
DataFrame 去重,指定列去重drop_duplicates
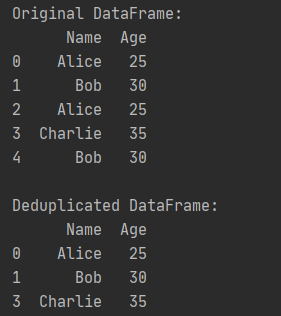
import pandas as pd # 创建示例 DataFrame data = { 'Name': ['Alice', 'Bob', 'Alice', 'Charlie', 'Bob'], 'Age': [25, 30, 25, 35, 30] } df = pd.DataFrame(data) # 去重操作 deduplicated_df = df.drop_duplicates() print("Original DataFrame:") print(df) print("\nDeduplicated DataFrame:") print(deduplicated_df)
import pandas as pd # 创建示例 DataFrame data = { 'Name': ['Alice', 'Bob', 'Alice', 'Charlie', 'Bob'], 'Age': [25, 30, 25, 35, 30], 'Location': ['NY', 'CA', 'NY', 'TX', 'CA'] } df = pd.DataFrame(data) # 在 'Name' 和 'Location' 列上进行去重 deduplicated_df = df.drop_duplicates(subset=['Name', 'Location']) print("Original DataFrame:") print(df) print("\nDeduplicated DataFrame:") print(deduplicated_df)

本文来自博客园,作者:OTAKU_nicole,转载请注明原文链接:https://www.cnblogs.com/nicole-zhang/p/17614333.html

