值初始化为0,因此第6行读取成员变量x的值时结果为0。我们不需要在构造函数中使用“this.x = x”来设置成员变量x的值,TypeScript能够自动处理。
readonly修饰符也可以和任意一个可访问性修饰符结合使用来定义只读的参数成员。
继承
继承是面向对象程序设计的三个基本特征之一,TypeScript中的类也支持继承。
在定义类时可以使用extends关键字来指定要继承的类,具体语法如下所示:
class DerivedClass extends BaseClass { }
在该语法中,我们将BaseClass叫作基类,将DerivedClass叫作派生类,派生类继承了基类。
有时候,我们也将基类称作父类,将派生类称作子类。
当派生类继承了基类后,就自动继承了基类的非私有成员。
例如,下例中Circle类继承了Shape类。因此,Circle类获得了Shape类的color和switchColor公有成员。
我们可以在Circle类的实例对象上访问color成员变量和调用switchColor成员函数。
class Shape {
color: string = 'black';
switchColor() {
this.color =
this.color === 'black' ? 'white' : 'black';
}
}
class Circle extends Shape {}
const circle = new Circle();
circle.color; // 'black'
circle.switchColor();
circle.color; // 'white'
重写基类成员
在派生类中可以重写基类的成员变量和成员函数。
在重写成员变量和成员函数时,需要在派生类中定义与基类中同名的成员变量和成员函数。
class Shape {
color: string = 'black';
switchColor() {
this.color =
this.color === 'black' ? 'white' : 'black';
}
}
class Circle extends Shape {
color: string = 'red';
switchColor() {
this.color = this.color === 'red' ? 'green' :'red';
}
}
const circle = new Circle();
circle.color; // 'red'21 circle.switchColor();
circle.color; // 'green'
在派生类中,可以通过super关键字来访问基类中的非私有成员。
当派生类和基类中存在同名的非私有成员时,在派生类中只能通过super关键字来访问基类中的非私有成员,无法使用this关键字来引用基类中的非私有成员。
class Shape {
color: string = 'black';
switchColor() {
this.color =
this.color === 'black' ? 'white' : 'black';
}
}
class Circle extends Shape {
switchColor() {
super.switchColor();
console.log(`Color is ${this.color}.`);
}
}
const circle = new Circle();
circle.switchColor();20 circle.switchColor();
// 打印:
// Color is white.
// Color is black.
若派生类重写了基类中的受保护成员,则可以将该成员的可访问性设置为受保护的或公有的。
也就是说,在派生类中只允许放宽基类成员的可访问性。
class Base {
protected x: string = '';
protected y: string = '';
protected z: string = '';
}
class Derived extends Base {
// 正确
public x: string = '';
// 正确
protected y: string = '';
// 错误!派生类不能够将基类的受保护成员重写为更严格的可访问性
private z: string = '';
}
由于派生类是基类的子类型,因此在重写基类的成员时需要保证子类型兼容性。
class Shape {
color: string = 'black';
switchColor() {
this.color =
this.color === 'black' ? 'white' :'black';
}
}
class Circle extends Shape {
// 编译错误
// 类型'(color: string) => void'不能赋值给类型'() =>void'
switchColor(color: string) {}
}
关于子类型兼容性的详细介绍请参考
子类型兼容性
派生类实例化
在派生类的构造函数中必须调用基类的构造函数,否则将不能正确地实例化派生类。
在派生类的构造函数中使用“super()”语句就能够调用基类的构造函数。
若派生类中定义了构造函数,但没有添加“super()”语句,那么将产生编译错误。
class Shape {
color: string = 'black';
constructor() {
this.color = 'black';
}
switchColor() {
this.color =
this.color === 'black' ? 'white' :'black';
}
}
class Circle extends Shape {
radius: number;
constructor() {
super();
this.radius = 1;
}
}
在派生类的构造函数中,引用了this的语句必须放在“super()”调用的语句之后,否则将产生编译错误,因为在基类初始化之前访问类的成员可能会产生错误。
在实例化派生类时的初始化顺序如下:
- 初始化基类的属性
- 调用基类的构造函数
- 初始化派生类的属性
- 调用派生类的构造函数
下例中的数字标识与上面的步骤序号是对应的:
class Shape {
color: string = 'black'; // 1
constructor() { // 2
console.log(this.color);
this.color = 'white';
console.log(this.color);
}
}
class Circle extends Shape {
radius: number = 1; // 3
constructor() { // 4
super();
console.log(this.radius);
this.radius = 2;
console.log(this.radius);
}
}
const circle = new Circle();
// 输出结果为:
// black
// white
// 1
// 2
接口继承类
TypeScript允许接口继承类。若接口继承了一个类,那么该接口会继承基类中所有成员的类型。
例如,下例中接口B继承了类A。因此,接口B中包含了string类型的成员x和方法类型y。
class A {
x: string = '';
y(): boolean {
return true;
}
}
interface B extends A {}
declare const b: B;
b.x; // 类型为string
b.y(); // 类型为boolean
在接口继承类时,接口不但会继承基类的公有成员类型,还会继承基类的受保护成员类型和私有成员类型。
如果接口从基类继承了非公有成员,那么该接口只能由基类或基类的子类来实现。
// 正确,A 可以实现接口 I,因为私有属性和受保护属性源自同一个类A
class A implements I {
private x: string = '';
protected y: string = '';
}
// 接口 I 能够继承 A 的私有属性和受保护属性
interface I extends A {}
// 正确,B 可以实现接口 I,因为私有属性和受保护属性源自同一个类A
class B extends A implements I {}
// 错误!C 不是 A 的子类,无法实现 A 的有属性和受保护属性
class C implements I {}
实现接口
虽然一个类只允许继承一个基类,但是可以实现一个或多个接口。
在定义类时,使用implements语句能够声明类所实现的接口。
当实现多个接口时,接口名之间使用逗号“,”分隔。
interface A {}
interface B {}
class C implements A, B {}
如果类的定义中声明了要实现的接口,那么这个类就需要实现接口中定义的类型成员。
下例中,Circle类声明了要实现Shape 和Color两个接口。因此,在Circle类中需要实现两个接口中定义的类型成员color和area。
interface Color {
color: string;
}
interface Shape {
area(): number;
}
class Circle implements Shape, Color {
radius: number = 1;
color: string = 'black';
area(): number {
return Math.PI * this.radius * this.radius;
}
}
静态成员
类的定义中可以包含静态成员。
类的静态成员不属于类的某个实例,而是属于类本身。
类的静态成员使用static关键字定义,并且只允许通过类名来访问。
class Circle {
static version: string = '1.0';
}
// 正确,结果为 '1.0'
const version = Circle.version;
const circle = new Circle();
circle.version;
// ~~~~~~~
// 编译错误!'version' 属性是 'Circle' 类的静态属性
静态成员可访问性
类的静态成员也可以定义不同的可访问性,如public、private和protected。
类的public静态成员对访问没有限制,可以在当前类的内部、外部以及派生类的内部访问。
class Base {
public static x: string = '';
a() {
// 正确,允许在类内部访问公有静态成员 x
Base.x;
}
}
class Derived extends Base {
b() {
// 正确,允许在派生类内部访问公有静态成员 x
Base.x;
}
}
// 正确,允许在类外部访问公有静态成员 x
Base.x;
类的protected静态成员允许在当前类的内部和派生类的内部访问,但是不允许在当前类的外部访问。
class Base {
protected static x: string = '';
a() {
// 正确,允许在类内部访问受保护的静态成员 x
Base.x;
}
}
class Derived extends Base {
b() {
// 正确,允许在派生类内部访问受保护的静态成员 x
Base.x;
}
}
// 错误!不允许在类外部访问受保护的静态成员 x
Base.x;
类的private静态成员只允许在当前类的内部访问。
class Base {
private static x: string = '';
a() {
// 正确,允许在类内部访问受保护的静态成员 x
Base.x;
}
}
class Derived extends Base {
b() {
// 错误!不允许在派生类内部访问受保护的静态成员 x
Base.x;
}
}
// 错误!不允许在类外部访问受保护的静态成员 x
Base.x;
继承静态成员
类的public静态成员和protected静态成员也可以被继承。
class Base {
public static x: string = '';
protected static y: string = '';
}
class Derived extends Base {
b() {
// 继承了基类的静态成员 x
Derived.x;
// 继承了基类的静态成员 y
Derived.y;
}
}
抽象类和抽象成员
前面介绍的类和类的成员都属于具体类和具体类成员。
TypeScript也支持定义抽象类和抽象类成员。
抽象类和抽象类成员都使用abstract关键字来定义。
抽象类
定义抽象类时,只需要在class关键字之前添加abstract关键字即可。
abstract class A {}
抽象类与具体类的一个重要区别是,抽象类不能被实例化。
也就是说,不允许使用new运算符来创建一个抽象类的实例。
抽象类的作用是作为基类使用,派生类可以继承抽象类。
抽象类也可以继承其他抽象类。
抽象类中允许(通常)包含抽象成员,也允许包含非抽象成员。
抽象成员
在抽象类中允许声明抽象成员,抽象成员不允许包含具体实现代码。
// 以下用法均为正确用法
abstract class A {
abstract a: string;
abstract b: number = 0;
abstract method(): string;
abstract get accessor(): string;
abstract set accessor(value: string);
}
abstract class B {
// 编译错误!抽象方法不能带有具体实现
abstract method() {}
// 编译错误!抽象存取器不能带有具体实现
abstract get c(): string { return ''; };
abstract set c(value: string) {};
}
如果一个具体类继承了抽象类,那么在具体的派生类中必须实现抽象类基类中的所有抽象成员。
因此,抽象类中的抽象成员不能声明为private,否则将无法在派生类中实现该成员。
若没有正确地在具体的派生类中实现抽象成员,将产生编译错误。
this类型
在类中存在一种特殊的this类型,它表示当前this值的类型。
我们可以在类的非静态成员的类型注解中使用this类型。
例如,下例中add()方法和subtract()方法的返回值类型为this类型。
第20行,我们可以链式调用add()方法和subtract()方法,因为它们返回的是当前实例对象。
01 class Counter {
02 private count: number = 0;
03
04 public add(): this {
05 this.count++;
06 return this;
07 }
08 public subtract(): this {
09 this.count--;
10 return this;
11 }
12
13 public getResult(): number {
14 return this.count;
15 }
16 }
17
18 const counter = new Counter();
19
20 counter
21 .add()
22 .add()
23 .subtract()
24 .getResult(); // 结果为1
需要强调的是,this类型是动态的,表示当前this值的类型。
当前this值的类型不一定是引用了this类型的那个类,该差别主要体现在类之间有继承关系的时候。
class A {
foo(): this {
return this;
}
}
class B extends A {
bar(): this {
return this;
}
}
const b = new B();
const x = b.bar().foo();
// ~
// 类型为B
此例中,foo方法和bar方法的返回值类型都是this类型,且B继承了A。第14行,通过B类的实例来调用foo方法和bar方法时,返回值类型都是B类的实例类型。
注意,this类型不允许应用于类的静态成员。
class A {
static a: this;
// ~~~~
// 编译错误! 'this' 类型只能用于类的非静态成员
}
类类型
类声明将会引入一个新的命名类型,即与类同名的类类型。类类型表示类的实例类型,它由类的实例成员类型构成。
例如,下例中Circle类声明同时也定义了Circle类类型,该类型包含number类型的radius属性和函数类型的area属性。该类类型与CircleType接口表示的对象类型是相同的类型。
class Circle {
radius: number;
area(): number {
return Math.PI * this.radius * this.radius;
}
}
interface CircleType {
radius: number;
area(): number;
}
// 正确
const a: Circle = new Circle();
// 正确
const b: CircleType = new Circle();
在定义一个类时,实际上我们定义了一个构造函数。随后,我们可以使用new运算符和该构造函数来创建类的实例。我们可以将该类型称作类的构造函数类型,在该类型中也包含了类的静态成员类型。
例如,下例中常量a的类型是类类型A,也就是我们经常提到的类的实例类型。常量b的类型是类的构造函数类型,我们使用了包含构造签名的接口表示该类型,并将类A赋值给了常量b。不难发现,类的静态成员x是类构造函数类型的一部分。
class A {
static x: number = 0;
y: number = 0;
}
// 类类型,即实例类型
const a: A = new A();
interface AConstructor {
new (): A;
x: number;
}
// 类构造函数类型
const b: AConstructor = A;
TypeScript类型进阶
泛型
泛型程序设计是一种编程风格或编程范式,它允许在程序中定义形式类型参数,然后在泛型实例化时使用实际类型参数来替换形式类型参数。
通过泛型,我们能够定义通用的数据结构或类型,这些数据结构或类型仅在它们操作的实际类型上有差别。泛型程序设计是实现可重用组件的一种手段。
泛型简介
function identity<T>(arg: T): T {
return arg;
}
此例中,T是identity函数的一个类型参数,它能够捕获identity函数的参数类型并用作返回值类型。
从identity函数的类型注解中我们能够观察到,传入参数的类型与返回值类型是相同的类型,两者均为类型T。
我们称该版本的identity函数为泛型函数。
在调用identity泛型函数时,我们能够为类型参数T传入一个实际类型。
function identity<T>(arg: T): T {
return arg;
}
const foo = identity<string>('foo');
// ~~~
// 能够推断出 'foo' 的类型为 'string'
const bar = identity<string>(true);
// ~~~~
// 编译错误!
// 类型为 'true' 的参数不能赋值给类型为 'string' 的参数
此例第5行,在调用identity函数时指定了类型参数T的实际类型为string类型,编译器能够推断出返回值的类型也为string类型。
第9行,在调用identity函数时,实际类型参数与函数实际参数的类型不兼容,因此产生了错误。
在大部分情况下,程序中不需要显式地指定类型参数的实际类型。TypeScript编译器能够根据函数调用的实际参数自动地推断出类型参数的实际类型。
例如,下例中在调用identity泛型函数时没有指定类型参数T的实际类型,但是编译器能够根据传入的实际参数的类型推断出泛型类型参数T的实际类型,进而又能够推断出identity泛型函数的返回值类型。
function identity<T>(arg: T): T {
return arg;
}
const foo = identity('foo');
// ~~~~~
// 能够推断出foo的类型为'foo'
const bar = identity(true);
// ~~~~
// 能够推断出bar的类型为true
形式类型参数
形式类型参数声明
泛型类型参数能够表示绑定到泛型类型或泛型函数调用的某个实际类型。
在类声明、接口声明、类型别名声明以及函数声明中都支持定义类型参数。
泛型形式类型参数列表定义的具体语法如下所示:
<TypeParameter, TypeParameter, ...>
在该语法中,TypeParameter表示形式类型参数名,形式类型参数需要置于“<”和“>”符号之间。
当同时存在多个形式类型参数时,类型参数之间需要使用逗号“,”进行分隔。
形式类型参数名必须为合法的标识符。
形式类型参数名通常以大写字母开头,因为它代表一个类型。
在一些编程风格指南中,推荐给形式类型参数取一个具有描述性的名字,如TResponse,同时还建议形式类型参数名以大写字母T(Type的首字母)作为前缀。
另一种流行的命名方法是使用单个大写字母作为形式类型参数名。该风格的命名通常由字母T开始,并依次使用后续的U、V等大写字母。若形式类型参数列表中只存在一个或者少量的类型参数,可以考虑采用该风格,但前提是不能影响程序的可读性。
类型参数默认类型
在声明形式类型参数时,可以为类型参数设置一个默认类型,这类似于函数默认参数。
类型参数默认类型的语法如下所示:
<T = DefaultType>
该语法中,T为形式类型参数,DefaultType为类型参数T的默认类型,两者之间使用等号连接。
类型参数的默认类型也可以引用形式类型参数列表中的其他类型参数,但是只能引用在当前类型参数左侧(前面)定义的类型参数。例如,下例中类型参数U的默认类型为类型参数T。
<T, U = T>
可选的类型参数
如果一个形式类型参数没有定义默认类型,那么它是一个必选类型参数;反之,如果一个形式类型参数定义了默认类型,那么它是一个可选的类型参数。
在形式类型参数列表中,必选类型参数不允许出现在可选类型参数之后。
<T = boolean, U> // 错误
<T, U = boolean> // 正确
编译器以从左至右的顺序依次解析并设置类型参数的默认类型。
若一个类型参数的默认类型引用了其左侧声明的类型参数,则没有问题;若一个类型参数的默认类型引用了其右侧声明的类型参数,则会产生编译错误,因为此时引用的类型参数处于未定义的状态。
<T = U, U = boolean> // 错误
<T = boolean, U = T> // 正确
实际类型参数
在引用泛型类型时,可以传入一个实际类型参数作为形式类型参数的值,该过程称作泛型的实例化。
传入实际类型参数的语法如下所示
<Type, Type, ...>
在该语法中,实际类型参数列表置于“<”和“>”符号之间;Type表示一个实际类型参数,如原始类型、接口类型等;多个实际类型参数之间使用逗号“,”分隔。
function identity<T>(arg: T): T {
return arg;
}
identity<number>(1);
identity<Date>(new Date());
当显式地传入实际类型参数时,只有必选类型参数是一定要提供的,可选类型参数可以被省略,这时可选类型参数将使用其默认类型。
泛型约束
泛型约束声明
在泛型的形式类型参数上允许定义一个约束条件,它能够限定类型参数的实际类型的最大范围。
我们将类型参数的约束条件称为泛型约束。
定义泛型约束的语法如下所示
<TypeParameter extends ConstraintType>
该语法中,TypeParameter表示形式类型参数名;extends是关键字;ConstraintType表示一个类型,该类型用于约束TypeParameter的可选类型范围。
对于一个形式类型参数,可以同时定义泛型约束和默认类型,但默认类型必须满足泛型约束。
<TypeParameter extends ConstraintType = DefaultType>
如果泛型形式类型参数定义了泛型约束,那么传入的实际类型参数必须符合泛型约束,否则将产生错误。
泛型约束引用类型参数
在泛型约束中,约束类型允许引用当前形式类型参数列表中的其他类型参数。
例如,下例中形式类型参数U引用了在其左侧定义的形式类型参数T作为约束类型:
<T, U extends T>
下例中,形式类型参数T引用了在其右侧定义的形式类型参数U:
<T extends U, U>
需要注意的是,一个形式类型参数不允许直接或间接地将其自身作为约束类型,否则将产生循环引用的编译错误。
<T extends T> // 错误
<T extends U, U extends T> // 错误
基约束
本质上,每个类型参数都有一个基约束(Base Constraint),它与是否在形式类型参数上定义了泛型约束无关。
类型参数的实际类型一定是其基约束的子类型。对于任意的类型参数T,其基约束的计算规则有三个。
规则一,如果类型参数T声明了泛型约束,且泛型约束为另一个类型参数U,那么类型参数T的基约束为类型参数U。示例如下:
<T extends U> // 类型参数T的基约束为类型参数U
规则二,如果类型参数T声明了泛型约束,且泛型约束为某一具体类型Type,那么类型参数T的基约束为类型Type。示例如下:
<T extends boolean>
规则三,如果类型参数T没有声明泛型约束,那么类型参数T的基约束为空对象类型字面量“{}”。
除了undefined类型和null类型外,其他任何类型都可以赋值给空对象类型字面量。示例如下:
<T> // 类型参数T的基约束为"{}"类型
常见错误
01 interface Point {
02 x: number;
03 y: number;
04 }
05
06 function f<T extends Point>(arg: T): T {
07 return { x: 0, y: 0 };
08 // ~~~~~~~~~~~~~~~~~~~~~~
09 // 编译错误!类型 '{ x: number; y: number; }' 不能赋值给类型 'T'
10 }
此例第7行,第一感觉可能是这段代码没有错误,因为返回值“{x: 0, y: 0 }”的类型是泛型约束Point类型的子类型。
实际上,这段代码是错误的,因为f函数的返回值类型应该与传入参数arg的类型相同,而不能仅满足泛型约束。
从下例中可以更容易地发现问题所在:
function f<T extends boolean>(obj: T): T {
return true;
}
f<false>(false); // 返回值类型应该为false
此例中,泛型函数f的泛型约束为boolean类型,函数f的参数类型和返回值类型相同,均为类型参数T,函数体中直接返回了true值。
第5行,调用泛型函数f时传入了实际类型参数为false类型。
因此,函数f的参数类型和返回值类型都应均为false类型。但实际上根据泛型函数f的实现,其返回值类型为true类型。
泛型函数
若一个函数的函数签名中带有类型参数,那么它是一个泛型函数。
泛型函数中的类型参数用来描述不同参数之间以及参数和函数返回值之间的关系。
泛型函数中的类型参数既可以用于形式参数的类型,也可以用于函数返回值类型。
泛型函数定义
函数签名分为调用签名和构造签名。这两种函数签名都支持定义类型参数。
定义泛型调用签名的语法如下所示:
<T>(x: T): T
在该语法中,T为泛型形式类型参数。
定义泛型构造签名的语法如下所示:
new <T>(): T[];
在该语法中,T为泛型形式类型参数。
泛型函数示例
function f0<T>(x: T): T {
return x;
}
const a: string = f0<string>('a');
const b: number = f0<number>(0);
function f1<T>(x: T, y: T): T[] {
return [x, y];
}
const a: number[] = f1<number>(0, 1);
const b: boolean[] = f1<boolean>(true, false);
function f2<T, U>(x: T, y: U): { x: T; y: U } {
return { x, y };
}
const a: { x: string; y: number } = f2<string, number>('a', 0);
const b: { x: string; y: string } = f2<string, string>('a', 'aa');
function f3<T, U>(a: T[], f: (x: T) => U): U[] {
return a.map(f);
}
const a: boolean[] = f3<number, boolean>([0, 1, 2], n=> !!n);
泛型函数类型推断
在上一节的所有示例中,我们在调用泛型函数时都显式地指定了实际类型参数。
在大部分情况下,TypeScript编译器能够自动推断出泛型函数的实际类型参数。
如果没有传入实际类型参数,编译器也能够推断出实际类型参数,甚至比显式指定实际类型参数更加精确。
function f0<T>(x: T): T {
return x;
}
const a = f0('a');
// ~~
// 推断出实际类型参数为:'a'
const b = f0('b');
// ~
// 推断出 b 的类型为 'b' 而不是 string
此例第5行,在调用泛型函数f0时没有传入实际类型参数,但是编译器能够推断出实际类型参数T为字符串字面量类型“'a'”。与此同时,编译器也能够推断出常量a的类型为字符串字面量类型“'a'”,因为泛型函数f0的返回值类型为字符串字面量类型“'a'”。
另一点值得注意的是,此例中编译器推断出的实际类型参数不是string类型,而是字符串字面量类型“'a'”和“'b'”。因为TypeScript有一个原则,始终将字面量视为字面量类型,只在必要的时候才会将字面量类型放宽为某种基础类型,例如string类型。
此例中,字符串字面量类型“'a'”是比string类型更加精确的类型。在实际使用中,我们也正是希望编译器能够尽可能地帮助细化类型。
关于类型放宽的详细介绍参考
类型放宽,关于类型细化的详情介绍参考类型细化。
泛型函数注意事项
有些泛型函数完全可以定义为非泛型函数,也就是说没有必要使用泛型函数。如果一个函数既可以定义为非泛型函数,又可以定义为泛型函数,那么推荐使用非泛型函数的形式,因为它会更简洁也更易于理解。
当泛型函数的类型参数只在函数签名中出现了一次(自身定义除外)时,该泛型函数是非必要的。
function f<T>(x: T): void {
console.log(x);
}
首先,函数f是一个合法的泛型函数。此例中,在类型参数声明“<T>”之外,类型参数T只出现了一次,即“(x: T)”。在这种情况下,泛型函数就不是必需的,完全可以通过非泛型函数来实现相同的功能。
function f0(x: string): void {
console.log(x);
}
function f1(x: any): void {
console.log(x);
}
该问题的实质是,泛型函数的类型参数是用来关联多个不同值的类型的,如果一个类型参数只在函数签名中出现一次,则说明它与其他值没有关联,因此不需要使用类型参数,直接声明实际类型即可。
从技术上讲,几乎任何函数都可以声明为泛型函数。
若泛型函数的类型参数不表示参数之间或参数与返回值之间的某种关系,那么使用泛型函数可能是一种反模式。
泛型接口
若接口的定义中带有类型参数,那么它是泛型接口。
在泛型接口定义中,形式类型参数列表紧随接口名之后。
泛型接口定义的语法如下所示:
interface MyArray<T> extends Array<T> {
first: T | undefined;
last: T | undefined;
}
此例中,我们定义了泛型接口MyArray,它包含一个类型参数T。
类型参数既可以用在接口的extends语句中,如“Array<T>”,也可以用在接口类型成员上,如“first: T | undefined”。
在引用泛型接口时,必须指定实际类型参数,除非类型参数定义了默认类型。
泛型类型别名
若类型别名的定义中带有类型参数,那么它是泛型类型别名。
泛型类型别名定义
在泛型类型别名定义中,形式类型参数列表紧随类型别名的名字之后。
在引用泛型类型别名表示的类型时,必须指定实际类型参数。
泛型类型别名定义的语法如下所示:
type Nullable<T> = T | undefined | null;
定义了一个名为Nullable的泛型类型别名,它有一个形式类型参数T。
该泛型类型别名表示可以为空的T类型,即“Nullable<T>”类型的值也可以为undefined或null。
泛型类
若类的定义中带有类型参数,那么它是泛型类。
在泛型类定义中,形式类型参数列表紧随类名之后。定义泛型类的语法如下所示:
class Container<T> {
constructor(private readonly data: T) {}
}
const a = new Container<boolean>(true);
const b = new Container<number>(0);
泛型类中的类型参数允许在类的继承语句和接口实现语句中使用,即extends语句和implements语句。
每个类声明都会创建两种类型,即类的实例类型和类的构造函数类型。
泛型类描述的是类的实例类型。
因为类的静态成员是类构造函数类型的一部分,所以泛型类型参数不能用于类的静态成员。
也就是说,在类的静态成员中不允许引用类型参数。
示例如下:
class Container<T> {
static version: T;
// ~
// 编译错误!静态成员不允许引用类型参数
constructor(private readonly data: T) {}
}
局部类型
TypeScript支持声明具有块级作用域的局部类型,主要包括:
- 局部枚举类型
- 局部类类型
- 局部接口类型
- 局部类型别名
function f<T>() {
enum E {
A,
B,
}
class C {
