纯干货无广告,毕业大论文,如何优雅地拼拼凑凑,降重和润色
拼拼凑凑
风格选定
风格1
风格2
风格3
实例(使用GPT翻译成中文)
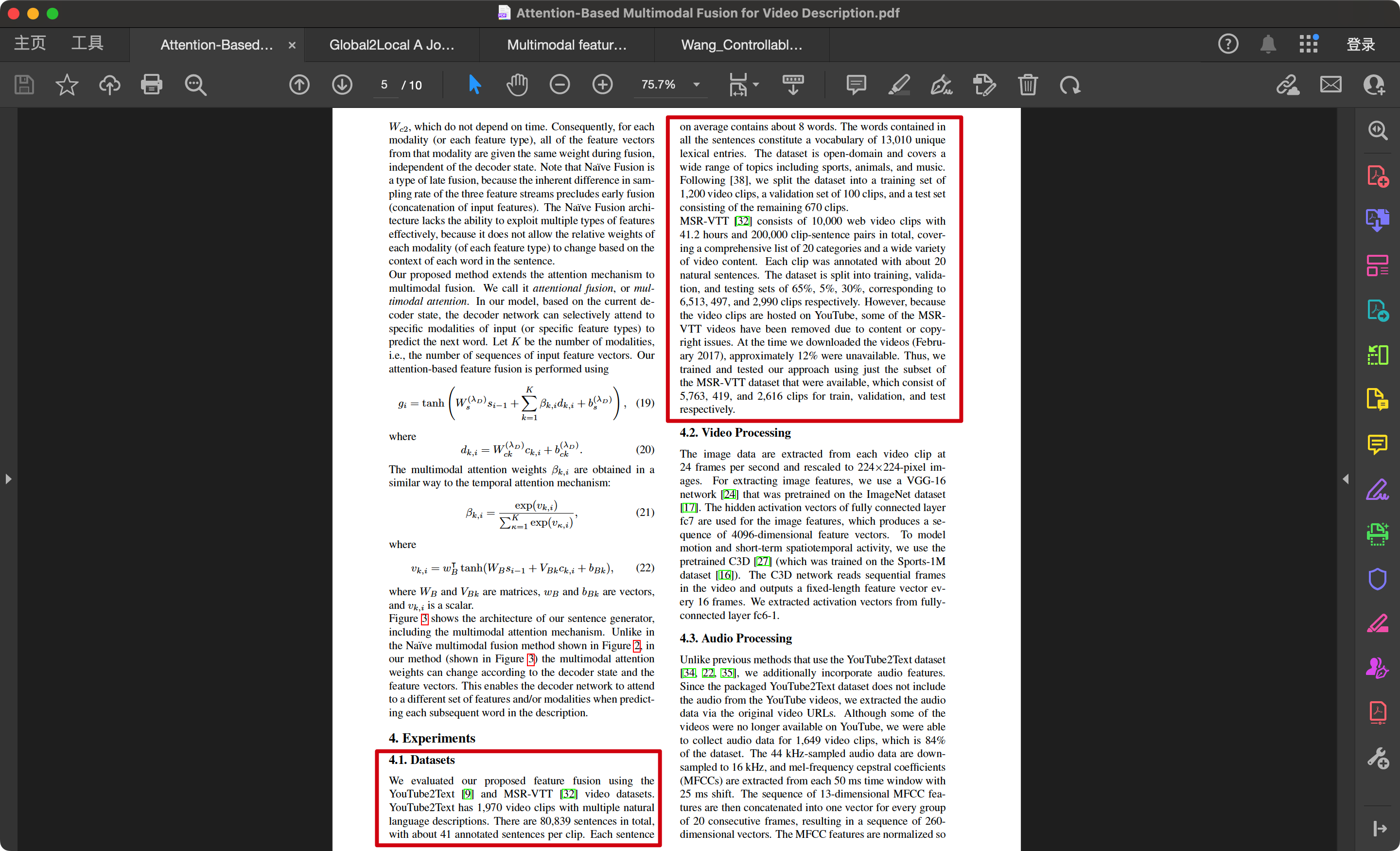
Attention-Based Multimodal Fusion for Video Description(1)
我们使用YouTube2Text [9] 和 MSR-VTT [32] 视频数据集评估了我们提出的特征融合方法。YouTube2Text包含……
MSR-VTT [32] 包含10,000个网络视频片段,总时长为41.2小时,并提供了200,000个片段-句子对,涵盖了20个类别以及各种类型的视频内容。