Linux笔记:8-进程管理与 SELinux
@
进程管理与 SELinux
一个程序被加载到内存当中运作,那么在内存内的那个数据就被称为进程(process)。进程是操作系统上非常重要的概念,所有系统上面跑的数据都会以进程的型态存在。
什么是进程 (process)
在 Linux 系统当中:『触发任何一个事件时,系统都会将他定义成为一个进程,并且给予这个进程一个 ID ,称为 PID,同时依据启发这个进程的用户与相关属性关系,给予这个 PID 一组有效的权限设定。』 从此以后,这个 PID 能够在系统上面进行的动作,就与这个 PID 的权限有关。
进程与程序 (process & program)
如何产生一个进程呢?
其实很简单,就是『执行一个程序或指令』就可以触发一个事件而取得一个 PID ;
我们说过,系统应该是仅认识 binary file 的,那么当我们要让系统工作的时候,当然就是需要启动一个 binary file,那个 binary file 就是程序 (program) 。
我们知道,每个程序都有三组人马的权限,每组人马都具有 r/w/x 的权限,所以:『不同的使用者身份执行这个 program 时,系统给予的权限也都不相同!』;
举例来说,我们可以利用 touch 来建立一个空的文件,当 root 执行这个 touch 指令时,他取得的是 UID/GID = 0/0 的权限,而当 dmtsai(UID/GID=501/501) 执行这个 touch 时,他的权限就跟 root 不同!我们将这个概念绘制成图示
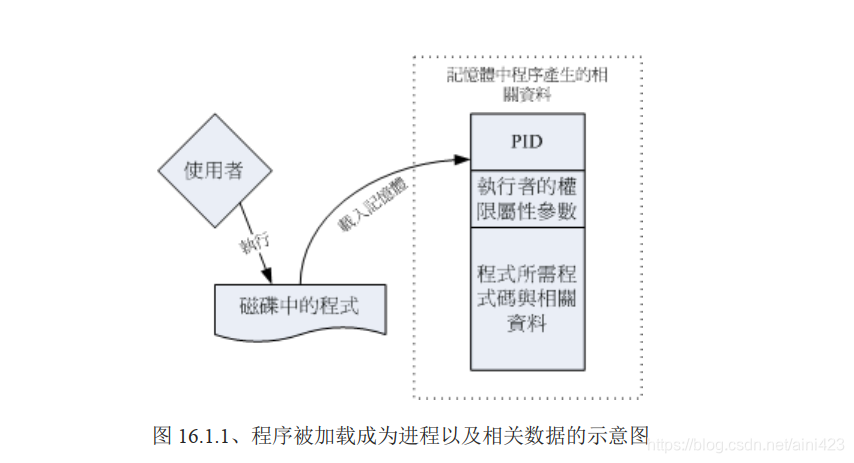
如上图所示,程序一般是放置在实体磁盘中,然后透过用户的执行来触发。
触发后会加载到内存中成为一个个体,那就是进程。
为了操作系统可管理这个进程,因此进程有给予执行者的权限/属性等参数,并包括程序所需要的脚本与数据或文件数据等, 最后再给予一个 PID 。系统就是透过这个 PID来判断该 process 是否具有权限进行工作的!他是很重要的。
举个更常见的例子,我们要操作系统的时候,通常是利用联机程序或者直接在主机前面登入,然后取得我们的 shell 对吧!那么,我们的 shell 是 bash 对吧,这个 bash 在 /bin/bash 对吧,那么同时间的每个人登入都是执行 /bin/bash 对吧!不过,每个人取得的权限就是不同。
如图:
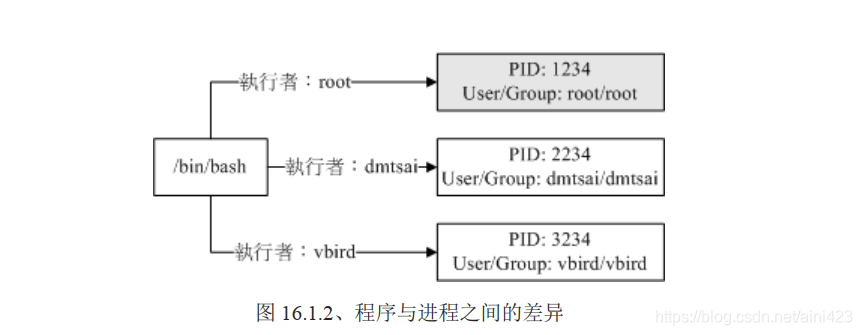
也就是说,当我们登入并执行 bash 时,系统已经给我们一个 PID 了,这个 PID 就是依据登入者的UID/GID (/etc/passwd) 来的~以上面的图,我们知道 /bin/bash是一个程序 (program),当 dmtsai 登入后,他取得一个 PID 号码为 2234 的进程,这个进程的User/Group 都是 dmtsai ,而当这个程序进行其他作业时,例如上面提到的 touch 这个指令时, 那么由这个进程衍生出来的其他进程在一般状态下,也会沿用这个进程的相关权限的。
程序与进程总结:
- 程序 (program):通常为 binary program ,放置在储存媒体中 (如硬盘、光盘、软盘、磁带等), 为实体文件的型态存在;
- 进程 (process):程序被触发后,执行者的权限与属性、程序的程序代码与所需数据等都会被加载内存中, 操作系统并给予这个内存内的单元一个标识符 (PID),可以说,进程就是一个正在运作中的程序。
子进程与父进程
在上面的说明里面,我们有提到所谓的『衍生出来的进程』
例如:当我们登入系统后,会取得一个 bash 的 shell ,然后,我们用这个 bash 提供的接口去执行另一个指令,例如 /usr/bin/passwd 或者是 touch 等等,那些另外执行的指令也会被触发成为 PID 。
那个后来执行指令才产生的 PID 就是『子进程』了,而在我们原本的 bash 环境下,就称为『父进程』。
所以你必须要知道,程序彼此之间是有相关性的;
假如连续执行两个 bash 后,第二个 bash 的父进程就是前一个 bash。
因为每个进程都有一个 PID ,那某个进程的父进程该如何判断?
就透过 Parent PID (PPID) 来判断即可。
此外,export探讨过环境变量的继承问题,子进程可以取得父进程的环境变量。
fork and exec:进程呼叫的流程
其实子进程与父进程之间的关系还挺复杂的,最大的复杂点在于进程互相之间的呼叫。
在 Linux 的进程呼叫通常称为 fork-and-exec 的流程 !
进程都会藉由父进程以复制 (fork) 的方式产生一个一模一样的子进程, 然后被复制出来的子进程再以 exec 的方式来执行实际要进行的程序,最终就成为一个子进程的存在。 整个流程有点像底下这张图:
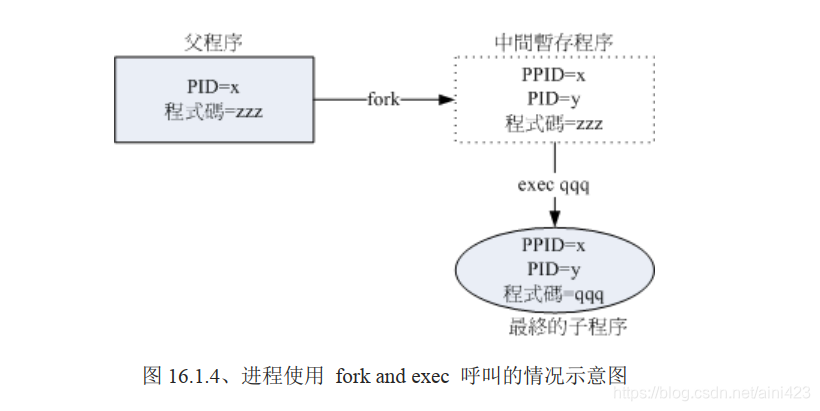
- 系统先以 fork 的方式复制一个与父进程相同的暂存进程,这个进程与父进程唯一的差别就是 PID不同! 但是这个暂存进程还会多一个 PPID 的参数,PPID 如前所述,就是父进程的进程标识符啦!
- 然后暂存进程开始以 exec 的方式加载实际要执行的程序,以上述图标来讲,新的程序名称为 qqq ,最终子进程的程序代码就会变成 qqq 。
系统或网络服务:常驻在内存的进程
我们知道系统每分钟都会去扫瞄 /etc/crontab 以及相关的配置文件, 来进行定时任务;
这个定时任务是 crond 这个程序所管理的,我们将他启动在背景当中一直持续不断的运作, 以前 DOS 年代常常说的一句话,那就是『常驻在内存当中的进程』
常驻在内存当中的进程通常都是负责一些系统所提供的功能以服务用户各项任务,因此这些常驻程序就会被我们称为:服务 (daemon)。
系统的服务非常的多,不过主要大致分成系统本身所需要的服务,例如刚刚提到的 crond 及 atd ,还有 rsyslogd 等等的。
还有一些则是负责网络联机的服务,例如Apache, named, postfix, vsftpd... 等等的。这些网络服务比较有趣的地方,在于这些程序被执行后,他会启动一个可以负责网络监听的端口口 (port) ,以提供外部客户端 (client) 的联机要求。
以 crontab 来说,他的主要执行程序名称是 cron 或 at ;
而系统服务名却是crond, atd;就是因为 Linux 希望我们可以简单的判断该程序是否为 daemon, 所以,一般daemon 类型的程序都会加上 d 在文件名后头。
Linux 的多人多任务环境
我们现在知道了,其实在 Linux 底下执行一个指令时,系统会将相关的权限、属性、程序代码与数据等均加载内存,并给予这个单元一个进程标识符 (PID),最终该指令可以进行的任务则与这个 PID的权限有关。
根据这个说明,我们就可以简单的了解,为什么 Linux 这么多用户,但是却每个人都可以拥有自己的环境了。
多人环境
Linux 最棒的地方就在于他的多人多任务环境
在 Linux 系统上面具有多种不同的账号, 每种账号都有都有其特殊的权限,只有一个人具有至高无上的权力,那就是root (系统管理员)。除了 root 之外,其他人都必须要受一些限制的!而每个人进入 Linux 的环境设定都可以随着每个人的喜好来设定(通过~/.bashrc );因为每个人登入后取得的 shell 的 PID 不同。
多任务行为
目前的 CPU 速度可高达几个 GHz。
我们的 Linux 可以让 CPU 在各个工作间进行切换, 也就是说,其实每个工作都仅占去 CPU 的几个指令次数,所以 CPU 每秒就能够在各个进程之间进行切换;
CPU 切换进程的工作,与这些工作进入到 CPU 运作的排程 (CPU 排程,非 crontab 排程) 会影响到系统的整体效能! 目前 Linux 使用的多任务切换行为是非常棒的一个机制,几乎可以将 PC 的性能整个压榨出来! 由于效能非常好,因此当多人同时登入系统时,其实会感受到整部主机好像就为了你存在一般! 这就是多人多任务的环境。
多重登入环境的七个基本终端窗口
在 Linux 当中,默认提供了六个文字界面登入窗口,以及一个图形界面,你可以使用 [Alt]+[F1]....[F7]来切换不同的终端机界面,而且每个终端机界面的登入者还可以不同人!这个东西可就很有用!尤其是在某个进程死掉的时候!
其实,这也是多任务环境下所产生的一个情况啦!我们的 Linux 默认会启动六个终端机登入环境的
程序,所以我们就会有六个终端机接口。
特殊的进程管理行为
Linux可以在任何时候,将某个被困住的进程杀掉,然后再重新执行该进程而不用重新启动系统。
假如我在 Linux下以文字界面登入,在屏幕当中显示错误讯息后就挂了~动都不能动,该如何是好!? 这个时候那默认的七个窗口就帮上忙啦!你可以随意的再按 [Alt]+[F1].....[F7] 来切换到其他的终端机界面,然后以 ps -aux 找出刚刚的错误进程,然后给他 kill 一下。
之所以可以这样做,是因为每个进程之间可能是独立的,也可能有相依性, 只要到独立的进程当中,删除有问题的那个进程,当然他就可以被系统移除掉。
bash 环境下的工作管理 (job control)
我们登入 bash 之后, 就是取得一个名为 bash 的 PID 了,而在这个环境底下所执行的其他指令,就几乎都是所谓的子进程了;
这个单一的 bash 接口下,可以『同时』进行多个工作;
多人多任务的系统资源分配问题考虑
多人多任务确实有很多的好处,但其实也有管理上的困扰,因为使用者越来越多, 将导致你管理上的困扰;
另外,由于使用者日盛,当使用者达到一定的人数后, 通常你的机器便需要升级了,因为 CPU 的运算与 RAM 的大小可能就会不敷使用
工作管理 (job control)
这个工作管理 (job control) 是用在 bash 环境下的;
也就是说:『当我们登入系统取得 bash shell 之后,在单一终端机接口下同时进行多个工作的行为管理 』
举例来说,我们在登入 bash 后, 想要一边复制文件、一边进行资料搜寻、一边进行编译,还可以一边进行 vim 程序撰写! 当然我们可以重复登入那六个文字接口的终端机环境中,不过,也能在一个bash中进行。
什么是工作管理
从上面的说明当中,你应该要了解的是:
『进行工作管理的行为中, 其实每个工作都是目前 bash 的子进程,亦即彼此之间是有相关性的。 我们无法以 job control 的方式由 tty1 的环境去管理 tty2 的bash !』
或许你会觉得很奇怪啊,既然我可以在六个终端接口登入,那何必使用 job control ?