x: string | undefined;
}
// 允许带有泛型参数
interface I<T> {
x: T;
}
// 可以引用其他局部类型
type A = E.A | E.B;
}
此例中,枚举类型E、类类型C、接口类型I和类型别名A都是局部类型。
局部类型也允许带有类型参数,并且可以引用外层作用域中的类型参数。
类似于let声明和const声明,局部类型拥有块级作用域。
例如,下例中在if分支和else支持中均声明了接口T,它们仅在各自所处的块级作用域内生效。
因此,这两个接口T不会相互影响,并且if分支中的代码也无法引用else分支中的接口T。
function f(x: boolean) {
if (x) {
interface T {
x: number;
}
const v: T = { x: 0 };
} else {
interface T {
x: string;
}
const v: T = { x: 'foo' };
}
}
联合类型
联合类型由一组有序的成员类型构成。
联合类型表示一个值的类型可以为若干种类型之一。
例如,联合类型“string | number”表示一个值的类型既可以为string类型也可以为number类型
联合类型通过联合类型字面量来定义。
联合类型字面量
联合类型由两个或两个以上的成员类型构成,各成员类型之间使用竖线符号“|”分隔。
示例如下:
type NumericType = number | bigint;
此例中,定义了一个名为NumericType的联合类型。
该联合类型由两个成员类型组成,即number类型和bigint类型。
若一个值既可能为number类型又可能为bigint类型,那么我们说该值的类型为联合类型“number | bigint”。
联合类型的成员类型可以为任意类型,如原始类型、数组类型、对象类型,以及函数类型等。
如果联合类型中存在相同的成员类型,那么相同的成员类型将被合并为单一成员类型。
联合类型是有序的成员类型的集合。
在绝大部分情况下,成员类型满足类似于数学中的“加法交换律”,即改变成员类型的顺序不影响联合类型的结果类型。
// T0与T1表示相同的类型
type T0 = string | number;
type T1 = number | string;
联合类型中的类型成员同样满足类似于数学中的“加法结合律”。
对部分类型成员使用分组运算符不影响联合类型的结果类型
// T0与T1表示相同的类型
type T0 = (boolean | string) | number;
type T1 = boolean | (string | number);
联合类型的成员类型可以进行化简。
假设有联合类型“U = T0 |T1”,如果T1是T0的子类型,那么可以将类型成员T1从联合类型U中消去。
最后,联合类型U的结果类型为“U = T0”。
// 'true' 和 'false' 类型是 'boolean' 类型的子类型
type T0 = boolean | true | false;
// 所以T0等同于 T1
type T1 = boolean;
联合类型的类型成员
像接口类型一样,联合类型作为一个整体也可以有类型成员,只不过联合类型的类型成员是由其成员类型决定的。
属性签名
若联合类型U中的每个成员类型都包含一个同名的属性签名M,那么联合类型U也包含属性签名M。
interface Circle {
area: number;
radius: number;
}
interface Rectangle {
area: number;
width: number;
height: number;
}
type Shape = Circle | Rectangle;
此例中,因为Circle类型与Rectangle类型均包含名为area的属性签名类型成员,所以联合类型Shape也包含名为area的属性签名类型成员。
因此,允许访问Shape类型上的area属性。
type Shape = Circle | Rectangle;
declare const s: Shape;
s.area; // number
因为radius、width和height类型成员不是 Circle类型和Rectangle类型的共同类型成员,因此它们不是Shape联合类型的类型成员。
type Shape = Circle | Rectangle;
declare const s: Shape;
s.radius; // 错误
s.width; // 错误
s.height; // 错误
对于联合类型的属性签名,其类型为所有成员类型中该属性类型的联合类型。
例如,下例中联合类型“Circle | Rectangle”具有属性签名area,其类型为Circle类型中area属性的类型和Rectangle类型中area属性的类型组成的联合类型,即“bigint | number”类型。
interface Circle {
area: bigint;
}
interface Rectangle {
area: number;
}
declare const s: Circle | Rectangle;
s.area; // bigint | number
如果联合类型的属性签名在某个成员类型中是可选属性签名,那么该属性签名在联合类型中也是可选属性签名;否则,该属性签名在联合类型中是必选属性签名。
interface Circle {
area: bigint;
}
interface Rectangle {
area?: number;
}
declare const s: Circle | Rectangle;
s.area; // bigint | number | undefine
此例中,area属性在Rectangle类型中是可选的属性。
因此,在联合类型“Circle | Rectangle”中,area属性也是可选属性。
索引签名
索引签名包含两种,即字符串索引签名和数值索引签名。在联合类型中,这两种索引签名具有相似的行为。
如果联合类型中每个成员都包含字符串索引签名,那么该联合类型也拥有了字符串索引签名,字符串索引签名中的索引值类型为每个成员类型中索引值类型的联合类型;否则,该联合类型没有字符串索引签名。
如果联合类型中每个成员都包含数值索引签名,那么该联合类型也拥有了数值索引签名,数值索引签名中的索引值类型为每个成员类型中索引值类型的联合类型;否则,该联合类型没有数值索引签名。
调用签名与构造签名
如果联合类型中每个成员类型都包含相同参数列表的调用签名,那么联合类型也拥有了该调用签名,其返回值类型为每个成员类型中调用签名返回值类型的联合类型;否则,该联合类型没有调用签名。
interface T0 {
(name: string): number;
}
interface T1 {
(name: string): bigint;
}
type T = T0 | T1;
interface T0T1 {
(name: string): number | bigint;
}
如果联合类型中每个成员都包含相同参数列表的构造签名,那么该联合类型也拥有了构造签名,其返回值类型为每个成员类型中构造签名返回值类型的联合类型;否则,该联合类型没有构造签名。
interface T0 {
new (name: string): Date;
}
interface T1 {
new (name: string): Error;
}
type T = T0 | T1;
interface T0T1 {
new (name: string): Date | Error;
}
交叉类型
交叉类型在逻辑上与联合类型是互补的。
联合类型表示一个值的类型为多种类型之一,而交叉类型则表示一个值同时属于多种类型。
交叉类型通过交叉类型字面量来定义。
交叉类型字面量
交叉类型由两个或多个成员类型构成,各成员类型之间使用“&”符号分隔。
interface Clickable {
click(): void;
}
interface Focusable {
focus(): void;
}
type T = Clickable & Focusable;
此例中,定义了一个名为T的交叉类型。
该交叉类型由两个成员类型组成,即Clickable类型和Focusable类型。
若一个值既是Clickable类型又是Focusable类型,那么我们说该值的类型为交叉类型“Clickable & Focusable”。
成员类型的运算
与联合类型相似,如果交叉类型中存在多个相同的成员类型,那么相同的成员类型将被合并为单一成员类型。
交叉类型是有序的成员类型的集合。
在绝大部分情况下,成员类型满足类似于数学中的“加法交换律”,即改变成员类型的顺序不影响交叉类型的结果类型。
需要注意的是,当交叉类型涉及调用签名重载或构造签名重载时便失去了“加法交换律”的性质。
因为交叉类型中成员类型的顺序将决定重载签名的顺序,进而将影响重载签名的解析顺序。
interface Clickable {
register(x: any): void;
}
interface Focusable {
register(x: string): boolean;
}
type ClickableAndFocusable = Clickable & Focusable;
type FocusableAndFocusable = Focusable & Clickable;
function foo(
clickFocus: ClickableAndFocusable,
focusClick: FocusableAndFocusable
) {
let a: void = clickFocus.register('foo');
let b: boolean = focusClick.register('foo');
}
此例第8行和第9行使用不同的成员类型顺序定义了两个交叉类型。第15行,调用“register()”方法的返回值类型为void,说明在ClickableAndFocusable类型中,Clickable接口中定义的“register()”方法具有更高的优先级。第16行,调用“register()”方法的返回值类型为boolean,说明FocusableAndFocusable类型中Focusable接口中定义的“register()”方法具有更高的优先级。此例也说明了调用签名重载的顺序与交叉类型中成员类型的定义顺序是一致的。
交叉类型中的类型成员同样满足类似于数学中的“加法结合律”。对部分类型成员使用分组运算符不影响交叉类型的结果类型。
interface Clickable {
click(): void;
}
interface Focusable {
focus(): void;06
}
interface Scrollable {
scroll(): void;
}
type T0 = (Clickable & Focusable) & Scrollable;
type T1 = Clickable & (Focusable & Scrollable);
原始类型
交叉类型通常与对象类型一起使用。
虽然在交叉类型中也允许使用原始类型成员,但结果类型将成为never类型,因此在实际代码中并不常见。
type T = boolean & number & string;
此例中,类型T是boolean、number和string类型组成的交叉类型。
根据交叉类型的定义,若一个值是T类型,那么该值既是boolean类型,又是number类型,还是string类型。显然,不存在这样一个值,所以T类型为never类型。never类型是尾端类型,是一种不存在可能值的类型。
交叉类型的类型成员
属性签名
只要交叉类型I中任意一个成员类型包含了属性签名M,那么交叉类型I也包含属性签名M。
interface A {
a: boolean;
}
interface B {
b: string;
}
那么,接口类型A和B的交叉类型“A & B”为如下对象类型:
{
a: boolean;
b: string;
}
对于交叉类型的属性签名,其类型为所有成员类型中该属性类型的交叉类型。
interface A {
x: { a: boolean };
}
interface B {
x: { b: boolean };
}
那么,接口类型A和B的交叉类型“A & B”为如下对象类型:
{
x: { a: boolean } & { b: boolean }
}
该类型也等同于如下类型:
{
x: {
a: boolean;
b: boolean;
};
}
若交叉类型的属性签名M在所有成员类型中都是可选属性,那么该属性签名在交叉类型中也是可选属性。否则,属性签名M是一个必选属性。
interface A {
x: boolean;
y?: string;
}
interface B {
x?: boolean;
y?: string;
}
那么,接口类型A和B的交叉类型“A & B”为如下对象类型:
{
x: boolean;
y?: string;
}
在“A & B”交叉类型中,属性x是必选属性,属性y是可选属性。
索引签名
如果交叉类型中任何一个成员类型包含了索引签名,那么该交叉类型也拥有了索引签名;否则,该交叉类型没有索引签名。
interface A {
[prop: string]: string;
}
interface B {
[prop: number]: string;
}
那么,接口类型A和B的交叉类型“A & B”为如下对象类型,它同时包含了字符串索引签名和数值索引签名:
{
[prop: string]: string;
[prop: number]: string;
}
交叉类型索引签名中的索引值类型为每个成员类型中索引值类型的交叉类型。
interface A {
[prop: string]: { a: boolean };
}
interface B {
[prop: string]: { b: boolean };
}
那么,接口类型A和B的交叉类型“A & B”为如下对象类型:
{
[prop: string]: { a: boolean } & { b: boolean };
}
该类型也等同于如下类型:
{
[prop: string]: {
a: boolean;
b: boolean;
};
}
调用签名与构造签名
若交叉类型的成员类型中含有调用签名或构造签名,那么这些调用签名和构造签名将以成员类型的先后顺序合并到交叉类型中。
interface A {
(x: boolean): boolean;
}
interface B {
(x: string): string;
}
那么交叉类型“A & B”为如下对象类型:
{
(x: boolean): boolean;
(x: string): string;
}
同时,交叉类型“B & A”为如下对象类型:
{
(x: string): string;
(x: boolean): boolean;
}
通过这两个例子能够看到,交叉类型中调用签名的顺序与交叉类型类型成员的顺序相同,构造签名同理。
当交叉类型中存在重载签名时,需要特别留意类型成员的定义顺序。
交叉类型与联合类型
优先级
当表示交叉类型的“&”符号与表示联合类型的“|”符号同时使用时,“&”符号具有更高的优先级。
“&”符号如同数学中的乘法符号“×”,而“|”符号则如同数学中的加法符号“+”。
A & B | C & D
// 等同于
(A & B) | (C & D)
还要注意,当表示交叉类型的“&”符号与表示联合类型的“|”符号与函数类型字面量同时使用时,“&”符号和“|”符号拥有更高的优先级。
() => bigint | number
// 等同于
() => (bigint | number)
// 而不是
(() => bigint) | number
在任何时候,我们都可以使用分组运算符“()”来明确指定优先级。
分配律性质
由交叉类型和联合类型组成的类型满足类似于数学中乘法分配律的规则。表示交叉类型的“&”符号如同数学中的乘法符号“×”,而表示联合类型的“|”符号则如同数学中的加法符号“+”。下例中的“≡”符号是恒等号,表示符号两侧是恒等关系
A & (B | C) ≡ (A & B) | (A & C)
另一个稍微复杂的示例如下所示:
(A | B) & (C | D) ≡ A & C | A & D | B & C | B & D
了解了交叉类型与联合类型的分配律性质后,我们就能够分析与理解一些复杂的类型。
T = (string | 0) & (number | 'a');
T = (string | 0) & (number | 'a');
= (string & number) | (string & 'a') | (0 & number) | (0 & 'a');
// 没有交集的原始类型的交叉类型是 'never' 类型
= never | 'a' | 0 | never;
// 'never' 尾端类型是所有类型的子类型
// 并且若某成员是其他成员的子类型,则可以从联合类型中消去
= 'a' | 0;
索引类型
对于一个对象而言,我们可以使用属性名作为索引来访问属性值。
相似地,对于一个对象类型而言,我们可以使用属性名作为索引来访问属性类型成员的类型。
TypeScript引入了两个新的类型结构来实现索引类型:
- 索引类型查询
- 索引访问类型
索引类型查询
通过索引类型查询能够获取给定类型中的属性名类型。
索引类型查询的结果是由字符串字面量类型构成的联合类型,该联合类型中的每个字符串字面量类型都表示一个属性名类型。
keyof Type
在该语法中,keyof是关键字,Type表示任意一种类型。
interface Point {
x: number;
y: number;
}
type T = keyof Point; // 'x' | 'y'
此例中,对Point类型使用索引类型查询的结果类型为联合类型“'x' | 'y'”,即由Point类型的属性名类型组成的联合类型。
索引类型查询解析
JavaScript中的对象是键值对的数据结构,它只允许将字符串和Symbol值作为对象的键。
索引类型查询获取的是对象的键的类型,因此索引类型查询的结果类型是联合类型“string | symbol”的子类型,因为只有这两种类型的值才能作为对象的键。
但由于数组类型十分常用且其索引值的类型为number类型,因此编译器额外将number类型纳入了索引类型查询的结果类型范围。
于是,索引类型查询的结果类型是联合类型“string | number | symbol”的子类型,这是编译器内置的类型约束。
type KeyofT = keyof T;
让我们来看看该索引类型查询的详细解析步骤
如果类型T中包含字符串索引签名,那么将string类型和number类型添加到结果类型KeyofT。
如果类型T中包含数值索引签名,那么将number类型添加到结果类型KeyofT。
如果类型T中包含属性名类型为“unique symbol”的属性,那么将该“unique symbol”类型添加到结果类型KeyofT。
注意,如果想要在对象类型中声明属性名为symbol类型的属性,那么属性名的类型必须为“unique symbol”类型,而不允许为symbol类型。
const s: unique symbol = Symbol();
interface T {
[s]: boolean;
}
// typeof s
type KeyofT = keyof T;
因为“unique symbol”类型是symbol类型的子类型,所以该索引类型查询的结果类型仍是联合类型“string | number | symbol”的子类型。
最后,如果类型T中包含其他属性成员,那么将表示属性名的字符串字面量类型和数字字面量类型添加到结果类型KeyofT。
interface T {
0: boolean;
a: string;
b(): void;
}
// 0 | 'a' | 'b'
type KeyofT = keyof T;
以上我们介绍了在对象类型上使用索引类型查询的解析过程。
虽然在对象类型上使用索引类型查询更有意义,但是索引类型查询也允许在非对象类型上使用,例如原始类型、顶端类型等
当对any类型使用索引类型查询时,结果类型固定为联合类型“string | number | symbol”。
type KeyofT = keyof any; // string | number |symbol
当对unknown类型使用索引类型查询时,结果类型固定为never类型。
type KeyofT = keyof unknown; // never
当对原始类型使用索引类型查询时,先查找与原始类型对应的内置对象类型,然后再进行索引类型查询。
例如,与原始类型boolean对应的内置对象类型是Boolean对象类型
interface Boolean {
valueOf(): boolean;
}
// 对原始类型boolean执行索引类型查询的结果为字符串字面量类型“'valueOf'”
type KeyofT = keyof boolean; // 'valueOf'
联合类型
在索引类型查询中,如果查询的类型为联合类型,那么先计算联合类型的结果类型,再执行索引类型查询。
例如,有以下对象类型A和B,以及索引类型查询KeyofT
type A = { a: string; z: boolean };
type B = { b: string; z: boolean };
type KeyofT = keyof (A | B); // 'z'
在计算KeyofT类型时,先计算联合类型“A | B”的结果类型。示例如下:
type AB = A | B; // { z: boolean }
然后计算索引类型查询KeyofT的类型。
type KeyofT = keyof AB; // 'z'
交叉类型
在索引类型查询中,如果查询的类型为交叉类型,那么会将原索引类型查询展开为子索引类型查询的联合类型,展开的规则类似于数学中的“乘法分配律”。
keyof (A & B) ≡ keyof A | keyof B
type A = { a: string; x: boolean };
type B = { b: string; y: number };
type KeyofT = keyof (A & B); // 'a' | 'x' | 'b' | 'y'
索引访问类型
索引访问类型能够获取对象类型中属性成员的类型,它的语法如下所示
T[K]
在该语法中,T和K都表示类型,并且要求K类型必须能够赋值给“keyof T”类型。
“T[K]”的结果类型为T中K属性的类型。
通过索引访问类型能够获取对象类型T中属性x和y的类型
type T = { x: boolean; y: string };
type Kx = 'x';
type T0 = T[Kx]; // boolean
type Ky = 'y';
type T1 = T[Ky]; // string
下面我们将深入介绍索引访问类型的详细解析步骤。假设有如下索引访问类型
T[K]
若K是字符串字面量类型、数字字面量类型、枚举字面量类型或“unique symbol”类型,并且类型T中包含名为K的公共属性,那么“T[K]”的类型就是该属性的类型。
若K是联合类型“K1 | K2”,那么“T[K]”等于联合类型“T[K1] | T[K2]”。
type T = { x: boolean; y: string };
type K = 'x' | 'y';
type TK = T[k];
// 等同于
type TK = T['x'] | T['y'];
若K类型能够赋值给string类型,且类型T中包含字符串索引签名,那么“T[K]”为字符串索引签名的类型。
但如果类型T中包含同名的属性,那么同名属性的类型拥有更高的优先级。
interface T {
a: true;
[prop: string]: boolean;
}
type Ta = T['a']; // true
type Tb = T['b']; // boolean
若K类型能够赋值给number类型,且类型T中包含数值索引签名,那么“T[K]”为数值索引签名的类型。
但如果类型T中包含同名的属性,那么同名属性的类型拥有更高的优先级。
interface T {
0: true;
[prop: number]: boolean;
}
type T0 = T[0]; // true
type T1 = T[1]; // boolean
索引类型的应用
通过结合使用索引类型查询和索引访问类型就能够实现类型安全的对象属性访问操作。
例如,下例中定义了工具函数getProperty,它能够返回对象的某个属性值。
该工具函数的特殊之处在于它还能够准确地返回对象属性的类型。
function getProperty<T, K extends keyof T>( obj: T, key: K): T[K] {
return obj[key];
}
interface Circle {
kind: 'circle';
radius: number;
}
function f(circle: Circle) {
// 正确,能够推断出 radius 的类型为 'circle' 类型
const kind = getProperty(circle, 'kind');
// 正确,能够推断出 radius 的类型为 number 类型
const radius = getProperty(circle, 'radius');
// 错误
const unknown = getProperty(circle, 'unknown');
// ~~~~~~~~~
// 编译错误:'unknown'类型不能赋值给'kind' |'radius'
}
映射对象类型
映射对象类型是一种独特的对象类型,它能够将已有的对象类型映射为新的对象类型。
例如,我们想要将已有对象类型T中的所有属性修改为可选属性,那么我们可以直接修改对象类型T的类型声明,将每个属性都修改为可选属性。
除此之外,更好的方法是使用映射对象类型将原对象类型T映射为一个新的对象类型T′,同时在映射过程中将每个属性修改为可选属性
映射对象类型声明
映射对象类型是一个类型运算符,它能够遍历联合类型并以该联合类型的类型成员作为属性名类型来构造一个对象类型。
映射对象类型声明的语法如下所示
{ readonly [P in K]? : T }
在该语法中,readonly是关键字,表示该属性是否为只读属性,该关键字是可选的;“?”修饰符表示该属性是否为可选属性,该修饰符是可选的;in是遍历语法的关键字;K表示要遍历的类型,由于遍历的结果类型将作为对象属性名类型,因此类型K必须能够赋值给联合类型“string | number | symbol”,因为只有这些类型的值才能作为对象的键;P是类型变量,代表每次遍历出来的成员类型;T是任意类型,表示对象属性的类型,并且在类型T中允许使用类型变量P。
映射对象类型的运算结果是一个对象类型。映射对象类型的核心是它能够遍历类型K的所有类型成员,并针对每一个成员P都将它映射为类型T。
映射对象类型解析
本节我们将深入映射对象类型的详细运算步骤
{ [P in K]: T }
首先要强调的是,类型K必须能够赋值给联合类型“string |number | symbol”。
若当前遍历出来的类型成员P为字符串字面量类型,则在结果对象类型中创建一个新的属性成员,属性名类型为该字符串字面量类型且属性值类型为T。
若当前遍历出来的类型成员P为数字字面量类型,则在结果对象类型中创建一个新的属性成员,属性名类型为该数字字面量类型且属性值类型为T。
若当前遍历出来的类型成员P为“unique symbol”类型,则在结果对象类型中创建一个新的属性成员,属性名类型为该“uniquesymbol”类型且属性值类型为T。
若当前遍历出来的类型成员P为string类型,则在结果对象类型中创建字符串索引签名。
若当前遍历出来的类型成员P为number类型,则在结果对象类型中创建数值索引签名。
// { x: boolean }
type MappedObjectType = { [P in 'x']: boolean };
// { 0: boolean }
type MappedObjectType = { [P in 0]: boolean };
const s: unique symbol = Symbol();
// { [s]: boolean }
type MappedObjectType = { [P in typeof s]: boolean };
// { [x: string]: boolean }
type MappedObjectType = { [P in string]: boolean };
// { [x: number]: boolean }
type MappedObjectType = { [P in number]: boolean };
映射对象类型应用
将映射对象类型与索引类型查询结合使用就能够遍历已有对象类型的所有属性成员,并使用相同的属性来创建一个新的对象类型。
type T = { a: string; b: number };
// { a: boolean; b: boolean; }
type M = { [P in keyof T]: boolean };
此例中,映射对象类型能够遍历对象类型T的所有属性成员,并在新的对象类型M中创建同名的属性成员a和b,同时将每个属性成员的类型设置为boolean类型。
我们使用了索引类型查询来获取类型T中所有属性名的类型并将其提供给映射对象类型进行遍历,两者能够完美地结合。
将映射对象类型、索引类型查询以及索引访问类型三者结合才能够最大限度地体现映射对象类型的威力。
type T = { a: string; b: number };
// { a: string; b: number; }
type M = { [P in keyof T]: T[P] };
此例中,我们将对象类型T按原样复制了一份!在定义映射对象类型中的属性类型时,我们不再使用固定的类型,例如boolean。
借助于类型变量P和索引访问类型,我们能够动态地获取对象类型T中每个属性的类型。有了这个模板后,我们可以随意发挥,创建出一些有趣的类型。
同态映射对象类型
映射后的对象类型结构与源对象类型T的结构完全一致,我们将这种映射对象类型称为同态映射对象类型。
同态映射对象类型与源对象类型之间有着相同的属性集合。
如果映射对象类型中存在索引类型查询,那么TypeScript编译器会将该映射对象类型视为同态映射对象类型。
更确切地说,同态映射对象类型具有如下语法形式
{ readonly [P in keyof T]? : X }
在该语法中,readonly关键字和“?”修饰符均为可选的。
type T = { a?: string; b: number };
type K = keyof T;
// 同态映射对象类型
type HMOT = { [P in keyof T]: T[P] };
// 非同态映射对象类型
type MOT = { [P in K]: T[P] };
修饰符拷贝
同态映射对象类型的一个重要性质是,新的对象类型会默认拷贝源对象类型中所有属性的readonly修饰符和“?”修饰符。
type T = { a?: string; readonly b: number };
// { a?: string; readonly b: number; }
type HMOT = { [P in keyof T]: T[P] };
如果是非同态映射对象类型,那么新的对象类型不会拷贝源对象类型T中属性的readonly修饰符和“?”修饰符。
type T = { a?: string; readonly b: number };
type K = keyof T;
// { a: string | undefined; b: number; }
type MOT = { [P in K]: T[P] };
改进的修饰符拷贝
为了改进映射对象类型中修饰符拷贝行为的一致性,TypeScript特殊处理了映射对象类型中索引类型为类型参数的情况。假设有如下映射对象类型
{ [P in K]: X }
如果在该语法中,K为类型参数且有泛型约束“K extends keyofT”,那么编译器也会将对象类型T的属性修饰符拷贝到映射对象类型中,尽管该类型不是同态映射对象类型。
换句话说,当映射对象类型在操作已知对象类型的所有属性或部分属性时会拷贝属性修饰符到映射对象类型中。
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};
此例中,Pick类型为非同态映射对象类型,因为它的语法中不包含索引类型查询。
但是在Pick类型中,K不是某一具体类型,而是一个类型参数,并且存在泛型约束“K extends keyof T”。
这时,TypeScript会特殊处理这种形式的映射对象类型来保留属性修饰符。示例如下:
type T = {
a?: string;
readonly b: number;
c: boolean;
};
// { a?: string; readonly b: number }
type SomeOfT = Pick<T, 'a' | 'b'>;
此例中的Pick类型是十分常用的类型,它能够从已有对象类型中挑选一个或多个指定的属性并保留它们的类型和修饰符,然后构造出一个新的对象类型。因此,TypeScript内置了该工具类型。
添加和移除修饰符
不论是同态映射对象类型的修饰符拷贝规则还是改进的映射对象类型修饰符拷贝规则,它们都无法删除属性已有的修饰符。
因此,TypeScript引入了两个新的修饰符用来精确控制添加或移除映射属性的“?”修饰符和readonly修饰符:
- “+”修饰符,为映射属性添加“?”修饰符或readonly修饰符。
- –”修饰符,为映射属性移除“?”修饰符或readonly修饰符。
+”修饰符和“–”修饰符应用在“?”修饰符和readonly修饰符之前。
{ -readonly [P in keyof T]-?: T[P] }
{ +readonly [P in keyof T]+?: T[P] }
// 将已有对象类型的所有属性转换为必选属性,则可以使用“Required<T>”工具类型。
type Required<T> = { [P in keyof T]-?: T[P] };
type T = {
a?: string | undefined | null;
readonly b: number | undefined | null;