每个片段平均有大约20个自然语言句子注释。该数据集被分为训练集、验证集和测试集,比例为65%、5%、30%,对应于6,513个、497个和2,990个视频片段。然而,由于这些视频片段托管于YouTube上,部分MSR-VTT视频由于内容或版权问题已被删除。在我们下载这些视频(2017年2月)时,约12%不可用。因此,我们只使用了可用的MSR-VTT数据集子集进行训练和测试,具体为训练集5,763个片段、验证集419个片段和测试集2,616个片段。
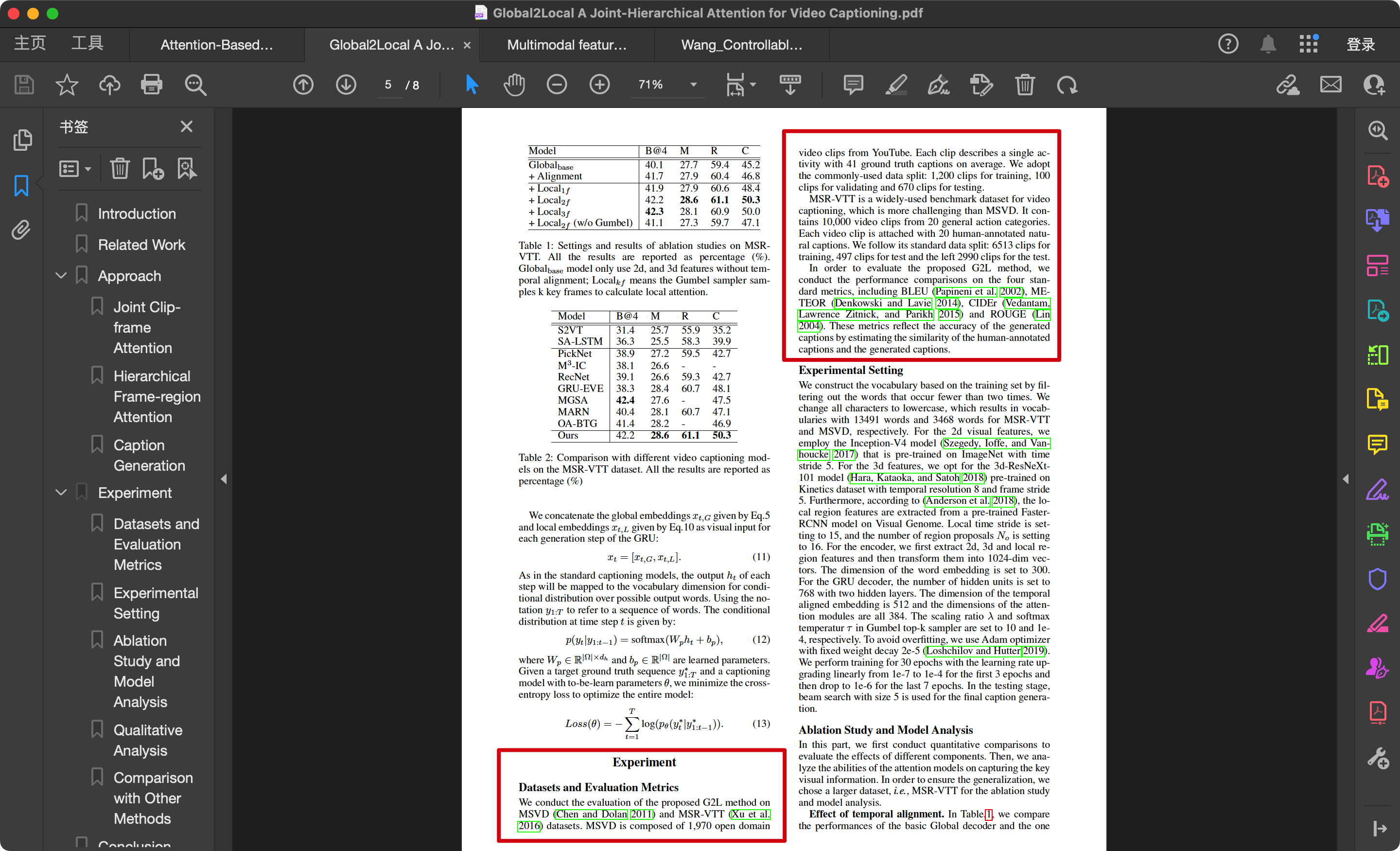
