一个字符的String.length()为什么不一定等于1
参考文章:https://juejin.im/post/5e0e0bc66fb9a047eb2d335d?utm_source=gold_browser_extension
从文章中我们知道,java内码是是使用unicode(utf-16),而unicode的字符范围是U+0000-U+FFFF。
utf-16指的是16 位一个单元(一单元=两字节),当字符内容超出U+FFFF时,就会以两个单元(四个字符)保存。
public class testStringLength {
public static void main(String[] args) {
String B = "𝄞";
System.out.println(B.length());//2
}
}
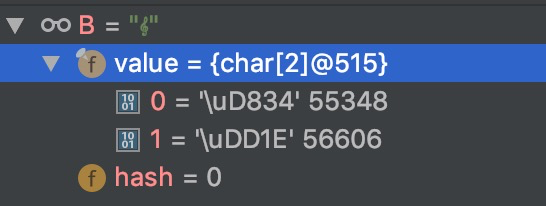
这里B.length()输出2是因为字符(U+1D11E)号超出出U+FFFF,因此会拆成两个U+D834、U+DD1E来记录,而通过length源码我们知道他是通过unicode来判断长度的,所以才会输出2。
/**
* Returns the length of this string.
* The length is equal to the number of <a href="Character.html#unicode">Unicode
* code units</a> in the string.
*
* @return the length of the sequence of characters represented by this
* object.
*/
public int length() {
return value.length;
}
那我们如何获取长度呢?文中是使用codePointCount
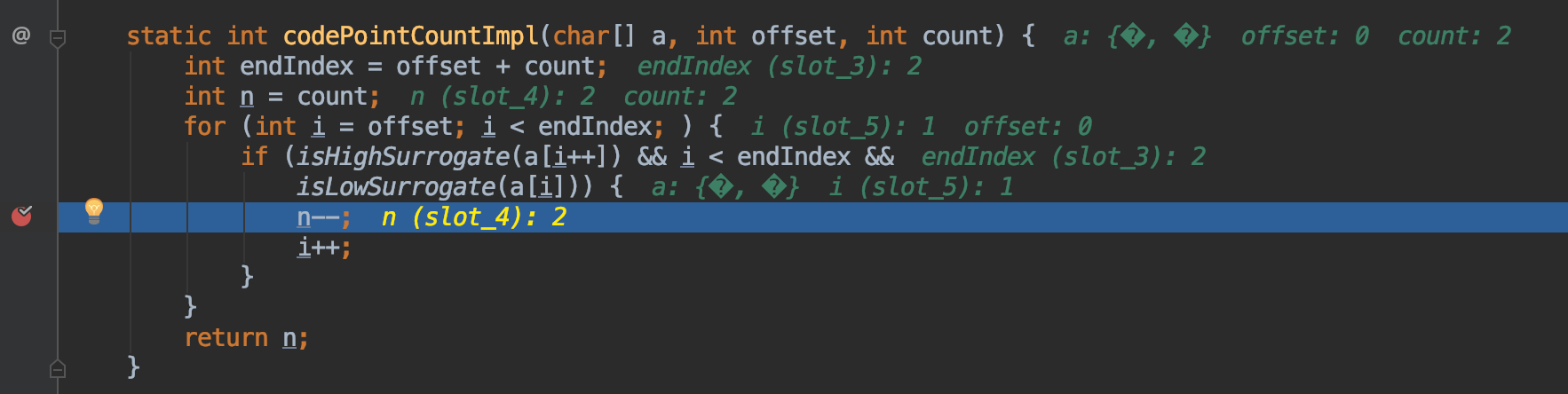
为了解决超出U+FFFF时的问题,Unicode制定了Surrogate(代理单元)这个概念,通过定义U+D800至U+DBFF為「High Surrogates」,U+DC00至U+DFFF為「Low Surrogates」,一共2048个。
那么在超出U+FFFF时,就拆分为两个单元定义(前者高代理,后者低代理),如果符合条件就识别为代理单元。
这里我们看到,使用isHighSurrogate判断U+D834高代理,isLowSurrogate判断U+DD1E低代理,同时满足即为代理单元,那就长度n直接-1,因此获取到我们需要的长度值1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号