};
// {
// a: string | null;
// readonly b: number | undefined | null;
// }
type RequiredT = Required<T>;
需要注意的是,“–”修饰符仅作用于带有“?”和readonly修饰符的属性。
编译器在移除属性a的“?”修饰符时,同时会移除属性类型中的undefined类型,但是不会移除null类型,因此RequiredT类型中属性a的类型为“string | null”类型。
由于属性b不带有“?”修饰符,因此此例中的“–”修饰符对属性b不起作用,也不会移除属性b中的undefined类型。
对于“+”修饰符,明确地添加它与省略它的作用是相同的,因此通常省略。
例如,“+readonly”等同于“readonly”,如下所示:
type ReadonlyPartial<T> = {
+readonly [P in keyof T]+?: T[P]
};
// 等同于:
type ReadonlyPartial<T> = {
readonly [P in keyof T]?: T[P]
};
同态映射对象类型深入
同态映射对象类型是一种能够维持对象结构不变的映射对象类型。
同态映射对象类型“{ [P in keyof T]: X }”与对象类型T是同态关系,它们包含了完全相同的属性集合。
在默认情况下,同态映射对象类型会保留对象类型T中属性的修饰符。
type HMOT<T, X> = { [P in keyof T]: X };
现在来看看同态映射对象类型“HMOT<T, X>”的具体映射规则。
若T为原始类型,则不进行任何映射,同态映射对象类型“HMOT<T, X>”等于类型T。
type HMOT<T, X> = { [P in keyof T]: X };
type T = string;
type R = HMOT<T, boolean> // <- 与boolean类型无关= string
若T为联合类型,则对联合类型的每个成员类型求同态映射对象类型,并使用每个结果类型构造一个联合类型。
type HMOT<T, X> = { [P in keyof T]: X };
type T = { a: string } | { b: number };
type R = HMOT<T, boolean>;
= HMOT<{ a: string }, boolean> | HMOT<{ b: number }, boolean>;
= { a: boolean } | { b: boolean };
若T为数组类型,则同态映射对象类型“HMOT<T, X>”也为数组类型。
type HMOT<T, X> = { [P in keyof T]: X };
type T = number[];
type R = HMOT<T, string>;
= string[];
若T为只读数组类型,则同态映射对象类型“HMOT<T, X>”也为只读数组类型。
type HMOT<T, X> = { [P in keyof T]: X };
type T = readonly number[];
type R = HMOT<T, string>;
= readonly string[];
若T为元组类型,则同态映射对象类型“HMOT<T, X>”也为元组类型。
type HMOT<T, X> = { [P in keyof T]: X };
type T = [string, number];
type R = HMOT<T, boolean>;
= [boolean, boolean];
若T为只读元组类型,则同态映射对象类型“HMOT<T, X>”也为只读元组类型。
type HMOT<T, X> = { [P in keyof T]: X };
type T = readonly [string, number];
type R = HMOT<T, boolean>;
= readonly [boolean, boolean];
若T为数组类型或元组类型,且同态映射对象类型中使用了readonly修饰符,那么同态映射对象类型“HMOT<T, X>”的结果类型为只读数组类型或只读元组类型。
若T为只读数组类型或只读元组类型,且同态映射对象类型中使用了“–readonly”修饰符,那么同态映射对象类型“HMOT<T, X>”的结果类型为非只读数组类型或非只读元组类型。
条件类型
条件类型与条件表达式类似,它表示一种非固定的类型。
条件类型能够根据条件判断从可选类型中选择其一作为结果类型。
条件类型的定义
条件类型的定义借用了JavaScript语言中的条件运算符,语法如下所示:
T extends U ? X : Y
在该语法中,extends是关键字;T、U、X和Y均表示一种类型。
若类型T能够赋值给类型U,则条件类型的结果为类型X,否则条件类型的结果为类型Y。
条件类型的结果类型只可能为类型X或者类型Y。
// string
type T0 = true extends boolean ? string : number;
// number
type T1 = string extends boolean ? string : number;
此例中的条件类型实际意义很小,因为条件类型中的所有类型都是固定的,因此结果类型也是固定的。
在实际应用中,条件类型通常与类型参数结合使用。
下例中定义了泛型类型别名“TypeName<T>”,它有一个类型参数T。“TypeName<T>”的值为条件类型,在该条件类型中根据不同的实际类型参数T将返回不同的类型。示例如下
type TypeName<T> = T extends string
? 'string'
: T extends number
? 'number'
: T extends boolean
? 'boolean'
: T extends undefined
? 'undefined'
: T extends Function
? 'function'
: 'object';
type T0 = TypeName<'a'>; // 'string'
type T1 = TypeName<0>; // 'number'
type T2 = TypeName<true>; // 'boolean'
type T3 = TypeName<undefined>; // 'undefined'
type T4 = TypeName<() => void>; // 'function'
type T5 = TypeName<string[]>; // 'object'
分布式条件类型
在条件类型“T extends U ? X : Y”中,如果类型T是一个裸(Naked)类型参数,那么该条件类型也称作分布式条件类型。
裸类型参数
从字面上理解,裸类型参数是指裸露在外的没有任何装饰的类型参数。
如果类型参数不是复合类型的组成部分而是独立出现,那么该类型参数称作裸类型参数。
例如,在下例的“T0<T>”类型中,类型参数T是裸类型参数;但是在“T1<T>”类型中,类型参数T不是裸类型参数,因为它是元组类型的组成部分。因此,类型“T0<T>”是分布式条件类型,而类型“T1<T>”则不是分布式条件类型。
type T0<T> = T extends string ? true : false;
// ~
// 裸类型参数
type T1<T> = [T] extends [string] ? true : false;
// ~
// 非裸类型参数
分布式行为
与常规条件类型相比,分布式条件类型具有一种特殊的行为,那就是在使用实际类型参数实例化分布式条件类型时,如果实际类型参数T为联合类型,那么会将分布式条件类型展开为由子条件类型构成的联合类型。
T ≡ A | B
T extends U ? X : Y
≡ (A extends U ? X : Y) | (B extends U ? X : Y)
过滤联合类型
在了解了分布式条件类型的分布式行为后,我们可以巧妙地利用它来过滤联合类型。
在联合类型一节中介绍过,在联合类型“U = U0| U1”中,若U1是U0的子类型,那么联合类型可以化简为“U =U0”。
never类型是尾端类型,它是任何其他类型的子类型。
因此,当never类型与其他类型组成联合类型时,可以直接将never类型从联合类型中“消掉”。
T | never ≡ T
基于分布式条件类型和以上两个“公式”,我们就能够从联合类型中过滤掉特定的类型。
下例中的“Exclude<T, U>”类型能够从联合类型T中删除符合条件的类型
type Exclude<T, U> = T extends U ? never : T;
在分布式条件类型“Exclude<T, U>”中,若类型T能够赋值给类型U,则返回never类型;否则,返回类型T。
这里巧妙地使用了never类型来从联合类型T中删除符合条件的类型。
T = Exclude<string | undefined, null | undefined>
= (string extends null | undefined ? never : string)
|(null extends null | undefined ? never : null)
= string | never
= string
避免分布式行为
分布式条件类型的分布式行为通常是期望的行为,但也可能存在某些场景,让我们想要禁用分布式条件类型的分布式行为。
这就需要将分布式条件类型转换为非分布式条件类型。
一种可行的方法是将分布式条件类型中的裸类型参数修改为非裸类型参数,
这可以通过将extends两侧的类型包裹在元组类型中来实现。
这样做之后,原本的分布式条件类型将变成非分布式条件类型,因此也就不再具有分布式行为。
type CT<T> = T extends string ? true : false;
type T = CT<string | number>; // boolean
// 将此例中的分布式条件类型转换为非分布式条件类型
type CT<T> = [T] extends [string] ? true : false;
type T = CT<string | number>; // false
infer关键字
在extends语句中类型U的位置上允许使用infer关键字来定义可推断的类型变量,可推断的类型变量只允许在条件类型的true分支中引用,即类型X的位置上使用。
T extends U ? X : Y
语法如下:
T extends infer U ? U : Y;
此例中,使用infer声明定义了可推断的类型变量U。
当编译器解析该条件类型时,会根据T的实际类型来推断类型变量U的实际类型。
type CT<T> = T extends Array<infer U> ? U : never;
type T = CT<Array<number>>; // number
此例中,条件类型“CT<T>”定义了一个可推断的类型变量U,它表示数组元素的类型。
第3行,当使用数组类型“Array<number>”实例化“CT<T>”条件类型时,编译器将根据“Array<number>”类型来推断“Array<infer U>”类型中类型变量U的实际类型,推断出来的类型变量U的实际类型为number类型。
接下来再来看一个例子,我们可以使用条件类型和infer类型变量来获取某个函数的返回值类型。
“ReturnType<T>”类型接受函数类型的类型参数,并返回函数的返回值类型。
type ReturnType< T extends (...args: any) => any>
= T extends (...args: any) => infer R ? R : any;
type F = (x: number) => string;
type T = ReturnType<F>; // string
在条件类型中,允许定义多个infer声明。
例如,下例中存在两个infer声明,它们定义了同一个推断类型变量U:
type CT<T> =T extends { a: infer U; b: infer U } ? U : never;
type T = CT<{ a: string; b: number }>; // string |number
同时,在多个infer声明中也可以定义不同的推断类型变量。
例如,下例中的两个infer声明分别定义了两个推断类型变量M和N:
type CT<T> =
T extends { a: infer M; b: infer N } ? [M, N] :never;
type T = CT<{ a: string; b: number }>; // [string,number]
内置工具类型
在前面的章节中,我们已经陆续介绍了一些TypeScript内置的实用工具类型。
这些工具类型的定义位于TypeScript语言安装目录下的“lib/lib.es5.d.ts”文件中。
在TypeScript程序中,不需要进行额外的安装或配置就可以直接使用这些工具类型。
目前,TypeScript提供的所有内置工具类型如下:
- Partial<T>
- Required<T>
- Readonly<T>
- Record<K, T>
- Pick<T, K>
- Omit<T, K>
- Exclude<T, U>
- Extract<T, U>
- NonNullable<T>
- Parameters<T>
- ConstructorParameters<T>
- ReturnType<T>
- InstanceType<T>
- ThisParameterType<T>
- OmitThisParameter<T>
- ThisType<T>
Partial<T>
该工具类型能够构造一个新类型,并将实际类型参数T中的所有属性变为可选属性。
interface A {
x: number;
y: number;
}
type T = Partial<A>; // { x?: number; y?: number; }
const a: T = { x: 0, y: 0 };
const b: T = { x: 0 };
const c: T = { y: 0 };
const d: T = {};
Required<T>
该工具类型能够构造一个新类型,并将实际类型参数T中的所有属性变为必选属性。
interface A {
x?: number;
y: number;
}
type T0 = Required<A>; // { x: number; y: number; }
Readonly<T>
该工具类型能够构造一个新类型,并将实际类型参数T中的所有属性变为只读属性。
interface A {
x: number;
y: number;
}
// { readonly x: number; readonly y: number; }
type T = Readonly<A>;
const a: T = { x: 0, y: 0 };
a.x = 1; // 编译错误!不允许修改
a.y = 1; // 编译错误!不允许修改
Record<K, T>
该工具类型能够使用给定的对象属性名类型和对象属性类型创建一个新的对象类型。“Record<K, T>”工具类型中的类型参数K提供了对象属性名联合类型,类型参数T提供了对象属性的类型。
type K = 'x' | 'y';
type T = number;
type R = Record<K, T>; // { x: number; y: number; }
const a: R = { x: 0, y: 0 };
因为类型参数K是用作对象属性名类型的,所以实际类型参数K必须能够赋值给“string | number | symbol”类型,只有这些类型能够作为对象属性名类型。
Pick<T, K>
该工具类型能够从已有对象类型中选取给定的属性及其类型,然后构建出一个新的对象类型。
“Pick<T, K>”工具类型中的类型参数T表示源对象类型,类型参数K提供了待选取的属性名类型,它必须为对象类型T中存在的属性。
interface A {
x: number;
y: number;
}
type T0 = Pick<A, 'x'>; // { x: number }
type T1 = Pick<A, 'y'>; // { y: number }
type T2 = Pick<A, 'x' | 'y'>; // { x: number; y:number }
type T3 = Pick<A, 'z'>;
// ~~~
// 编译错误:类型'A'中不存在属性'z'
Omit<T, K>
“Omit<T, K>”工具类型与“Pick<T, K>”工具类型是互补的,它能够从已有对象类型中剔除给定的属性,然后构建出一个新的对象类型。
“Omit<T, K>”工具类型中的类型参数T表示源对象类型,类型参数K提供了待剔除的属性名类型,但它可以为对象类型T中不存在的属性。
interface A {
x: number;
y: number;
}
type T0 = Omit<A, 'x'>; // { y: number }
type T1 = Omit<A, 'y'>; // { x: number }
type T2 = Omit<A, 'x' | 'y'>; // { }
type T3 = Omit<A, 'z'>; // { x: number; y:number }
Exclude<T, U>
该工具类型能够从类型T中剔除所有可以赋值给类型U的类型。
type T0 = Exclude<"a" | "b" | "c", "a">; // "b" | "c"
type T1 = Exclude<"a" | "b" | "c", "a" | "b">; // "c"
type T2 = Exclude<string | (() => void), Function>; //string
Extract<T, U>
“Extract<T, U>”工具类型与“Exclude<T, U>”工具类型是互补的,它能够从类型T中获取所有可以赋值给类型U的类型。
type T0 = Extract<'a' | 'b' | 'c', 'a' | 'f'>; // 'a'
type T1 = Extract<string | (() => void), Function>; //() => void
type T2 = Extract<string | number, boolean>; //never
NonNullable<T>
该工具类型能够从类型T中剔除null类型和undefined类型并构造一个新类型,也就是获取类型T中的非空类型。
// string | number
type T0 = NonNullable<string | number | undefined>;
// string[]
type T1 = NonNullable<string[] | null | undefined>;
Parameters<T>
该工具类型能够获取函数类型T的参数类型并使用参数类型构造一个元组类型。
type T0 = Parameters<() => string>; // []
type T1 = Parameters<(s: string) => void>; // [string]
type T2 = Parameters<<T>(arg: T) => T>; //[unknown]
type T4 = Parameters< (x: { a: number; b: string }) => void >; // [{ a:number, b: string }]
type T5 = Parameters<any>; //unknown[]
type T6 = Parameters<never>; // never
type T7 = Parameters<string>;
// ~~~~~~~
// 编译错误!string类型不符合约束'(...args: any) => any'
type T8 = Parameters<Function>;
// ~~~~~~~~
// 编译错误!Function类型不符合约束'(...args: any) => any'
ConstructorParameters<T>
该工具类型能够获取构造函数T中的参数类型,并使用参数类型构造一个元组类型。若类型T不是函数类型,则返回never类型。
// [string, number]
type T0 = ConstructorParameters<new (x: string, y:number) => object>;
// [(string | undefined)?]
type T1 = ConstructorParameters<new (x?: string) =>object>;
type T2 = ConstructorParameters<string>; // 编译错误
type T3 = ConstructorParameters<Function>; // 编译错误
ReturnType<T>
该工具类型能够获取函数类型T的返回值类型。
// string
type T0 = ReturnType<() => string>;
// { a: string; b: number }
type T1 = ReturnType<() => { a: string; b: number }>;
// void
type T2 = ReturnType<(s: string) => void>;
// {}
type T3 = ReturnType<<T>() => T>;
// number[]
type T4 = ReturnType<<T extends U, U extends number[]>() => T>;
// any
type T5 = ReturnType<never>;
type T6 = ReturnType<boolean>; // 编译错误
type T7 = ReturnType<Function>; // 编译错误
InstanceType<T>
该工具类型能够获取构造函数的返回值类型,即实例类型。
class C {
x = 0;
}
type T0 = InstanceType<typeof C>; // C
type T1 = InstanceType<new () => object>; // object
type T2 = InstanceType<any>; // any
type T3 = InstanceType<never>; // any
type T4 = InstanceType<string>; // 编译错误
type T5 = InstanceType<Function>; // 编译错误
ThisParameterType<T>
该工具类型能够获取函数类型T中this参数的类型,若函数类型中没有定义this参数,则返回unknown类型。
在使用“ThisParameterType<T>”工具类型时需要启用“--strictFunctionTypes”编译选项。
/**
* --strictFunctionTypes=true
*/
function f0(this: object, x: number) {}
function f1(x: number) {}
type T0 = ThisParameterType<typeof f0>; // object
type T1 = ThisParameterType<typeof f1>; // unknown
type T2 = ThisParameterType<string>; // unknown
OmitThisParameter<T>
该工具类型能够从类型T中剔除this参数类型,并构造一个新类型。
在使用“Omit-ThisParameter<T>”工具类型时需要启用“--strictFunctionTypes”编译选项。
/**
* --strictFunctionTypes=true
*/
function f0(this: object, x: number) {}
function f1(x: number) {}
// (x: number) => void
type T0 = OmitThisParameter<typeof f0>;
// (x: number) => void
type T1 = OmitThisParameter<typeof f1>;
// string
type T2 = OmitThisParameter<string>;
ThisType<T>
该工具类型比较特殊,它不是用于构造一个新类型,而是用于定义对象字面量的方法中this的类型。
如果对象字面量的类型是“ThisType<T>”类型或包含“ThisType<T>”类型的交叉类型,那么在对象字面量的方法中this的类型为T。
在使用“ThisType<T>”工具类型时需要启用“--noImplicitThis”编译选项。
/**
* --noImplicitThis=true
*/
let obj: ThisType<{ x: number }> & { getX: () =>number };
obj = {
getX() {
this; // { x: number; y: number; }
return this.x;
},
};
此例中,使用交叉类型为对象字面量obj指定了“ThisType<T>”类型,因此obj中getX方法的this类型为“{ x: number; }”类型。
类型查询
typeof是JavaScript语言中的一个一元运算符,它能够获取操作数的数据类型。
例如,当对一个字符串使用该运算符时,将返回固定的值“'string'”。
typeof 'foo'; // 'string'
TypeScript对JavaScript中的typeof运算符进行了扩展,使其能够在表示类型的位置上使用。
当在表示类型的位置上使用typeof运算符时,它能够获取操作数的类型,我们称之为类型查询。
类型查询的语法如下所示
typeof TypeQueryExpression
在该语法中,typeof是关键字;TypeQueryExpression是类型查询的操作数,它必须为一个标识符或者为使用点号“.”分隔的多个标识符。
const a = { x: 0 };
function b(x: string, y: number): boolean {
return true;
}
type T0 = typeof a; // { x: number }
type T1 = typeof a.x; // number
type T2 = typeof b; // (x: string, y: number) =>boolean
在前面的章节中,我们介绍了特殊的“unique symbol”类型。
每一个“unique symbol”类型都是唯一的,TypeScript只允许使用const声明或readonly属性声明来定义“unique symbol”类型的值。
若想要获取特定的“unique symbol”值的类型,则需要使用typeof类型查询,否则将无法引用其类型。
const a: unique symbol = Symbol();
const b: typeof a = a
类型断言
TypeScript程序中的每一个表达式都具有某种类型,编译器可以通过类型注解或者类型推断来确定表达式的类型。但有些时候,开发者比编译器更加清楚某个表达式的类型。
<T>类型断言
<T>expr
在该语法中,T表示类型断言的目标类型;expr表示一个表达式。<T>类型断言尝试将expr表达式的类型转换为T类型。
在使用<T>类型断言时,需要注意运算符的优先级。
const username = document.getElementById('username');
if (username) {
(<HTMLInputElement>username).value; // 正确
// <HTMLInputElement>username.value;
// ~~~~~
// 编译错误!属性'value'不存在于类型'HTMLElement'上
}
as T类型断言
as T类型断言与<T>类型断言的功能完全相同,两者只是在语法上有所区别。
expr as T
在该语法中,as是关键字;T表示类型断言的目标类型;expr表示一个表达式。as T类型断言尝试将expr表达式的类型转换为T类型。
<T>断言与as T断言的比较。
最初,TypeScript中只支持<T>类型断言。后来,React框架开发团队在为JSX添加TypeScript支持时,发现<T>类型断言的语法与JSX的语法会产生冲突,因此,TypeScript语言添加了新的as T类型断言语法来解决两者的冲突。
类型断言的约束
类型断言不允许在两个类型之间随意做转换而是需要满足一定的前提。
假设有如下as T类型断言(<T>断言同理)
expr as T
若想要该类型断言能够成功执行,则需要满足下列两个条件之一:
- expr表达式的类型能够赋值给T类型
- T类型能够赋值给expr表达式的类型
以上两个条件意味着,在执行类型断言时编译器会尝试进行双向的类型兼容性判定,允许将一个类型转换为更加精确的类型或者更加宽泛的类型。
如果两个类型之间完全没有关联,也就是不满足上述的两个条件,那么编译器会拒绝执行类型断言。
01 let a: boolean = 'hello' as boolean;
02 // ~~~~~~~~~~~~~~~~~~
03 // 编译错误!'string'类型与'boolean'类型没有关联
少数情况下,在两个复杂类型之间进行类型断言时,编译器可能会无法识别出正确的类型,因此错误地拒绝了类型断言操作,又或者因为某些特殊原因而需要进行强制类型转换。那么在这些特殊的场景中可以使用如下变通方法来执行类型断言。该方法先后进行了两次类型断言,先将expr的类型转换为顶端类型unknown,而后再转换为目标类型。因为任何类型都能够赋值给顶端类型,它满足类型断言的条件,因此允许执行类型断言。
expr as unknown as T
除了使用unknow类型外,也可以使用any类型。
但因为unknown类型是更加安全的顶端类型,因此推荐优先使用unknown类型。
const a = 1 as unknown as number;
const类型断言
const类型断言是一种特殊形式的<T>类型断言和as T类型断言,它能够将某一类型转换为不可变类型。
const类型断言有以下两种语法形式
expr as const
// 或者
<const>expr
在该语法中,const是关键字,它借用了const声明的关键字;expr则要求是以下字面量中的一种:
- boolean字面量。
- string字面量。
- number字面量。
- bigint字面量。
- 枚举成员字面量。
- 数组字面量。
- 对象字面量。
const类型断言会将expr表达式的类型转换为不可变类型
如果expr为boolean字面量、string字面量、number字面量、bigint字面量或枚举成员字面量,那么转换后的结果类型为对应的字面量类型。
如果expr为数组字面量,那么转换后的结果类型为只读元组类型。
如果expr为对象字面量,那么转换后的结果类型会将对象字面量中的属性全部转换成只读属性。
let a1 = true; // boolean
let a2 = true as const; // true
let b1 = 'hello'; // string
let b2 = 'hello' as const; // 'hello'
let c1 = 0; // number
let c2 = 0 as const; // number
let d1 = 1n; // number
let d2 = 1n as const; // 1n
enum Foo {
X,
Y,
}
let e1 = Foo.X; // Foo
let e2 = Foo.X as const; // Foo.X
let a1 = [0, 0]; // number[]
let a2 = [0, 0] as const; // readonly [0, 0]
// { x: number; y: number; }
let a1 = { x: 0, y: 0 };
// { readonly x: 0; readonly y: 0; }
let a2 = { x: 0, y: 0 } as const;
在可变值的位置上,编译器会推断出放宽的类型。
例如,let声明属于可变值,而const声明则不属于可变值;非只读数组和对象属于可变值,因为允许修改元素和属性。
下例中,add函数接受两个必选参数。第5行,定义了一个包含两个元素的数组字面量。第9行,使用展开运算符将数组nums展开作为调用add()函数的实际参数。
01 function add(x: number, y: number) {
02 return x + y;
03 }
04
05 const nums = [1, 2];
06 // ~~~~
07 // 推断出的类型为'number[]'
08
09 const total = add(...nums);
10 // ~~~~~~~
11 // 编译错误:应有2个参数,但获得0个或多个
此例中,在第9行产生了一个编译错误,传入的实际参数数量与期望的参数数量不匹配。
这是因为编译器推断出nums常量为“number[]”类型,而不是有两个固定元素的元组类型。
展开“number[]”类型的值可能得到零个或多个元素,而add函数则明确声明需要两个参数,所以产生编译错误。若想要解决这个问题,只需让编译器知道nums是有两个元素的元组类型即可,使用const断言是一种简单可行的方案。
function add(x: number, y: number) {
return x + y;
}
const nums = [1, 2] as const;
// ~~~~
// 推断出的类型为'readonly [1, 2]'
const total = add(...nums); // 正确
使用const断言后,推断的nums类型为包含两个元素的元组类型,因此编译器有足够的信息能够判断出add函数调用是正确的。
!类型断言
非空类型断言运算符“!”是TypeScript特有的类型运算符,它是非空类型断言的一部分。
非空类型断言能够从某个类型中剔除undefined类型和null类型。
expr!