不要忘记了,我们可以在 /etc/security/limits.conf 里面设定使用者同时可以登入的联机数,在这样的情况下,某些使用者可能仅能以一个终端联机来工作! 所以,你就得要了解一下这种工作管理的模式。
由于假设我们只有一个终端接口,因此在可以出现提示字符让你操作的环境就称为前景 (foreground),至于其他工作就可以让你放入背景 (background) 去暂停或运作。要注意的是,放入背景的工作想要运作时, 他必须不能够与使用者互动。
举例来说, vim 绝对不可能在背景里面执行 (running) 的!因为你没有输入数据他就不会跑啊! 而且放入背景的工作是不可以使用 [ctrl]+c 来终止的。
总之,要进行 bash 的 job control 必须要注意到的限制是:
- 这些工作所触发的进程必须来自于你 shell 的子进程(只管理自己的 bash);
- 前景:你可以控制与下达指令的这个环境称为前景的工作 (foreground);
- 背景:可以自行运作的工作,你无法使用 [ctrl]+c 终止他,可使用 bg/fg 呼叫该工作;
- 背景中『执行』的进程不能等待 terminal/shell 的输入(input)
job control 的管理
bash 只能够管理自己的工作而不能管理其他 bash 的工作,所以即使你是 root 也不能够将别人的 bash 底下的 job 给他拿过来执行。
此外,又分前景与背景,然后在背景里面的工作状态又可以分为『暂停 (stop)』与『运作中 (running)』。
直接将指令丢到背景中『执行』的 &
将工作丢到背景中; 最简单的方法就是利用『 & 』
举个简单的例子,我们要将 /etc/ 整个备份成为/tmp/etc.tar.gz 且不想要等待,那么可以这样做:
[root@study ~]# tar -zpcf /tmp/etc.tar.gz /etc &
[1] 14432 <== [job number] PID
[root@study ~]# tar: Removing leading `/' from member names
# 在中括号内的号码为工作号码 (job number),该号码与 bash 的控制有关。
# 后续的 14432 则是这个工作在系统中的 PID。至于后续出现的数据是 tar 执行的数据流,
# 由于我们没有加上数据流重导向,所以会影响画面!不过不会影响前景的操作喔!
在该指令的最后面加上一个『 & 』代表将该指令丢到背景中,此时 bash 会给予这个指令一个『工作号码(job number)』,就是那个 [1] ;
后面那个 14432 则是该指令所触发的『 PID 』;
这个 & 代表:『将工作丢到背景中去执行』! 注意到那个『执行』的字眼!此外,这样的情况最大的好处是: 不怕被 [ctrl]+c 中断的;
如果背景中程序完成时,会在前景中有提示,如下:
[1]+ Done tar -zpcf /tmp/etc.tar.gz /etc
就代表 [1] 这个工作已经完成 (Done) ,该工作的指令则是接在后面那一串指令列。
此外,将工作丢到背景当中要特别注意资料的流向!包括上面的讯息就有出现错误讯息,导致我的前景被影响。只要按下 [enter] 就会继续前景工作;
在背景当中执行的指令,如果有 stdout 及 stderr 时,他的数据依旧是输出到屏幕上面的,所以,我们会无法看到提示字符,当然也就无法完好的掌握前景工作。同时由于是背景工作的 tar ,此时你怎么按下 [ctrl]+c 也无法停止屏幕被搞的花花绿绿的!所以啰,最佳的状况就是利用数据流重导向, 将输出数据传送至某个文件中。
工作号码 (job number) 只与你这个 bash 环境有关,但是他既然是个指令触发的东西,所以当然一定是一个进程, 因此你会观察到有 job number 也搭配一个 PID !
将『目前』的工作丢到背景中『暂停』:[ctrl]-z
想个情况:如果我正在使用 vim ,却发现我有个文件不知道放在哪里,需要到 bash 环境下进行搜寻,此时是否要结束 vim?只要暂时将 vim 给他丢到背景当中等待即可。
例如以下的案例:
[root@study ~]# vim ~/.bashrc
# 在 vim 的一般模式下,按下 [ctrl]-z 这两个按键
[1]+ Stopped vim ~/.bashrc
[root@study ~]# <==顺利取得了前景的操控权!
[root@study ~]# find / -print
....(输出省略)....
# 此时屏幕会非常的忙碌!因为屏幕上会显示所有的文件名。请按下 [ctrl]-z 暂停
[2]+ Stopped find / -print
在 vim 的一般模式下,按下 [ctrl] 及 z 这两个按键,屏幕上会出现 [1] ,表示这是第一个工作, 而那个 + 代表最近一个被丢进背景的工作,且目前在背景下预设会被取用的那个工作 (与 fg 这个指令有关 )!而那个 Stopped 则代表目前这个工作的状态。在预设的情况下,使用 [ctrl]-z 丢到背景当中的工作都是『暂停』的状态!
观察目前的背景工作状态: jobs
[root@study ~]# jobs [-lrs]
选项与参数:
-l :除了列出 job number 与指令串之外,同时列出 PID 的号码;
-r :仅列出正在背景 run 的工作;
-s :仅列出正在背景当中暂停 (stop) 的工作。
范例一:观察目前的 bash 当中,所有的工作,与对应的 PID
[root@study ~]# jobs -l
[1]- 14566 Stopped vim ~/.bashrc
[2]+ 14567 Stopped find / -print
目前我有两个工作在背景当中,两个工作都是暂停的, 而如果我仅输入 fg 时,那么那个 [2] 会被拿到前景当中来处理;
其实 + 代表最近被放到背景的工作号码, - 代表最近最后第二个被放置到背景中的工作号码。 而超过最后第三个以后的工作,就不会有 +/- 符号存在了。
将背景工作拿到前景来处理:fg
[root@study ~]# fg %jobnumber
选项与参数:
%jobnumber :jobnumber 为工作号码(数字)。注意,那个 % 是可有可无的!
范例一:先以 jobs 观察工作,再将工作取出:
[root@study ~]# jobs -l
[1]- 14566 Stopped vim ~/.bashrc
[2]+ 14567 Stopped find / -print
[root@study ~]# fg <==预设取出那个 + 的工作,亦即 [2]。立即按下[ctrl]-z
[root@study ~]# fg %1 <==直接规定取出的那个工作号码!再按下[ctrl]-z
[root@study ~]# jobs -l
[1]+ 14566 Stopped vim ~/.bashrc
[2]- 14567 Stopped find / -print
需要注意最后一个显示结果,我们会发现 + 出现在第一个工作后,这是因为你刚刚利用 fg %1 将第一号工作捉到前景后又放回背景,此时最后一个被放入背景的将变成 vi 那个指令动作,所以当然 [1] 后面就会出现 +了;
输入『 fg - 』 则代表将 - 号的那个工作号码拿出来,上面就是 [2]那个工作号码
让工作在背景下的状态变成运作中: bg
范例一:一执行 find / -perm /7000 > /tmp/text.txt 后,立刻丢到背景去暂停!
[root@study ~]# find / -perm /7000 > /tmp/text.txt
# 此时,请立刻按下 [ctrl]-z 暂停!
[3]+ Stopped find / -perm /7000 > /tmp/text.txt
范例二:让该工作在背景下进行,并且观察他!!
[root@study ~]# jobs ; bg %3 ; jobs
[1] Stopped vim ~/.bashrc
[2]- Stopped find / -print
[3]+ Stopped find / -perm /7000 > /tmp/text.txt
[3]+ find / -perm /7000 > /tmp/text.txt &
[1]- Stopped vim ~/.bashrc
[2]+ Stopped find / -print
[3] Running find / -perm /7000 > /tmp/text.txt &
那个状态栏~以经由 Stopping 变成了 Running ;
指令列最后方多了一个 & 的符号! 代表该工作被启动在背景当中了。
管理背景当中的工作: kill
如果想要将该工作直接移除,这个时候就得需要给予该工作一个讯号 (signal) ,让他知道该怎么作才好。
[root@study ~]# kill -signal %jobnumber
[root@study ~]# kill -l
选项与参数:
-l :这个是 L 的小写,列出目前 kill 能够使用的讯号 (signal) 有哪些?
signal :代表给予后面接的那个工作什么样的指示啰!用 man 7 signal 可知:
-1 :重新读取一次参数的配置文件 (类似 reload);
-2 :代表与由键盘输入 [ctrl]-c 同样的动作;
-9 :立刻强制删除一个工作;
-15:以正常的进程方式终止一项工作。与 -9 是不一样的。
范例一:找出目前的 bash 环境下的背景工作,并将该工作『强制删除』。
[root@study ~]# jobs
[1]+ Stopped vim ~/.bashrc
[2] Stopped find / -print
[root@study ~]# kill -9 %2; jobs
[1]+ Stopped vim ~/.bashrc
[2] Killed find / -print
# 再过几秒你再下达 jobs 一次,就会发现 2 号工作不见了!因为被移除了!
范例二:找出目前的 bash 环境下的背景工作,并将该工作『正常终止』掉。
[root@study ~]# jobs
[1]+ Stopped vim ~/.bashrc
[root@study ~]# kill -SIGTERM %1
# -SIGTERM 与 -15 是一样的!您可以使用 kill -l 来查阅!
# 不过在这个案例中, vim 的工作无法被结束喔!因为他无法透过 kill 正常终止的意思!
特别留意一下, -9 这个 signal 通常是用在『强制删除一个不正常的工作』时所使用的, -15 则是以正常步骤结束一项工作(15 也是默认值),两者之间并不相同。**
kill 后面接的数字默认会是 PID ,如果想要管理 bash 的工作控制,就得要加上 %数字 ,这点也得特别留意。
脱机管理问题
要注意的是,我们在工作管理当中提到的『背景』指的是在终端机模式下可以避免 [crtl]-c 中断的一个情境, 你可以说那个是 bash 的背景,并不是放到系统的背景去执行。所以,工作管理的背景依旧与终端机有关。
在这样的情况下,如果你是以远程联机方式连接到你的 Linux 主机,并且将工作以 & 的方式放到背景去;在工作尚未结束的情况下你脱机了,该工作会被中断掉。
解决方式有:
可以参考 at(一次性定时任务) 来处理即可!因为 at 是将工作放置到系统背景, 而与终端机无关。
如果不想要使用 at 的话,那你也可以尝试使用 nohup 这个指令来处理!这个 nohup 可以让你在脱机或注销系统后,还能够让工作继续进行。
[root@study ~]# nohup [指令与参数] <==在终端机前景中工作
[root@study ~]# nohup [指令与参数] & <==在终端机背景中工作
上述指令需要注意的是, nohup 并不支持 bash 内建的指令,因此你的指令必须要是外部指令才行。
# 1. 先编辑一支会『睡着 500 秒』的程序:
[root@study ~]# vim sleep500.sh
#!/bin/bash
/bin/sleep 500s
/bin/echo "I have slept 500 seconds."
# 2. 丢到背景中去执行,并且立刻注销系统:
[root@study ~]# chmod a+x sleep500.sh
[root@study ~]# nohup ./sleep500.sh &
[2] 14812
[root@study ~]# nohup: ignoring input and appending output to `nohup.out' <==会告知这个讯息!