Global2Local: A Joint-Hierarchical Attention for Video Captioning(2)
我们在MSVD(Chen 和 Dolan 2011)和 MSR-VTT(Xu 等 2016)数据集上对提出的G2L方法进行了评估。MSVD由……
MSR-VTT是一个广泛使用的视频字幕生成基准数据集,比MSVD更具挑战性。它包含来自20个通用动作类别的10,000个视频片段。每个视频片段附有20个人工标注的自然字幕。我们遵循其标准的数据划分:6,513个片段用于训练,497个片段用于测试,剩余2,990个片段也用于测试。
Multimodal feature fusion based on object relation for video captioning(3)
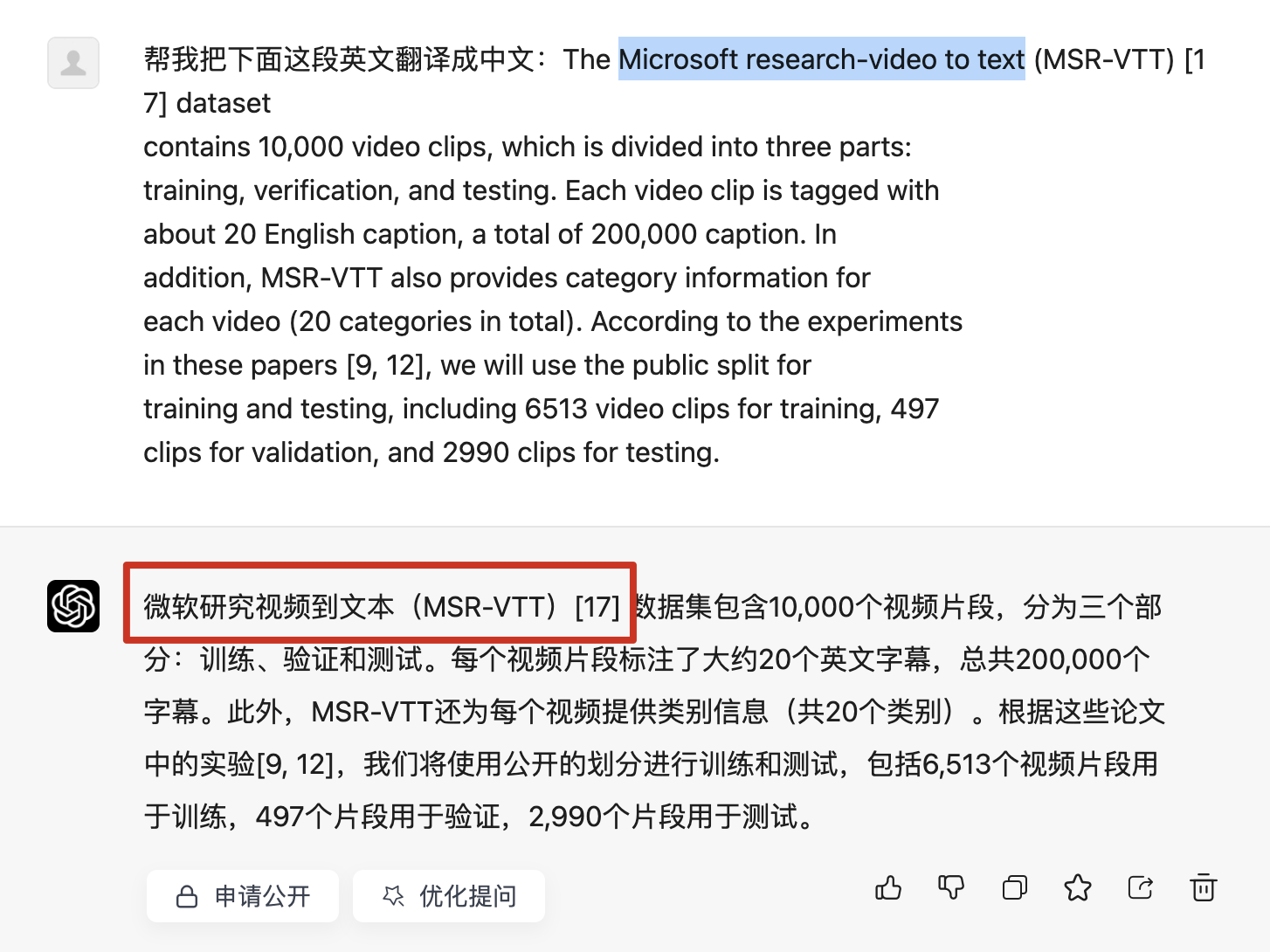
微软研究视频到文本(翻译的结果,但是这是有问题的)Microsoft research‐video to text(MSR-VTT)[17] 数据集包含10,000个视频片段,分为三个部分:训练、验证和测试。每个视频片段标注了大约20个英文字幕,总共200,000个字幕。此外,MSR-VTT还为每个视频提供类别信息(共20个类别)。根据这些论文中的实验[9, 12],我们将使用公开的划分进行训练和测试,包括6,513个视频片段用于训练,497个片段用于验证,2,990个片段用于测试。