在该语法中,expr表示一个表达式,非空类型断言尝试从expr表达式的类型中剔除undefined类型和null类型。
当代码中使用了非空类型断言时,相当于在告诉编译器expr的值不是undefined值和null值。
当编译器遇到非空类型断言时,就会无条件地相信表达式的类型不是undefined类型和null类型。
因此,不应该滥用非空类型断言,应当只在确定一个表达式的值不为空时才使用它,否则将存在安全隐患。
虽然非空类型断言也允许在非“--strictNullChecks”模式下使用,但没有实际意义。
因为在非严格模式下,编译器不会检查undefined值和null值。
类型细化
类型细化是指TypeScript编译器通过分析特定的代码结构,从而得出代码中特定位置上表达式的具体类型。细化后的表达式类型通常比其声明的类型更加具体。
类型细化最常见的表现形式是从联合类型中排除若干个成员类型。
例如,表达式的声明类型为联合类型“string | number”,经过类型细化后其类型可以变得更加具体,例如成为string类型。
TypeScript编译器主要能够识别以下几类代码结构并进行类型细化:
- 类型守卫
- 可辨识联合类型
- 赋值语句
- 控制流语句
- 断言函数
类型守卫
类型守卫是一类特殊形式的表达式,具有特定的代码编写模式。
编译器能够根据已知的模式从代码中识别出这些类型守卫表达式,然后分析类型守卫表达式的值,从而能够将相关的变量、参数或属性等的类型细化为更加具体的类型。
实际上,类型守卫早已经融入我们的代码当中,我们通常不需要为类型守卫做额外的编码工作,它们已经在默默地发挥作用。
typeof类型守卫
typeof运算符用于获取操作数的数据类型。
typeof运算符的返回值是一个字符串,该字符串表明了操作数的数据类型。由于支持的数据类型的种类是固定的,因此typeof运算符的返回值也是一个有限集合,如下表:
| 操作数的类型 | typeof返回值 |
|---|---|
| Undefined类型 | "undefined" |
| Null类型 | "object" |
| Boolean类型 | "boolean" |
| Number类型 | "number" |
| String类型 | "string" |
| Symbol类型 | "symbol" |
| BigInt类型 | "bigint" |
| 函数类型 | "function" |
| 对象类型 | "object" |
typeof类型守卫能够根据typeof表达式的值去细化typeof操作数的类型。
例如,如果“typeof x”的值为字符串“'number'”,那么编译器就能够将x的类型细化为number类型。
对null值使用typeof运算符的返回值不是字符串“'null'”,而是字符串“'object'”。因此,typeof类型守卫在细化运算结果为“'object'”的类型时,会包含null类型。
虽然函数也是一种对象类型,但函数特殊的地方在于它是可以调用的对象。
typeof运算符为函数类型定义了一个单独的“'function'”返回值,使用了“'function'”的typeof类型守卫会将操作数的类型细化为函数类型。
interface FooFunction {
(): void;
}
function f(x: FooFunction | undefined) {
if (typeof x === 'function') {
x; // FooFunction
} else {
x; // undefined
}
}
我们介绍过带有调用签名的对象类型是函数类型。
因为接口表示一种对象类型,且FooFunction接口中有调用签名成员,所以FooFunction接口表示函数类型。
第6行,typeof类型守卫将参数x的类型细化为函数类型FooFunction。
instanceof类型守卫
instanceof运算符能够检测实例对象与构造函数之间的关系。
instanceof运算符的左操作数为实例对象,右操作数为构造函数,若构造函数的prototype属性值存在于实例对象的原型链上,则返回true;否则,返回false
instanceof类型守卫会根据instanceof运算符的返回值将左操作数的类型进行细化。
instanceof类型守卫同样适用于自定义构造函数,并对其实例对象进行类型细化。
class A {}
class B {}
function f(x: A | B) {
if (x instanceof A) {
x; // A
}
if (x instanceof B) {
x; // B
}
}
in类型守卫
in运算符是JavaScript中的关系运算符之一,用来判断对象自身或其原型链中是否存在给定的属性,若存在则返回true,否则返回false。
in运算符有两个操作数,左操作数为待测试的属性名,右操作数为测试对象。
in类型守卫根据in运算符的测试结果,将右操作数的类型细化为具体的对象类型。
interface A {
x: number;
}
interface B {
y: string;
}
function f(x: A | B) {
if ('x' in x) {
x; // A
} else {
x; // B
}
}
逻辑与、或、非类型守卫
逻辑与表达式、逻辑或表达式和逻辑非表达式也可以作为类型守卫。
逻辑表达式在求值时会判断操作数的真与假。如果一个值转换为布尔值后为true,那么该值为真值;如果一个值转换为布尔值后为false,那么该值为假值。
不同类型的值转换为布尔值的具体规则如表:
| 操作数的类型 | 转换成布尔值后的结果 |
|---|---|
| Undefined | false |
| Null | false |
| Boolean | 结果不变,为true或false |
| Number | 若数字为+0,-0或NaN,结果为false;否则,结果为true |
| String | 若字符串为空字符串,结果为false;否则,结果为true |
| Symbol | true |
| BigInt | 若值为0n,结果为false;否则,结果为true |
| Object | true |
不仅是逻辑表达式会进行真假值比较,JavaScript中的很多语法结构也都会进行真假值比较。
例如,if条件判断语句使用真假值比较,若if表达式的值为真,则执行if分支的代码,否则执行else分支的代码。
function f(x: true | false | 0 | 0n | '' | undefined | null)
{
if (x) {
x; // true
} else {
x; // false | 0 | 0n | '' | undefined | null
}
}
逻辑非运算符“!”是一元运算符,它只有一个操作数。
若逻辑非运算符的操作数为真,那么逻辑非表达式的值为false;反之,若逻辑非运算符的操作数为假,则逻辑非表达式的值为true。
逻辑非类型守卫将根据逻辑非表达式的结果对操作数进行类型细化。
逻辑与运算符“&&”是二元运算符,它有两个操作数。
若左操作数为假,则返回左操作数;否则,返回右操作数。
逻辑与类型守卫将根据逻辑与表达式的结果对操作数进行类型细化。
逻辑或运算符“||”是二元运算符,它有两个操作数。
若左操作数为真,则返回左操作数;否则,返回右操作数。
同逻辑与类型守卫类似,逻辑或类型守卫将根据逻辑或表达式的结果对操作数进行类型细化。
逻辑与、或、非类型守卫也支持在操作数中使用对象属性访问表达式,并且能够对对象属性进行类型细化。
interface Options {
location?: {
x?: number;
y?: number;
};
}
function f(options?: Options) {
if (options && options.location && options.location.x) {
const x = options.location.x; // number
}
const y = options.location.x;
// ~~~~~~~~~~~~~~~~
// 编译错误:对象可能为 'undefined'
}
需要注意的是,如果在对象属性上使用了逻辑与、或、非类型守卫,而后又对该对象属性进行了赋值操作,那么类型守卫将失效,不会进行类型细化。
interface Options {
location?: {
x?: number;
y?: number;
};
}
function f(options?: Options) {
// 09
if (options && options.location && options.location.x) {
// 有效
const x = options.location.x; //number
}
if (options && options.location && options.location.x) {
// 15
options.location = { x: 1, y: 1 }; // 重新赋值
// 无效
const x = options.location.x; //number | undefined
}
if (options && options.location && options.location.x) {
// 22
options = { location: { x: 1, y: 1 } }; // 重新赋值
// 无效
const x = options.location.x; // 编译错误
}
}
作为对比,第9行的类型守卫能够生效,因为在if分支内没有对options及其属性进行重新赋值。
第15行,在使用了类型守卫后又对“options.location”进行了重新赋值,这会导致第14行的类型守卫失效。实际上不只是“options.location”,给“options.location.x”访问路径上的任何对象属性重新赋值都会导致类型守卫失效。
例如第22行,对options赋值也会导致类型守卫失效。
等式类型守卫
等式表达式是十分常用的代码结构,同时它也是一种类型守卫,即等式类型守卫。
等式表达式可以使用四种等式运算符“=” “!” “==” “!=”,它们能够将两个值进行相等性比较并返回一个布尔值。
编译器能够对等式表达式进行分析,从而将等式运算符的操作数进行类型细化。
当等式运算符的操作数之一是undefined值或null值时,该等式类型守卫也是一个空值类型守卫。空值类型守卫能够将一个值的类型细化为空类型或非空类型。
如果等式类型守卫中使用的是严格相等运算符“=”和“!”,那么类型细化时将区别对待undefined类型和null类型。
例如,若判定一个值严格等于undefined值,则将该值细化为undefined类型,而不是细化为联合类型“undefined | null”。
function f0(x: boolean | undefined | null) {
if (x === undefined) {
x; // undefined
} else {
x; // boolean | null
}
if (x !== undefined) {
x; // boolean | null
} else {
x; // undefined
}
if (x === null) {
x; // null
} else {
x; // boolean | undefined
}
if (x !== null) {
x; // boolean | undefined
} else {
x; // null
}
}
但如果等式类型守卫中使用的是非严格相等运算符“==”和“!=”,那么类型细化时会将undefined类型和null类型视为相同的空类型,不论在等式类型守卫中使用的是undefined值还是null值,结果都是相同的。
例如,若使用非严格相等运算符判定一个值等于undefined值,则将该值细化为联合类型“undefined | null”。
function f0(x: boolean | undefined | null) {
if (x == undefined) {
x; // undefined | null
} else {
x; // boolean
}
if (x != undefined) {
x; // boolean
} else {
x; // undefined | null
}
}
function f1(x: boolean | undefined | null) {
if (x == null) {
x; // undefined | null
} else {
x; // boolean
}
if (x != null) {
x; // boolean
} else {
x; // undefined | null
}
}
除了undefined值和null值之外,等式类型守卫还支持以下种类的字面量:
- boolean字面量。
- string字面量。
- number字面量和bigint字面量。
- 枚举成员字面量。
当等式类型守卫中出现以上字面量时,会将操作数的类型细化为相应的字面量类型。
等式类型守卫也支持将两个参数或变量进行等式比较,并同时细化两个操作数的类型。
function f0(x: string | number, y: string | boolean) {
if (x === y) {
x; // string
y; // string
} else {
x; // string | number
y; // string | boolean
}
}
function f1(x: number, y: 1 | 2) {
if (x === y) {
x; // 1 | 2
y; // 1 | 2
} else {
x; // number
y; // 1 | 2
}
}
在switch语句中,每一个case分支语句都相当于等式类型守卫。
在case分支中,编译器会对条件表达式进行类型细化。
function f(x: number) {
switch (x) {
case 0:
x; // 0
break;
case 1:
x; // 1
break;
default:
x; // number
}
}
此例中,switch语句的每个case分支都相当于将x与case表达式的值进行相等比较并可以视为等式类型守卫,编译器能够细化参数x的类型。
自定义类型守卫函数
除了内置的类型守卫之外,TypeScript允许自定义类型守卫函数。
类型守卫函数是指在函数返回值类型中使用了类型谓词的函数。
类型谓词的语法如下所示:
x is T
在该语法中,x为类型守卫函数中的某个形式参数名;T表示任意的类型。
从本质上讲,类型谓词相当于boolean类型。
类型谓词表示一种类型判定,即判定x的类型是否为T。
当在if语句中或者逻辑表达式中使用类型守卫函数时,编译器能够将x的类型细化为T类型。
type A = { a: string };
type B = { b: string };
function isTypeA(x: A | B): x is A {
return (x as A).a !== undefined;
}
function isTypeB(x: A | B): x is B {
return (x as B).b !== undefined;
}
function f(x: A | B) {
// 13
if (isTypeA(x)) {
x; // A
} else {
x; // B
}
if (isTypeB(x)) {
x; // B
} else {
x; // A
}
}
此例第13行使用isTypeA类型守卫函数,在if分支中编译器能够将参数x的类型细化为A类型,同时在else分支中编译器能够将参数x的类型细化为B类型。
this类型守卫
在类型谓词“x is T”中,x可以为关键字this,这时它叫作this类型守卫。
this类型守卫主要用于类和接口中,它能够将方法调用对象的类型细化为T类型。
class Teacher {
isStudent(): this is Student {
return false;
}
}
class Student {
grade: string;
isStudent(): this is Student {
return true;
}
}
function f(person: Teacher | Student) {
// 16
if (person.isStudent()) {
person.grade; // Student
}
}
此例中,isStudent方法是this类型守卫,能够判定this对象是否为Student类的实例对象。
第16行,在if语句中使用了this类型守卫后,编译器能够将if分支中person对象的类型细化为Student类型。
请注意,类型谓词“this is T”只能作为函数和方法的返回值类型,而不能用作属性或存取器的类型。
在TypeScript的早期版本中曾支持在属性上使用“this is T” 类型谓词,但是在之后的版本中移除了该特性。
可辨识联合类型
在程序中,通过结合使用联合类型、单元类型和类型守卫能够创建出一种高级应用模式,这称作可辨识联合。
可辨识联合也叫作标签联合或变体类型,是一种数据结构,该数据结构中存储了一组数量固定且种类不同的类型,还存在一个标签字段,该标签字段用于标识可辨识联合中当前被选择的类型,在同一时刻只有一种类型会被选中。
可辨识联合在函数式编程中比较常用,TypeScript基于现有的代码结构和编码模式提供了对可辨识联合的支持。
根据可辨识联合的定义,TypeScript中的可辨识联合类型由以下几个要素构成:
- 一组数量固定且种类不同的对象类型。这些对象类型中含有共同的判别式属性,判别式属性就是可辨识联合定义中的标签属性。若一个对象类型中包含判别式属性,则该对象类型是可辨识对象类型。
- 由可辨识对象类型组成的联合类型即可辨识联合,通常我们会使用类型别名为可辨识联合类型命名。
- 判别式属性类型守卫。判别式属性类型守卫的作用是从可辨识联合中选取某一特定类型。
通过一个例子来介绍可辨识联合的构造及使用方式
第一步:我们使用接口定义了两个对象类型Square和Circle。
这两个对象类型中包含了共同的判别式属性kind。
interface Square {
kind: 'square';
size: number;
}
interface Circle {
kind: 'circle';
radius: number;
}
第二步,创建可辨识对象类型Square和Circle的联合类型,即可辨识联合。
我们使用类型别名为该可辨识联合类型命名,以方便在程序中使用。
type Shape = Square | Circle;
最后,我们将所有代码合并在一起。
在程序中使用判别式属性类型守卫从可辨识联合类型中选取某一特定类型。
interface Square {
kind: 'square';
size: number;
}
interface Circle {
kind: 'circle';
radius: number;
}
type Shape = Square | Circle;
function f(shape: Shape) {
// 14
if (shape.kind === 'square') {
shape; // Square
}
if (shape.kind === 'circle') {
shape; // Circle
}
}
此例第14行和第18行,在if语句中使用了判别式属性类型守卫去检查判别式属性的值。
第15行,在if分支中根据判别式属性值“'square'”能够将可辨识联合细化为具体的Square对象类型。
同理,第19行,在if分支中根据判别式属性值“'circle'”能够将可辨识联合细化为具体的Circle对象类型。
判别式属性
对于可辨识联合类型整体来讲,其判别式属性的类型是一个联合类型,该联合类型的成员类型是由每一个可辨识对象类型中该判别式属性的类型所组成。
TypeScript要求在判别式属性的联合类型中至少有一个单元类型。关于单元类型的详细介绍请参考5.6节。
字符串字面量类型是常用的判别式属性类型,它正是一种单元类型。
除此之外,也可以使用数字字面量类型和枚举成员字面量类型等任意单元类型。
例如,下例中以数字字面量类型作为判别式属性:
interface A {
kind: 0;
c: number;
}
interface B {
kind: 1;
d: number;
}
type T = A | B;
function f(t: T) {
if (t.kind === 0) {
t; // A
} else {
t; // B
}
}
按照判别式属性的定义,可辨识联合类型中可以同时存在多个判别式属性。
interface A {
kind: true;
type: 'A';
}
interface B {
kind: false;
type: 'B';
}
type T = A | B;
function f(t: T) {
if (t.kind === true) {
t; // A
} else {
t; // B
}
if (t.type === 'A') {
t; // A
} else {
t; // B
}
}
通常情况下,判别式属性的类型都是单元类型,因为这样做方便在判别式属性类型守卫中进行比较。但在实际代码中事情往往没有这么简单,有些时候判别式属性不全是单元类型。
因此,TypeScript也适当放宽了限制,不要求可辨识联合中每一个判别式属性的类型都为单元类型,而是要求至少存在一个单元类型的判别式属性。
下例中的Result是可辨识联合类型,判别式属性error的类型为联合类型“null | Error”,其中,null类型是单元类型,而Error类型不是单元类型。
示例如下:
interface Success {
error: null;
value: number;
}
interface Failure {
error: Error;
}
type Result = Success | Failure;
function f(result: Result) {
if (result.error) {
result; // Failure
}
if (!result.error) {
result; // Success
}
}
判别式属性类型守卫
判别式属性类型守卫表达式支持以下几种形式:
- x.p
- !x.p
- x.p == v
- x.p === v
- x.p != v
- x.p !== v
其中,x代表可辨识联合对象;p为判别式属性名;v若存在,则为一个表达式。
判别式属性类型守卫能够对可辨识联合对象x进行类型细化。
interface Square {
kind: 'square';
size: number;
}
interface Rectangle {
kind: 'rectangle';
width: number;
height: number;
}
interface Circle {
kind: 'circle';
radius: number;15
}
type Shape = Square | Rectangle | Circle;
function f(shape: Shape) {
if (shape.kind === 'square') {
shape; // Square
} else {
shape; // Circle
}
if (shape.kind !== 'square') {
shape; // Rectangle | Circle
} else {
shape; // Square
}
if (shape.kind === 'square' || shape.kind === 'rectangle') {
shape; // Square | Rectangle
} else {
shape; // Circle
}
}
除了使用判别式属性类型守卫和if语句之外,还可以使用switch语句来对可辨识联合类型进行类型细化。
在每个case语句中,都会根据判别式属性的类型来细化可辨识联合类型。
可辨识联合完整性检查
可辨识联合是由一组数量固定且种类不同的对象类型构成。
编译器能够利用该性质并结合switch语句来对可辨识联合进行完整性检查。
编译器能够分析出switch语句是否处理了可辨识联合中的所有可辨识对象。
如果switch语句中的分支能够匹配expr表达式的所有可能值,那么我们将该switch语句称作完整的switch语句。若switch语句中定义了default分支,那么该switch语句一定是完整的switch语句。
interface Circle {
kind: 'circle';
radius: number;
}
interface Square {
kind: 'square';
size: number;
}
type Shape = Circle | Square;
function area(s: Shape): number {
switch (s.kind) {
case 'square':
return s.size * s.size;
case 'circle':
return Math.PI * s.radius * s.radius;
}
// 21
console.log('foo'); // <- 检测到此行为不可达的代码
}
在switch语句中,两个case分支分别匹配了Circle和Square类型并返回。
编译器能够检测出switch语句已经处理了所有可能的情况并退出函数,同时第21行的代码不可能被执行到。
在这种情况下,编译器会给出提示“存在执行不到的代码”。
更通用的完整性检查方法是给switch语句添加default分支,并在default分支中使用一个特殊的辅助函数来帮助进行完整性检查。
interface Circle {
kind: 'circle';
radius: number;
}
interface Square {
kind: 'square';
size: number;
}
type Shape = Circle | Square;
function area(s: Shape) {
switch (s.kind) {
case 'square':
return s.size * s.size;
default:
assertNever(s);
// ~
// 编译错误!类型'Circle'不能赋值给类型'never'
}
}
function assertNever(x: never): never {
throw new Error('Unexpected object: ' + x);
}
此例中的方法是一种变通方法,它需要定义一个额外的assertNever()函数并声明它的参数类型为never类型。
该方法能够帮助进行完整性检查的原因是,如果switch语句的case分支没有匹配到所有可能的可辨识对象类型,那么在default分支中s的类型为某一个或多个可辨识对象类型,而对象类型不允许赋值给never类型,因此会产生编译错误。
但如果case语句匹配了全部的可辨识对象类型,那么default分支中s的类型为never类型,因此也就不会产生编译错误。
赋值语句分析
除了利用类型守卫去细化类型,TypeScript编译器还能够分析代码中的赋值语句,并根据等号右侧操作数的类型去细化左侧操作数的类型。
例如,当给变量赋予一个字符串值时,编译器可以将该变量的类型细化为string类型。
let x;
x = true;
x; // boolean
x = false;
x; // boolean
x = 'x';
x; // string
x = 0;
x; // number
x = 0n;
x; // bigint
x = Symbol();
x; // symbol
x = undefined;
x; // undefined
x = null;
x; // null
在声明变量x时没有使用类型注解,因此编译器仅根据变量x被赋予的值进行类型细化。
但如果在变量或参数声明中包含了类型注解,那么在进行类型细化时同样会参考变量声明的类型。
let x: boolean | 'x';
x = 'x';
x; // 'x'
x = true;
x; // true
此例第3行,给变量x赋予了一个字符串值'x'。
第5行,变量x细化后的类型为字符串字面量类型'x',而不是string类型。
这是因为编译器在细化类型时必须参考变量声明的类型,细化后的类型能够赋值给变量声明的类型是最基本的要求。
基于控制流的类型分析
TypeScript编译器能够分析程序代码中所有可能的执行路径,从而得到在代码中某一特定位置上的变量类型和参数类型等,我们将这种类型分析方式叫作基于控制流的类型分析。
常用的控制流语句有if语句、switch语句以及return语句等。
在使用类型守卫时,我们已经在使用基于控制流的类型分析了。
通过基于控制流的类型分析,编译器还能够对变量进行确切赋值分析。
确切赋值分析能够对数据流进行分析,其目的是确保变量在使用之前已经被赋值。
function f(check: boolean) {
let x: number;
// 3
x; // 编译错误!变量 'x' 在赋值之前使用
if (check) {
x = 1;
x; // number
}
// 10
x; // 编译错误!变量 'x' 在赋值之前使用
x = 2;
x; // number
}
上例中第3行和第10行会产生编译错误,因为在使用变量x之前它没有被赋值;但是在第7行没有编译错误,因为
第6行对变量x进行了赋值操作,这就是确切赋值分析的作用。
断言函数
在程序设计中,断言表示一种判定。
如果对断言求值后的结果为false,则意味着程序出错。
TypeScript 3.7引入了断言函数功能。断言函数用于检查实际参数的类型是否符合类型判定。
若符合类型判定,则函数正常返回;若不符合类型判定,则函数抛出异常。
基于控制流的类型分析能够识别断言函数并进行类型细化。
断言函数有以下两种形式:
function assert(x: unknown): asserts x is T { }
//或
function assert(x: unknown): asserts x { }
在该语法中,“asserts x is T”和“asserts x”表示类型判定,它只能作为函数的返回值类型。
asserts和is是关键字;x必须为函数参数列表中的一个形式参数名;T表示任意的类型;“is T”部分是可选的。
若一个函数带有asserts类型判定,那么该函数就是一个断言函数。
接下来将分别介绍这两种断言函数。
asserts x is T
对于“asserts x is T”形式的断言函数,它只有在实际参数x的类型为T时才会正常返回,否则将抛出异常。
function assertIsBoolean(x: unknown): asserts x is boolean {
if (typeof x !== 'boolean') {
throw new TypeError('Boolean type expected.');
}
}
在assertIsBoolean断言函数的函数体中,开发者需要按照约定的断言函数语义去实现断言函数。
第2行使用了类型守卫,当参数x的类型不是boolean时函数抛出一个异常。
asserts x
对于“asserts x”形式的断言函数,它只有在实际参数x的值为真时才会正常返回,否则将抛出异常。
例如,下例中定义了assertTruthy断言函数,它的类型判定为“asserts x”。
这表示只有在参数x是真值时,该函数才会正常返回,如果参数x不是真值,那么assertTruthy函数将抛出异常。
function assertTruthy(x: unknown): asserts x {
if (!x) {
throw new TypeError(`${x} should be a truthy value.`);
}
}
在assertTruthy断言函数的函数体中,开发者需要按照约定的断言函数语义去实现断言函数。
第2行使用了类型守卫,当参数x是假值时,函数抛出一个异常。
断言函数的返回值
在定义断言函数时,我们需要将函数的返回值类型声明为asserts类型判定。
编译器将asserts类型判定视为void类型,这意味着断言函数的返回值类型是void。
从类型兼容性的角度来考虑:undefined类型可以赋值给void类型;never类型是尾端类型,也可以赋值给void类型;当然,还有无所不能的any类型也可以赋值给void类型。
除此之外,任何类型都不能作为断言函数的返回值类型(在严格类型检查模式下)
下例中,f0断言函数和f1断言函数都是正确的使用方式。如果函数抛出异常,那么相当于函数返回值类型为never类型;如果函数没有使用return语句,那么在正常退出函数时相当于返回了undefined值。
f2断言函数和f3断言函数是错误的使用方式,因为它们的返回值类型与void类型不兼容。
function f0(x: unknown): asserts x {
if (!x) {
// 相当于返回 never 类型,与 void 类型兼容
throw new TypeError(
`${x} should be a truthy value.`
);
}
// 正确,隐式地返回 undefined 类型,与 void 类型兼容
}
function f1(x: unknown): asserts x {
if (!x) {
throw new TypeError(
`${x} should be a truthy value.`
);
}
// 正确
return undefined; // 返回 undefined 类型,与 void类型兼容
}
function f2(x: unknown): asserts x {
if (!x) {
throw new TypeError(
`${x} should be a truthy value.`
);
}
return false; // 编译错误!类型 false 不能赋值给类型void
}
function f3(x: unknown): asserts x {
if (!x) {
throw new TypeError(
`${x} should be a truthy value.`
);
}
return null; // 编译错误!类型 null 不能赋值给类型void
}
断言函数的应用
当程序中调用了断言函数后,其结果一定为以下两种情况之一:
- 断言判定失败,程序抛出异常并停止继续向后执行代码
- 断言判定成功,程序继续向后执行代码
基于控制流的类型分析能够利用以上的事实对调用断言函数之后的代码进行类型细化。
function assertIsNumber(x: unknown): asserts x isnumber {
if (typeof x !== 'number') {
throw new TypeError(`${x} should be a number.`);
}
}
function f(x: any, y: any) {
x; // any
y; // any
assertIsNumber(x);
assertIsNumber(y);
x; // number
y; // number
}
此例中,assertIsNumber断言函数用于确保传入的参数是number类型。f函数的两个参数x和y都是any类型。
第8、9行还没有执行断言函数,这时参数x和y都是any类型。第14、15行,在执行了assertIsNumber断言函数后,编译器能够分析出当前位置上参数x和y的类型一定是number类型。
因为如果不是number类型,那么意味着断言函数已经抛出异常并退出了f函数,不可能执行到第14和15行位置。该分析结果也符合事实。
我们之前介绍了返回值类型为never的函数。
如果一个函数抛出了异常或者陷入了死循环,那么该函数无法正常返回一个值,因此该函数的返回值类型为never类型。
如果程序中调用了一个返回值类型为never的函数,那么就意味着程序会在该函数的调用位置终止,永远不会继续执行后续的代码。
类似于对断言函数的分析,编译器同样能够分析出返回值类型为never类型的函数对控制流的影响以及对变量或参数等类型的影响。
例如,在下例的函数f中,编译器能够推断出在if语句之外的参数x的类型为string类型。因为如果x的类型为undefined类型,那么函数将“终止”于第7行。
function neverReturns(): never {