[root@study ~]# exit
如果你再次登入的话,再使用 pstree 去查阅你的进程,会发现 sleep500.sh 还在执行中 ;
由于我们的程序最后会输出一个讯息,但是 nohup 与终端机其实无关了,因此这个讯息的输出就会被导向『 ~/nohup.out 』,所以你才会看到上述指令中,当你输入 nohup后, 会出现那个提示讯
进程管理
进程的观察
利用静态的 ps 或者是动态的 top,还能以 pstree 来查阅进程树之间的关系
ps :将某个时间点的进程运作情况撷取下来
据
[root@study ~]# ps -lA <==也是能够观察所有系统的数据
[root@study ~]# ps axjf <==连同部分进程树状态
选项与参数:
-A :所有的 process 均显示出来,与 -e 具有同样的效用;
-a :不与 terminal 有关的所有 process ;
-u :有效使用者 (effective user) 相关的 process ;
x :通常与 a 这个参数一起使用,可列出较完整信息。
输出格式规划:
l :较长、较详细的将该 PID 的的信息列出;
j :工作的格式 (jobs format)
-f :做一个更为完整的输出。
建议,直接背两个比较不同的选项:
一个是只能查阅自己 bash 进程的『 ps -l 』
一个则是可以查阅所有系统运作的进程『 ps aux 』,注意,『 ps aux 』没有那个减号 (-) ;
仅观察自己的 bash 相关进程: ps -l
范例一:将目前属于您自己这次登入的 PID 与相关信息列示出来(只与自己的 bash 有关)
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 14830 13970 0 80 0 - 52686 poll_s pts/0 00:00:00 sudo
4 S 0 14835 14830 0 80 0 - 50511 wait pts/0 00:00:00 su
4 S 0 14836 14835 0 80 0 - 29035 wait pts/0 00:00:00 bash
0 R 0 15011 14836 0 80 0 - 30319 - pts/0 00:00:00 ps
# 还记得鸟哥说过,非必要不要使用 root 直接登入吧?从这个 ps -l 的分析,你也可以发现,
# 鸟哥其实是使用 sudo 才转成 root 的身份~否则连测试机,鸟哥都是使用一般账号登入的!
各参数代表意义如下:
- F:代表这个进程旗标 (process flags),说明这个进程的总结权限,常见号码有:
- 若为 4 表示此进程的权限为 root
- 若为 1 则表示此子进程仅进行复制(fork)而没有实际执行(exec)。
- S:代表这个进程的状态 (STAT),主要的状态有:
- R (Running):该程序正在运作中;
- S (Sleep):该程序目前正在睡眠状态(idle),但可以被唤醒(signal)。
- D :不可被唤醒的睡眠状态,通常这支程序可能在等待 I/O 的情况(ex>打印)
- T :停止状态(stop),可能是在工作控制(背景暂停)或除错 (traced) 状态;
- Z (Zombie):僵尸状态,进程已经终止但却无法被移除至内存外。
- UID/PID/PPID:代表『此进程被该 UID 所拥有/进程的 PID 号码/此进程的父进程 PID 号码』
- C:代表 CPU 使用率,单位为百分比;
- PRI/NI:Priority/Nice 的缩写,代表此进程被 CPU 所执行的优先级,数值越小代表该进程越快被 CPU 执行。 下文会详细介绍 PRI 与 NI 。
- ADDR/SZ/WCHAN:都与内存有关,ADDR 是 kernel function,指出该进程在内存的哪个部分,如果是个
running 的进程,一般就会显示『 - 』 / SZ 代表此进程用掉多少内存 / WCHAN 表示目前进程是否运作中,
同样的, 若为 - 表示正在运作中。- TTY:登入者的终端机位置,若为远程登录则使用动态终端接口 (pts/n);
- TIME:使用掉的 CPU 时间,注意,是此进程实际花费 CPU 运作的时间,而不是系统时间;
- CMD:就是 command 的缩写,造成此进程的触发程序之指令为何
观察系统所有进程: ps aux
范例二:列出目前所有的正在内存当中的进程:
[root@study ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 60636 7948 ? Ss Aug04 0:01 /usr/lib/systemd/systemd ...
root 2 0.0 0.0 0 0 ? S Aug04 0:00 [kthreadd]
.....(中间省略).....
root 14830 0.0 0.1 210744 3988 pts/0 S Aug04 0:00 sudo su -
root 14835 0.0 0.1 202044 2996 pts/0 S Aug04 0:00 su -
root 14836 0.0 0.1 116140 2960 pts/0 S Aug04 0:00 -bash
.....(中间省略).....
root 18459 0.0 0.0 123372 1380 pts/0 R+ 00:25 0:00 ps aux
各参数代表意义如下:
- USER:该 process 属于那个使用者账号的?
- PID :该 process 的进程标识符。
- %CPU:该 process 使用掉的 CPU 资源百分比;
- %MEM:该 process 所占用的物理内存百分比;
- VSZ :该 process 使用掉的虚拟内存量 (Kbytes)
- RSS :该 process 占用的固定的内存量 (Kbytes)
- TTY :该 process 是在那个终端机上面运作,若与终端机无关则显示 ?,另外, tty1-tty6 是本机上面的登入者进程,若为 pts/0 等等的,则表示为由网络连接进主机的进程。
- STAT:该进程目前的状态,状态显示与 ps -l 的 S 旗标相同 (R/S/T/Z)
- START:该 process 被触发启动的时间;
- TIME :该 process 实际使用 CPU 运作的时间。
- COMMAND:该进程的实际指令为何?
必须要知道的是『僵尸 (zombie) 』进程是什么? 通常,造成僵尸进程的成因是因为该进程应该已经执行完毕,或者是因故应该要终止了, 但是该进程的父进程却无法完整的将该进程结束掉,而造成那个进程一直存在内存当中。 如果你发现在某个进程的 CMD 后面还接上/
时,就代表该进程是僵尸进程,例如:
apache 8683 0.0 0.9 83384 9992 ? Z 14:33 0:00 /usr/sbin/httpd <defunct>
如果你发现系统中很多僵尸进程时,要找出该进程的父进程,然后好好的做个追踪,好好的进行主机的环境优化;
看看有什么地方需要改善的,不要只是直接将他 kill 掉而已!不然的话,万一他一直产生,那可就麻烦了!
事实上,通常僵尸进程都已经无法控管,而直接是交给 systemd 这支程序来负责,偏偏 systemd是系统第一支执行的程序, 他是所有程序的父程序!
我们无法杀掉该程序的 (杀掉他,系统就死掉了!),所以,如果产生僵尸进程, 而系统过一阵子还没有办法透过核心非经常性的特殊处理来将该进程删除时,那你只好透过 reboot 的方式来将该进程抹去。
top:动态观察进程的变化
相对于 ps 是撷取一个时间点的进程状态, top 则可以持续侦测进程运作的状态 。
[root@study ~]# top [-d 数字] | top [-bnp]
选项与参数:
-d :后面可以接秒数,就是整个进程画面更新的秒数。预设是 5 秒;
b :以批次的方式执行 top ,还有更多的参数可以使用喔!
通常会搭配数据流重导向来将批次的结果输出成为文件。
-n :与 -b 搭配,意义是,需要进行几次 top 的输出结果。
-p :指定某些个 PID 来进行观察监测而已。
在 top 执行过程当中可以使用的按键指令:
? :显示在 top 当中可以输入的按键指令;
P :以 CPU 的使用资源排序显示;
M :以 Memory 的使用资源排序显示;
N :以 PID 来排序喔!
T :由该 Process 使用的 CPU 时间累积 (TIME+) 排序。
k :给予某个 PID 一个讯号 (signal)
r :给予某个 PID 重新制订一个 nice 值。
q :离开 top 软件的按键。
范例一:每两秒钟更新一次 top ,观察整体信息:
[root@study ~]# top -d 2
top - 00:53:59 up 6:07, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 179 total, 2 running, 177 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2916388 total, 1839140 free, 353712 used, 723536 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 2318680 avail Mem
<==如果加入 k 或 r 时,就会有相关的字样出现在这里喔!
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18804 root 20 0 130028 1872 1276 R 0.5 0.1 0:00.02 top
1 root 20 0 60636 7948 2656 S 0.0 0.3 0:01.70 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
不同于 ps 是静态的结果输出, top 这个程序可以持续的监测整个系统的进程工作状态。
在预设的情况下,每次更新进程资源的时间为 5 秒,不过,可以使用 -d来进行修改。
top 主要分为两个画面,上面的画面为整个系统的资源使用状态,基本上总共有六行,显示的内容依序是:
第一行(top...):这一行显示的信息分别为:
目前的时间,亦即是 00:53:59 那个提示;
开机到目前为止所经过的时间,亦即是 up 6:07, 那个提示;
已经登入系统的用户人数,亦即是 3 users, 那个提示;
已经登入系统的用户人数,亦即是 3 users, 项目;在说到 batch 工作方式为负载小于 0.8 就是这个负载;代表的是 1, 5, 15 分钟,系统平均要负责运作几个进程(工作)的意思。 越小代表系统越闲置,若高于 1 得要注意你的系统进程是否太过繁复了 。
第二行(Tasks...):显示的是目前进程的总量与个别进程在什么状态(running, sleeping, stopped, zombie)。 比较需要注意的是最后的 zombie 那个数值,如果不是 0 ;说明有进程为僵尸进程。
第三行(%Cpus...):显示的是 CPU 的整体负载,每个项目可使用 ? 查阅。需要特别注意的是 wa 提示,那个项目代表的是 I/O wait, 通常你的系统会变慢都是 I/O 产生的问题比较大,因此这里得要注意这个提示耗用 CPU 的资源。 另外,如果是多核心的设备,可以按下数字键『1』来切换成不同 CPU 的负载率。
第四行与第五行:表示目前的物理内存与虚拟内存 (Mem/Swap) 的使用情况。 再次重申,要注意的是 swap的使用量要尽量的少;如果 swap 被用的很大量,表示系统的物理内存实在不足。
第六行:这个是当在 top 程序当中输入指令时,显示状态的地方。
至于 top 下半部分的画面,则是每个 process 使用的资源情况。
- PID :每个 process 的 ID
- USER:该 process 所属的使用者;
- PR :Priority 的简写,进程的优先执行顺序,越小越早被执行;
- NI :Nice 的简写,与 Priority 有关,也是越小越早被执行;
- %CPU:CPU 的使用率;
- %MEM:内存的使用率;
- TIME+:CPU 使用时间的累加;
top 预设使用 CPU 使用率 (%CPU) 作为排序的重点,如果你想要使用内存使用率排序,则可以按下『M』, 若要回复则按下『P』即可。如果想要离开 top 则按下『 q 』 。
观察特定进程
范例三:我们自己的 bash PID 可由 $$ 变量取得,请使用 top 持续观察该 PID
[root@study ~]# echo $$
14836 <==就是这个数字!他是我们 bash 的 PID
[root@study ~]# top -d 2 -p 14836
top - 01:00:53 up 6:14, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2916388 total, 1839264 free, 353424 used, 723700 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 2318848 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14836 root 20 0 116272 3136 1848 S 0.0 0.1 0:00.07 bash
pstree
[root@study ~]# pstree [-A|U] [-up]
选项与参数:
-A :各进程树之间的连接以 ASCII 字符来连接;
-U :各进程树之间的连接以万国码的字符来连接。在某些终端接口下可能会有错误;
-p :并同时列出每个 process 的 PID;
-u :并同时列出每个 process 的所属账号名称。
范例一:列出目前系统上面所有的进程树的相关性:
[root@study ~]# pstree -A
systemd-+-ModemManager---2*[{ModemManager}] # 这行是 ModenManager 与其子进程
|-NetworkManager---3*[{NetworkManager}] # 前面有数字,代表子进程的数量!
....(中间省略)....
|-sshd---sshd---sshd---bash---bash---sudo---su---bash---pstree <==我们指令执行的相依性
....(底下省略)....
# 注意一下,为了节省版面,所以鸟哥已经删去很多进程了!
范例二:承上题,同时秀出 PID 与 users
[root@study ~]# pstree -Aup
systemd(1)-+-ModemManager(745)-+-{ModemManager}(785)
| `-{ModemManager}(790)
|-NetworkManager(870)-+-{NetworkManager}(907)
| |-{NetworkManager}(911)
| `-{NetworkManager}(914)
....(中间省略)....
|-sshd(1326)---sshd(13923)---sshd(13927,dmtsai)---bash(13928)---bash(13970)---
....(底下省略)....
# 在括号 () 内的即是 PID 以及该进程的 owner 喔!一般来说,如果该进程的所有人与父进程同,
# 就不会列出,但是如果与父进程不一样,那就会列出该进程的拥有者!看上面 13927 就转变成 dmtsai 了
直接输入 pstree 可以查到进程相关性,如上表所示,还会使用线段将相关性进程连结起来
一般链接符号可以使用 ASCII 码即可,但有时因为语系问题会主动的以 Unicode 的符号来链接, 但因为可能终端机无法支持该编码,或许会造成乱码问题。因此可以加上 -A 选项来克服此类线段乱码问题。
由 pstree 的输出我们也可以很清楚的知道,所有的进程都是依附在 systemd 这支进程底下的;
仔细看一下,这支进程的 PID 是一号!因为他是由 Linux 核心所主动呼叫的第一支程序!所以 PID就是一号了。 这也是我们刚刚提到僵尸进程时有提到,为啥发生僵尸进程需要重新启动? 因为systemd 要重新启动,而重新启动 systemd 就是 reboot
如果还想要知道 PID 与所属使用者,加上 -u 及 -p 两个参数即可。
进程的管理
进程之间是可以互相控制的;
举例来说,你可以关闭、重新启动服务器软件,服务器软件本身是个进程, 你既然可以让她关闭或启动,当然就是可以控制该进程 。
进程之间的相互管理,其实是透过给予该进程一个讯号 (signal) 去告知该进程你想要让她作什么 。
主要的讯号代号与名称对应及内容是:
代 号 名称 内容 1 SIGHUP 启动被终止的进程,可让该 PID 重新读取自己的配置文件,类似重新启动 2 SIGINT 相当于用键盘输入 [ctrl]-c 来中断一个进程的进行 9 SIGKILL 代表强制中断一个进程的进行,如果该进程进行到一半, 那么尚未完成的部分可能会有『半产 品』产生,类似 vim 会有 .filename.swp 保留下来。 15 SIGTERM 以正常的结束进程来终止该进程。由于是正常的终止, 所以后续的动作会将他完成。不过,如 果该进程已经发生问题,就是无法使用正常的方法终止时, 输入这个 signal 也是没有用的。 19 SIGSTOP 以正常的结束进程来终止该进程。由于是正常的终止, 所以后续的动作会将他完成。不过,如 果该进程已经发生问题,就是无法使用正常的方法终止时, 输入这个 signal 也是没有用的。 上面仅是常见的 signal 而已,更多的讯号信息请自行 man 7 signal ;
一般来说,你只要记得『1, 9,15』这三个号码的意义即可。透过 kill 或 killall 传送一个讯号给某个进程。
kill -signal PID
kill 可以帮我们将这个 signal 传送给某个工作 (%jobnumber) 或者是某个 PID (直接输入数字)。
要再次强调的是: kill 后面直接加数字与加上 %number 的情况是不同的
因为工作控制中有 1 号工作,但是 PID 1 号则是专指『 systemd 』这支程序!