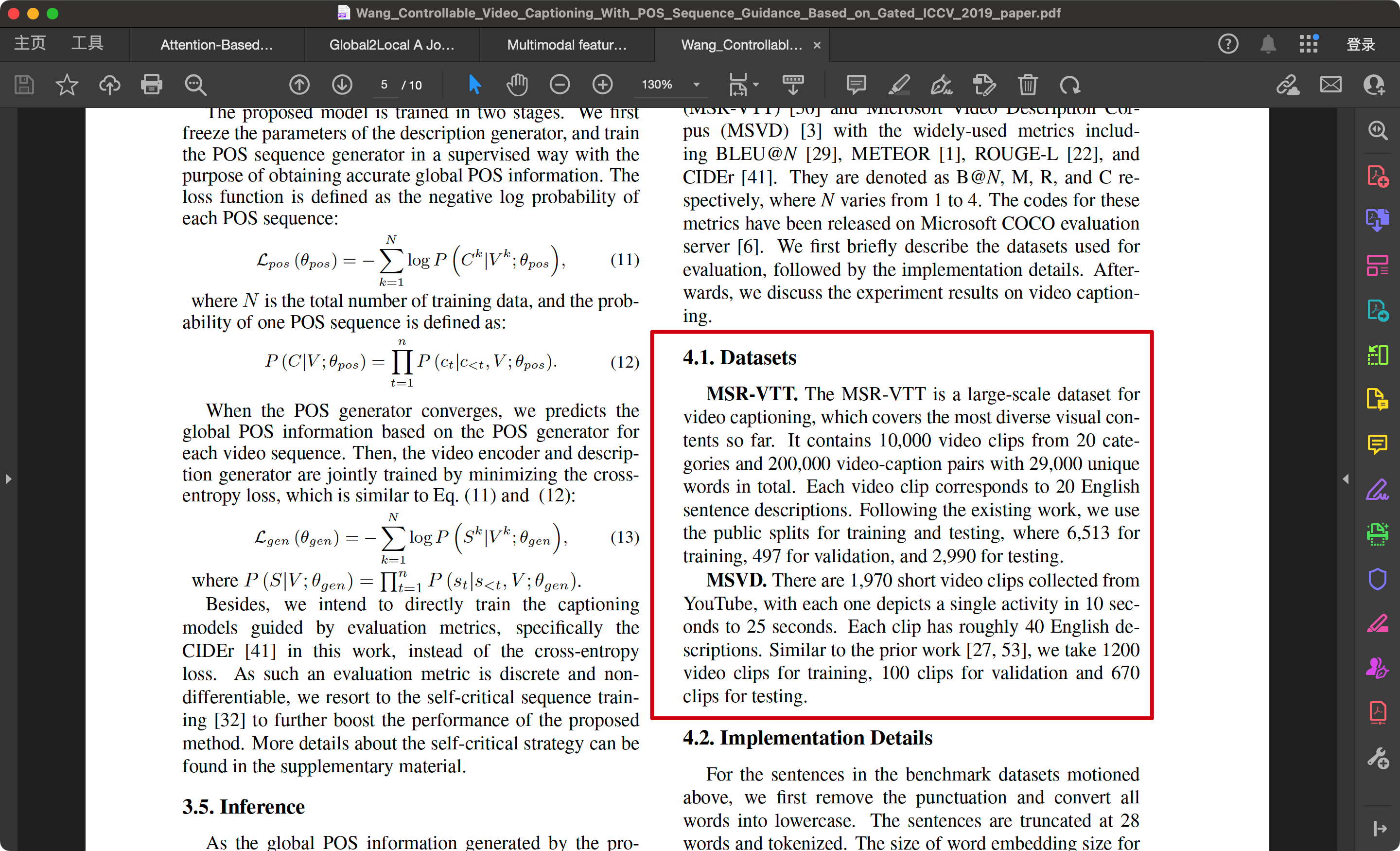
Controllable Video Captioning with POS Sequence Guidance Based on Gated Fusion Network(4)
MSR-VTT是一个用于视频字幕生成的大规模数据集,涵盖了迄今为止最为多样的视觉内容。它包含来自20个类别的10,000个视频片段和200,000个视频-字幕对,总共包含29,000个独特的单词。每个视频片段对应20个英文句子描述。按照现有的工作,我们使用公开的数据划分进行训练和测试,其中6,513个用于训练,497个用于验证,2,990个用于测试。