throw new Error();
}
function f(x: string | undefined) {
if (x === undefined) {
// 07
neverReturns();
}
x; // string
}
TypeScript类型深入
子类型兼容性
在编程语言理论中,子类型与超(父)类型是类型多态的一种表现形式。
子类型与超类型都有其各自的数据类型,将两者关联在一起的是它们之间的可替换关系。
面向对象程序设计中的里氏替换原则描述了程序中任何使用了超类型的地方都可以用其子类型进行替换,并且在替换后程序的行为保持不变。
当使用子类型替换超类型时,不需要修改任何其他代码,程序依然能够正常工作。
类型系统可靠性
如果一个类型系统能够识别并拒绝程序中所有可能的类型错误,那么我们称该类型系统是可靠的。
TypeScript中的类型系统允许一些未知操作通过类型检查。
因此,TypeScript的类型系统不总是可靠的。
例如,我们可以使用类型断言来改写一个值的类型,尽管提供的类型是错误的,编译器也不会报错。
const a: string = (1 as unknown) as string;
TypeScript类型系统中的不可靠行为大多经过了严格的设计考量来适配JavaScript程序中早已广泛使用的编码模式。
TypeScript也提供了一些严格类型检查的编译选项,例如“--strictNullChecks”等,通过启用这些编译选项可以有选择地逐渐增强类型系统的可靠性。
子类型的基本性质
符号约定
我们先约定一下本书中表示子类型和超类型关系的符号以便于之后的描述。
若类型A是类型B的子类型,则记作:
A <: B
若类型A是类型B的超类型,则记作:
A :> B
自反性
子类型关系与超类型关系具有自反性,即任意类型都是其自身的子类型和超类型。
自反性可以使用如下符号表示:
A <: A 且 A :> A
传递性
子类型关系与超类型关系也具有传递性。
若类型A是类型B的子类型,且类型B是类型C的子类型,那么类型A也是类型C的子类型。
传递性可以使用如下符号表示:
// 如果:
A <: B <: C
// 那么:
A <: C
顶端类型与尾端类型
顶端类型与尾端类型的概念来自类型论,它们是独立于编程语言而存在的。
依据类型论中的描述,顶端类型是一种通用超类型,所有类型都是顶端类型的子类型;同时,尾端类型是所有类型的子类型。
TypeScript中存在两种顶端类型,即any类型和unknown类型。
因此,所有类型都是any类型和unknown类型的子类型。
boolean <: any
string <: any
number <: any
{} <: any
() => void <: any
boolean <: unknown
string <: unknown
number <: unknown
{} <: unknown
() => void <: unknown
TypeScript中仅存在一种尾端类型,即never类型。
因此,never类型是所有类型的子类型。
never <: boolean
never <: string
never <: number
never <: {}
never <: () => void
原始类型
TypeScript中的原始类型有number、bigint、boolean、string、symbol、void、null、undefined、枚举类型以及字面量类型。
原始类型间的子类型关系比较容易分辨。
字面量类型
字面量类型是其对应的基础原始类型的子类型。
例如,数字字面量类型是number类型的子类型,字符串字面量类型是string类型的子类型。
undefined与null
undefined类型和null类型分别只包含一个值,即undefined值和null值。
它们通常用来表示还未初始化的值。
undefined类型是除尾端类型never外所有类型的子类型,其中也包括null类型。
null类型是除尾端类型和undefined类型外的所有类型的子类型。
枚举类型
在联合枚举类型中,每个枚举成员都能够表示一种类型,同时联合枚举成员类型是联合枚举类型的子类型。
enum E {
A,
B,
}
我们可以得出如下子类型关系:
E.A <: E
E.B <: E
在数值型枚举中,每个枚举成员都表示一个数值常量。
因此,数值型枚举类型是number类型的子类型。
例如,有如下数值型枚举类型定义:
enum E {
A = 0,
B = 1,
}
我们可以得出如下子类型关系:
E <: number
函数类型
函数类型由参数类型和返回值类型构成。
在比较两个函数类型间的子类型关系时要同时考虑参数类型和返回值类型。
在介绍函数类型间的子类型关系之前,让我们先介绍一个重要的概念,即变型
变型
变型与复杂类型间的子类型关系有着密不可分的联系。
变型描述的是复杂类型的组成类型是如何影响复杂类型间的子类型关系的。
例如,已知Cat类型是Animal类型的子类型,那么Cat数组类型是否是Animal数组类型的子类型?又或者有一个参数类型为Cat类型的函数以及参数类型为Animal类型的函数,这两个函数间的子类型关系又如何?为了确定复杂类型间的子类型关系,编译器需要根据某种变型关系进行判断。
变型关系主要有以下三种:
- 协变
- 逆变
- 双变
现约定如果复杂类型Complex是由类型T构成,那么我们将其记作Complex(T)。
假设有两个复杂类型Complex(A)和Complex(B),如果由A是B的子类型能够得出Complex(A)是Complex(B)的子类型,那么我们将这种变型称作协变。
协变关系维持了复杂类型与其组成类型间的子类型关系。
协变的子类型关系如下所示(符号“→”表示能够推导出):
A <: B → Complex(A) <: Complex(B)
如果由A是B的子类型能够得出Complex(B)是Complex(A)的子类型,那么我们将这种变型称作逆变。
逆变关系反转了复杂类型与其组成类型间的子类型关系。
逆变的子类型关系如下所示:
A <: B → Complex(B) <: Complex(A)
如果由A是B的子类型或者B是A的子类型能够得出Complex(A)是Complex(B)的子类型,那么我们将这种变型称作双变。
双变同时具有协变关系与逆变关系。
双变的子类型关系如下所示:
A <: B 或 B <: A → Complex(A) <: Complex(B)
最后,若类型间不存在上述变型关系,那么我们称之为不变。
函数参数数量
在确定函数类型间的子类型关系时,编译器将检查函数的参数数量。
若函数类型S是函数类型T的子类型,则S中的每一个必选参数必须能够在T中找到对应的参数,即S中必选参数的个数不能多于T中的参数个数。
type S = (a: number) => void;
type T = (x: number, y: number) => void;
若函数类型S是函数类型T的子类型,则T中的可选参数会计入参数总数,也就是在比较参数个数时不区分T中的可选参数和必选参数。
type S = (a: number) => void;
type T = (x?: number, y?: number) => void;
若函数类型S是函数类型T的子类型,则T中的剩余参数会被视作无穷多的可选参数并计入参数总数。
在这种情况下相当于不进行参数个数检查,因为S的参数个数不可能比无穷多还多。
type S = (a: number, b: number) => void;
type T = (...x: number[]) => void;
通过以上两个例子可以看到,当T中存在可选参数或剩余参数时,函数类型检查是不可靠的。因为当使用子类型S替换了超类型T之后,调用S时的实际参数个数可能少于必选参数的个数。
例如,有如下的函数s和函数t,其中s是t的子类型,使用一个实际参数调用函数t没有问题,但是将t替换为其子类型s后会产生错误,因为调用s需要两个实际参数。
function s(a: number, b: number): void {}
function t(...x: number[]): void {}
t(0);
s(0); // 编译错误
上面介绍了如何处理超类型(函数类型T)中的可选参数和剩余参数。
接下来,我们再看一下如何处理子类型(函数类型S)中存在的可选参数和剩余参数。
若函数类型S是函数类型T的子类型,则S中的可选参数不计入参数总数,即允许S中存在多余的可选参数。
type S = (a: boolean, b?: boolean) => void;
type T = (x: boolean) => void;
若函数类型S是函数类型T的子类型,则S中的剩余参数也不计入参数总数。
type S = (a: boolean, ...b: boolean[]) => void;
type T = (x: boolean) => void;
函数参数类型
函数的参数类型会影响函数类型间的子类型关系。
编译器在检查函数参数类型时有两种检查模式可供选择:
- 非严格函数类型检查模式(默认模式)。
- 严格函数类型检查模式。
非严格函数类型检查
非严格函数类型检查是编译器默认的检查模式。
在该模式下,函数参数类型与函数类型是双变关系。
若函数类型S是函数类型T的子类型,那么S的参数类型必须是T中对应参数类型的子类型或者超类型。
这意味着在对应位置上的两个参数只要存在子类型关系即可,而不强调哪一方应该是另一方的子类型。
type S = (a: 0 | 1) => void;
type T = (x: number) => void;
此例中,S是T的子类型,同时T也是S的子类型。
在默认的类型检查模式下,函数类型检查是不可靠的,因为编译器允许使用更具体的类型来替换宽松的类型。
这会导致原本合法的函数调用在替换后变得不合法,因为替换后的函数参数类型要求更加严格。
这个问题可以通过启用严格函数类型检查来解决。
严格函数类型检查
TypeScript编译器提供了“--strictFunctionTypes”编译选项用来启用严格的函数类型检查。
在该模式下,函数参数类型与函数类型是逆变关系,而非相对宽松的双变关系。
type S = (a: number) => void;
type T = (x: 0 | 1) => void;
此例中,S是T的子类型,S中参数a的类型必须是T中参数x类型的超类型。
因此,上一节中的例子在严格函数类型检查模式下将产生编译错误。
通过以上介绍能够了解到,在“--strictFunctionTypes”模式下函数参数类型检查是可靠的,因为它只允许使用更宽松的类型来替换具体的类型。
函数返回值类型
在确定函数类型间的子类型关系时,编译器将检查函数返回值类型是否兼容。
不论是否启用了“--strictFunctionTypes”编译选项,函数返回值类型与函数类型始终是协变关系。
若函数类型S是函数类型T的子类型,那么S的返回值类型必须是T的返回值类型的子类型。
type S = () => 0 | 1;
type T = () => number;
此例中,函数类型S是函数类型T的子类型。
编译器对函数返回值类型的检查是可靠的,因为在期望得到number类型的地方提供更加具体的“0 | 1”类型是合法的。
函数重载
在确定函数类型间的子类型关系时,编译器将检查函数重载签名类型是否兼容。
若函数类型S是函数类型T的子类型,并且T存在函数重载,那么T的每一个函数重载必须能够在S的函数重载中找到与其对应的子类型。
type S = {
(x: string): string;
(x: number): number;
};
type T = {
(x: 'a'): string;
(x: 0): number;
};
此例中,函数类型S是函数类型T的子类型,T中的两个函数重载能够在S中找到与之对应的子类型。
对象类型
对象类型由零个或多个类型成员组成,在比较对象类型的子类型关系时要分别考虑每一个类型成员。
结构化子类型
在TypeScript中,对象类型间的子类型关系取决于对象的结构,我们称之为结构化子类型。
在结构化子类型系统中仅通过比较两个对象类型的类型成员列表就能够确定它们的子类型关系。
对象类型的名称完全不影响对象类型间的子类型关系。
class Point {
x: number = 0;
y: number = 0;
}
class Position {
x: number = 0;
y: number = 0;
}
const point: Point = new Position();
const position: Position = new Point();
属性成员类型
若对象类型S是对象类型T的子类型,那么对于T中的每一个属性成员M(如下例中的接口T及其成员x和y)都能够在S中找到一个同名的属性成员N(如下例中的接口S及其成员x和y),并且N是M的子类型。
由此可知,对象类型T中的属性成员数量不能多于对象类型S中的属性成员数量。
interface T {
x: string;
y: string;
}
interface S {
x: 'x';
y: 'y';
z: 'z';
}
此例中,对象类型S是对象类型T的子类型。
若对象类型S是对象类型T的子类型,那么T中的必选属性成员(如下例中的接口T及其成员x)在S中也必须为必选属性成员(如下例中的接口S及其成员x)。
interface T {
x: string;
}
interface S0 {
x: string;
y: string;
}
interface S1 {
x?: string;
y: string;
}
此例中,S0是T的子类型,但S1不是T的子类型。
调用签名与构造签名
如果对象类型S是对象类型T的子类型,那么对于T中的每一个调用签名M(如下例中的接口T及其调用签名“(x: string): boolean;”和“(x: string, y: number): boolean;”)都能够在S中找到一个调用签名N(如下例中的接口S及其调用签名“(x: string, y?: number):boolean;”),且N是M的子类型。
interface T {
(x: string): boolean;
(x: string, y: number): boolean;
}
interface S {
(x: string, y?: number): boolean;
}
对象类型中的构造签名与调用签名有着相同的判断规则。
如果对象类型S是对象类型T的子类型,那么对于T中的每一个构造签名M(如下例中的接口T及其构造签名“new (x: string): object;”和“new(x: string, y: number): object;”)都能够在S中找到一个构造签名N(如下例中的接口S及其构造签名“new (x: string, y?:number): object;”),且N是M的子类型。
interface T {
new (x: string): object;
new (x: string, y: number): object;
}
interface S {
new (x: string, y?: number): object;
}
此例中,对象类型S是对象类型T的子类型。
字符串索引签名
假设对象类型S是对象类型T的子类型,如果T中存在字符串索引签名(如下例中的接口T及其字符串索引签名“[x: string]:boolean;”),那么S中也应该存在字符串索引签名(如下例中的接口S及其字符串索引签名“[x: string]: true;”),并且是T中字符串索引签名的子类型。
interface T {
[x: string]: boolean;
}
interface S {
[x: string]: true;
}
此例中,对象类型S是对象类型T的子类型。
数值索引签名
假设对象类型S是对象类型T的子类型,如果T中存在数值索引签名(如下例中的接口T及其数字索引签名“[x: number]:boolean;”),那么S中应该存在字符串索引签名或数值索引签名(如下例中的接口S0及其字符串索引签名“[x: string]: true;”或者接口S1及其数字索引签名“[x: number]: true;”),并且是T中数值索引签名的子类型。
interface T {
[x: number]: boolean;
}
interface S0 {
[x: string]: true;
}
interface S1 {
[x: number]: true;
}
此例中,对象类型S0和S1是对象类型T的子类型。
类实例类型
在确定两个类类型之间的子类型关系时仅检查类的实例成员类型,类的静态成员类型以及构造函数类型不进行检查。
class Point {
x: number;
y: number;
static t: number;
constructor(x: number) {}
}
class Position {
x: number;
y: number;
z: number;
constructor(x: string) {}
}
const point: Point = new Position('');
此例中,Position是Point的子类型,在确定子类型关系时仅检查x和y属性。
如果类中存在私有成员或受保护成员,那么在确定类类型间的子类型关系时要求私有成员和受保护成员来自同一个类,这意味着两个类需要存在继承关系。
class Point {
protected x: number;
}
class Position {
protected x: number;
}
此例中,Point和Position类型之间不存在子类型关系。
虽然两者都定义了number类型的属性x,但它们是受保护成员,因此要求属性x必须来自同一个类。
class Point {
protected x: number = 0;
}
class Position extends Point {
protected y: number = 0;
}
此例中,Point和Position中的受保护成员x都来自Point,因此Position是Point的子类型。
泛型
泛型指的是带有类型参数的类型,本节将介绍如何判断泛型间的子类型关系。
泛型对象类型
对于泛型接口、泛型类和表示对象类型的泛型类型别名而言,实例化泛型类型时使用的实际类型参数不影响子类型关系,真正影响子类型关系的是泛型实例化后的结果对象类型。
例如,对于下例中的泛型接口Empty,不论使用什么实际类型参数来实例化都不影响子类型关系,因为实例化后的Empty类型始终为空对象类型“{}”。
interface Empty<T> {}
type T = Empty<number>;
type S = Empty<string>;
// 此例中,对象类型S是对象类型T的子类型,同时对象类型T也是对象类型S的子类型。
在下例中,泛型实际类型参数T将影响实例化后的对象类型NotEmpty。
在比较子类型关系时,使用的是泛型实例化后的结果对象类型。
interface NotEmpty<T> {
data: T;
}
type T = NotEmpty<boolean>;
type S = NotEmpty<true>;
此例中,对象类型S是对象类型T的子类型。
泛型函数类型
与检查函数类型相似,编译器在检查泛型函数类型时有两种检查模式可供选择:
- 非严格泛型函数类型检查。
- 严格泛型函数类型检查。
TypeScript编译器提供了“--noStrictGenericChecks”编译选项用来启用或关闭严格泛型函数类型检查。
非严格泛型函数类型检查
在非严格泛型函数类型检查模式下,编译器先将所有的泛型类型参数替换为any类型,然后再确定子类型关系。这意味着泛型类型参数不影响泛型函数的子类型关系。
type A = <T, U>(x: T, y: U) => [T, U];
type B = <S>(x: S, y: S) => [S, S];
//首先,将所有的类型参数替换为any类型,结果如下:
type A = (x: any, y: any) => [any, any];
type B = (x: any, y: any) => [any, any];
在替换后,A和B类型变成了相同的类型,因此A是B的子类型,同时B也是A的子类型。
严格泛型函数类型检查
在严格的泛型函数类型检查模式下,不使用any类型替换所有的类型参数,而是先通过类型推断来统一两个泛型函数的类型参数,然后再确定两者的子类型关系。
有如下的泛型函数类型A和B:
type A = <T, U>(x: T, y: U) => [T, U];
type B = <S>(x: S, y: S) => [S, S];
如果我们想要确定A是否为B的子类型,那么先尝试使用B的类型来推断A的类型。
通过比较每个参数类型和返回值类型,能够得出类型参数T和U均为S。接下来使用推断的结果来实例化A类型,即将类型A中的T和U均替换为S,替换后的结果如下:
type A = <S>(x: S, y: S) => [S, S];
在统一了类型参数之后,再来比较泛型函数间的子类型关系。
因为统一后的类型A和B相同,所以A是B的子类型。
至此,A和B的子类型关系确定完毕。
注意,这时不能确定B是否也为A的子类型,因为当前的推导过程是由B向A推导。
现在反过来,如果我们最开始想要确定B是否为A的子类型,那么这时将由A向B来推断并统一类型参数的值。
经推断,S的类型为联合类型“T | U”,然后使用“S = T | U”来实例化B类型;
type B = <T, U>(x: T | U, y: T | U) => [T | U, T | U];
在统一了类型参数之后,再来比较A和 B之间的子类型关系。
type A = <T, U>(x: T, y: U) => [T, U];
type B = <T, U>(x: T | U, y: T | U) => [T | U, T | U];
此时,B不是A的子类型,因为B的返回值类型不是A的返回值类型的子类型。
联合类型
联合类型由若干成员类型构成,在计算联合类型的子类型关系时需要考虑每一个成员类型。
假设有联合类型“S = S0 | S1”和任意类型T,如果成员类型S0是类型T的子类型,并且成员类型S1是类型T的子类型,那么联合类型S是类型T的子类型。
type S = 0 | 1;
type T = number;
此例中,联合类型S是类型T的子类型。
假设有联合类型“S = S0 | S1”和任意类型T,如果类型T是成员类型S0的子类型,或者类型T是成员类型S1的子类型,那么类型T是联合类型S的子类型。
type S = number | string;
type T = 0;
此例中,类型T是联合类型S的子类型。
交叉类型
交叉类型由若干成员类型构成,在计算交叉类型的子类型关系时需要考虑每一个成员类型。
假设有交叉类型“S = S0 & S1”和任意类型T,如果成员类型S0是类型T的子类型,或者成员类型S1是类型T的子类型,那么交叉类型S是类型T的子类型。
type S = { x: number } & { y: number };
type T = { x: number };
此例中,交叉类型S是类型T的子类型。
假设有交叉类型“S = S0 & S1”和任意类型T,如果类型T是成员类型S0的子类型,并且类型T是成员类型S1的子类型,那么类型T是交叉类型S的子类型。
type S = { x: number } & { y: number };
type T = { x: number; y: number; z: number };
此例中,类型T是交叉类型S的子类型。
赋值兼容性
TypeScript中存在两种兼容性,即子类型兼容性和赋值兼容性。子类型兼容性与赋值兼容性有着密切的联系,若类型S是类型T的子类型,那么类型S能够赋值给类型T。
在赋值语句中,变量和表达式之间需要满足赋值兼容性;在函数调用语句中,函数形式参数与实际参数之间也要满足赋值兼容性。
type T = { x: number };
type S = { x: number; y: number };
let t: T = { x: 0 };
let s: S = { x: 0, y: 0 };
t = s;
function f(t: T) {}
f(t);
f(s);
此例中,S是T的子类型,那么S可以赋值给T,同时可以使用S来调用接收T类型参数的函数。
子类型兼容性
在绝大多数情况下,如果类型S能够赋值给类型T,那么也意味着类型S是类型T的子类型。
针对这个规律只有以下几种例外情况:
- any类型。在赋值兼容性中,any类型能够赋值给任何其他类型,但any类型不是其他类型的子类型,因为any类型是顶端类型。
- 数值型枚举与number类型。number类型可以赋值给数值型枚举类型,但number类型不是数值型枚举的子类型,反而数值型枚举是number类型的子类型。
enum E {
A,
B,
}
const s: number = 0;
const t: E = s;
- 带有可选属性的对象类型。如果对象类型T中有可选属性M,那么对象类型S也可以赋值给对象类型T,即使S中没有属性M。
type T = { x: number; y?: number };
type S = { x: number };
const s: S = { x: 0 };
const t: T = s;
此例中,类型S能够赋值给类型T,但是类型S不是类型T的子类型,因为类型T中的属性y不能够在类型S中找到对应的属性定义。
类型推断
在TypeScript程序中,每一个表达式都具有一种类型,表达式类型的来源有以下两种:
- 类型注解
- 类型推断
类型注解是最直接地定义表达式类型的方式,而类型推断是指在没使用类型注解的情况下,编译器能够自动地推导出表达式的类型。
在绝大部分场景中,TypeScript编译器都能够正确地推断出表达式的类型。类型推断在一定程度上简化了代码,避免了在程序中为每一个表达式添加类型注解
常规类型推断
当程序中声明了一个变量并且给它赋予了初始值,那么编译器能够根据变量的初始值推断出变量的类型。
如果我们声明了一个常量,那么编译器能够推断出更加精确的类型。
const x = 0;
// ~
// 推断类型为:数字字面量类型
如果声明变量时没有设置初始值,那么编译器将推断出变量的类型为any类型。
推断函数返回值的类型是另一个典型的类型推断场景,编译器能够根据函数中的return语句来推断出函数的返回值类型。
最佳通用类型
在编译器进行类型推断的过程中,有可能推断出多个可能的类型。
例如,有如下的数组定义,该数组中既有number类型的元素,也有string类型的元素。
编译器在推断数组的类型时,会参考每一个数组元素的类型。因此,编译器最终推断出的数组类型为联合类型“number | string”。
let x = [0, 'one']; // (number | string)[]
此例中,每一种可能的数组元素类型都会作为类型推断的候选类型。
编译器会从所有的候选类型中计算出最佳通用类型作为类型推断的结果类型。
此例中,number类型和string类型的最佳通用类型是联合类型“number | string”,因为这两个类型之间没有子类型关系。
下面的例子能够更好地体现最佳通用类型的计算。此例中,zoo数组有三个元素,分别为Dog、Cat和Animal类的实例对象。其中,Dog类和Cat类是Animal类的子类。最终,编译器推断出来的zoo数组的类型为“Animal[]”类型。因为Dog和Cat的类型是Animal类型的子类型,因此Animal类型是最佳通用类型。
class Animal {}
class Dog extends Animal {}
class Cat extends Animal {}
const zoo = [new Dog(), new Cat(), new Animal()];
// ~~~
// 推断类型为:Animal[]
如果编译器自动推断出来的类型不是我们想要的类型,那么可以给表达式添加明确的类型注解或者使用类型断言。
class Animal {}
class Dog extends Animal {}
class Cat extends Animal {}
const zoo0: Animal[] = [new Dog(), new Cat()];
const zoo1 = [new Dog(), new Cat()] as Animal[];
按上下文归类
在常规类型推断中,编译器能够在变量声明语句中由变量的初始值类型推断出变量的类型。
这是一种由右向左或者自下而上的类型推断 。
反过来,编译器还能够由变量的类型来推断出变量初始值的类型。
这是一种由左向右或者自上而下的类型推断。我们将这种类型推断称作按上下文归类。

下例中,AddFunction接口带有调用签名,因此它表示函数类型。
我们声明了Add-Function类型的常量add,其类型是使用类型注解明确定义的。
常量add的初始值是箭头函数“(x, y) => x + y”。编译器能够由AddFunction类型推断出箭头函数中参数x和y的类型以及其返回值类型均为number类型。
interface AddFunction {
(a: number, b: number): number;
}
const add: AddFunction = (x, y) => x + y;
在常规类型推断一节中,我们介绍了使用类型注解来“修正”Animal数组的类型推断结果,这正是按上下文归类的应用。
class Animal {}
class Dog extends Animal {}
class Cat extends Animal {}
const zoo: Animal[] = [new Dog(), new Cat()];
此例第5行,如果没有给常量zoo添加类型注解“Animal[]”,那么推断出来的常量zoo的类型为“(Dog | Cat)[]”。
当我们给常量zoo添加了类型注解“Animal[]”后,由于按上下文归类的作用,Animal类型也成了类型推断的候选类型之一。
因此,由Animal类型、Dog类型和Cat类型计算得出的最佳通用类型为Animal类型。
类型放宽
在编译器进行类型推断的过程中,有时会将放宽的源类型作为推断的结果类型。
例如,源类型为数字字面量类型0,放宽后的类型为原始类型number。
let zero = 0 // number 类型
类型放宽是TypeScript语言的内部行为,它并非是提供给开发者的某种功能特性,因此只需了解即可。
TypeScript语言内部的类型放宽分为以下两类:
- 常规类型放宽
- 字面量类型放宽
常规类型放宽
常规类型放宽相对简单,是指编译器在进行类型推断时会将undefined类型和null类型放宽为any类型。
TypeScript 2.0引入了“--strictNullChecks”模式后,常规类型放宽的规则也有所变化。
非严格类型检查模式
在非严格类型检查模式下,即没有启用“--strictNullChecks”编译选项时,undefined类型和null类型会被放宽为any类型。
下例中,所有变量的推断类型均为any类型。需要理解的是即便在非严格类型检查模式下,undefined值的类型依然是undefined类型(null值同理),只是编译器在类型推断时将undefined类型放宽为了any类型 。
let a = undefined; // any
const b = undefined; // any
let c = null; // any
const d = null; // any
严格类型检查模式
在启用了“--strictNullChecks”编译选项时,编译器不再放宽undefined类型和null类型,它们将保持各自的类型 。
下例中,变量a和b推断出的类型为undefined类型,变量c和d推断出的类型为null类型,编译器不会将它们的类型放宽。
let a = undefined; // undefined
const b = undefined; // undefined
let c = null; // null
const d = null; // null
字面量类型放宽
字面量类型放宽是指编译器在进行类型推断时会将字面量类型放宽为基础原始类型,例如将数字字面量类型0放宽为原始类型number。
但实际上,字面量类型放宽远不是像描述的这样简单
细分字面量类型
对于每一个字面量类型可以再将其细分为两种,即可放宽的字面量类型和不可放宽的字面量类型。
每个字面量类型都通过一些内部标识来表示其是否为可放宽的字面量类型。
在一个字面量类型被创建时,就已经确定了其是否为可放宽的字面量类型,并且不能再改变。判断是否为可放宽的字面量类型的规则如下:
- 若字面量类型源自类型,那么它是不可放宽的字面量类型
- 若字面量类型源自表达式,那么它是可放宽的字面量类型
在下例中,常量zero的类型为数字字面量类型0,该类型是通过类型注解定义的,即源自类型。
因此,类型注解中的数字字面量类型0是不可放宽的字面量类型。
const zero: 0 = 0;
// ~
// 类型为:数字字面量类型 0
下例中,赋值运算符右侧为数字字面量0,它是一个表达式并且其类型为数字字面量类型0。
因为该数字字面量类型0源自表达式,所以它是可放宽的字面量类型。
放宽的字面量类型
放宽的字面量类型指的是对字面量类型执行放宽操作后得到的结果类型。
若字面量类型是不可放宽的字面量类型,那么对其执行放宽操作的结果不变,仍为字面量类型本身;若字面量类型是可放宽的字面量类型,那么对其执行放宽操作的结果为相应的基础原始类型
| 可放宽的字面量类型 | 放款的字面量类型 |
|---|---|
| boolean字面量类型,如true | boolean |
| string字面量类型,如id | string |
| 数字字面量类型,如 0 | number |
| Bigint 字面量类型,如 2n | bigint |
| 枚举成员字面量类型 | 枚举类型 |
| 字面量类型的联合类型 | 放宽的字面量类型的联合类型 |
字面量类型放宽的场景
当编译器进行类型推断时,如果当前表达式的值是可变的,那么将推断出放宽的字面量类型;反之,如果当前表达式的值是不可变的,那么不放宽字面量类型。
在var声明和let声明中,若给变量赋予了初始值,那么推断出的变量类型为放宽的初始值类型。
下例中,变量a和变量b的初始值类型为可放宽的数字字面量类型0。因为变量a和变量b的值是可变的,所以两者的推断类型为放宽的字面量类型,即number类型。
var a = 0;
// ~
// 推断的类型为:number
let b = 0;
// ~
// 推断的类型为:number
在const声明中,由于常量的值一经设置就不允许再修改,因此在推断const声明的类型时不会执行类型放宽操作。
下例中,编译器在推断常量a的类型时不会执行类型放宽操作,而是直接使用初始值的类型作为常量a的类型。
const a = 0;
// ~
// 推断的类型为:可放宽的数字字面量类型 0
这里要强调一下,常量a的推断类型为可放宽的数字字面量类型0。
数组字面量中的元素是可以修改的,因此数组字面量元素的推断类型为放宽的字面量类型。
在对象字面量中,属性值是可变的,因此对象字面量属性的推断类型为放宽的字面量类型。
在类的定义中,若非只读属性具有初始值,那么推断出的属性类型为初始值的放宽的字面量类型。
下例中,Foo类的属性a是非只读属性,并且带有初始值0。
因此,属性a的推断类型为放宽的数字字面量类型,即number类型。属性b是只读属性,在推断类型时不执行放宽操作,因此推断类型为其初始值的类型,即可放宽的数字字面量类型0。
class Foo {
a = 0;
// ~
// 推断的类型为:number
readonly b = 0;
// ~
// 推断的类型为:0
}
在函数或方法的参数列表中,若形式参数定义了默认值,那么推断出的参数类型为默认值的放宽的字面量类型。
function foo(x = 0) {
// ~
// 推断的类型为:number
}
const bar = {
baz(x = 0) {
// ~
// 推断的类型为:number
}
};
在函数或方法中,若返回值的类型为字面量类型(不包含字面量类型的联合类型),那么推断的返回值类型为放宽的字面量类型。
下例中,foo函数返回值的类型为数字字面量类型0。
因此,foo函数的推断返回值类型为放宽的数字字面量类型,即number类型。
bar函数的返回值类型为字面量类型联合类型“0 | 1”。
因此,bar函数的推断返回值类型不进行放宽操作,仍为字面量类型联合类型“0 | 1”。
function foo() {
// ~~~
// 推断的返回值类型为:number