killall -signal 指令名称
由于 kill 后面必须要加上 PID (或者是 job number),所以,通常 kill 都会配合 ps, pstree 等指令,因为我们必须要找到相对应的那个进程的 ID 。
killall 可以利用『指令的名称』来直接给与一个信号;而不关心具体工作号和进程PID。
[root@study ~]# killall [-iIe] [command name]
选项与参数:
-i :interactive 的意思,交互式的,若需要删除时,会出现提示字符给用户;
-e :exact 的意思,表示『后面接的 command name 要一致』,但整个完整的指令
不能超过 15 个字符。
-I :指令名称(可能含参数)忽略大小写。
范例一:给予 rsyslogd 这个指令启动的 PID 一个 SIGHUP 的讯号
[root@study ~]# killall -1 rsyslogd
# 如果用 ps aux 仔细看一下,若包含所有参数,则 /usr/sbin/rsyslogd -n 才是最完整的!
范例二:强制终止所有以 httpd 启动的进程 (其实并没有此进程在系统内)
[root@study ~]# killall -9 httpd
范例三:依次询问每个 bash 程序是否需要被终止运作!
[root@study ~]# killall -i -9 bash
Signal bash(13888) ? (y/N) n <==这个不杀!
Signal bash(13928) ? (y/N) n <==这个不杀!
Signal bash(13970) ? (y/N) n <==这个不杀!
Signal bash(14836) ? (y/N) y <==这个杀掉!
# 具有互动的功能!可以询问你是否要删除 bash 这个程序。要注意,若没有 -i 的参数,
# 所有的 bash 都会被这个 root 给杀掉!包括 root 自己的 bash 喔! ^_^
总之,要删除某个进程,我们可以使用 PID 或者是启动该进程的指令名称;
而如果要删除某个服务呢,最简单的方法就是利用 killall , 因为他可以将系统当中所有以某个指令名称启动的进程全部删除。
举例来说,上面的范例二当中,系统内所有以 httpd 启动的进程,就会通通的被删除
关于进程的执行顺序
进程执行的优先序由:进程的优先执行序 (Priority) 与 CPU 排序 决定。
CPU 排序与Linux的定时工作排序并不一样。
CPU 排序指的是每支进程被 CPU运作的演算规则, 而定时工作排序则是将某支程序安排在某个时间再交由系统执行。 CPU 排序与操作系统较具有相关性。
Priority 与 Nice 值
CPU 一秒钟可以运作多达数 G 的微指令次数,透过核心的 CPU 排程可以让各进程被CPU 所切换运作, 因此每个进程在一秒钟内或多或少都会被 CPU 执行部分的脚本。如果进程都是集中在一个队列中等待 CPU 的运作, 而不具有优先级之分,也就是像我们去游乐场玩热门游戏需要排队一样,每个人都是照顺序来 。
如图:

上图中假设 pro1, pro2 是紧急的进程, pro3, pro4 是一般的进程,在这样的环境中,由于不具有优先级;
pro1, pro2 还是得要继续等待而没有优待 ;
我们可以将进程的优先级与 CPU 排程进行如下图的解释:
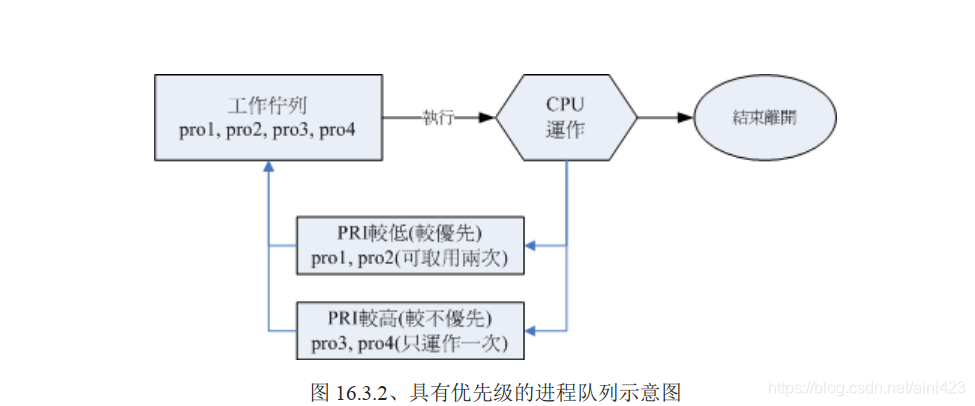
如上图所示,具高优先权的 pro1, pro2 可以被取用两次,而较不重要的 pro3, pro4 则运作次数较少。如此一来 pro1, pro2 就可以较快被完成 ;
要注意,上图仅是示意图,并非较优先者一定会被运作两次;
为了要达到上述的功能,我们 Linux 给予进程一个所谓的『优先执行序 (priority, PRI)』,这个 PRI 值越低代表越优先的意思。
不过这个 PRI 值是由核心动态调整的,用户无法直接调整 PRI值的。
PRI
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 14836 14835 0 90 10 - 29068 wait pts/0 00:00:00 bash
0 R 0 19848 14836 0 90 10 - 30319 - pts/0 00:00:00 ps
# 你应该要好奇,怎么我的 NI 已经是 10 了?还记得刚刚 top 的测试吗?我们在那边就有改过一次喔!
由于 PRI 是核心动态调整的,我们用户也无权去干涉 PRI ;
那如果你想要调整进程的优先执行序时,就得要透过 Nice 值了;
Nice 值就是上表的 NI ;一般来说, PRI 与 NI 的相关性如下:
PRI(new) = PRI(old) + nice
不过你要特别留意到,如果原本的 PRI 是 50 ,并不是我们给予一个 nice = 5 ,就会让 PRI 变成 55;
因为 PRI 是系统『动态』决定的,所以,虽然 nice 值是可以影响 PRI ,不过, 最终的 PRI仍是要经过系统分析后才会决定的。
另外, nice 值是有正负的,而既然 PRI 越小越早被执行, 所以,当 nice 值为负值时,那么该进程就会降低 PRI 值,亦即会变的较优先被处理。
此外,你必须要留意到:
- nice 值可调整的范围为 -20 ~ 19 ;
- root 可随意调整自己或他人进程的 Nice 值,且范围为 -20 ~ 19 ;
- 一般使用者仅可调整自己进程的 Nice 值,且范围仅为 0 ~ 19 (避免一般用户抢占系统资源);
- 一般使用者仅可将 nice 值越调越高,例如本来 nice 为 5 ,则未来仅能调整到大于 5;
设置进程 nice 值 方式:
- 一开始执行程序就立即给予一个特定的 nice 值:用 nice 指令;
- 调整某个已经存在的 PID 的 nice 值:用 renice 指令
nice :新执行的指令即给予新的 nice 值
[root@study ~]# nice [-n 数字] command
选项与参数:
-n :后面接一个数值,数值的范围 -20 ~ 19。
范例一:用 root 给一个 nice 值为 -5 ,用于执行 vim ,并观察该进程!
[root@study ~]# nice -n -5 vim &
[1] 19865
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 14836 14835 0 90 10 - 29068 wait pts/0 00:00:00 bash
4 T 0 19865 14836 0 85 5 - 37757 signal pts/0 00:00:00 vim
0 R 0 19866 14836 0 90 10 - 30319 - pts/0 00:00:00 ps
# 原本的 bash PRI 为 90 ,所以 vim 预设应为 90。不过由于给予 nice 为 -5 ,
# 因此 vim 的 PRI 降低了!RPI 与 NI 各减 5 !但不一定每次都是正好相同喔!因为核心会动态调整
[root@study ~]# kill -9 %1 <==测试完毕将 vim 关闭
通常什么时候要将 nice 值调大?
举例来说,系统的背景工作中, 某些比较不重要的进程之进行:例如备份工作!由于备份工作相当的耗系统资源, 这个时候就可以将备份的指令之 nice 值调大一些,可以使系统的资源分配的更为公平。
renice :已存在进程的 nice 重新调整
[root@study ~]# renice [number] PID
选项与参数:
PID :某个进程的 ID 啊!
范例一:找出自己的 bash PID ,并将该 PID 的 nice 调整到 -5
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 14836 14835 0 90 10 - 29068 wait pts/0 00:00:00 bash
0 R 0 19900 14836 0 90 10 - 30319 - pts/0 00:00:00 ps
[root@study ~]# renice -5 14836
14836 (process ID) old priority 10, new priority -5
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 14836 14835 0 75 -5 - 29068 wait pts/0 00:00:00 bash
0 R 0 19910 14836 0 75 -5 - 30319 - pts/0 00:00:00 ps
renice 后面需要接上 PID ;所以你务必要以 ps 或者其他进程观察的指令去找出 PID 才行 。
由上面这个范例当中我们也看的出来,虽然修改的是 bash 那个进程,但是该进程所触发的 ps 指令当中的 nice 也会继承而为 -5; 整个 nice 值是可以在父进程 --> 子进程之间传递的。
另外,除了 renice 之外,其实那个 top 同样的也是可以调整 nice 值。
系统资源的观察
一些对系统资源的观察指令:
free :观察内存使用情况
[root@study ~]# free [-b|-k|-m|-g|-h] [-t] [-s N -c N]
选项与参数:
-b :直接输入 free 时,显示的单位是 Kbytes,我们可以使用 b(bytes), m(Mbytes)
k(Kbytes), 及 g(Gbytes) 来显示单位喔!也可以直接让系统自己指定单位 (-h)
-t :在输出的最终结果,显示物理内存与 swap 的总量。
-s :可以让系统每几秒钟输出一次,不间断的一直输出的意思!对于系统观察挺有效!
-c :与 -s 同时处理~让 free 列出几次的意思~
范例一:显示目前系统的内存容量
[root@study ~]# free -m
total used free shared buff/cache available
Mem: 2848 346 1794 8 706 2263
Swap: 1023 0 1023
Mem 那一行显示的是物理内存的量, Swap 则是内存置换空间的量;
total 是总量, used 是已被使用的量, free 则是剩余可用的量;
shared/buffers/cached 则是在已被使用的量当中,用来作为缓冲及快取的量;
这些 shared/buffers/cached的用量中,在系统比较忙碌时,可以被释出而继续利用;因此后面就有一个 available (可用的) 数值 。
请看上头范例一的输出,我们可以发现这部测试机根本没有什么特别的服务,但是竟然有 706MB 左右的 cache ; 测试过程中还是有读/写/执行很多的文件;这些文件就会被系统暂时快取下来,等待下次运作时可以更快速的取出之意。
也就是说,系统是『很有效率的将所有的内存用光光』,目的是为了让系统的存取效能加速 。
需要注意的 swap 的量,一般来说, swap 最好不要被使用,尤其 swap 最好不要被使用超过 20% 以上。因为, Swap 的效能跟物理内存实在差很多,而系统会使用到 swap , 绝对是因为物理内存不足了才会这样做。
注意:
Linux 系统为了要加速系统效能,所以会将最常使用到的或者是最近使用到的文件数据快取 (cache) 下来, 这样未来系统要使用该文件时,就直接由内存中搜寻取出,而不需要重新读取硬盘,速度上面当然就加快了;
因此,物理内存被用光是正常的。
uname:查阅系统与核心相关信息
[root@study ~]# uname [-asrmpi]
选项与参数:
-a :所有系统相关的信息,包括底下的数据都会被列出来;
-s :系统核心名称
-r :核心的版本
-m :本系统的硬件名称,例如 i686 或 x86_64 等;
-p :CPU 的类型,与 -m 类似,只是显示的是 CPU 的类型!