拼拼凑凑(手动拼凑)
我们使用YouTube2Text [9] 和 MSR-VTT [32] 视频数据集(1)对提出的G2L方法进行了评估。MSVD由……(2)
Microsoft research‐video to text(MSR-VTT)[17] 数据集包含10,000个视频片段,(3)和200,000个视频-字幕对,总共包含29,000个独特的单词。(4)根据这些论文中的实验[9, 12],(3)该数据集被分为训练集、验证集和测试集,(1)其中6,513个【视频片段】用于训练,497【视频片段】个用于验证,2,990个【视频片段】用于测试。(4)然而,由于这些视频片段托管于YouTube上,部分MSR-VTT视频由于内容或版权问题已被删除。在我们下载这些视频(2017年2月)时,约12%不可用。因此,我们只使用了可用的MSR-VTT数据集子集进行训练和测试,具体为训练集5,763个片段、验证集419个片段和测试集2,616个片段。(1)
注意:黄色标注的那一个片段名堂就多了,哪些视频因为内容或者版权问题被删除,亦或者说部分视频找不到,鬼都不知道是不是如此,没人去验证,也很难验证。那么把一些评价不好的数据删掉,保留有益的数据集,模型效果必然不错。这也是很多论文对数据集的基本操作,尤其是私有数据集。
拼拼凑凑(GPT直述)