return 0;
}
function bar() {
// ~~~
// 推断的返回值类型为:0 | 1
return Math.random() < 0.5 ? 0 : 1;
}
全新的字面量类型
每个字面量类型都有一个内置属性表示其是否可以被放宽。
在TypeScript语言的内部实现中,将源自表达式的字面量类型标记为全新的(fresh)字面量类型,只有全新的字面量类型才是可放宽的字面量类型。
当全新的字面量类型出现在代码中可变值的位置时才会执行类型放宽操作。
const a = 0;
// ~
// 推断的类型为:0
let b = a;
// ~
// 推断的类型为:number
常量a初始值的类型为可放宽的数字字面量类型0,同时也是全新的字面量类型。
const声明属于不可变的值。
因此,推断常量a的类型时不进行字面量类型放宽操作,常量a的推断类型与初始值类型相同,即全新的可放宽的数字字面量类型0。
此例第5行,常量a的类型为全新的可放宽的数字字面量类型0,并且let声明属于可变的值。
因此,推断变量b的类型时将进行字面量类型放宽操作,变量b的推断类型为放宽的全新的可放宽数字字面量类型0,即number类型。
const c: 0 = 0;
// ~
// 类型为:0
let d = c;
// ~
// 推断的类型为:0
此例第1行,虽然常量c的初始值类型为全新的可放宽的数字字面量类型0,但是常量c使用了类型注解明确指定了数字字面量类型0,因此,常量c的类型为不可放宽的数字字面量类型0,同时它也是非全新的字面量类型。
此例第5行,虽然let声明属于可变位置,但是常量c的类型为非全新的字面量类型,因此,推断变量d的类型时不进行字面量类型放宽操作,变量d的推断类型与常量c的类型相同,均为非全新的不可放宽的数字字面量类型0。
如果在代码中可变的位置上使用了“as const”断言,那么可变位置将变成不可变位置,同时也不再进行字面量类型放宽操作。
let a = 0;
// ~
// 推断的类型为:number
let b = 0 as const;
// ~
// 推断的类型为:0
命名空间
在ECMAScript 2015之前,JavaScript语言没有内置的模块支持。
在JavaScript程序中,通常使用“命名空间”来组织并隔离代码以免产生命名冲突等问题。
最为流行的实现命名空间的方法是使用立即执行的函数表达式。
这是因为立即执行的函数表达式能够创建出一个新的作用域并且不会对外层作用域产生影响。
TypeScript利用了这个经典的命名空间实现方式并提供了声明命名空间的简便语法
命名空间声明
命名空间通过namespace关键字来声明,它相当于一种语法糖。
namespace Utils {
function isString(value: any) {
return typeof value === 'string';
}
}
这段TypeScript代码在编译后将生成如下JavaScript代码:
// output.js
"use strict";
var Utils;
(function (Utils) {
function isString(value) {
return typeof value === 'string';
}
})(Utils || (Utils = {}))
我们能够看到命名空间被转换成了立即执行的函数表达式。
在定义命名空间的名字时允许使用以点符号“.”分隔的名字,这与其他编程语言中的命名空间声明类似。
namespace System.Utils {
function isString(value: any) {
return typeof value === 'string';
}
}
此例中定义的命名空间相当于两个嵌套的命名空间声明,它等同于如下的代码
namespace System {
export namespace Utils {
function isString(value: any) {
return typeof value === 'string';
}
}
}
在命名空间内部可以使用绝大多数语言功能,如变量声明、函数声明、接口声明和命名空间声明等
导出命名空间内的声明
默认情况下,在命名空间内部的声明只允许在该命名空间内部使用,在命名空间之外访问命名空间内部的声明会产生错误。
如果想要让命名空间内部的某个声明在命名空间外部也能够使用,则需要使用导出声明语句明确地导出该声明。导出命名空间内的声明需要使用export关键字,示例如下
namespace Utils {
export function isString(value: any) {
return typeof value === 'string';
}
// 正确
isString('yes');
}
// 正确
Utils.isString('yes');
别名导入声明
我们可以使用import语句为命名空间的导出声明起一个别名。当命名空间名字比较长时,使用别名能够有效地简化代码。
namespace Utils {
export function isString(value: any) {
return typeof value === 'string';
}
}
namespace App {
import isString = Utils.isString;
isString('yes');
Utils.isString('yes');
}
别名导入本质上“相当于”新声明了一个变量并将导出声明赋值给该变量。
需要注意的是,别名导入只是相当于新声明了一个变量而已,实际上不完全是这样的,因为别名导入对类型也有效。
在多文件中使用命名空间
在实际工程中,代码不可能都放在同一个文件中,一定会拆分到不同的源代码文件。
我们也可以将同一个命名空间声明拆分到不同的文件中,TypeScript最终会将同名的命名空间声明合并在一起。
“a.ts”文件的内容如下:
namespace Utils {
export function isString(value: any) {
return typeof value === 'string';
}
export interface Point {
x: number;
y: number;
}
}
“b.ts”文件的内容如下:
namespace Utils {
export function isNumber(value: any) {
return typeof value === 'number';
}
}
最终,合并后的Utils命名空间中存在三个导出声明isString、isNumber和Point。
文件间的依赖
当我们将命名空间拆分到不同的文件后,需要注意文件的加载顺序,因为文件之间可能存在依赖关系。
// a.ts”文件的内容如下
namespace App {
export function isString(value: any) {
return typeof value === 'string';
}
}
// “b.ts”文件的内容如下
namespace App {
const a = isString('foo');
}
这两个文件中,“b.ts”依赖于“a.ts”。因为“b.ts”中调用了“a.ts”中定义的方法。
我们需要保证“a.ts”先于“b.ts”被加载,否则在执行“b.ts”中的代码时将产生isString未定义的错误。
定义文件间的依赖关系有多种方式,本节将介绍以下两种
- 使用tsconfig.json文件
- 使用三斜线指令
tsconfig.json
通过“tsconfig.json”配置文件能够定义文件间的加载顺序。
例如,通过如下的配置文件能够定义“a.ts”先于“b.ts”被加载,这里我们主要配置了outFile和files两个选项。
{
"compilerOptions": {
"strict": true,
"target": "ESNext",
"outFile": "main.js"
},
"files": ["a.ts", "b.ts"]
}
首先,outFile选项指定了编译后输出的文件名。在指定了该选项后,编译后的“a.ts”和“b.ts”文件将被合并成一个“main.js”文件。
其次,files选项指定了工程中包含的所有源文件。files文件列表是有序列表,我们正是通过它来保证“a.ts”先于“b.ts”被加载。
三斜线指令
三斜线指令是TypeScript早期版本中就支持的一个特性,我们可以通过它来定义文件间的依赖。
三斜线指令的形式如下所示
/// <reference path="a.ts" />
此例中的三斜线指令声明了对“a.ts”文件的依赖。
我们可以在“b.ts”中使用三斜线指令来声明对“a.ts”文件的依赖。
// “a.ts”文件的内容如下:
namespace App {
export function isString(value: any) {
return typeof value === 'string';
}
}
// “b.ts”文件的内容如下:
/// <reference path="a.ts" />
namespace App {
const a = isString('foo');
}
在使用了三斜线指令后,编译器能够识别出“b.ts”依赖于“a.ts”。
在编译“b.ts”之前,编译器会确保先编译“a.ts”。
就算在tsconfig.json配置文件的files选项中将“b.ts”放在了“a.ts”之前,编译器也能够识别出正确的依赖顺序。
我们甚至都不需要在files选项中包含“a.ts”文件,只需要包含“b.ts”即可。
因为在编译“b.ts”时,编译器将保证依赖的文件会一同被编译。
小结
命名空间是一种历史悠久的实现代码封装和隔离的方式。在JavaScript语言还没有支持模块时,命名空间极为流行。在TypeScript语言的源码中也大量地使用了命名空间。
随着近些年JavaScript模块系统的演进以及原生模块功能的推出,命名空间的使用场景将变得越来越有限并有可能退出历史舞台。
在新的工程中或面向未来的代码中,推荐优先选择模块来代替命名空间。
模块
模块化编程是一种软件设计方法,它强调将程序按照功能划分为独立可交互的模块。
一个模块是一段可重用的代码,它将功能的实现细节封装在模块内部。模块也是一种组织代码的方式。一个模块可以声明对其他模块的依赖,且模块之间只能通过模块的公共API进行交互。
在新的工程或代码中,应该优先使用模块来组织代码,因为模块提供了更好的封装性和可重用性。
模块简史
自1996年JavaScript诞生到2015年ECMAScript 2015发布,在将近20年的时间里JavaScript语言始终缺少原生的模块功能。在这20年间,社区的开发者们设计了多种模块系统来帮助进行JavaScript模块化编程。其中较为知名的模块系统有以下几种:
- CommonJS模块
- AMD模块
- UMD模块
CommonJS
CommonJS是一个主要用于服务器端JavaScript程序的模块系统。
CommonJS使用require语句来声明对其他模块的依赖,同时使用exports语句来导出当前模块内的声明。CommonJS的典型应用场景是在Node.js程序中。
在Node.js中,每一个文件都会被视为一个模块。
AMD
CommonJS模块系统在服务器端JavaScript程序中取得了成功,但无法给浏览器端JavaScript程序带来帮助。
主要原因有以下两点:
- 浏览器环境中的JavaScript引擎不支持CommonJS模块,因此无法直接运行使用了CommonJS模块的代码。
- CommonJS模块采用同步的方式加载模块文件,这种加载方式不适用于浏览器环境。因为在浏览器中同步地加载模块文件会阻塞用户操作,从而带来不好的用户体验。
基于以上原因,CommonJS的设计者又进一步设计了适用于浏览器环境的AMD模块系统。AMD是“Asynchronous Module Definition”的缩写,表示异步模块定义。AMD模块系统不是将一个文件作为一个模
块,而是使用特殊的define函数来注册一个模块。因此,在一个文件中允许同时定义多个模块。AMD模块系统中也提供了require函数用来声明对其他模块的依赖,同时还提供了exports语句用来导出当前模块内的声明。
UMD
虽然CommonJS模块和AMD模块有着紧密的内在联系和相似的定义方式,但是两者不能互换使用。CommonJS模块不能在浏览器中使用,AMD模块也不能在Node.js中使用。如果一个功能模块既要在浏览器中使用也要在Node.js环境中使用,就需要分别使用CommonJS模块和AMD模块的格式编写两次。
UMD模块的出现解决了这个问题。UMD是“Universal ModuleDefinition”的缩写,表示通用模块定义。一个UMD模块既可以在浏览器中使用,也可以在Node.js中使用。UMD模块是基于AMD模块的定义,并且针对CommonJS模块定义进行了适配。因此,编写UMD模块会稍显复杂。
ESM
在经过了将近10年的标准化设计后,JavaScript语言的官方模块标准终于确定并随着ECMAScript 2015一同发布。它就是ECMAScript模块,简称为ES模块或ESM。
ECMAScript模块是正式的语言内置模块标准,而前面介绍的CommonJS、AMD等都属于非官方模块标准。在未来,标准的ECMAScript模块将能够在任何JavaScript运行环境中使用,例如浏览器环境和服务器端环境等。实际上,在最新版本的Chrome、Firefox等浏览器上以及Node.js环境中已经能够支持ECMAScript模块。ECMAScript模块使用import和export等关键字来定义。
ECMAScript模块
ECMAScript模块是JavaScript语言的标准模块,因此TypeScript也支持ECMAScript模块。
每个模块都拥有独立的模块作用域,模块中的代码在其独立的作用域内运行,而不会影响模块外的作用域(有副作用的模块除外,后文将详细介绍)。
模块通过import语句来声明对其他模块的依赖;同时,通过export语句将模块内的声明公开给其他模块使用。
模块不是使用类似于module的某个关键字来定义,而是以文件为单位。
一个模块对应一个文件,同时一个文件也只能表示一个模块,两者是一对一的关系。
若一个TypeScript文件中带有顶层的import或export语句,那么该文件就是一个模块,术语为“Module”。
若一个TypeScript文件中既不包含import语句,也不包含export语句,那么该文件称作脚本,术语为“Script”。
脚本中的代码全部是全局代码,它直接存在于全局作用域中。
因此,模块中的代码能够访问脚本中的代码,因为在模块作用域中能够访问外层的全局作用域。
模块导出
默认情况下,在模块内部的声明不允许在模块外部访问。若想将模块内部的声明开放给模块外部访问,则需要使用模块导出语句将模块内的声明导出。
模块导出语句包含以下两类:
- 命名模块导出。
- 默认模块导出。
命名模块导出
命名模块导出使用自定义的标识符名来区分导出声明。
在一个模块中,可以同时存在多个命名模块导出。
在常规的声明语句中添加export关键字,即可定义命名模块导出。
// 导出变量声明示例如下
export var a = 0;
export let b = 0;
export const c = 0;
// 导出函数声明示例如下
export function f() {}
// 导出类声明示例如下
export class C {}
// 导出接口声明示例如下
export interface I {}
// 导出类型别名示例如下
export type Numeric = number | bigint;
命名模块导出列表
进行命名模块导出时,一次只能导出一个声明,而命名模块导出列表能够一次性导出多个声明。
命名模块导出列表使用export关键字和一对大括号将所有导出的声明名称包含在内。
在一个模块中,可以同时存在多个命名模块导出列表语句。
命名模块导出语句和命名模块导出列表语句也可以同时使用。
const a = 0;
const b = 0;
export { a, b };
function f0() {}
function f1() {}
export { f0, f1 };
默认模块导出
为了与现有的CommonJS模块和AMD模块兼容,ECMAScript模块提供了默认模块导出的功能。
对于一个CommonJS模块或AMD模块来讲,模块中的exports对象就相当于默认模块导出。
默认模块导出是一种特殊形式的模块导出,它等同于名字为“default”的命名模块导出。
因此,一个模块中只允许存在一个默认模块导出。默认模块导出使用“export default”关键字来定义。
// 默认导出函数声明示例如下
export default function f() {}
// 默认导出类声明示例如下
export default class C {}
因为默认模块导出不依赖于声明的名字而是统一使用“default”作为导出名,因此默认模块导出可以导出匿名的函数和类等。
// 默认导出匿名函数示例如下
export default function() {}
// 默认导出匿名类示例如下:
export default class {}
// 默认导出任意表达式的值示例如下:
export default 0;
由于默认模块导出相当于名为“default”的命名模块导出,因此,默认模块导出也可以写为如下形式
function f() {}
export { f as default };
此例中,as关键字的作用是重命名模块导出,它将f重命名为default。
我们将在后文中详细介绍模块导出的重命名。此例中的命名模块导出列表等同于如下的默认模块导出语句:
export default function f() {}
聚合模块
聚合模块是指将其他模块的模块导出作为当前模块的模块导出。
聚合模块使用“export ... from ...”语法并包含以下形式:
- 从模块mod中选择部分模块导出作为当前模块的模块导出(1)。
- 从模块mod中选择默认模块导出作为当前模块的默认模块导出。默认模块导出相当于名为“default”的命名模块导出(2)。
- 从模块mod中选择某个非默认模块导出作为当前模块的默认模块导出。默认模块导出相当于名为“default”的命名模块导出(3)。
- 从模块mod中选择所有非默认模块导出作为当前模块的模块导出(4)。
- 从模块mod中选择所有非默认模块导出,并以ns为名作为当前模块的模块导出(5)。
// 1
export { a, b, c } from 'mod';
// 2
export { default } from 'mod';
// 3
export { a as default } from 'mod';
// 4
export * from 'mod';
// 5
export * as ns from "mod";
需要注意的是,在聚合模块时不会引入任何本地声明。
例如,下例从模块mod中重新导出了声明a,但是在当前模块中是不允许使用声明a的,因为没有导入声明a。
export { a } from 'mod';
console.log(a);
// ~
// 编译错误!找不到名字 "a"
模块导入
如果想要使用一个模块的导出声明,则需要使用import语句来导入它。
导入命名模块导出
对于一个模块的命名模块导出,可以通过其导出的名称来导入它,具体语法如下所示
import { a, b, c } from 'mod';
在该语法中,import关键字后面的大括号中列出了mod模块中的命名模块导出;from关键字的后面是模块名,模块名不包含文件扩展名,如“.ts”
导入整个模块
我们可以将整个模块一次性地导入,语法如下所示:
import * as ns from 'mod';
在该语法中,from后面是要导入的模块名,它将模块mod中的所有命名模块导出导入到对象ns中。
导入默认模块导出
导入默认模块导出需要使用如下语法:
import modDefault from 'mod';
在该语法中,modDefault可以为任意标识符名,表示导入的默认模块导出在当前模块中所绑定的标识符。
在当前模块中,将使用modDefault这个名字来访问mod模块中的默认模块导出。
空导入
空导入语句不会导入任何模块导出,它只是执行模块内的代码。
空导入的用途是“导入”模块的副作用。
在计算机科学中,“副作用”指的是某个操作会对外部环境产生影响。
例如,有一个获取时间的函数,如果该函数除了会返回当前时间,同时还会修改操作系统的时间设置,那么我们可以说该函数具有副作用。
对于模块来讲,模块有其独立的模块作用域,但是在模块作用域中也能够访问并修改全局作用域中的声明。
有些模块从设计上就是用来与全局作用域进行交互的,如监听全局事件或设置某个全局变量等。
除此之外,应尽量保持模块与外部环境的隔离,将模块的实现封闭在模块内部,并通过导入和导出语句与模块外部进行交互。
空导入的语法如下所示:
import 'mod';
重命名模块导入和导出
为了解决模块导入和导出的命名冲突问题,ECMAScript模块允许重命名模块的导入和导出声明。
重命名模块导入和导出通过as关键字来定义。
重命名模块导出
重命名模块导出的语法如下所示
export { oldName as newName };
在该语法中,将导出模块内的oldName声明,并将其重命名为newName。
在其他模块中需要使用newName这个名字来访问该模块中的oldName声明。
重命名聚合模块
重命名聚合模块的语法如下所示:
export { oldName as newName } from "mod";
在该语法中,将导出mod模块内的oldName声明,并将其重命名为newName。
重命名模块导入
重命名模块导入的语法如下所示:
import { oldName as newName } from "mod";
在该语法中,将导入mod模块内的oldName声明,并重命名为newName。
在当前模块中需要使用newName这个名字来访问mod模块中的oldName声明。
针对类型的模块导入与导出
我们知道类和枚举既能表示一个值也能表示一种类型。
在使用import和export语句来导入和导出类和枚举时,会同时导入和导出它们所表示的值和类型。
因此,在代码中我们可以将导入的类和枚举同时用作值和类型。
在TypeScript 3.8版本中,引入了只针对类型的导入导出语句。
当在类和枚举上使用针对类型的导入导出语句时,只会导入和导出类和枚举所表示的类型,而不会导入和导出它们表示的值。
延伸来看,在变量声明、函数声明上使用针对类型的导入导出语句时只会导入导出变量类型和函数类型,而不会导入导出变量的值和函数值。
背景介绍
TypeScript为JavaScript添加了额外的静态类型,与类型相关的代码在编译生成JavaScript代码时会被完全删除,因为JavaScript本身并不支持静态类型。
例如,我们在Type-Script程序中定义了一个接口,那么该接口声明在编译生成JavaScript时会被直接删除。
该规则同样适用于模块导入导出语句。
在默认情况下,如果模块的导入导出语句满足如下条件,那么在编译生成JavaScript时编译器会删除相应的导入导出语句,具体的条件如下:
- 模块导入或导出的标识符仅被用在类型的位置上。
- 模块导入或导出的标识符没有被用在表达式的位置上,即没有作为一个值使用。
虽然在大部分情况下,编译器删除针对类型的导入导出语句不会影响生成的JavaScript代码,但有时候也会给开发者带来困扰。
一个典型的例子是使用了带有副作用的模块。
如果一个模块只从带有副作用的模块中导入了类型,那么这条导入语句将会被编译器删除。
因此,带有副作用的模块代码将不会被执行,这有可能不是期望的行为
// utils.ts”文件的内容如下
globalThis.mode = 'dev';
export interface Point {
x: number;
y: number;
}
// “index.ts”文件的内容如下
import { Point } from './utils';
const p: Point = { x: 0, y: 0 };
if (globalThis.mode === 'dev') {
console.log(p);
}
由于在“index.ts”文件中只导入了“utils.ts”模块中的接口类型,因此在编译生成的JavaScript文件中会删除导入“utils.ts”模块的语句,而事实上,此例中的“index.ts”模块依赖于“utils.ts”模块中的副作用,即设置全局的mode属性。
在TypeScript 3.8版本中,引入了只针对类型的模块导入导出语句以及“--importsNot-UsedAsValues”编译选项来帮助缓解上述问题。
导入与导出类型
总的来说,针对类型的模块导入导出语法是在前面介绍的模块导入导出语法中添加type关键字。
从模块中导出类型使用“export type”关键字,具体语法如下所示:
export type { Type }
export type { Type } from 'mod';
该语法中,Type表示类型名。
从模块中导入默认模块导出类型的语法如下所示:
import type DefaultType from 'mod';
该语法中,DefaultType可以为任意的标识符名,表示导入的默认模块导出类型在当前模块中所绑定的标识符。
在当前模块中,将使用DefaultType这个名字来访问mod模块中的默认模块导出类型。
从模块中导入命名类型的语法如下所示:
import type { Type } from 'mod';
从模块中导入所有导出的命名类型的语法如下所示:
import type * as TypeNS from 'mod';
该语法中,TypeNS可以为任意标识符名,它将mod模块中的所有命名模块导出类型放在命名空间TypeNS下。
--importsNotUsedAsValues
针对类型的模块导入与导出的一个重要性质是,在编译生成JavaScript代码时,编译器一定会删除“import type”和“export type”语句,因为能够完全确定它们只与类型相关。
对于常规的import语句,编译器提供了“--importsNotUsedAsValues”编译选项来精确控制在编译时如何处理它们。
该编译选项接受以下三个可能的值:
- "remove"(默认值)。该选项是编译器的默认行为,它自动删除只和类型相关的import语句。
- "preserve"。该选项会保留所有import语句。
- "error"。该选项会保留所有import语句,发现可以改写为“import type”的import语句时会报错。
动态模块导入
动态模块导入允许在一定条件下按需加载模块,而不是在模块文件的起始位置一次性导入所有依赖的模块。
因此,动态模块导入可能会提升一定的性能。动态模块导入通过调用特殊的“import()”函数来实现。该函数接受一个模块路径作为参数,并返回Promise对象。如果能够成功加载模块,那么Promise对象的完成值为模块对象。
动态模块导入语句不必出现在模块的顶层代码中,它可以被用在任意位置,甚至可以在非模块中使用。
--module
TypeScript编译器提供了“--module”编译选项来设置编译生成的JavaScript代码使用的模块格式。
在TypeScript程序中,推荐使用标准的ECMAScript模块语法来进行编码,然后通过编译器来生成其他模块格式的代码。
该编译选项的可选值如下:
- None(非模块代码)
- CommonJS
- AMD
- System
- UMD
- ES6
- ES2015
- ES2020
- ESNext
外部声明
TypeScript语言主要有两种类型的源文件:
- 文件扩展名为“.ts”或“.tsx”的文件。
- 文件扩展名为“.d.ts”的文件。
“.ts”或“.tsx”文件中包含了应用的实现代码,它也是开发者日常编写的代码。
“.ts”和“.tsx”文件中既可以包含类型声明又可以包含可执行代码。
在编译TypeScript程序的过程中,“.ts”和“.tsx”文件会生成对应的“.js”和“.jsx”文件。
值得一提的是,“.tsx”文件中包含了使用JSX语法编写的代码。JSX采用了类似于XML的语法,JSX因知名的React框架而流行,因为React框架推荐使用JSX来编写应用程序。
“.d.ts”文件是类型声明文件,其中字母“d”表示“declaration”,即声明的意思。
“.d.ts”文件只提供类型声明,不提供任何值,如字符串和函数实现等。
因此,在编译TypeScript程序的过程中,“.d.ts”文件不会生成对应的“.js”文件
我们可以将“.d.ts”文件称作外部声明文件或简称为声明文件。
声明文件中的内容是外部声明。外部声明用于为已有代码提供静态类型信息以供TypeScript编译器使用。
例如,知名代码库jQuery的外部声明文件提供了jQuery API的类型信息。
TypeScript编译器能够利用该类型信息进行代码静态类型检查以及代码自动补全等操作。
外部声明是TypeScript语言规范中使用的术语。我们不必纠结于如何划分外部和内部,它是一个相对概念。
外部声明也可以出现在“.ts”文件中,我们只需明确外部声明是类型声明而不是具体实现,外部声明在编译后不会输出任何可执行代码即可。
外部声明包含以下两类:
- 外部类型声明。
- 外部模块声明。
外部类型声明
外部类型声明通过declare关键字来定义,包含外部变量声明、外部函数声明、外部类声明、外部枚举声明和外部命名空间声明。
外部变量声明
外部变量声明定义了一个变量类型
外部变量声明不允许定义初始值,因为它只表示一种类型,而不能够表示一个值。
如果外部变量声明中没有使用类型注解,那么变量的类型为any类型。
declare var a: boolean;
declare let b: boolean;
declare const c: boolean;
// “typings.d.ts”文件的内容如下:
declare var Infinity: number;
// “index.ts”文件的内容如下
const x = 10 ** 10000;
if (x === Infinity) {
console.log('Infinity');
}
编译器能够从“typings.d.ts”文件中获取Infinity变量的类型。实际上,Infinity是JavaScript语言内置的一个全局属
性,它表示一个无穷大的数值。
外部函数声明
外部函数声明定义了一个函数类型
外部函数声明使用“declare function”关键字来定义。
外部函数声明中不允许带有函数实现,只能定义函数类型。
declare function f(a: string, b: boolean): void;
// “typings.d.ts”文件的内容如下:
declare function alert(message?: any): void;
// “index.ts”文件的内容如下:
alert('Hello, World!');
此例中,编译器能够从“typings.d.ts”文件中获取alert函数的类型。
外部类声明
外部类声明定义了一个类类型
外部类声明使用“declare class”关键字来定义。
外部类声明中的成员不允许带有具体实现,只允许定义类型。
例如,类的方法和构造函数不允许带有具体实现,类的属性声明不允许定义初始值等。
declare class C {
// 静态成员声明
public static s0(): string;
private static s1: string;
// 属性声明
public a: number;
private b: number;
// 构造函数声明
constructor(arg: number);
// 方法声明
m(x: number, y: number): number;
// 存取器声明
get c(): number;
set c(value: number);
// 索引签名声明
[index: string]: any;
}
外部枚举声明
外部枚举声明定义了一个枚举类型。
外部枚举声明与常规的枚举声明的语法是相同的
declare enum Foo {
A,
B,
}
declare enum Bar {
A = 0,
B = 1,
}
declare const enum Baz {
A,
B,
}
declare const enum Qux {
A = 0,
B = 1,
}
外部枚举声明与常规枚举声明主要有以下两点不同:
- 在外部枚举声明中,枚举成员的值必须为常量枚举表达式,例如数字字面量、字符串字面量或简单算术运算等。
- 在使用了“declare enum”的外部枚举中,若枚举成员省略了初始值,则会被视为计算枚举成员,因此不会被赋予一个自增长的初始值,如0、1和2等
// “typings.d.ts”文件的内容如下:
declare enum Direction {
Up,
Down,
Left,
Right,
}
// “index.ts”文件的内容如下:
let direction: Direction = Direction.Up;
此例中,编译器能够从“typings.d.ts”文件中获取Direction枚举的类型。
注意,若想要实际运行此例中的代码,我们还需要给出Direction枚举的具体定义。“typings.d.ts”中只声明了Direction枚举的类型,而没有提供具体定义。
外部命名空间声明
外部命名空间声明定义了一个命名空间类型
declare namespace Foo {
// 外部变量声明
var a: boolean;
let b: boolean;
const c: boolean;
// 外部函数声明
function foo(bar: string, baz: boolean): void;
// 外部类声明
class C {
x: number;
constructor(x: number);
y(): void;
}
// 接口声明
interface I {
x: number;
y: number;
}
// 外部枚举声明
enum E {
A,
B,
}
// 嵌套的外部命名空间声明
namespace Inner {
var a: boolean;
}
}
外部命名空间的成员默认为导出成员,不需要使用export关键字来明确地导出它们,但使用了export关键字也没有错误。
外部模块声明
外部模块声明定义了一个模块类型。
外部模块声明只能在文件的顶层定义,并且存在于全局命名空间当中。
declare module 'io' {
export function readFile(filename: string):string;
}
在该语法中,“declare module”是关键字,它后面跟着一个表示模块名的字符串,模块名中不能使用路径。
使用声明文件
TypeScript中的“.d.ts”声明文件主要有以下几种来源:
- TypeScript语言内置的声明文件。
- 安装的第三方声明文件。
- 自定义的声明文件。
语言内置的声明文件
当我们在计算机中安装了TypeScript语言后,同时也安装了一些语言内置的声明文件,它们位于TypeScript语言安装目录下的lib文件夹中。
TypeScript语言内置的声明文件统一使用“lib.[description].d.ts”命名方式,其中,description部分描述了该声明文件的内容。
在这些声明文件中,既定义了标准的JavaScriptAPI,如Array API、Math API以及Date API等,也定义了特定于某种JavaScript运行环境的API,如DOM API和Web Workers API等。
TypeScript编译器在编译代码时能够自动加载内置的声明文件。
因此,我们可以在代码中直接使用那些标准API,而不需要进行特殊的配置。
第三方声明文件
如果我们的工程中使用了某个第三方代码库,例如jQuery,通常我们也想要安装该代码库的声明文件。
这样,TypeScript编译器就能够对代码进行类型检查,同时代码编辑器也能够根据声明文件中的类型信息来提供代码自动补全等功能。
在尝试安装某个第三方代码库的声明文件时,可能会遇到以下三种情况,
下面以jQuery为例:
- 在安装jQuery时,jQuery的代码包中已经内置了它的声明文件。
- 在安装jQuery时,jQuery的代码包中没有内置的声明文件,但是在DefinitelyTyped网站上能够找到jQuery的声明文件。