-i :硬件的平台 (ix86)
范例一:输出系统的基本信息
[root@study ~]# uname -a
Linux study.centos.vbird 3.10.0-229.el7.x86_64 #1 SMP Fri Mar 6 11:36:42 UTC 2015
x86_64 x86_64 x86_64 GNU/Linux
uname 可以列出目前系统的核心版本、 主要硬件平台以及CPU 类型等等的信息。
uptime:观察系统启动时间与工作负载
root@study ~]# uptime
02:35:27 up 7:48, 3 users, load average: 0.00, 0.01, 0.05
# top 这个指令已经谈过相关信息,不再聊!
显示出目前系统已经开机多久的时间,以及 1, 5, 15 分钟的平均负载 。
netstat :追踪网络或插槽文件
这个指令比较常被用在网络的监控方面,不过,在进程管理方面也是需要了解的;
基本上, netstat 的输出分为两大部分,分别是网络与系统自己的进程相关性部分:
[root@study ~]# netstat -[atunlp]
选项与参数:
-a :将目前系统上所有的联机、监听、Socket 数据都列出来
-t :列出 tcp 网络封包的数据
-u :列出 udp 网络封包的数据
-n :不以进程的服务名称,以埠号 (port number) 来显示;
-l :列出目前正在网络监听 (listen) 的服务;
-p :列出该网络服务的进程 PID
范例一:列出目前系统已经建立的网络联机与 unix socket 状态
[root@study ~]# netstat
Active Internet connections (w/o servers) <==与网络较相关的部分
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 172.16.15.100:ssh 172.16.220.234:48300 ESTABLISHED
Active UNIX domain sockets (w/o servers) <==与本机的进程自己的相关性(非网络)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ] DGRAM 1902 @/org/freedesktop/systemd1/notify
unix 2 [ ] DGRAM 1944 /run/systemd/shutdownd
....(中间省略)....
unix 3 [ ] STREAM CONNECTED 25425 @/tmp/.X11-unix/X0
unix 3 [ ] STREAM CONNECTED 28893
unix 3 [ ] STREAM CONNECTED 21262
在上面的结果当中,显示了两个部分,分别是网络的联机以及 linux 上面的 socket 进程相关性部分。
因特网联机情况的参数说明:
- Proto :网络的封包协议,主要分为 TCP 与 UDP 封包;
- Recv-Q:非由用户程序链接到此 socket 的复制的总 bytes 数;
- Send-Q:非由远程主机传送过来的 acknowledged 总 bytes 数;
- Local Address :本地端的 IP:port 情况
- Foreign Address:远程主机的 IP:port 情况
- State :联机状态,主要有建立(ESTABLISED)及监听(LISTEN);
上面仅有一条联机的数据,他的意义是:『透过 TCP 封包的联机,远程的 172.16.220.234:48300联机到本地端的 172.16.15.100:ssh ,这条联机状态是建立 (ESTABLISHED) 的状态!』
除了网络上的联机之外,其实 Linux 系统上面的进程是可以接收不同进程所发送来的信息,那就是Linux 上头的插槽文档 (socket file)。
socket file 可以沟通两个进程之间的信息,因此进程可以取得对方传送过来的资料。
由于有 socket file,因此类似 X Window 这种需要透过网络连接的软件,目前新版的 distributions 就以 socket 来进行窗口接口的联机沟通了。
上表中 socket file 的输出字段有:
- Proto :一般就是 unix 啦;
- RefCnt:连接到此 socket 的进程数量;
- Flags :联机的旗标;
- Type :socket 存取的类型。主要有确认联机的 STREAM 与不需确认的 DGRAM 两种;
- State :若为 CONNECTED 表示多个进程之间已经联机建立。
- Path :连接到此 socket 的相关程序的路径!或者是相关数据输出的路径
以上表的输出为例,最后那三行在 /tmp/.xx 底下的数据,就是 X Window 窗口接口的相关进程 。
而 PATH 指向的就是这些进程要交换数据的插槽文件
利用 netstat 可以看到我们的哪些进程有启动哪些网络的『后门』(即开启了相应的网络端口);
范例二:找出目前系统上已在监听的网络联机及其 PID
[root@study ~]# netstat -tulnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1326/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2349/master
tcp6 0 0 :::22 :::* LISTEN 1326/sshd
tcp6 0 0 ::1:25 :::* LISTEN 2349/master
udp 0 0 0.0.0.0:123 0.0.0.0:* 751/chronyd
udp 0 0 127.0.0.1:323 0.0.0.0:* 751/chronyd
udp 0 0 0.0.0.0:57808 0.0.0.0:*
743/avahi-daemon: r
udp 0 0 0.0.0.0:5353 0.0.0.0:*
743/avahi-daemon: r
udp6 0 0 :::123 :::* 751/chronyd
udp6 0 0 ::1:323 :::* 751/chronyd
# 除了可以列出监听网络的接口与状态之外,最后一个字段还能够显示此服务的
# PID 号码以及进程的指令名称喔!例如上头的 1326 就是该 PID
范例三:将上述的 0.0.0.0:57808 那个网络服务关闭的话?
[root@study ~]# kill -9 743
[root@study ~]# killall -9 avahi-daemon
dmesg :分析核心产生的讯息
系统在开机的时候,核心会去侦测系统的硬件,你的某些硬件到底有没有被捉到,那就与这个时候的侦测有关。
但是这些侦测的过程要不是没有显示在屏幕上,就是很飞快的在屏幕上一闪而逝 ;
可以通过 dmesg 将信息打印出来。
所有核心侦测的讯息,不管是开机时候还是系统运作过程中,反正只要是核心产生的讯息,都会被记录到内存中的某个保护区段。
dmesg 这个指令就能够将该区段的讯息读出来;
因为讯息实在太多了,所以执行时可以加入这个管线指令『 | more 』来使画面暂停。
范例一:输出所有的核心开机时的信息
[root@study ~]# dmesg | more
范例二:搜寻开机的时候,硬盘的相关信息为何?
[root@study ~]# dmesg | grep -i vda
[ 0.758551] vda: vda1 vda2 vda3 vda4 vda5 vda6 vda7 vda8 vda9
[ 3.964134] XFS (vda2): Mounting V4 Filesystem
....(底下省略)....
vmstat :侦测系统资源变化
如果你想要动态的了解一下系统资源的运作, vmstat 可以侦测『 CPU / 内存 / 磁盘输入输出状态 』等等;
如果你想要了解一部繁忙的系统到底是哪个环节最累人, 可以使用 vmstat 分析看看。
[root@study ~]# vmstat [-a] [延迟 [总计侦测次数]] <==CPU/内存等信息
[root@study ~]# vmstat [-fs] <==内存相关
[root@study ~]# vmstat [-S 单位] <==设定显示数据的单位
[root@study ~]# vmstat [-d] <==与磁盘有关
[root@study ~]# vmstat [-p 分区槽] <==与磁盘有关
选项与参数:
-a :使用 inactive/active(活跃与否) 取代 buffer/cache 的内存输出信息;
-f :开机到目前为止,系统复制 (fork) 的进程数;
-s :将一些事件 (开机至目前为止) 导致的内存变化情况列表说明;
-S :后面可以接单位,让显示的数据有单位。例如 K/M 取代 bytes 的容量;
-d :列出磁盘的读写总量统计表
-p :后面列出分区槽,可显示该分区槽的读写总量统计表
范例一:统计目前主机 CPU 状态,每秒一次,共计三次!
[root@study ~]# vmstat 1 3
procs ------------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1838092 1504 722216 0 0 4 1 6 9 0 0 100 0 0
0 0 0 1838092 1504 722200 0 0 0 0 13 23 0 0 100 0 0
0 0 0 1838092 1504 722200 0 0 0 0 25 46 0 0 100 0 0
利用 vmstat 甚至可以进行追踪;
你可以使用类似『 vmstat 5 』代表每五秒钟更新一次,且无穷的更新!直到你按下 [ctrl]-c 为止。
各项字段的意义 如下:
进程字段 (procs) 的项目分别为:
r :等待运作中的进程数量;b:不可被唤醒的进程数量。这两个项目越多,代表系统越忙碌 (因为系统太忙,所以很多进程就无法被执行或一直在等待而无法被唤醒之故)。
内存字段 (memory) 项目分别为:
swpd:虚拟内存被使用的容量; free:未被使用的内存容量; buff:用于缓冲存储器; cache:用于高速
缓存。 这部份则与 free 是相同的。内存置换空间 (swap) 的项目分别为:
si:由磁盘中将进程取出的量;so:由于内存不足而将没用到的进程写入到磁盘的 swap 的容量。如果 si/so的数值太大,表示内存内的数据常常得在磁盘与主存储器之间传来传去,系统效能会很差!
磁盘读写 (io) 的项目分别为:
bi:由磁盘读入的区块数量; bo:写入到磁盘去的区块数量。
如果这部份的值越高,代表系统的 I/O 非常忙碌!
系统 (system) 的项目分别为:
in:每秒被中断的进程次数; cs:每秒钟进行的事件切换次数;
这两个数值越大,代表系统与接口设备的沟通非常频繁! 这些接口设备当然包括磁盘、网络卡、时间钟等。
CPU 的项目分别为:
us:非核心层的 CPU 使用状态; sy:核心层所使用的 CPU 状态; id:闲置的状态; wa:等待 I/O 所
耗费的 CPU 状态; st:被虚拟机 (virtual machine) 所盗用的 CPU 使用状态 (2.6.11 以后才支持)。
观察磁盘使用情况:
范例二:系统上面所有的磁盘的读写状态
[root@study ~]# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
vda 21928 0 992587 47490 7239 2225 258449 13331 0 26
sda 395 1 3168 213 0 0 0 0 0 0
sr0 0 0 0 0 0 0 0 0 0 0
dm-0 19139 0 949575 44608 7672 0 202251 16264 0 25
dm-1 336 0 2688 327 0 0 0 0 0 0
md0 212 0 1221 0 14 0 4306 0 0 0
dm-2 218 0 9922 565 54 0 4672 128 0 0
dm-3 179 0 957 182 11 0 4306 68 0 0
特殊文件与进程
具有 SUID/SGID 权限的指令执行状态
SUID 的权限其实与进程的相关性非常的大 ;
具有SUID 权限的程序被一般用户执行,具有一下特点:
- SUID 权限仅对二进制程序(binary program)有效;
- 执行者对于该程序需要具有 x 的可执行权限;
- 本权限仅在执行该程序的过程中有效 (run-time);
- 执行者将具有该程序拥有者 (owner) 的权限。
SUID 的权限会生效是由于『具有该权限的程序被触发』,而我们知道一个程序被触发会变成进程, 执行者可以具有程序拥有者的权限就是在该程序变成进程的那个时候。
比如:一般用户执行了 passwd 后你就具有 root 的权限;因为你在触发 passwd 后,会取得一个新的进
程与 PID,该 PID 产生时透过 SUID 来给予该 PID 特殊的权限设定;
我们使用 dmtsai 登入系统且执行 passwd 后,透过工作控制来解析这个流程:
[dmtsai@study ~]$ passwd
Changing password for user dmtsai.
Changing password for dmtsai
(current) UNIX password: <==这里按下 [ctrl]-z 并且按下 [enter]
[1]+ Stopped passwd
[dmtsai@study ~]$ pstree -uA
systemd-+-ModemManager---2*[{ModemManager}]
....(中间省略)....
|-sshd---sshd---sshd(dmtsai)---bash-+-passwd(root)
| `-pstree
....(底下省略)....
从上表的结果我们可以发现,bash部分是属于 dmtsai 这个一般账号的权限,passwd的则是 root的权限;
但你看到了, passwd 确实是由 bash 衍生出来的,不过就是权限不一样。
透过这样的解析, 你也会比较清楚为何不同程序所产生的权限不同。
这是由于『SUID 程序运作过程中产生的进程』的关系。
/proc/* 代表的意义
其实,我们之前提到的所谓的进程都是在内存当中;
而内存当中的数据又都是写入到 /proc/ 这个目录下的,所以,我们当然可以直接观察 /proc 这个目录当中的文件* 。
[root@study ~]# ll /proc
dr-xr-xr-x. 8 root root 0 Aug 4 18:46 1
dr-xr-xr-x. 8 root root 0 Aug 4 18:46 10
dr-xr-xr-x. 8 root root 0 Aug 4 18:47 10548
....(中间省略)....
-r--r--r--. 1 root root 0 Aug 5 17:48 uptime
-r--r--r--. 1 root root 0 Aug 5 17:48 version
-r--------. 1 root root 0 Aug 5 17:48 vmallocinfo
-r--r--r--. 1 root root 0 Aug 5 17:48 vmstat
-r--r--r--. 1 root root 0 Aug 5 17:48 zoneinfo
本上,目前主机上面的各个进程的 PID 都是以目录的型态存在于 /proc 当中。
举例来说,我们开机所执行的第一支程序 systemd 他的 PID 是 1 , 这个 PID 的所有相关信息都写入在 /proc/1/*当中!
若我们直接观察 PID 为 1 的数据好了,他有点像这样:
[root@study ~]# ll /proc/1
dr-xr-xr-x. 2 root root 0 Aug 4 19:25 attr
-rw-r--r--. 1 root root 0 Aug 4 19:25 autogroup
-r--------. 1 root root 0 Aug 4 19:25 auxv
-r--r--r--. 1 root root 0 Aug 4 18:46 cgroup
--w-------. 1 root root 0 Aug 4 19:25 clear_refs
-r--r--r--. 1 root root 0 Aug 4 18:46 cmdline <==就是指令串
-r--------. 1 root root 0 Aug 4 18:46 environ <==一些环境变量
lrwxrwxrwx. 1 root root 0 Aug 4 18:46 exe
....(以下省略)....
主要留意的文件:
- cmdline:这个进程被启动的指令串;
- environ:这个进程的环境变量内容。
[root@study ~]# cat /proc/1/cmdline
/usr/lib/systemd/systemd--switched-root--system--deserialize24
就是这个指令、选项与参数启动 systemd ;
这还是跟某个特定的 PID 有关的内容。
如果查看整个 Linux 系统相关的参数,是在 /proc 目录底下的文件;具体文件说明如下:
文件名 文件内容 /proc/cmdline 加载 kernel 时所下达的相关指令与参数!查阅此文件,可了解指令是如何启动的! /proc/cpuinfo 本机的 CPU 的相关信息,包含频率、类型与运算功能等 /proc/cpuinfo 这个文件记录了系统各个主要装置的主要装置代号,与 mknod 有关呢! /proc/filesystems 目前系统已经加载的文件系统啰! /proc/interrupts 目前系统上面的 IRQ 分配状态。 /proc/ioports 目前系统上面各个装置所配置的 I/O 地址。 /proc/kcore 这个就是内存的大小啦!好大对吧!但是不要读他啦! /proc/loadavg 还记得 top 以及 uptime 吧?没错!上头的三个平均数值就是记录在此! /proc/loadavg 使用 free 列出的内存信息,嘿嘿!在这里也能够查阅到! /proc/modules 目前我们的 Linux 已经加载的模块列表,也可以想成是驱动程序啦! /proc/mounts 系统已经挂载的数据,就是用 mount 这个指令呼叫出来的数据啦 /proc/swaps 到底系统挂加载的内存在哪里?呵呵!使用掉的 partition 就记录在此啦! /proc/swaps 使用 fdisk -l 会出现目前所有的 partition 吧?在这个文件当中也有纪录喔! /proc/uptime 就是用 uptime 的时候,会出现的信息啦! /proc/uptime 核心的版本,就是用 uname -a 显示的内容啦! /proc/bus/* 一些总线的装置,还有 USB 的装置也记录在此喔!
查询已开启文件的进程或已执行进程开启的文件
文件和进程关联性相互查询
fuser:藉由文件(或文件系统)找出正在使用该文件的进程
利用 fuser ,观察进程到底在这次启动过程中开启了多少文件 ;
你如果卸除时发现系统通知:『 device is busy 』,那表示这个文件系统正在忙碌中, 表示有某支进程有利用到该文件系统,那么你就可以利用 fuser 来追踪 。
[root@study ~]# fuser [-umv] [-k [i] [-signal]] file/dir
选项与参数:
-u :除了进程的 PID 之外,同时列出该进程的拥有者;
-m :后面接的那个档名会主动的上提到该文件系统的最顶层,对 umount 不成功很有效!
-v :可以列出每个文件与进程还有指令的完整相关性!
-k :找出使用该文件/目录的 PID ,并试图以 SIGKILL 这个讯号给予该 PID;
-i :必须与 -k 配合,在删除 PID 之前会先询问使用者意愿!
-signal:例如 -1 -15 等等,若不加的话,预设是 SIGKILL (-9) 啰!
范例一:找出目前所在目录的使用 PID/所属账号/权限 为何?
[root@study ~]# fuser -uv .
USER PID ACCESS COMMAND
/root: root 13888 ..c.. (root)bash
root 31743 ..c.. (root)bash
『.』底下有两个 PID 分别为 13888, 31743 的进程,该进程属于 root 且指令为 bash 。
ACCESS 字段,代表的含义是:
- c :此进程在当前的目录下(非次目录);
- e :可被触发为执行状态;
- f :是一个被开启的文件;
- r :代表顶层目录 (root directory);
- F :该文件被开启了,不过在等待回应中;
- m :可能为分享的动态函式库
lsof :列出被进程所开启的文件档名
相对于 fuser 是由文件或者装置去找出使用该文件或装置的进程;
lsof 查出某个进程开启或者使用的文件与装置 ;
[root@study ~]# lsof [-aUu] [+d]
选项与参数:
-a :多项数据需要『同时成立』才显示出结果时!
-U :仅列出 Unix like 系统的 socket 文件类型;
-u :后面接 username,列出该使用者相关进程所开启的文件;
+d :后面接目录,亦即找出某个目录底下已经被开启的文件!
范例一:列出目前系统上面所有已经被开启的文件与装置:
[root@study ~]# lsof
COMMAND PID TID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root cwd DIR 253,0 4096 128 /
systemd 1 root rtd DIR 253,0 4096 128 /
systemd 1 root txt REG 253,0 1230920 967763 /usr/lib/systemd/systemd
....(底下省略)....
# 注意到了吗?是的,在预设的情况下, lsof 会将目前系统上面已经开启的
# 文件全部列出来~所以,画面多的吓人啊!您可以注意到,第一个文件 systemd 执行的
# 地方就在根目录,而根目录,嘿嘿!所在的 inode 也有显示出来喔!
范例二:仅列出关于 root 的所有进程开启的 socket 文件
[root@study ~]# lsof -u root -a -U
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root 3u unix 0xffff8800b7756580 0t0 13715 socket
systemd 1 root 7u unix 0xffff8800b7755a40 0t0 1902
@/org/freedesktop/systemd1/notify
systemd 1 root 9u unix 0xffff8800b7756d00 0t0 1903 /run/systemd/private
.....(中间省略).....
Xorg 4496 root 1u unix 0xffff8800ab107480 0t0 25981 @/tmp/.X11-unix/X0
Xorg 4496 root 3u unix 0xffff8800ab107840 0t0 25982 /tmp/.X11-unix/X0
Xorg 4496 root 16u unix 0xffff8800b7754f00 0t0 25174 @/tmp/.X11-unix/X0
.....(底下省略).....
# 注意到那个 -a 吧!如果你分别输入 lsof -u root 及 lsof -U ,会有啥信息?
# 使用 lsof -u root -U 及 lsof -u root -a -U ,呵呵!都不同啦!
# -a 的用途就是在解决同时需要两个项目都成立时啊! ^_^
范例三:请列出目前系统上面所有的被启动的周边装置
[root@study ~]# lsof +d /dev
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root 0u CHR 1,3 0t0 1028 /dev/null
systemd 1 root 1u CHR 1,3 0t0 1028 /dev/null
# 看吧!因为装置都在 /dev 里面嘛!所以啰,使用搜寻目录即可啊!
范例四:秀出属于 root 的 bash 这支程序所开启的文件
[root@study ~]# lsof -u root | grep bash
ksmtuned 781 root txt REG 253,0 960384 33867220 /usr/bin/bash
bash 13888 root cwd DIR 253,0 4096 50331777 /root
bash 13888 root rtd DIR 253,0 4096 128 /
bash 13888 root txt REG 253,0 960384 33867220 /usr/bin/bash
bash 13888 root mem REG 253,0 106065056 17331169 /usr/lib/locale/locale-archive
....(底下省略)....
pidof :找出某支正在执行的程序的 PID
[root@study ~]# pidof [-sx] program_name
选项与参数:
-s :仅列出一个 PID 而不列出所有的 PID
-x :同时列出该 program name 可能的 PPID 那个进程的 PID
范例一:列出目前系统上面 systemd 以及 rsyslogd 这两个程序的 PID
[root@study ~]# pidof systemd rsyslogd
1 742
# 理论上,应该会有两个 PID 才对。上面的显示也是出现了两个 PID 喔。
# 分别是 systemd 及 rsyslogd 这两支程序的 PID 啦。
透过这个 pidof 指令,并且配合 ps aux 与正规表示法,就可以很轻易的找到您所想要的进程内容 ;
如果要找的是 bash ,那就 pidof bash ,立刻列出一堆 PID 号码
SELinux 初探
从进入了 CentOS 5.x 之后的 CentOS 版本中 (当然包括 CentOS 7),SELinux 已经是个非常完备的核心模块 。
CentOS 提供了很多管理 SELinux 的指令与机制, 因此在整体架构上面是单纯且容易操作管理的 。
在没有自行开发网络服务软件以及使用其他第三方协力软件的情况下, 也就是全部使用 CentOS 官方提供的软件来使用我们服务器的情况下,建议大家不要关闭 SELinux 。
什么是 SELinux
SELinux ,其实他是『 Security Enhanced Linux 』的缩写,字面上的意义就是安全强化的Linux 之意 。
控制主体(进程)能否能对目标(文件系统,文件资源)的读取。
当初设计的目标:避免资源的误用
SELinux 是整合到核心的一个模块 ;
SELinux 是在进行进程、文件等细部权限设定依据的一个核心模块。
传统的文件权限与账号关系:自主式访问控制, DAC
系统的账号主要分为系统管理员 (root) 与一般用户,而这两种身份能否使用系统上面的文件资源则与 rwx 的权限设定有关。
各种权限设定对 root 是无效的。
当某个进程想要对文件进行存取时, 系统就会根据该进程的拥有者/群组,并比对文件的权限,若通过权限检查,就可以存取该文件了 。
这种存取文件系统的方式被称为『自主式访问控制 (Discretionary Access Control, DAC)』,基本上,就是依据进程的拥有者与文件资源的 rwx 权限来决定有无存取的能力。
DAC 的访问控制的问题:
- root 具有最高的权限:如果不小心某支进程被有心人士取得, 且该进程属于 root 的权限,那么这支进程就可以在系统上进行任何资源的存取。
- 使用者可以取得进程来变更文件资源的访问权限:如果你不小心将某个目录的权限设定为 777 ,由于对任
何人的权限会变成 rwx ,因此该目录就会被任何人所任意存取!这些问题是非常严重的;尤其是当你的系统是被某些漫不经心的系统管理员所掌控时。
人往往是最大的安全问题。
以政策规则订定特定进程读取特定文件:委任式访问控制, MAC
DAC 的困扰就是当使用者取得进程后,他可以藉由这支进程与自己预设的权限来处理他自己的文件资源。 万一这个用户对 Linux 系统不熟,那就很可能会有资源误用的问题产生。
为了避免 DAC 容易发生的问题,因此 SELinux 导入了委任式访问控制 (Mandatory Access Control,MAC) 的方法
委任式访问控制 (MAC) ,他可以针对特定的进程与特定的文件资源来进行权限的控管。
也就是说,即使你是 root ,那么在使用不同的进程时,你所能取得的权限并不一定是 root , 而得要看当时该进程的设定而定 ;如此一来,我们针对控制的『主体』变成了『进程』而不是使用者 。
此外,这个主体进程也不能任意使用系统文件资源,因为每个文件资源也有针对该主体进程设定可取用的权限 。
如此一来,控件对象就细的多了;但整个系统进程那么多、文件那么多,一项一项控制可就没完没了,所以 SELinux 也提供一些预设的政策 (Policy) ,并在该政策内提供多个规则 (rule) ,让你可以选择是否启用该控制规则。
在委任式访问控制的设定下,我们的进程能够活动的空间就变小了;
举例来说, WWW 服务器软件的达成进程为 httpd 这支程序, 而默认情况下, httpd 仅能在 /var/www/ 这个目录底下存取文件,如果 httpd 这个进程想要到其他目录去存取数据时, 除了规则设定要开放外,目标目录也得要设定成 httpd 可读取的模式 (type) 才行 。
简单的来说,针对 Apache 这个 WWW 网络服务使用 DAC 或 MAC 的结果来说,两者间的关系可以使用下图来说明。

左图是没有 SELinux 的 DAC 存取结果,apache 这只 root 所主导的进程,可以在这三个目录内作任何文件的新建与修改~ 相当麻烦~右边则是加上 SELinux 的 MAC 管理的结果,SELinux 仅会针对 Apache 这个『 process 』放行部份的目录, 其他的非正规目录就不会放行给 Apache 使用。
因此不管你是谁,就是不能穿透 MAC 的框框 。
SELinux 的运作模式
SELinux 是透过 MAC 的方式来控管进程,他控制的主体是进程, 而目标则是该进程能否读取的『文件资源』
- 主体 (Subject):
SELinux 主要想要管理的就是进程,因此你可以将『主体』跟本章谈到的 process 划上等号;
- 目标 (Object):
主体进程能否存取的『目标资源』一般就是文件系统。因此这个目标项目可以等文件系统划上等号;
- 政策 (Policy):
由于进程与文件数量庞大,因此 SELinux 会依据某些服务来制订基本的存取安全性政策。
这些政策内还会有详细的规则 (rule) 来指定不同的服务开放某些资源的存取与否。
目前的 CentOS 7.x 里面仅有提供三个主要的政策,分别是:
- targeted:针对网络服务限制较多,针对本机限制较少,是预设的政策;
- minimum:由 target 修订而来,仅针对选择的进程来保护!