- 通过以上方式均找不到jQuery的声明文件,需要自定义jQuery的声明文件。
含有内置声明文件
通常来讲,若代码库的安装目录中包含“.d.ts”文件,则说明该代码库提供了内置的声明文件。
DefinitelyTyped
DefinitelyTyped(https://definitelytyped.org/)是一个公开的集中式的TypeScript声明文件代码仓库,该仓库中包含了数千个代码库的声明文件。
如果我们正在使用的第三方代码库没有内置的声明文件,那么可以尝试在DefinitelyTyped仓库中搜索声明文件。
npm install @types/jquery
安装jQuery的声明文件,即“@types/jquery”代码包。
typings与types
每个npm包都有一个标准的“package.json”文件,该文件描述了当前npm包的基础信息。
该文件中比较重要的属性有表示包名的name属性、表示版本号的version属性和表示入口脚本的main属性等。
TypeScript扩展了“package.json”文件,增加了typings属性和types属性。
虽然两者的名字不同,但是作用相同,它们都用于指定当前npm包提供的声明文件。
{
"name": "my-package",
"version": "1.0.0",
"main": "index.js",
"typings": "index.d.ts"
}
此例中,使用typings属性定义了“my-package”包的声明文件为“index.d.ts”文件。
当TypeScript编译器进行模块解析时,将会读取该属性的值并使用指定的“index.d.ts”文件作为声明文件。
这里我们也可以将typings属性替换为types属性,两者是等效的。
如果一个npm包的声明文件为“index.d.ts”且位于npm包的根目录下,那么在“package.json”文件中也可以省略typings属性和types属性,因为编译器在进行模块解析时,若在“package.json”文件中没有找到typings属性和types属性,则将默认使用名为“index.d.ts”的文件作为声明文件。
typesVersions
每个声明文件都有其兼容的TypeScript语言版本。
例如,如果一个声明文件中使用了TypeScript 3.0才开始支持的unknown类型,那么在使用该声明文件时,需要安装Type-Script 3.0或以上的版本。
也就是说,将该声明文件提供给其他用户使用时,需要使用者安装TypeScript3.0或以上的版本,这可能会给使用者带来困扰。
在TypeScript 3.1版本中,编译器能够根据当前安装的TypeScript版本来决定使用的声明文件,该功能是通过“package.json”文件中的typesVersions属性来实现的。
“package.json”文件的内容如下:
{
"name": "my-package",
"version": "1.0.0",
"main": "index.js",
"typings": "index.d.ts",
"typesVersions": {
">=3.7": {
"*": ["ts3.7/*"]
},
">=3.1": {
"*": ["ts3.1/*"]
}
}
}
此例中,我们定义了两个声明文件匹配规则:
- 第7行,当安装了TypeScript 3.7及以上版本时,将使用“ts3.7”目录下的声明文件
- 第10行,当安装了TypeScript 3.1及以上版本时,将使用“ts3.1”目录下的声明文件。
需要注意的是,typesVersions中的声明顺序很关键,编译器将从第一个声明(此例中为">=3.7")开始尝试匹配,若匹配成功,则应用匹配到的值并退出。
因此,若将此例中的两个声明调换位置,则会产生不同的结果。
此外,如果typesVersions中不存在匹配的版本,如当前安装的是TypeScript 2.0版本,那么编译器将使用typings属性和types属性中定义的声明文件。
自定义声明文件
如果使用的第三方代码库没有提供内置的声明文件,而且在DefinitelyTyped仓库中也没有对应的声明文件,那么就需要开发者自己编写一个声明文件。
但如果我们不想编写一个详尽的声明文件,而只是想要跳过对某个第三方代码库的类型检查,则可以使用下面介绍的方法。
// 我们还是以jQuery为例,自定义一个jQuery声明文件,让编译器不对jQuery进行类型检查。
// “jquery.d.ts”声明文件的内容如下
declare module 'jquery';
此例中的代码是外部模块声明,该声明会将jquery模块的类型设置为any类型。
jquery模块中所有成员的类型都成了any类型,这等同于不对jQuery进行类型检查。
模块解析
当在程序中导入了一个模块时,编译器会去查找并读取导入模块的定义,我们将该过程叫作模块解析。
模块解析的过程受以下因素影响:
- 相对模块导入与非相对模块导入。
- 模块解析策略。
- 模块解析编译选项。
本节将先介绍如何判断相对模块导入与非相对模块导入,然后介绍TypeScript中的两种模块解析策略是如何解析相对模块导入和非相对模块导入的,最后还会介绍一些与模块解析相关的编译选项,这些编译选项能够配置模块解析的具体行为。
相对模块导入
在模块导入语句中,若模块名以下列符号开始,那么它就是相对模块导入。
- /
- ./
- ../
“/”表示系统根目录
“./”表示当前目录
“../”表示上一级目录
在解析相对模块导入语句中的模块名时,将参照当前模块文件所在的目录位置。
非相对模块导入
在模块导入语句中,若模块名不是以“/”、“./”和“../”符号开始,那么它就是非相对模块导入。
模块解析策略
TypeScript提供了两种模块解析策略,分别是:
- Classic策略。
- Node策略。
模块解析策略可以使用“--moduleResolution”编译选项来指定
tsc --moduleResolution Classic
模块解析策略也可以在“tsconfig.json”配置文件中使用moduleResolution属性来设置
{
"compilerOptions": {
"moduleResolution": "Node"
}
}
当没有设置模块的解析策略时,默认的模块解析策略与“--module”编译选项的值有关。
“--module”编译选项用来设置编译生成的JavaScript代码使用的模块格式。
若“--module”编译选项的值不为CommonJS,则默认的模块解析策略为Classic。
模块解析策略之Classic
Classic模块解析策略是TypeScript最早提供的模块解析策略,它尝试将模块名视为一个文件进行解析。
解析相对模块导入
在Classic模块解析策略下,相对模块导入的解析过程包含以下两个阶段:
- 将导入的模块名视为文件,并在指定目录中查找TypeScript文件
- 将导入的模块名视为文件,并在指定目录中查找JavaScript文件
解析非相对模块导入
在Classic模块解析策略下,非相对模块导入的解析过程包含以下三个阶段:
- 将导入的模块名视为文件,从当前目录开始向上遍历至系统根目录,并查找TypeScript文件。
- 将导入的模块名视为安装的声明文件,从当前目录开始向上遍历至系统根目录,并在每一级目录下的“node_modules/@types”文件夹中查找安装的声明文件。
- 将导入的模块名视为文件,从当前目录开始向上遍历至系统根目录,并查找JavaScript文件。
在Classic模块解析策略下,非相对模块导入的解析与相对模块导入的解析相比较有以下几点不同:
- 解析相对模块导入时只会查找指定的一个目录;解析非相对模块导入时会向上遍历整个目录树。
- 解析非相对模块导入比解析相对模块导入多了一步,即在每一层目录的“node_modules/@types”文件夹中查找是否安装了要导入的声明文件。
在查找模块文件的过程中,一旦找到匹配的文件,就会停止搜索。
模块解析策略之Node
Node模块解析策略是TypeScript 1.6版本中引入的,它因模仿了Node.js的模块解析策略而得名。
在实际工程中,我们可能更想要使用Node模块解析策略,因为它的功能更加丰富。
解析相对模块导入
在Node模块解析策略下,相对模块导入的解析过程包含以下几个阶段:
- 将导入的模块名视为文件,并在指定目录中查找TypeScript文件
- 将导入的模块名视为目录,并在该目录中查找“package.json”文件,然后解析“package.json”文件中的typings属性和types属性。
- 将导入的模块名视为文件,并在指定目录中查找JavaScript文件
- 将导入的模块名视为目录,并在该目录中查找“package.json”文件,然后解析“package.json”文件中的main属性
解析非相对模块导入
在Node模块解析策略下,非相对模块导入的解析过程包含以下几个阶段:
- 将导入的模块名视为文件,并在当前目录下的“node_modules”文件夹中查找TypeScript文件。
- 将导入的模块名视为目录,并在当前目录下的“node_modules”文件夹中查找给定目录下的“package.json”文件,然后解析“package.json”文件中的typings属性和types属性。
- 将导入的模块名视为安装的声明文件,并在当前目录下的“node_modules/@types”文件夹中查找安装的声明文件。
- 重复第1~3步的查找过程,从当前目录开始向上遍历至系统根目录。
- 将导入的模块名视为文件,并在当前目录下的“node_modules”文件夹中查找JavaScript文件。
- 将导入的模块名视为目录,并在当前目录下的“node_modules”文件夹中查找给定目录下的“package.json”文件,然后解析“package.json”文件中的main属性。
- 重复第5~6步的查找过程,从当前目录开始向上遍历至系统根目录。
--baseUrl
“--baseUrl”编译选项用来设置非相对模块导入的基准路径。
在解析相对模块导入时,将不受“--baseUrl”编译选项值的影响。
设置--baseUrl
该编译选项既可以在命令行上指定,也可以在“tsconfig.json”配置文件中进行设置。
在命令行上使用“--baseUrl”编译选项,示例如下:
tsc --baseUrl ./
此例中,将“--baseUrl”编译选项的值设置为当前目录“./”,参照的是执行tsc命令时所在的目录。
在“tsconfig.json”配置文件中使用baseUrl属性来设置“--baseUrl”编译选项,示例如下:
{
"compilerOptions": {
"baseUrl": "./"
}
}
此例中,将baseUrl设置为当前目录“./”,参照的是“tsconfig.json”配置文件所在的目录。
解析--baseUrl
当设置了“--baseUrl”编译选项时,非相对模块导入的解析过程包含以下几个阶段:
- 根据“--baseUrl”的值和导入的模块名,计算出导入模块的路径。
- 将导入的模块名视为文件,并查找TypeScript文件。
- 将导入的模块名视为目录,在该目录中查找“package.json”文件,然后解析“package.json”文件中的typings属性和types属性
- 将导入的模块名视为目录,在该目录中查找“package.json”文件,然后解析“package.json”文件中的main属性。
- 忽略“--baseUrl”的设置并回退到使用Classic模块解析策略或Node模块解析策略来解析模块。
当设置了“--baseUrl”编译选项时,相对模块导入的解析过程不受影响,将使用设置的Classic模块解析策略或Node模块解析策略来解析模块
paths
paths编译选项用来设置模块名和模块路径的映射,用于设置非相对模块导入的规则。
设置paths
paths编译选项只能在“tsconfig.json”配置文件中设置,不支持在命令行上使用。
由于paths是基于“--baseUrl”进行解析的,所以必须同时设置“--baseUrl”和paths编译选项。
有如下目录结构的工程:
C:\app
|-- bar
| `-- b.ts
|-- foo
| `-- a.ts
`-- tsconfig.json
“tsconfig.json”文件的内容如下:
{
"compilerOptions": {
"baseUrl": "./",
"paths": {
"b": ["bar/b"]
}
}
}
此例中的paths设置会将对模块b的非相对模块导入映射到“C:\app\bar\b”路径。
编译器在解析非相对模块导入b时,发现存在匹配的paths路径映射,因此会使用路径映射中的地址“C:\app\bar\b”作为模块路径去解析模块b。
使用通配符
在设置paths时,还可以使用通配符“*”,它能够匹配任意路径。
有如下目录结构的工程
C:\app
|-- bar
| `-- b.ts
|-- foo
| `-- a.ts
`-- tsconfig.json
“tsconfig.json”文件的内容如下
{
"compilerOptions": {
"baseUrl": "./",
"paths": {
"@bar/*": ["bar/*"]
}
}
}
此例中的paths设置会将对模块“@bar/...”的导入映射到“C:\app\bar...”路径下。两个星号通配符代表相同的路径。
// “a.ts”文件的内容如下:
import * as B from '@bar/b';
编译器在解析非相对模块导入“'@bar/b'”时,发现存在匹配的paths路径映射,因此会使用路径映射后的地址“C:\app\bar\b”作为模块路径去解析模块b。
rootDirs
rootDirs编译选项能够使用不同的目录创建出一个虚拟目录,在使用时就好像这些目录被合并成了一个目录一样。
在解析相对模块导入时,编译器会在rootDirs编译选项构建出来的虚拟目录中进行搜索。
rootDirs编译选项需要在“tsconfig.json”配置文件中设置,它的值是由路径构成的数组。
有如下目录结构的工程:
C:\app
|-- bar
| `-- b.ts
|-- foo
| `-- a.ts
`-- tsconfig.json
“tsconfig.json”文件的内容如下:
{
"compilerOptions": {
"rootDirs": ["bar", "foo"]
}
}
此例中的rootDirs创建了一个虚拟目录,它包含了“C:\app\bar”和“C:\app\foo”目录下的内容。
// “a.ts”文件的内容如下:
import * as B from './b';
编译器在解析相对模块导入“'./b'”时,将会同时查找“C:\app\bar”目录和“C:\app\foo”目录。
导入外部模块声明
在Classic模块解析策略和Node模块解析策略中,编译器都是在尝试查找一个与导入模块相匹配的文件。
但如果最终未能找到这样的模块文件并且导入语句是非相对模块导入,那么编译器将继续在外部模块声明中查找导入的模块。
有如下目录结构的工程
C:\app
|-- foo
| |---a.ts
| `-- typings.d.ts
`-- tsconfig.json
“typings.d.ts”文件的内容如下:
declare module 'mod' {
export function add(x: number, y: number): number;
}
在“a.ts”文件中,可以使用非相对模块导入语句来导入外部模块“mod”。
import * as Mod from 'mod';
Mod.add(1, 2);
注意,在“a.ts”文件中无法使用相对模块导入来导入外部模块“mod”,示例如下:
import * as M1 from './mod';
// ~~~~~~~
// 错误:无法找到模块'./mod'
import * as M2 from './typings';
// ~~~~~~~~~~~
// 错误:typings.d.ts不是一个模块
--traceResolution
在启用了“--traceResolution”编译选项后,编译器会打印出模块解析的具体步骤。
不论是在学习TypeScript语言的过程中还是在调试代码的过程中,都可以通过启用该选项来了解编译器解析模块时的具体行为。
随着TypeScript版本的更新,模块解析算法也许会有所变化,而“--traceResolution”的输出结果能够真实反映当前使用的TypeScript版本中的模块解析算法。
该编译选项可以在命令行上指定,也可以在“tsconfig.json”配置文件中设置。
声明合并
声明是编程语言中的基础结构,它描述了一个标识符所表示的含义。
在TypeScript语言中,一个标识符总共可以有以下三种含义:
- 表示一个值
- 表示一个类型
- 表示一个命名空间
对于同一个标识符而言,它可以同时具有上述多种含义。
例如,有一个标识符A,它可以同时表示一个值、一种类型和一个命名空间。
const A = 0;
interface A {}
namespace A {}
在同一声明空间内使用的标识符必须唯一。
TypeScript语言中的大部分语法结构都能够创建出新的声明空间,例如函数声明和类声明都能够创建出一个新的声明空间。最典型的声明空间是全局声明空间和模块声明空间。
当编译器发现同一声明空间内存在同名的声明时,会尝试将所有同名的声明合并为一个声明,即声明合并;若发现无法进行声明合并,则会产生编译错误。
声明合并是TypeScript语言特有的行为。在进行声明合并时,编译器会按照标识符的含义进行分组合并,即值和值合并、类型和类型合并以及命名空间和命名空间合并。
但是并非所有同名的声明都允许进行声明合并,例如,常量声明a和函数声明a之间不会进行声明合并。
接口声明合并
接口声明为标识符定义了类型含义。在同一声明空间内声明的多个同名接口会合并成一个接口声明。
若待合并的接口中存在同名的属性签名类型成员,那么这些同名的属性签名必须是相同的类型,否则会因为合并冲突而产生编译错误。
interface A {
a: number;
}
interface A {
a: string; // 编译错误
}
若待合并的接口中存在同名的方法签名类型成员,那么同名的方法签名类型成员会被视为函数重载,并且靠后定义的方法签名具有更高的优先级。
合并重载签名的基本原则是后声明的重载签名具有更高优先级。
但也存在一个例外,若重载签名的参数类型中包含字面量类型,则该重载签名具有更高的优先级。
若待合并的接口中存在多个调用签名类型成员或构造签名类型成员,那么它们将被视作函数重载和构造函数重载。
与合并方法签名类型成员相同,后声明的调用签名类型成员和构造签名类型成员具有更高的优先级,同时也会参考参数类型中是否包含字面量类型。
当涉及重载时,接口合并的顺序变得尤为重要,因为它将影响重载的解析顺序。
interface A {
f(x: any): void;
}
interface A {
f(x: string): boolean;
}
interface MergedA {
f(x: string): boolean;
f(x: any): void;
}
若待合并的接口中存在多个字符串索引签名或数值索引签名,则将产生编译错误。
在合并接口时,所有的接口中只允许存在一个字符串索引签名和一个数值索引签名。
若待合并的接口是泛型接口,那么所有同名接口必须有完全相同的类型参数列表。
若待合并的接口存在继承的接口,那么所有继承的接口会被合并为单一的父接口。
在实际程序中,我们应避免复杂接口的合并行为,因为这会让代码变得难以理解。
枚举声明合并
多个同名的枚举声明会合并成一个枚举声明。
在合并枚举声明时,只允许其中一个枚举声明的首个枚举成员省略初始值。
enum E {
A,
}
enum E {
B = 1,
}
enum E {
C = 2,
}
let e: E;
e = E.A;
e = E.B;
e = E.C;
此例中,第2行的首个枚举成员省略了初始值,因此TypeScript会自动计算初始值。
第6行和第10行,必须为首个枚举成员定义初始值,否则将产生编译错误,因为编译器无法在多个同名枚举声明之间自动地计算枚举值。
枚举声明合并的另外一点限制是,多个同名的枚举声明必须同时为const枚举或非const枚举,不允许混合使用。
类声明合并
TypeScript不支持合并同名的类声明,但是外部类声明可以与接口声明进行合并,合并后的类型为类类型。
declare class C {
x: string;
}
interface C {
y: number;
}
let c: C = new C();
c.x;
c.y
命名空间声明合并
命名空间的声明合并会稍微复杂一些,它可以与命名空间、函数、类和枚举进行合并。
命名空间与命名空间合并
与合并接口类似,同名的命名空间也会进行合并。
namespace Animals {
export class Bird {}
}
namespace Animals {
export interface CanFly {
canFly: boolean;
}
export class Dog {}
}
// 合并后等同于
namespace MergedAnimals {
export interface CanFly {
canFly: boolean;
}
export class Bird {}
export class Dog {}
}
如果存在嵌套的命名空间,那么在合并外层命名空间时,同名的内层命名空间也会进行合并。
namespace outer {
export namespace inner {
export var x = 10;
}
}
namespace outer {
export namespace inner {
export var y = 20;
}
}
namespace MergedOuter {
export namespace inner {
export var x = 10;
export var y = 20;
}
}
在合并命名空间声明时,命名空间中的非导出成员不会被合并,它们只能在各自的命名空间中使用。
namespace NS {
const a = 0;
export function foo() {
a; // 正确
}
}
namespace NS {
export function bar() {
foo(); // 正确
a; // 编译错误:找不到 'a'
}
}
命名空间与函数合并
同名的命名空间声明与函数声明可以进行合并,但是要求函数声明必须位于命名空间声明之前,这样做能够确保先创建出一个函数对象。
函数与命名空间合并就相当于给函数对象添加额外的属性。
function f() {
return f.version;
}
namespace f {
export const version = '1.0';
}
f(); // '1.0'
f.version; // '1.0'
命名空间与类合并
同名的命名空间声明与类声明可以进行合并,但是要求类声明必须位于命名空间声明之前,这样做能够确保先创建出一个构造函数对象。
命名空间与类的合并提供了一种创建内部类的方式。
class Outer {
inner: Outer.Inner = new Outer.Inner();
}
namespace Outer {
export class Inner {}
}
我们也可以利用命名空间与类的声明合并来为类添加静态属性和方法。
class A {
foo: string = A.bar;
}
namespace A {
export let bar = 'A';
export function create() {
return new A();
}
}
const a: A = A.create();
a.foo; // 'A'
A.bar; // 'A'
命名空间与枚举合并
同名的命名空间声明与枚举声明可以进行合并。
这相当于将枚举成员与命名空间的导出成员进行合并。
enum E {
A,
B,
C,
}
namespace E {
export function foo() {
E.A;
E.B;
E.C;
}
}
E.A;
E.B;
E.C;
E.foo();
需要注意的是,枚举成员名与命名空间导出成员名不允许出现同名的情况。
enum E {
A, // 编译错误!重复的标识符 A
}
namespace E {
export function A() {} // 编译错误!重复的标识符 A
}
扩充模块声明
对于任意模块,通过模块扩充语法能够对模块内的已有声明进行扩展。
例如,在“a.ts”模块中定义了一个接口A,在“b.ts”模块中可以对“a.ts”模块中定义的接口A进行扩展,为其增加新的属性。
// 有如下目录结构的工程:
C:\app
|-- a.ts
`-- b.ts
“a.ts”模块文件的内容如下:
export interface A {
x: number;
}
“b.ts”模块文件的内容如下:
import { A } from './a';
declare module './a' {
interface A {
y: number;
}
}
const a: A = { x: 0, y: 0 };
此例中,“declare module './a' {}”是模块扩充语法。
其中,“'./a'”表示要扩充的模块名,它与第一行模块导入语句中的模块名一致。
我们使用模块扩充语法对导入模块“'./a'”进行了扩充。
第4行定义的接口A将与“a.ts”模块中的接口A进行声明合并,合并后的结果仍为接口A,但是接口A增加了一个属性成员y。
在进行模块扩充时有以下两点需要注意:
不能在模块扩充语法中增加新的顶层声明,只能扩充现有的声明。
也就是说,我们只能对“'./a'”模块中已经存在的接口A进行扩充,而不允许增加新的声明,例如新定义一个接口B。
无法使用模块扩充语法对模块的默认导出进行扩充,只能对命名模块导出进行扩充,因为在进行模块扩充时需要依赖于导出的名字。
扩充全局声明
与模块扩充类似,TypeScript还提供了全局对象扩充语法“declare global {}”。
export {};
declare global {
interface Window {
myAppConfig: object;
}
}
const config: object = window.myAppConfig;
此例中,“declare global {}”是全局对象扩充语法,它扩展了全局的Window对象,增加了一个myAppConfig属性。
第1行,我们使用了“export {}”空导出语句,这是因为全局对象扩充语句必须在模块或外部模块声明中使用,当我们添加了空导出语句后,该文件就成了一个模块。
全局对象扩充也具有和模块扩充相同的限制,不能在全局对象扩充语法中增加新的顶层声明,只能扩充现有的声明。
TypeScript配置管理
编译器
TypeScript编译器是一段JavaScript程序,能够对TypeScript代码和JavaScript代码进行静态类型检查,并且可以将TypeScript程序编译为可执行的JavaScript程序。
TypeScript编译器具有以下两个主要功能:
- 能够对TypeScript和JavaScript代码进行静态类型检查。
- 能够将TypeScript和JavaScript代码转译为JavaScript代码。
关于编译器与转译器
编译器指的是能够将高级语言翻译成低级语言的程序。
编译器的典型代表是C语言编译器,它能够将C语言程序翻译为低级的机器语言
转译器通常是指能够将高级语言翻译成高级语言的程序,即在同一抽象层次上进行源代码的翻译。
转译器的典型代表是Babel,它能够将符合ES6规范的代码翻译为符合ES5规范的代码,其输入和输出均为JavaScript语言的代码。
有时候TypeScript编译器也称作TypeScript转译器,因为它是在TypeScript语言与JavaScript语言之间进行翻译的,而这两种编程语言拥有相近的抽象层次。
编译选项
严格类型检查
TypeScript编译器提供了两种类型检查模式,即严格类型检查和非严格类型检查。
非严格类型检查是默认的类型检查模式,该模式下的类型检查比较宽松。
在将已有的JavaScript代码迁移到TypeScript时,通常会使用这种类型检查模式,因为这样做可以让迁移工作更加顺利地进行,不至于一时产生过多的错误。
在严格类型检查模式下,编译器会进行额外的类型检查,从而能够更好地保证程序的正确性。
严格类型检查功能使用一系列编译选项来开启。在开始一个新的工程时,强烈推荐启用所有严格检查编译选项。对于已有的工程,则可以逐步启用这些编译选项。因为只有如此,才能够最大限度地利用编译器的静态类型检查功能。
--strict
“--strict”编译选项是所有严格类型检查编译选项的“总开关”。
如果启用了“--strict”编译选项,那么就相当于同时启用了下列编译选项:
- --noImplicitAny
- --strictNullChecks
- --strictFunctionTypes
- --strictBindCallApply
- --strictPropertyInitialization
- --noImplicitThis
- --alwaysStrict
在实际工程中,我们可以先启用“--strict”编译选项,然后再根据需求禁用不需要的某些严格类型检查编译选项。这样做有一个优点,那就是在TypeScript语言发布新版本时可能会引入新的严格类型检查编译选项,如果启用了“--strict”编译选项,那么就会自动应用新引入的严格类型检查编译选项。
--noImplicitAny
若一个表达式没有明确的类型注解并且编译器又无法推断出一个具体的类型时,那么它将被视为any类型。
编译器不会对any类型进行类型检查,因此可能存在潜在的错误。
/**
* --noImplicitAny=false
*/
function f(str) {
// ~~~
// 类型为:any
console.log(str.substring(3));
}
f(42); // 运行时错误
--strictNullChecks
若没有启用“--strictNullChecks”编译选项,编译器在类型检查时将忽略undefined值和null值。
/**
* --strictNullChecks=false
*/
function f(str: string) {
console.log(str.substring(3));
}
// 以下均没有编译错误,但在运行时产生错误
f(undefined);
f(null);
如果启用了“--strictNullChecks”编译选项,那么undefined值只能赋值给undefined类型(顶端类型、void类型除外),null值也只能赋值给null类型(顶端类型除外),两者都明确地拥有了各自的类型。
--strictFunctionTypes
该编译选项用于配置编译器对函数类型的类型检查规则。
如果启用了“--strictFunctionTypes”编译选项,那么函数参数类型与函数类型之间是逆变关系。
如果禁用了“--strictFunctionTypes”编译选项,那么函数参数类型与函数类型之间是相对宽松的双变关系。
不论是否启用了“--strictFunctionTypes”编译选项,函数返回值类型与函数类型之间始终是协变关系。
--strictBindCallApply
“Function.prototype.call”,“Function.prototype.bind”,“Function.prototype.apply”是JavaScript语言中函数对象上的内置方法。这三个方法都能够绑定函数调用时的this值。
function f(this: { name: string }, x: number, y:number) {
console.log(this.name);
console.log(x + y);
}
f.apply({ name: 'ts' }, [1, 2]);
f.call({ name: 'ts' }, 1, 2);
f.bind({ name: 'ts' })(1, 2);
如果没有启用“--strictBindCallApply”编译选项,那么编译器不会对以上三个内置方法进行类型检查。
虽然函数声明f中定义了this的类型以及参数x和y的类型,但是传入任何类型的实际参数都不会产生编译错误。
如果启用了“--strictBindCallApply”编译选项,那么编译器将对以上三个内置方法的this类型以及参数类型进行严格的类型检查。
/**
* --strictBindCallApply=true
*/
function f(this: Window, str: string) {
return this.alert(str);
}
f.call(document, 'foo');
// ~~~~~~~~
// 编译错误!'document' 类型的值不能赋值给 'window' 类型的参数
f.call(window, false);
// ~~~~~
// 编译错误!'false' 类型的值不能赋值给'string' 类型的参数
f.apply(document, ['foo']);
// ~~~~~~~~18 // 编译错误!'document' 类型的值不能赋值给 'window' 类型的参数
f.apply(window, [false]);
// ~~~~~
// 编译错误!'false' 类型的值不能赋值给'string' 类型的参数
f.bind(document);
// ~~~~~~~~
// 编译错误!'document' 类型的值不能赋值给 'window' 类型的参数
// 正确的用法
f.call(window, 'foo');
f.apply(window, ['foo']);
f.bind(window);
--strictPropertyInitialization
该编译选项用于配置编译器对类属性的初始化检查。
如果启用了“--strictPropertyInitialization”编译选项,那么当类的属性没有进行初始化时将产生编译错误。
类的属性既可以在声明时直接初始化,例如下例中的属性x,也可以在构造函数中初始化,例如下例中的属性y。如果一个属性没有使用这两种方式之一进行初始化,那么会产生编译错误,例如下例中的属性z。
/**
* -- strictPropertyInitialization=true
*/
class Point {
x: number = 0;
y: number;
z: number; // 编译错误!属性 'z' 没有初始值,也没有在构造函数中初始化
constructor() {
this.y = 0;
}
}
若没有启用“--strictPropertyInitialization”编译选项,那么上例中的代码不会产生编译错误。也就是说,允许未初始化的属性z存在。
使用该编译选项时需要注意一种特殊情况,有时候我们会在构造函数中调用其他方法来初始化类的属性,而不是在构造函数中直接进行初始化。
目前,编译器无法识别出这种情况,依旧会认为类的属性没有被初始化,进而产生编译错误。
我们可以使用“!”类型断言来解决这个问题。
/**
* -- strictPropertyInitialization=true
*/
class Point {
x: number; // 编译错误:属性 'x' 没有初始值,也没有在构造函数中初始化
y!: number; // 正确
constructor() {
this.initX();
this.initY();
}
private initX() {
this.x = 0;
}
private initY() {
this.y = 0;
}
}
--noImplicitThis
与“--noImplicitAny”编译选项类似,在启用了“--noImplicitThis”编译选项时,如果程序中的this值隐式地获得了any类型,那么将产生编译错误。
/**
* -- noImplicitThis=true
*/
class Rectangle {
width: number;
height: number;
constructor(width: number, height: number) {
this.width = width;
this.height = height;
}
getAreaFunctionWrong() {
return function () {