- mls:完整的 SELinux 限制,限制方面较为严格。
建议使用预设的 targeted 政策即可。
- 安全性本文 (security context):
主体能不能存取目标除了政策指定之外,主体与目标的安全性本文必须一致才能够顺利存取。
这个安全性本文 (security context) 有点类似文件系统的 rwx 。
安全性本文的内容与设定是非常重要的! 如果设定错误,你的某些服务(主体进程)就无法存取文件系统(目标资源),当然就会一直出现『权限不符』的错误讯息 。
由于 SELinux 重点在保护进程读取文件系统的权限,因此我们将上述的几个说明搭配起来,绘制成底下的流程图:

上图的重点在『主体』如何取得『目标』的资源访问权限;
由上图我们可以发现:
(1)主体进程必须要通过 SELinux 政策内的规则放行后,就可以与目标资源进行安全性本文的比对,
(2)若比对失败则无法存取目标,若比对成功则可以开始存取目标。
问题是,最终能否存取目标还是与文件系统的 rwx权限设定有关 。
加入了 SELinux 之后,出现权限不符的情况时,你就得要一步一步的分析可能的问题了。
安全性本文 (Security Context)
CentOS 7.x 的 target 政策已经帮我们制订好非常多的规则了,因此你只要知道如何开启/关闭某项规则的放行与否即可。
至于安全性本文 ,你可能需要自行配置文件案的安全性本文 ;
你可以吧安全本文想成 SELinux 内必备的 rwx。
安全性本文存在于主体进程中与目标文件资源中 ;
进程在内存内,所以安全性本文可以存入是没问题。
文件的安全性本文是放置到文件的 inode 内的,因此主体进程想要读取目标文件资源时,同样需要读取 inode , 这 inode 内就可以比对安全性本文以及 rwx等权限值是否正确,而给予适当的读取权限依据。
文件的安全性本文如下:
# 先来观察一下 root 家目录底下的『文件的 SELinux 相关信息』
[root@study ~]# ls -Z
-rw-------. root root system_u:object_r:admin_home_t:s0 anaconda-ks.cfg
-rw-r--r--. root root system_u:object_r:admin_home_t:s0 initial-setup-ks.cfg
-rw-r--r--. root root unconfined_u:object_r:admin_home_t:s0 regular_express.txt
# 上述特殊字体的部分,就是安全性本文的内容!鸟哥仅列出数个预设的文件而已,
# 本书学习过程中所写下的文件则没有列在上头喔!
如上所示,安全性本文主要用冒号分为三个字段,这三个字段的意义为
Identify:role:type
身份识别:角色:类型
三个字段的意义如下:
身份识别 (Identify):
相当于账号方面的身份识别;主要的身份识别常见有底下几种常见的类型:
unconfined_u: 不受限的用户,也就是说,该文件来自于不受限的进程所产生的!
一般来说,我们使用可登入账号来取得 bash 之后, 预设的 bash 环境是不受 SELinux 管制的~因为 bash 并不是什么特别的网络服务!因此,在这个不受 SELinux 所限制的 bash 进程所产生的文件,其身份识别大多就是unconfined_u 这个『不受限』用户。
system_u:系统用户,大部分就是系统自己产生的文件
基本上,如果是系统或软件本身所提供的文件,大多就是 system_u 这个身份名称,而如果是我们用户透过 bash 自己建立的文件,大多则是不受限的 unconfined_u 身份~如果是网络服务所产生的文件,或者是系统服务运作过程产生的文件,则大部分的识别就会是 system_u 。
角色 (Role):
透过角色字段,我们可以知道这个资料是属于进程、文件资源还是代表使用者。一般的角色有:
- object_r:代表的是文件或目录等文件资源,这应该是最常见的角色;
- system_r:代表的就是进程;不过,一般使用者也会被指定成为 system_r ;
角色的字段最后面使用『 _r 』来结尾
类型 (Type) (最重要!):
在预设的 targeted 政策中, Identify 与 Role 字段基本上是不重要的。重要的在于这个类型(type) 字段。
基本上,一个主体进程能不能读取到这个文件资源,与类型字段有关;而类型字段在文件与进程的定义不太相同,分别是 :
- type:在文件资源 (Object) 上面称为类型 (Type);
- domain:在主体进程 (Subject) 则称为领域 (domain) ;
domain 需要与 type 搭配,则该进程才能够顺利的读取文件资源 。
进程与文件 SELinux type 字段的相关性
系统中的进程在SELinux 底下的安全本文,如下:
# 再来观察一下系统『进程的 SELinux 相关信息』
[root@study ~]# ps -eZ
LABEL PID TTY TIME CMD
system_u:system_r:init_t:s0 1 ? 00:00:03 systemd
system_u:system_r:kernel_t:s0 2 ? 00:00:00 kthreadd
system_u:system_r:kernel_t:s0 3 ? 00:00:00 ksoftirqd/0
.....(中间省略).....
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 31513 ? 00:00:00 sshd
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 31535 pts/0 00:00:00 bash
# 基本上进程主要就分为两大类,一种是系统有受限的 system_u:system_r,另一种则可能是用户自己的,
# 比较不受限的进程 (通常是本机用户自己执行的程序),亦即是 unconfined_u:unconfined_r 这两种!
这些进程在 targeted 政策下的安全本文说明如下:
身份识别 角色 该对应在 targeted 的意义 unconfined_u unconfined_r 一般可登入使用者的进程啰!比较没有受限的进程之意!大多数都是用户已经顺利 登入系统 (不论是网络还是本机登入来取得可用的 shell) 后, 所用来操作系统的 进程!如 bash, X window 相关软件等。 system_u system_r 由于为系统账号,因此是非交谈式的系统运作进程,大多数的系统进程均是这种类型! 在预设的 target 政策下,其实最重要的字段是类型字段 (type), 主体与目标之间是否具有可以读写的权限,与进程的 domain 及文件的 type 有关!这两者的关系我们可以使用 crond 以及他的配置文件来说明;
即是 /usr/sbin/crond, /etc/crontab, /etc/cron.d 等文件来说明。
# 1. 先看看 crond 这个『进程』的安全本文内容:
[root@study ~]# ps -eZ | grep cron
system_u:system_r:crond_t:s0-s0:c0.c1023 1338 ? 00:00:01 crond
system_u:system_r:crond_t:s0-s0:c0.c1023 1340 ? 00:00:00 atd
# 这个安全本文的类型名称为 crond_t 格式!
# 2. 再来瞧瞧执行档、配置文件等等的安全本文内容为何!
[root@study ~]# ll -Zd /usr/sbin/crond /etc/crontab /etc/cron.d
drwxr-xr-x. root root system_u:object_r:system_cron_spool_t:s0 /etc/cron.d
-rw-r--r--. root root system_u:object_r:system_cron_spool_t:s0 /etc/crontab
-rwxr-xr-x. root root system_u:object_r:crond_exec_t:s0 /usr/sbin/crond
当我们执行 /usr/sbin/crond 之后,这个程序变成的进程的 domain 类型会是 crond_t 这一个 ;
而这个crond_t 能够读取的配置文件则为 system_cron_spool_t 这种的类型。
因此不论 /etc/crontab, /etc/cron.d 以及 /var/spool/cron 都会是相关的 SELinux 类型 (/var/spool/cron 为 user_cron_spool_t)。
图例说明如下:

上图的意义我们可以这样看的:
- 首先,我们触发一个可执行的目标文件,那就是具有 crond_exec_t 这个类型的 /usr/sbin/crond 文件;
- 该文件的类型会让这个文件所造成的主体进程 (Subject) 具有 crond 这个领域 (domain), 我们的政策针对这个领域已经制定了许多规则,其中包括这个领域可以读取的目标资源类型;
- 由于 crond domain 被设定为可以读取 system_cron_spool_t 这个类型的目标文件 (Object), 因此你的配置文件放到 /etc/cron.d/ 目录下,就能够被 crond 那支进程所读取了;
- 但最终能不能读到正确的资料,还得要看 rwx 是否符合 Linux 权限的规范
上述流程的重点:
第一个是政策内需要制订详细的 domain/type 相关性;
第二个是若文件的 type 设定错误, 那么即使权限设定为 rwx 全开的 777 ,该主体进程也无法读取目标文件资源;
如此一来, 也就可以避免用户将他的家目录设定为 777 时所造成的权限困扰。
SELinux 三种模式的启动、关闭与观察
并非所有的 Linux distributions 都支持 SELinux 的,所以你必须要先观察一下你的系统版本为何 ;
目前 SELinux 依据启动与否,共有三种模式,分别如下:
- enforcing:强制模式,代表 SELinux 运作中,且已经正确的开始限制 domain/type 了;
- permissive:宽容模式:代表 SELinux 运作中,不过仅会有警告讯息并不会实际限制 domain/type 的存取。
这种模式可以运来作为 SELinux 的 debug 之用;- disabled:关闭,SELinux 并没有实际运作。
流程示意图如下:

就如上图所示,首先,你得要知道,并不是所有的进程都会被 SELinux 所管制,因此最左边会出现一个所谓的『有受限的进程主体』 ;
观察受限进程:
举例来说,我们来找一找 crond 与 bash 这两只进程是否有被限制
[root@study ~]# ps -eZ | grep -E 'cron|bash'
system_u:system_r:crond_t:s0-s0:c0.c1023 1340 ? 00:00:00 atd
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 13888 tty2 00:00:00 bash
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 28054 pts/0 00:00:00 bash
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 28094 pts/0 00:00:00 bash
system_u:system_r:crond_t:s0-s0:c0.c1023 28174 ? 00:00:00 crond
如前所述,因为在目前 target 这个政策底下,只有第三个类型 (type) 字段会有影响,因此我们上表仅列出第三个字段的数据而已。 我们可以看到, crond 确实是有受限的主体进程,而 bash 因为是本机进程,因此就是不受限 (unconfined_t) 的类型!也就是说, bash 是不需要经过SELinux实际运作的流程,而是直接去判断 rwx 而已 。
三种模式的解释:
Disabled 的模式,那么 SELinux 将不会运作,当然受限的进程也不会经过 SELinux , 也是直接去判断 rwx 而已。
宽容 (permissive) 模式 ,这种模式也是不会将主体进程抵挡 (所以箭头是可以直接穿透的喔!),不过万一没有通过政策规则,或者是安全本文的比对时, 那么该读写动作将会被纪录起来 (log),可作为未来检查问题的判断依据。
Enforcing 模式,就是实际将受限主体进入规则比对、安全本文比对的流程,若失败,就直接抵挡主体进程的读写行为,并且将他记录下来。 如果通通没问题,这才进入到 rwx 权限的判断 。
查看SELinux模式:getenforce
[root@study ~]# getenforce
Enforcing <==诺!就显示出目前的模式为 Enforcing 啰!
查看SELinux 的政策 (Policy) :sestatus
[root@study ~]# sestatus [-vb]
选项与参数:
-v :检查列于 /etc/sestatus.conf 内的文件与进程的安全性本文内容;
-b :将目前政策的规则布尔值列出,亦即某些规则 (rule) 是否要启动 (0/1) 之意;
范例一:列出目前的 SELinux 使用哪个政策 (Policy)?
[root@study ~]# sestatus
SELinux status: enabled <==是否启动 SELinux
SELinuxfs mount: /sys/fs/selinux <==SELinux 的相关文件数据挂载点
SELinux root directory: /etc/selinux <==SELinux 的根目录所在
Loaded policy name: targeted <==目前的政策为何?
Current mode: enforcing <==目前的模式
Mode from config file: enforcing <==目前配置文件内规范的 SELinux 模式
Policy MLS status: enabled <==是否含有 MLS 的模式机制
Policy deny_unknown status: allowed <==是否预设抵挡未知的主体进程
Max kernel policy version: 28
SELinux 的配置文件 : /etc/selinux/config
[root@study ~]# vim /etc/selinux/config
SELINUX=enforcing <==调整 enforcing|disabled|permissive
SELINUXTYPE=targeted <==目前仅有 targeted, mls, minimum 三种政策
若有需要修改预设政策的话,就直接改 SELINUX=enforcing 那一行即可
SELinux 的启动与关闭
要注意的是:如果改变了政策则需要重新启动;
如果由 enforcing或 permissive 改成 disabled ,或由 disabled 改成其他两个,那也必须要重新启动。
这是因为 SELinux是整合到核心里面去的,你只可以在 SELinux 运作下切换成为强制 (enforcing) 或宽容 (permissive)模式,不能够直接关闭 SELinux 的! 如果刚刚你发现 getenforce 出现 disabled 时,请到上述文件修改成为 enforcing 然后重新启动。
你还需要注意的是:如果从 disable 转到启动 SELinux 的模式时, 由于系统必须要针对文件写入安全性本文的信息,因此开机过程会花费不少时间在等待重新写入 SELinux 安全性本文 (有时也称为SELinux Label) ,而且在写完之后还得要再次的重新启动一次 。你必须还要等待很长一段时间 。
如果你已经在 Enforcing 的模式,但是可能由于一些设定的问题导致 SELinux 让某些服务无法正常的运作, 此时你可以将 Enforcing 的模式改为宽容 (permissive) 的模式,让 SELinux 只会警告无法顺利联机的讯息, 而不是直接抵挡主体进程的读取权限。
让 SELinux 模式在 enforcing 与permissive 之间切换的方法为:
[root@study ~]# setenforce [0|1]
选项与参数:
0 :转成 permissive 宽容模式;
1 :转成 Enforcing 强制模式
范例一:将 SELinux 在 Enforcing 与 permissive 之间切换与观察
[root@study ~]# setenforce 0
[root@study ~]# getenforce
Permissive
[root@study ~]# setenforce 1
[root@study ~]# getenforce
Enforcing
不过请注意, setenforce 无法在 Disabled 的模式底下进行模式的切换 。
提示:
在某些特殊的情况底下,你从 Disabled 切换成 Enforcing 之后,竟然有一堆服务无法顺利启动,都会跟你说在 /lib/xxx 里面的数据没有权限读取,所以启动失败。这大多是由于在重新写入 SELinux type(Relabel) 出错之故,使用 Permissive 就没有这个错误。那如何处理呢?最简单的方法就是在 Permissive 的状态下,使用『 restorecon -Rv / 』重新还原所有 SELinux 的类型,就能够处理这个错误
SELinux 政策内的规则管理
我们知道 SELinux 的三种模式是会影响到主体进程的放行与否。 如果是进入Enforcing 模式,那么接着下来会影响到主体进程的,当然就是第二关:『 target 政策内的各项规则(rules) 』 。
SELinux 各个规则的布尔值查询 getsebool
如果想要查询系统上面全部规则的启动与否 (on/off,亦即布尔值),很简单的透过 sestatus -b 或getsebool -a 均可!