return this.width * this.height;
// ~~~~ ~~~~
// 编译错误:'this' 隐式地获得了 'any' 类型18 // 因为不存在类型注解
};
}
getAreaFunctionCorrect() {
return function (this: Rectangle) {
return this.width * this.height;
};
}
}
--alwaysStrict
ECMAScript 5引入了一个称为严格模式的新特性。
在全局JavaScript代码或函数代码的开始处添加“"use strict"”指令就能够启用JavaScript严格模式。
在模块和类中则会始终启用JavaScript严格模式。
注意,JavaScript严格模式不是本节所讲的TypeScript严格类型检查模式。
在JavaScript严格模式下,JavaScript有着更加严格的语法要求和一些新的语义。
例如,implements、interface、let、package、private、protected、public、static和yield都成了保留关键字;在函数的形式参数列表中,不允许出现同名的形式参数等。
若启用了“--alwaysStrict”编译选项,则编译器总是以JavaScript严格模式的要求来检查代码,并且在编译生成JavaScript代码时会在代码的开始位置添加“"use strict"”指令。
/**
* --alwaysStrict=true
*/
function outer() {
if (true) {
function inner() {
// ~~~~~
// 编译错误!当编译目标为'ES3'或'ES5'时,
// 在严格模式下的语句块中不允许使用函数声明
}
}
}
tsconfig.json
tsconfig.json配置文件来用来管理TypeScript工程。
tsconfig.json配置文件能够管理如下种类的工程配置:
- 编译文件列表。
- 编译选项。
- tsconfig.json配置文件间的继承关系(TypeScript 2.1)。
- 工程间的引用关系(TypeScript 3.0)。
使用配置文件
“tsconfig.json”配置文件是一个JSON[1]格式的文件。
若一个目录中存在“tsconfig.json”文件,那么该目录将被编译器视作TypeScript工程的根目录。
在编写好“tsconfig.json”配置文件之后,有以下两种方式来使用它:
- 运行tsc命令时,让编译器自动搜索“tsconfig.json”配置文件。
- 运行tsc命令时,使用“--project”或“-p”编译选项指定使用的“tsconfig.json”配置文件。
需要注意的是,如果运行tsc命令时指定了输入文件,那么编译器将忽略“tsconfig.json”配置文件,既不会自动搜索配置文件,也不会使用指定的配置文件。
tsc index.ts -p tsconfig.json
此例中,在运行tsc命令时指定了输入文件“index.ts”,因此编译器将不使用指定的“tsconfig.json”配置文件。
自动搜索配置文件
在运行tsc命令时,若没有使用“--project”或“-p”编译选项,那么编译器将在tsc命令的运行目录下查找是否存在文件名为“tsconfig.json”的配置文件。
若存在“tsconfig.json”配置文件,则使用该配置文件来编译工程;若不存在,则继续在父级目录下查找“tsconfig.json”配置文件,直到搜索到系统根目录为止;如果最终也未能找到一个可用的“tsconfig.json”配置文件,那么就会停止编译工程。
一旦编译器找到了匹配的“tsconfig.json”配置文件,就会终止查找过程并使用找到的配置文件。
指定配置文件
在运行tsc命令时,可以使用“--project”编译选项(短名字为“-p”)来指定使用的配置文件。
“--project”编译选项的参数是一个路径,它的值可以为:
- 指向某个具体的配置文件。在这种情况下,配置文件的文件名不限,例如可以使用名为“app.config.json”的配置文件。
- 指向一个包含了“tsconfig.json”配置文件的目录。在这种情况下,该目录中必须包含一个名为“tsconfig.json”的配置文件。
编译选项列表
在“tsconfig.json”配置文件中使用顶层的“compilerOptions”属性能够设置编译选项。
对于同一个编译选项而言,不论是在命令行上指定还是在“tsconfig.json”配置文件中指定,它们都具有相同的效果并且使用相同的名称。
TypeScript提供了一个“--init”编译选项,在命令行上运行tsc命令并使用“--init”编译选项会初始化一个“tsconfig.json”配置文件。
在生成的“tsconfig.json”配置文件中会自动添加一些常用的编译选项并将它们分类。
{
"compilerOptions": {
/* 基础选项 */
"incremental": true,
"target": "es5",
"module": "commonjs",
"lib": [],
"allowJs": true,
"checkJs": true,
"jsx": "preserve",
"declaration": true,
"declarationMap": true,
"sourceMap": true,
"outFile": "./",
"outDir": "./",
"rootDir": "./",
"composite": true,
"tsBuildInfoFile": "./",
"removeComments": true,
"noEmit": true,
"importHelpers": true,
"downlevelIteration": true,
"isolatedModules": true,
/* 严格类型检查选项 */
"strict": true,
"noImplicitAny": true,
"strictNullChecks": true,
"strictFunctionTypes": true,
"strictBindCallApply": true,
"strictPropertyInitialization": true,
"noImplicitThis": true,
"alwaysStrict": true,
/* 额外检查选项 */
"noUnusedLocals": true,
"noUnusedParameters": true,
"noImplicitReturns": true,
"noFallthroughCasesInSwitch": true,
/* 模块解析选项 */
"moduleResolution": "node",
"baseUrl": "./",
"paths": {},
"rootDirs": [],
"typeRoots": [],
"types": [],
"allowSyntheticDefaultImports": true,
"esModuleInterop": true,
"preserveSymlinks": true,
"allowUmdGlobalAccess": true,
/* SourceMap 选项 */
"sourceRoot": "",
"mapRoot": "",
"inlineSourceMap": true,
"inlineSources": true,
/* 实验性选项 */
"experimentalDecorators": true,
"emitDecoratorMetadata": true,
/* 高级选项 */
"forceConsistentCasingInFileNames": true
}
}
编译文件列表
“tsconfig.json” 配置文件的另一个主要用途是配置待编译的文件列表。
--listFiles编译选项
TypeScript提供了一个“--listFiles”编译选项,如果启用了该编译选项,那么在编译工程时,编译器将打印出参与本次编译的文件列表。
默认编译文件列表
如果工程中含有一个“tsconfig.json”配置文件,那么在默认情况下“tsconfig.json”配置文件所在目录及其子目录下的所有“.ts”“.d.ts”“.tsx”文件都会被添加到编译文件列表。
files属性
在“tsconfig.json”配置文件中,使用顶层的“files”属性能够定义编译文件列表。
“files”属性的值是由待编译文件路径所构成的数组。
// 例如一下tsconfig.json
{
"compilerOptions": {
"listFiles": true
},
"files": ["src/b.ts", "src/c.ts"]
}
在使用“files”属性设置编译文件列表时必须逐一地列出每一个文件,该属性不支持进行模糊的文件匹配。
因此,“files”属性适用于待编译文件数量较少的情况。当待编译文件数量较多时,使用“include”和“exclude”属性是更好的选择。
include属性
在“tsconfig.json”配置文件中,使用顶层的“include”属性能够定义编译文件列表。
“include”属性的功能包含了“files”属性的功能,它既支持逐一地列出每一个待编译的文件,也支持使用通配符来模糊匹配待编译的文件。
“include”属性支持使用三种通配符来匹配文件
假设当前工程目录结构如下:
C:\app
|-- bar
| `-- c.ts
|-- foo
| |-- a.spec.ts
| |-- a.ts
| |-- b.spec.ts
| `-- b.ts
`-- tsconfig.json
tsconfig.json配置文件的内容如下:
{
"include": ["foo/*.spec.ts"]
}
// 只有“C:\app\foo\a.spec.ts”和“C:\app\foo\b.spec.ts”文件会被添加到编译文件列表
{
"include": ["foo/?.ts"]
}
// 只有“C:\app\foo\a.ts”和“C:\app\foo\b.ts”文件会被添加到编译文件列表。
{
"include": ["bar/**/*.ts"]
}
// 只有“C:\app\bar\c.ts”文件会被添加到编译文件列表。
exclude属性
在“tsconfig.json”配置文件中,“exclude”属性需要与“include”属性一起使用,它的作用是从“include”属性匹配到的文件列表中去除指定的文件。
“exclude”属性也支持和“include”属性相同的通配符。
假设当前工程目录结构如下
C:\app
|-- bar
| `-- c.ts
|-- foo
| |-- a.spec.ts
| |-- a.ts
| |-- b.spec.ts
| `-- b.ts
`-- tsconfig.json
“tsconfig.json”配置文件的内容如下:
{
"compilerOptions": {
"listFiles": true
},
"include": ["**/*"],
"exclude": ["**/*.spec.ts"]
}
此例中,“include”属性将“C:\app”目录下所有的“.ts”文件添加到编译文件列表,然后“exclude”属性则将所有的“.spec.ts”文件从编译文件列表中移除。
声明文件列表
在TypeScript工程中“node_modules/@types”目录是一个特殊的目录,TypeScript将其视为第三方声明文件的根目录,因为在安装DefinitelyTyped提供的声明文件时,它会被安装到“node_modules/@types”目录下。
在默认情况下,编译器会将安装在“node_modules/@types”目录下的所有声明文件添加到编译文件列表。该默认行为可以使用“--typeRoots”和“--types”编译选项设置。
--typeRoots编译选项
“--typeRoots”编译选项用来设置声明文件的根目录。
当配置了“--typeRoots”编译选项时,只有该选项指定的目录下的声明文件会被添加到编译文件列表,而“node_modules/@types”目录下的声明文件将不再被默认添加到编译文件列表。
注意,“typeRoots”属性中的路径是相对于当前“tsconfig.json”配置文件的路径来进行解析的。
--types编译选项
“--types”编译选项也能够用来指定使用的声明文件。
“--typeRoots”编译选项配置的是含有声明文件的目录,而“--types”编译选项则配置的是具体的声明文件。
继承配置文件
一个“tsconfig.json”配置文件可以继承另一个“tsconfig.json”配置文件中的配置。
当一个项目中包含了多个TypeScript工程时,我们可以将工程共同的配置提取到“tsconfig.base.json”配置文件中,其他的“tsconfig.json”配置文件继承“tsconfig.base.json”配置文件中的配置。
这种方式避免了重复配置同一属性并且能够增强可维护性,当需要修改某一共通属性时,仅需要修改一处即可。
在“tsconfig.json”配置文件中,使用顶层的“extends”属性来设置要继承的“tscon-fig.json”配置文件。
在“extends”属性中指定的路径既可以是相对路径,也可以是绝对路径,但路径解析规则有所不同。
--showConfig编译选项
在介绍配置文件的继承之前,先介绍一下“--showConfig”编译选项。
在使用该编译选项后,编译器将显示出编译工程时使用的所有配置信息。
当我们在调试工程配置的时候,该编译选项是非常有帮助的。
注意,“--showConfig”编译选项只能在命令行上使用,在“tsconfig.json”配置文件中不能使用该编译选项。
需要注意的是,若启用了“--showConfig”编译选项,那么编译器将不会真正编译一个工程,而只是显示工程的配置。
使用相对路径
若“extends”属性中指定的路径是以“./”或“../”作为起始的,那么编译器在解析相对路径时将参照当前“tsconfig.json”配置文件所在的目录。
使用非相对路径
若“extends”属性指定的路径不是以“./”或“../”作为起始的,那么编译器将在“node_modules”目录下查找指定的配置文件。
编译器首先在“tsconfig.json”配置文件所在目录的“node_modules”子目录下查找,若该目录下包含了指定的配置文件,则使用该配置文件;否则,继续在父级目录下的“node_modules”子目录下查找,直到搜索到系统根目录为止。若最终未能找到指定的配置文件,则产生编译错误。
当编译器找到了匹配的配置文件时就会终止查找过程。
工程引用
随着工程规模的扩大,一个工程中的代码量可能会达到数十万行的级别。
当TypeScript编译器对数十万行代码进行类型检查时可能会遇到性能问题。
“分而治之”是解决该问题的一种策略,我们可以将一个较大的工程拆分为独立的子工程,然后将多个子工程关联在一起。
工程引用是TypeScript 3.0引入的新功能。
它允许一个TypeScript工程引用一个或多个其他的TypeScript工程。
借助于工程引用,我们可以将一个原本较大的TypeScript工程拆分成多个TypeScript工程,并设置它们之间的依赖关系。
每个TypeScript工程都可以进行独立的配置与类型检查。
当我们修改其中一个工程的代码时,会按需对其他工程进行类型检查,因此能够显著地提高类型检查的效率。
同时,使用工程引用还能够更好地组织代码结构,从逻辑上将软件拆分为可以重用的组件,将实现细节封装在组件内部,并通过定义好的接口与外界交互。
使用工程引用
若一个目录中包含“tsconfig.json”配置文件,那么该目录将被视为TypeScript工程的根目录。
在使用工程引用时,需要在“tsconfig.json”配置文件中进行以下配置:
- 使用“references”属性配置当前工程所引用的其他工程。
- 被引用的工程必须启用“composite”编译选项。
references
“tsconfig.json”配置文件有一个顶层属性“references”。
它的值是对象数组,用于设置引用的工程。
{
"references": [
{ "path": "../pkg1" },
{ "path": "../pkg2/tsconfig.release.json" },
]
}
其中,“path”的值既可以是指向含有“tsconfig.json”配置文件的目录,也可以直接指向某一个配置文件,此时配置文件名可以不为“tsconfig.json”。
--composite
“--composite”编译选项的值是一个布尔值。通过启用该选项,TypeScript编译器能够快速地定位依赖工程的输出文件位置。
如果一个工程被其他工程所引用,那么必须将该工程的“--composite”编译选项设置为true。
当启用了该编译选项时,它会影响以下的配置:
- 如果没有设置“--rootDir”编译选项,那么它将会被设置为包含“tsconfig.json”配置文件的目录。
- 如果设置了“include”或“files”属性,那么所有的源文件必须被包含在内,否则将产生编译错误。
- 必须启用“--declaration”编译选项。
--declarationMap
“--declarationMap”是推荐启用的编译选项。
如果启用了该选项,那么在生成“.d.ts”声明文件时会同时生成对应的“SourceMap”文件。
这样在代码编辑器中使用“跳转到定义”的功能时,编辑器会自动跳转到代码实现的位置,而不是跳转到声明文件中类型声明的位置。
工程引用示例
该示例项目由“C:\app\src”和“C:\app\test”两个工程组成,其目录结构如下:
C:\app
|-- src
| |-- index.ts
| `-- tsconfig.json
`-- test
|-- index.spec.ts
`-- tsconfig.json
// “index.ts”文件的内容如下:
export function add(x: number, y: number) {
return x + y;
}
// index.spec.ts”文件的内容如下:
import { add } from '../src/index';
if (add(1, 2) === 3) {
console.log('pass');
} else {
console.log('failed');
}
配置references
在该项目中,“C:\app\test”工程依赖于“C:\app\src”工程中的模块。
因此,“C:\app\test”工程依赖于“C:\app\src”工程。
在“C:\app\test”工程的“tsconfig.json”配置文件中设置对“C:\app\src”工程的依赖。
“C:\app\test\tsconfig.json”配置文件的内容如下:
{
"references": [
{
"path": "../src"
}
]
}
此例中,通过“references”属性设置了对“C:\app\src”工程的引用。
配置composite
在该项目中,“C:\app\src”工程被“C:\app\test”工程所依赖。
因此,必须在“C:\app\src”工程的tsconfig.json配置文件中将“--composite”编译选项设置为true。
{
"compilerOptions": {
"composite": true,
"declarationMap": true
}
}
--build
TypeScript提供了一种新的构建模式来配合工程引用的使用,它就是“--build”模式(简写为“-b”)。
在该模式下,编译器能够进行增量构建。
当使用该命令构建TypeScript工程时,编译器会执行如下操作:
- 查找当前工程所引用的工程。
- 检查当前工程和引用的工程是否有更新。
- 若工程有更新,则根据依赖顺序重新构建它们;若没有更新,则不进行重新构建。
TypeScript还提供了以下一些仅适用于“--build”模式的编译选项:
- --verbose,打印构建的详细日志信息,可以与以下编译选项一起使用。
- --dry,打印将执行的操作,而不进行真正的构建。
- --clean,删除工程中编译输出的文件,可以与“--dry”一起使用。
- --force,强制重新编译工程,而不管工程是否有更新。
- --watch,观察模式,执行编译命令后不退出,等待工程有更新后自动地再次编译工程。
solution模式
当一个项目由多个工程组成时,我们可以新创建一个“solution”工程来管理这些工程。
“solution”工程本身不包含任何实际代码,它只是引用了项目中所有的工程并将它们关联在一起。
在构建项目时,只需要构建“solution”工程就能够构建整个项目。
接下来,我们将之前的“C:\app\src”工程和“C:\app\test”工程重构为“solution”模式。修改后的目录结构如下:
C:\app
|-- src
| |-- index.ts
| `-- tsconfig.json
|-- test
| |-- index.spec.ts
| `-- tsconfig.json
`-- tsconfig.json
我们在“C:\app”目录下新建了一个“tsconfig.json”配置文件,目的是让“C:\app”成为一个“solution”工程。
“tsconfig.json”配置文件的内容如下:
{
"files": [],
"include": [],
"references": [
{ "path": "src" },
{ "path": "test" }
]
}
在该配置文件中同时将“C:\app\src”工程和“C:\app\test”工程设置为引用工程。
此外,必须将“files”和“include”属性设置为空数组,否则编译器将会重复编译“C:\app\src”工程和“C:\app\test”工程。
在“C:\app”目录下使用“--build”模式来编译该工程
编译器能够正确地编译“C:\app\src”工程和“C:\app\test”工程。
JavaScript类型检查
由于TypeScript语言是JavaScript语言的超集,因此JavaScript程序是合法的TypeScript程序。
TypeScript编译器能够像处理TypeScript程序一样去处理JavaScript程序,例如对JavaScript程序执行类型检查和编译JavaScript程序。
编译JavaScript
在一个工程中可能既存在TypeScript代码也存在JavaScript代码。
例如,一个TypeScript工程依赖于某个JavaScript代码库,又或者一个工程正在从JavaScript向TypeScript进行迁移。
如果TypeScript工程中的JavaScript程序也是工程的一部分,那么就需要使用“--allowJs”编译选项来配TypeScript编译器。
在默认情况下,编译器只会将“.ts”和“.tsx”文件添加到编译文件列表,而不会将“.js”和“.jsx”文件添加到编译文件列表。
如果想要让编译器去编译JavaScript文件,那么就需要启用“--allowJs”编译选项。
在启用了“--allowJs”编译选项后,工程中的“.js”和“.jsx”文件也会被添加到编译文件列表。
在启用了“--allowJs”编译选项后,编译器能够像编译TypeScript文件一样去编译JavaScript文件。
注意
这里的编译功能主要指:代码的转译;至于类型检查需要根据配置项情况
JavaScript类型检查
在默认情况下,TypeScript编译器不会对JavaScript文件进行类型检查。
就算启用了“--allowJs”编译选项,编译器依然不会对JavaScript代码进行类型检查。
--checkJs
TypeScript 2.3提供了一个“--checkJs”编译选项。
当启用了该编译选项时,编译器能够对“.js”和“.jsx”文件进行类型检查。
“--checkJs”编译选项必须与“--allowJs”编译选项一起使用。
// @ts-nocheck
“// @ts-nocheck”是一个注释指令,如果为JavaScript文件添加该注释,那么相当于告诉编译器不对该JavaScript文件进行类型检查。
该指令也可以在TypeScript文件中使用。
// @ts-check
如果一个JavaScript文件中添加了“// @ts-check”注释指令,那么编译器将对该JavaScript文件进行类型检查,不论是否启用了“--checkJs”编译选项。
// @ts-ignore
“// @ts-ignore”注释指令的作用是忽略对某一行代码进行类型检查。
当在代码中使用“// @ts-ignore”注释指令时,编译器不会对与该指令相邻的后面一行代码进行类型检查。
此外,该指令也可以在TypeScript文件中使用。
JSDoc与类型
JSDoc是一款知名的为JavaScript代码添加文档注释的工具。
JSDoc利用了JavaScript语言中的多行注释语法并结合使用特殊的“JSDoc标签”来为代码添加丰富的描述信息。
在使用JSDoc时,有以下两个基本要求:
- 代码注释必须以“/**”开始,其中星号(*)的数量必须为两个。若使用了 “/*” “/***” 或其他形式的多行注释,则JSDoc会忽略该条注释。
- 代码注释与它描述的代码处于相邻的位置,并且注释在上,代码在下。
TypeScript编译器既能够自动推断出大部分JavaScript代码的类型信息,也能够从JSDoc中提取类型信息。
接下来,我们将介绍TypeScript编译器支持的部分JSDoc标签。
@typedef
“@typedef”标签能够创建自定义类型。
通过“@typedef”标签创建的自定义类型等同于TypeScript中的类型别名。
/**
* @typedef {(number | string)} NumberLike
*/
// 等同于
type NumberLike = string | number;
@type
“@type”标签能够定义变量的类型。
/**
* @type {string}
*/
let a;
在“@type”标签中可以使用由“@typedef”标签创建的类型。
/**
* @typedef {(number | string)} NumberLike
*/
/**
* @type {NumberLike}
*/
let a = 0;
在“@type”标签中允许使用TypeScript中的类型及其语法。
/**@type {true | false} */
let a;
/** @type {number[]} */
let b;
/** @type {Array<number>} */
let c;
/** @type {{ readonly x: number, y?: string }} */
let d;
/** @type {(s: string, b: boolean) => number} */
let e;
@param
“@param”标签用于定义函数参数类型。
/**
* @param {string} x - A string param.
*/
function foo(x) {}
若函数参数是可选参数,则需要将参数名置于一对中括号“[]”中。
/**
* @param {string} [x] - An optional param.
*/
function foo(x) {}
在定义可选参数时,还可以为它指定一个默认值。
/**
* @param {string} [x="bar"] - An optional param
*/
function foo(x) {}
@return和@returns
“@return”和“@returns”标签的作用相同,两者都用于定义函数返回值类型。
/**
* @return {boolean}
*/
function foo() {
return true;
}
/**
* @returns {number}
*/
function bar() {
return 0;
}
@extends和修饰符
“@extends”标签用于定义继承的基类。
“@public”“@protected”“@private”标签分别用于定义类的公有成员、受保护成员和私有成员。
“@readonly”标签用于定义只读成员。
class Base {
/**
* @public
* @readonly
*/
x = 0;
/**
* @protected
*/
y = 0;
}
/**
* @extends {Base}
*/
class Derived extends Base {
/**
* @private
*/
z = 0;
}
三斜线指令
三斜线指令是一系列指令的统称,它是从TypeScript早期版本就开始支持的编译指令。
目前,已经不推荐继续使用三斜线指令,因为可以使用模块来取代它的大部分功能。
正如其名,三斜线指令是以三条斜线开始,并包含一个XML标签。
从JavaScript语法的角度上来看,三斜线指令相当于一条单行注释。
若一个文件中使用了三斜线指令,那么在三斜线指令之前只允许使用单行注释、多行注释和其他三斜线指令。
若某个三斜线指令出现在可执行语句之后,那么该三斜线指令将不生效。
/// <reference path="" />
该指令用于声明TypeScript源文件之间的依赖关系。
在编译一个文件时,编译器会同时将该文件中使用“/// <reference path=""/>”三斜线指令引用的文件添加到编译文件列表。
在“/// <reference path="" />”三斜线指令中,“path”属性定义了依赖文件的路径。
若指定的路径是一个相对路径,则相对于的是当前文件的路径。
--outFile编译选项
使用“--outFile”编译选项能够将编译生成的“.js”文件合并为一个文件。
但需要注意的是,该编译选项不支持合并使用了CommonJS模块和ES6模块模式的代码,只有将“--module”编译选项设置为None、System或AMD时才有效。
在合并生成代码的过程中,“/// <reference path="" />”三斜线指令可以作为排序文件的一种手段。
// “lib1.ts”文件
const a = 'lib1';
// “lib2.ts”文件
const b = 'lib2';
// “index.ts”文件
/// <reference path="lib2.ts" />
/// <reference path="lib1.ts" />
const index = 'index';
tsc命令如下:
tsc index.ts --outFile main.js
合并后的“main.js”文件内容如下:
var b = 'lib2';
var a = 'lib1';
/// <reference path="lib2.ts" />
/// <reference path="lib1.ts" />
var index = 'index';
在“index.ts”文件中,我们先声明了对“lib2.ts”文件的依赖,后声明了对“lib1.ts”文件的依赖。
在合并后的文件中,“lib2.ts”文件内容将出现在“lib1.ts”文件内容之上,在最后的是“index.ts”文件的内容。
--noResolve编译选项
在默认情况下,编译器会检查三斜线指令中引用的文件是否存在,并将它们添加到编译文件列表。
若启用了“--noResolve”编译选项,则编译器将忽略所有的三斜线指令。
此时,三斜线指令中引用的文件既不会被添加到编译文件列表,也不会影响“--outFile”的结果。
注意事项
在使用“/// <reference path="" />”三斜线指令时,有以下两个注意事项:
- "path”属性必须指向一个存在的文件,若文件不存在则会报错
- “path”属性不允许指向当前文件。
/// <reference types="" />
该三斜线指令用来定义对某个DefinitelyTyped声明文件的依赖,或者说是对安装在“node_modules/@types”目录下的某个声明文件的依赖。
在“/// <reference types="" />”三斜线指令中,“types”属性的值是声明文件安装包的名称,也就是安装到
“node_modules/@types”目录下的文件夹的名字。
例如,对jquery声明文件的依赖:
/// <reference types="jquery" />
declare var settings: JQuery.AjaxSettings;
注意,我们应该只在声明文件(.d.ts)中使用“/// <referencetypes="" />”三斜线指令,而不应该在“.ts”文件中使用该指令。
在.ts文件中,我们应该使用“--types”编译选项和“--typeRoots”编译选项来设置引用的声明文件。
/// <reference lib="" />
该三斜线指令用于定义对语言内置的某个声明文件的依赖。
在前文介绍过,当我们在计算机中安装TypeScript语言时,也会同时安装一些内置的声明文件。
这些声明文件位于TypeScript安装目录下的lib文件夹中,它们描述了JavaScript语言的标准API。
在“/// <reference lib="" />”三斜线指令中,“lib”属性的值是内置声明文件的名称。
内置声明文件统一使用“lib.[description].d.ts”命名方式,而“/// <reference lib="" />”指令中“lib”属性的值就是文件名中的“description”这部分。
例如,对于内置的“lib.es2015.symbol.wellknown.d.ts”声明文件,应使用如下方式进行引用:
/// <reference lib="es2015.symbol.wellknown" />
--target编译选项
“--target”编译选项能够设置程序的目标运行环境,可选择的值为:
- ES3(默认值)
- ES5
- ES6 / ES2015
- ES2016
- ES2017
- ES2018
- ES2019
- ES2020
- ESNext
如果我们将“--target”编译选项设置为“ES5”,那么编译器会自动将适用于“ES5”的内置声明文件添加到编译文件列表。
lib.d.ts
lib.es5.d.ts
lib.dom.d.ts
lib.webworker.importscripts.d.ts
lib.scripthost.d.ts
“--target”编译选项还决定了对哪些语法进行降级处理。
例如,在“ES5”环境中不支持箭头函数语法,因此当将“--target”设置为“ES5”时,编译后代码中的箭头函数将被替换为“ES5”环境中支持的函数表达式。
--lib编译选项
“--lib”编译选项与“/// <reference lib="" />”三斜线指令有着相同的作用,都是用来引用语言内置的某个声明文件。
如果将“--target”设置为“ES6”,但是我们想使用ES2017环境中才开始支持的“pad-Start()”函数。
那么,我们就需要引用内置的“lib.es2017.string.d.ts”声明文件,否则编译器将产生编译错误。
在“tsconfig.json”配置文件中使用“--lib”编译选项,示例如下:
{
"compilerOptions": {
"target": "ES6",
"lib": ["ES6", "ES2017.String"]
}
}
注意,我们不但要传入“ES2017.String”,还要传入“ES6”,否则编译器将仅包含“ES2017.String”这一个内置声明文件,这通常不是我们期望的结果。
使用“/// <reference lib="" />”三斜线指令,示例如下:
/// <reference lib="ES2017.String" />
不论使用以上哪种方式,我们都可以在代码中使用“padStart()”函数,因为编译器能够获取到该函数的类型信息。
需要注意的是,在将“lib.es2017.string.d.ts”内置声明文件添加到编译文件列表后,虽然编译器允许使用“padStart()”方法,但是实际的JavaScript运行环境可能不支持该方法。
因为该方法是在ES2017标准中定义的,而JavaScript运行环境可能仍处于一个较旧的版本,因此不支持这个新方法。这样就会导致程序可以成功地编译,但是在运行时出错,因为找不到“padStart()”方法的定义。