[root@study ~]# getsebool [-a] [规则的名称]
选项与参数:
-a :列出目前系统上面的所有 SELinux 规则的布尔值为开启或关闭值
范例一:查询本系统内所有的布尔值设定状况
[root@study ~]# getsebool -a
abrt_anon_write --> off
abrt_handle_event --> off
....(中间省略)....
cron_can_relabel --> off # 这个跟 cornd 比较有关!
cron_userdomain_transition --> on
....(中间省略)....
httpd_enable_homedirs --> off # 这当然就是跟网页,亦即 http 有关的啰!
....(底下省略)....
# 这么多的 SELinux 规则喔!每个规则后面都列出现在是允许放行还是不许放行的布尔值喔!
SELinux 各个规则规范的主体进程能够读取的文件 SELinux type 查询 seinfo, sesearch
[root@study ~]# seinfo [-Atrub]
选项与参数:
-A :列出 SELinux 的状态、规则布尔值、身份识别、角色、类别等所有信息
-u :列出 SELinux 的所有身份识别 (user) 种类
-r :列出 SELinux 的所有角色 (role) 种类
-t :列出 SELinux 的所有类别 (type) 种类
-b :列出所有规则的种类 (布尔值)
范例一:列出 SELinux 在此政策下的统计状态
[root@study ~]# seinfo
Statistics for policy file: /sys/fs/selinux/policy
Policy Version & Type: v.28 (binary, mls)
Classes: 83 Permissions: 255
Sensitivities: 1 Categories: 1024
Types: 4620 Attributes: 357
Users: 8 Roles: 14
Booleans: 295 Cond. Expr.: 346
Allow: 102249 Neverallow: 0
Auditallow: 160 Dontaudit: 8413
Type_trans: 16863 Type_change: 74
Type_member: 35 Role allow: 30
Role_trans: 412 Range_trans: 5439
....(底下省略)....
# 从上面我们可以看到这个政策是 targeted ,此政策的安全本文类别有 4620 个;
# 而各种 SELinux 的规则 (Booleans) 共制订了 295 条
如果你想要查询目前所有的身份识别与角色,就使用『 seinfo -u 』及『 seinfo -r 』就可以知道 ;
至于简单的统计数据,就直接输入 seinfo 即可 ;
具体进程的 domain 能够读取的文件 SELinux type :通过 sesearch(具体规则查询) 可查询;
[root@study ~]# sesearch [-A] [-s 主体类别] [-t 目标类别] [-b 布尔值]
选项与参数:
-A :列出后面数据中,允许『读取或放行』的相关数据
-t :后面还要接类别,例如 -t httpd_t
-b :后面还要接 SELinux 的规则,例如 -b httpd_enable_ftp_server
范例一:找出 crond_t 这个主体进程能够读取的文件 SELinux type
[root@study ~]# sesearch -A -s crond_t | grep spool
allow crond_t system_cron_spool_t : file { ioctl read write create getattr ..
allow crond_t system_cron_spool_t : dir { ioctl read getattr lock search op..
allow crond_t user_cron_spool_t : file { ioctl read write create getattr se..
allow crond_t user_cron_spool_t : dir { ioctl read write getattr lock add_n..
allow crond_t user_cron_spool_t : lnk_file { read getattr } ;
# allow 后面接主体进程以及文件的 SELinux type,上面的数据是撷取出来的,
# 意思是说,crond_t 可以读取 system_cron_spool_t 的文件/目录类型~等等!
范例二:找出 crond_t 是否能够读取 /etc/cron.d/checktime 这个我们自定义的配置文件?
[root@study ~]# ll -Z /etc/cron.d/checktime
-rw-r--r--. root root unconfined_u:object_r:admin_home_t:s0 /etc/cron.d/checktime
# 两个重点,一个是 SELinux type 为 admin_home_t,一个是文件 (file)
[root@study ~]# sesearch -A -s crond_t | grep admin_home_t
allow domain admin_home_t : dir { getattr search open } ;
allow domain admin_home_t : lnk_file { read getattr } ;
allow crond_t admin_home_t : dir { ioctl read getattr lock search open } ;
allow crond_t admin_home_t : lnk_file { read getattr } ;
# 仔细看!看仔细~虽然有 crond_t admin_home_t 存在,但是这是总体的信息,
# 并没有针对某些规则的寻找~所以还是不确定 checktime 能否被读取。但是,基本上就是 SELinux
# type 出问题~因此才会无法读取的!
修改 SELinux 规则的布尔值 setsebool
[root@study ~]# setsebool [-P] 『规则名称』 [0|1]
选项与参数:
-P :直接将设定值写入配置文件,该设定数据未来会生效的!
范例一:查询 httpd_enable_homedirs 这个规则的状态,并且修改这个规则成为不同的布尔值
[root@study ~]# getsebool httpd_enable_homedirs
httpd_enable_homedirs --> off <==结果是 off ,依题意给他启动看看!
[root@study ~]# setsebool -P httpd_enable_homedirs 1 # 会跑很久很久!请耐心等待!
[root@study ~]# getsebool httpd_enable_homedirs
httpd_enable_homedirs --> on
这个 setsebool 最好记得一定要加上 -P 的选项!因为这样才能将此设定写入配置文件 。
SELinux 安全本文的修改
现在我们知道 SELinux 对受限的主体进程有没有影响,第一关考虑SELinux 的三种类型,第二关考虑 SELinux 的政策规则是否放行,第三关则是开始比对 SELinux type 。
使用 chcon 手动修改文件的 SELinux type
[root@study ~]# chcon [-R] [-t type] [-u user] [-r role] 文件
[root@study ~]# chcon [-R] --reference=范例文件 文件
选项与参数:
-R :连同该目录下的次目录也同时修改;
-t :后面接安全性本文的类型字段!例如 httpd_sys_content_t ;
-u :后面接身份识别,例如 system_u; (不重要)
-r :后面街角色,例如 system_r; (不重要)
-v :若有变化成功,请将变动的结果列出来
--reference=范例文件:拿某个文件当范例来修改后续接的文件的类型!
范例一:查询一下 /etc/hosts 的 SELinux type,并将该类型套用到 /etc/cron.d/checktime 上
[root@study ~]# ll -Z /etc/hosts
-rw-r--r--. root root system_u:object_r:net_conf_t:s0 /etc/hosts
[root@study ~]# chcon -v -t net_conf_t /etc/cron.d/checktime
changing security context of ‘/etc/cron.d/checktime’
[root@study ~]# ll -Z /etc/cron.d/checktime
-rw-r--r--. root root unconfined_u:object_r:net_conf_t:s0 /etc/cron.d/checktime
范例二:直接以 /etc/shadow SELinux type 套用到 /etc/cron.d/checktime 上!
[root@study ~]# chcon -v --reference=/etc/shadow /etc/cron.d/checktime
[root@study ~]# ll -Z /etc/shadow /etc/cron.d/checktime
-rw-r--r--. root root system_u:object_r:shadow_t:s0 /etc/cron.d/checktime
----------. root root system_u:object_r:shadow_t:s0 /etc/shadow
使用 restorecon 让文件恢复正确的 SELinux type
让 SELinux 自己解决默认目录下的 SELinux type 的问题。
[root@study ~]# restorecon [-Rv] 文件或目录
选项与参数:
-R :连同次目录一起修改;
-v :将过程显示到屏幕上
范例三:将 /etc/cron.d/ 底下的文件通通恢复成预设的 SELinux type!
[root@study ~]# restorecon -Rv /etc/cron.d
restorecon reset /etc/cron.d/checktime context system_u:object_r:shadow_t:s0->
system_u:object_r:system_cron_spool_t:s0
# 上面这两行其实是同一行喔!表示将 checktime 由 shadow_t 改为 system_cron_spool_t
范例四:重新启动 crond 看看有没有正确启动 checktime 啰!?
[root@study ~]# systemctl restart crond
[root@study ~]# tail /var/log/cron
# 再去瞧瞧这个 /var/log/cron 的内容,应该就没有错误讯息了
restorecon 主动的恢复预设的 SELinux type 十分便捷;而且可以一口气恢复整个目录下的文件。
所以,建议你几乎只要记得 restorecon 搭配-Rv 同时加上某个目录这样的指令串即可~修改 SELinux 的 type 就变得非常的轻松 。
semanage 默认目录的安全性本文查询与修改
为什么 restorecon 可以『恢复』原本的 SELinux type ?
那肯定就是有个地方在纪录每个文件/目录的 SELinux 默认类型 。
可以通过semanage
- 查询预设的 SELinux type
- 增加/修改/删除预设的 SELinux type
[root@study ~]# semanage {login|user|port|interface|fcontext|translation} -l
[root@study ~]# semanage fcontext -{a|d|m} [-frst] file_spec
选项与参数:
fcontext :主要用在安全性本文方面的用途, -l 为查询的意思;
-a :增加的意思,你可以增加一些目录的默认安全性本文类型设定;
-m :修改的意思;
-d :删除的意思。
范例一:查询一下 /etc /etc/cron.d 的预设 SELinux type 为何?
[root@study ~]# semanage fcontext -l | grep -E '^/etc |^/etc/cron'
SELinux fcontext type Context
/etc all files system_u:object_r:etc_t:s0
/etc/cron\.d(/.*)? all files system_u:object_r:system_cron_spool_t:s0
看到上面输出的最后一行,那也是为啥我们直接使用 vim 去 /etc/cron.d 底下建立新文件时,预设的SELinux type 就是正确的 ;
同时,我们也会知道使用 restorecon 回复正确的 SELinux type 时,系统会去判断默认的类型为何的依据。
假如 (当然是假的!不可能这么干) 我们要建立一个 /srv/mycron 的目录,这个目录默认也是需要变成system_cron_spool_t 时,可以如下操作:
# 1. 先建立 /srv/mycron 同时在内部放入配置文件,同时观察 SELinux type
[root@study ~]# mkdir /srv/mycron
[root@study ~]# cp /etc/cron.d/checktime /srv/mycron
[root@study ~]# ll -dZ /srv/mycron /srv/mycron/checktime
drwxr-xr-x. root root unconfined_u:object_r:var_t:s0 /srv/mycron
-rw-r--r--. root root unconfined_u:object_r:var_t:s0 /srv/mycron/checktime
# 2. 观察一下上层 /srv 的 SELinux type
[root@study ~]# semanage fcontext -l | grep '^/srv'
SELinux fcontext type Context
/srv all files system_u:object_r:var_t:s0
# 怪不得 mycron 会是 var_t 啰!
# 3. 将 mycron 默认值改为 system_cron_spool_t 啰!
[root@study ~]# semanage fcontext -a -t system_cron_spool_t "/srv/mycron(/.*)?"
[root@study ~]# semanage fcontext -l | grep '^/srv/mycron'
SELinux fcontext type Context
/srv/mycron(/.*)? all files system_u:object_r:system_cron_spool_t:s0
# 4. 恢复 /srv/mycron 以及子目录相关的 SELinux type 喔!
[root@study ~]# restorecon -Rv /srv/mycron
[root@study ~]# ll -dZ /srv/mycron /srv/mycron/*
drwxr-xr-x. root root unconfined_u:object_r:system_cron_spool_t:s0 /srv/mycron
-rw-r--r--. root root unconfined_u:object_r:system_cron_spool_t:s0 /srv/mycron/checktime
# 有了默认值,未来就不会不小心被乱改了!这样比较妥当些~
如上所示, 你可以使用 semanage 来查询所有的目录默认值,也能够使用他来增加默认值的设定 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号