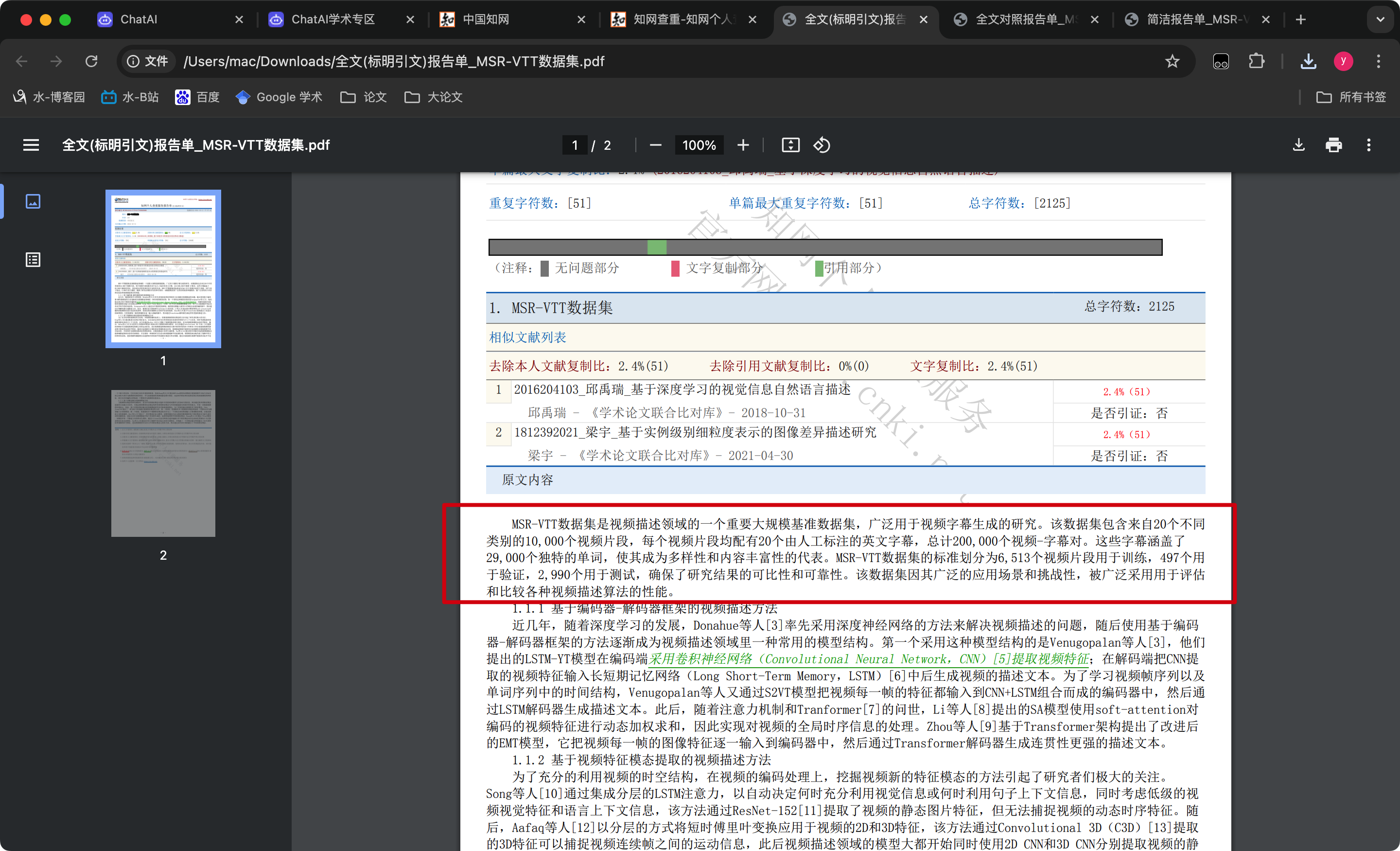
由于知网查重有字数限制,加了一堆没用的文本
知网查重率
0%
AIGC检测率
0%
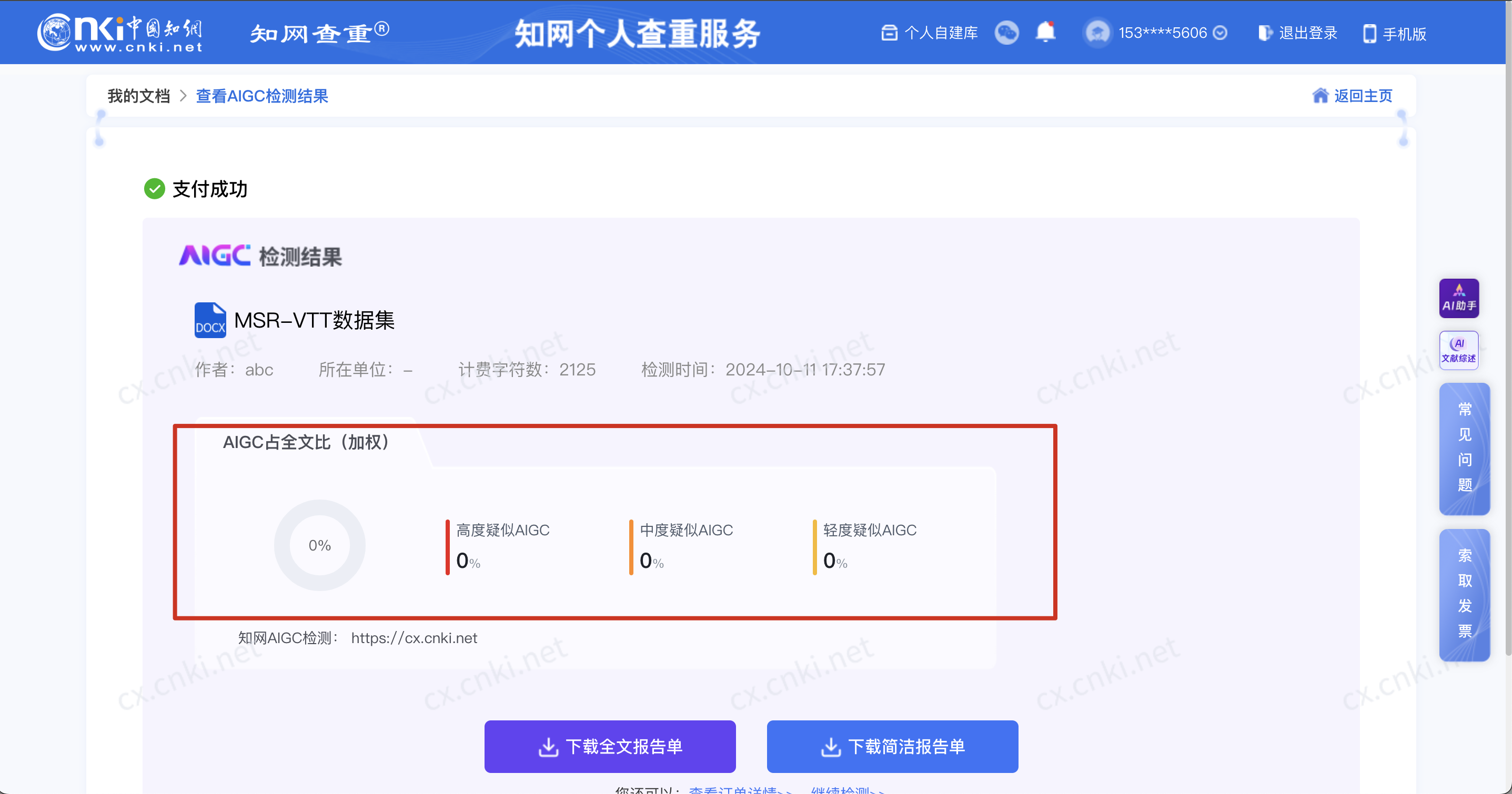
现在知道为什么诺奖颁发给ai了吧,但是不能完全相信AI,尤其是用gpt生成段落之后,一定要再次润色,后文会讲到这一点
查重
普通查重
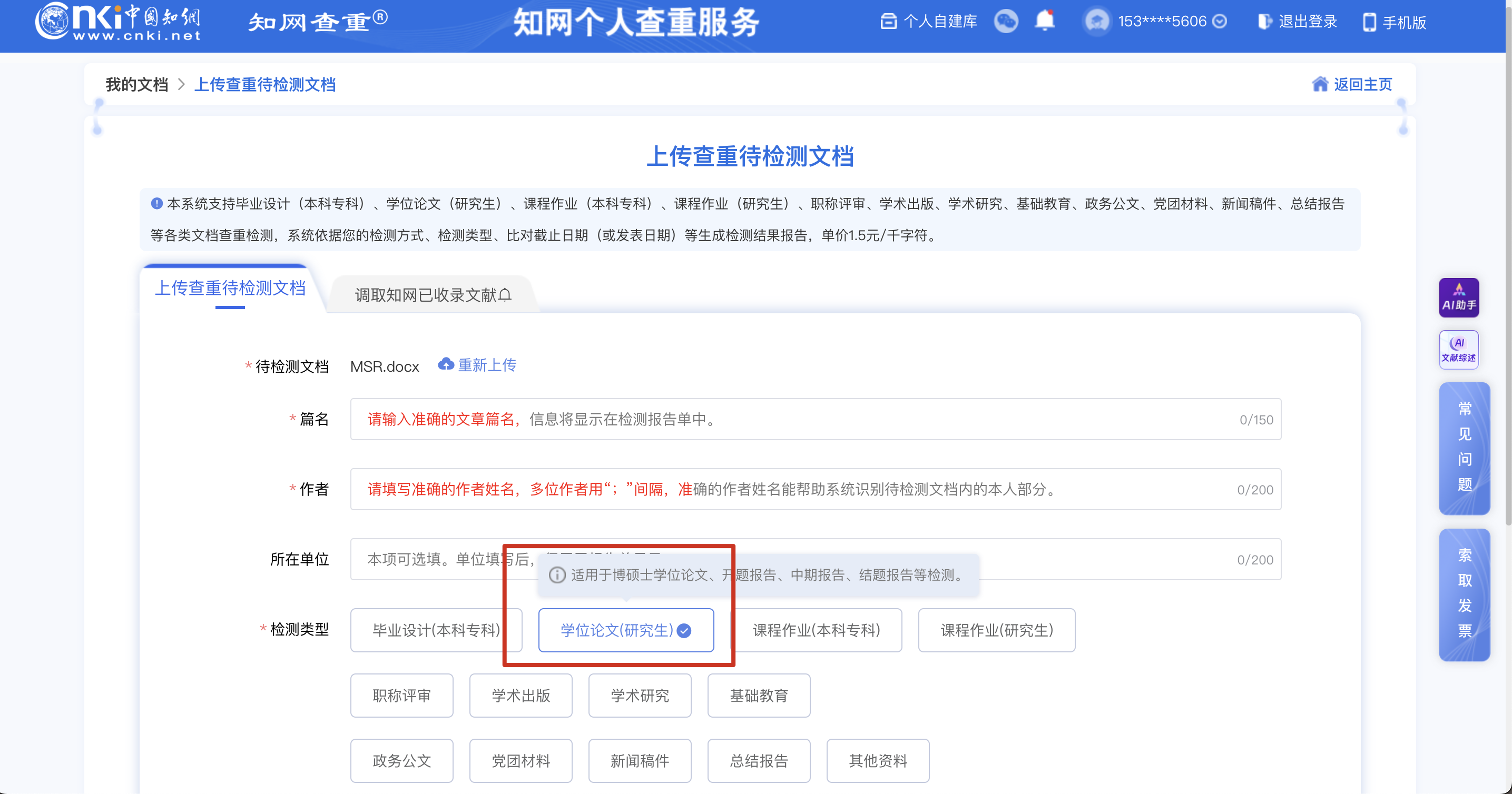
AIGC检测
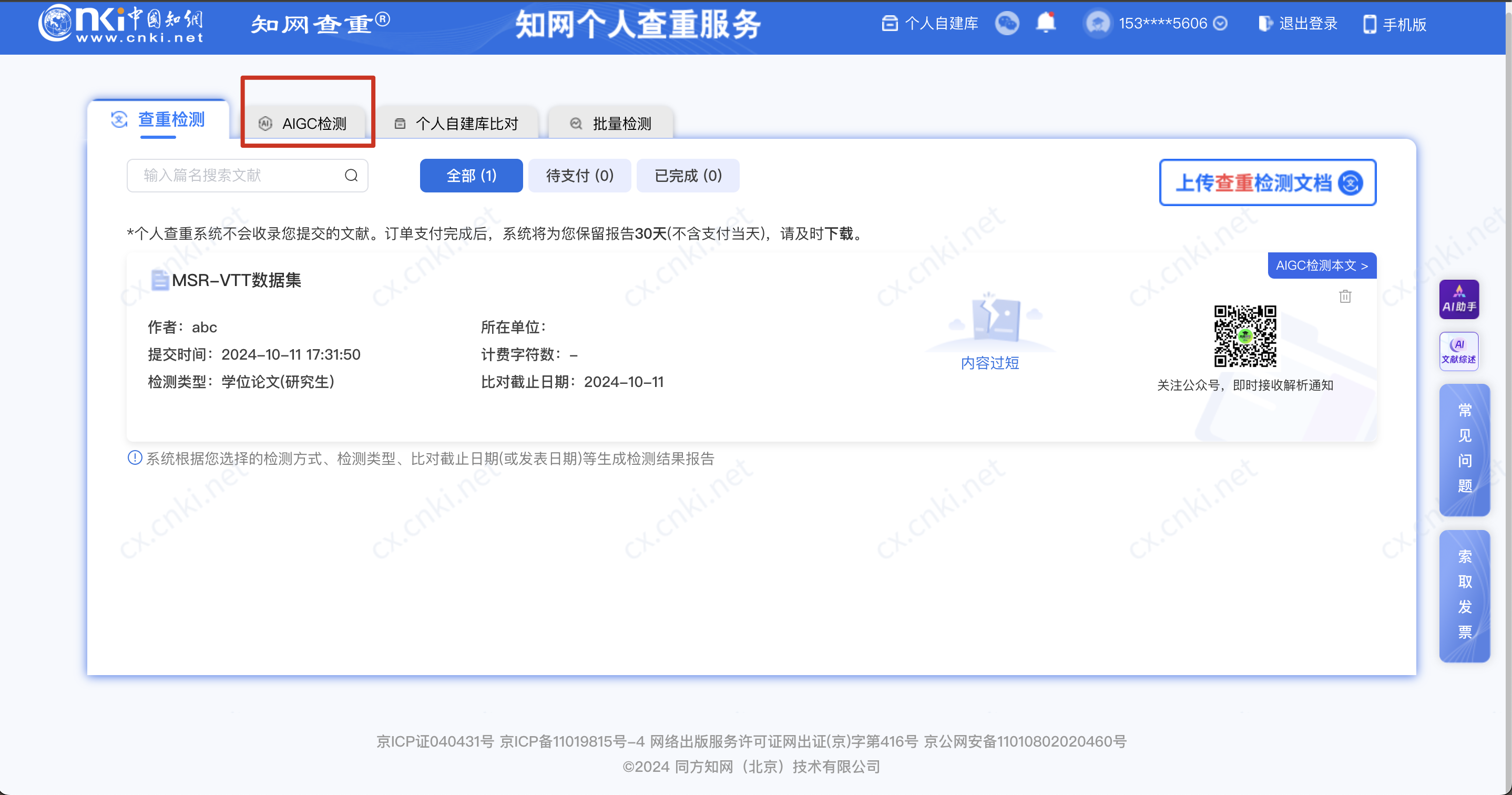
降重
直接使用GPT
直接使用提示词,但是效果不会特别好,建议用后面两种方法
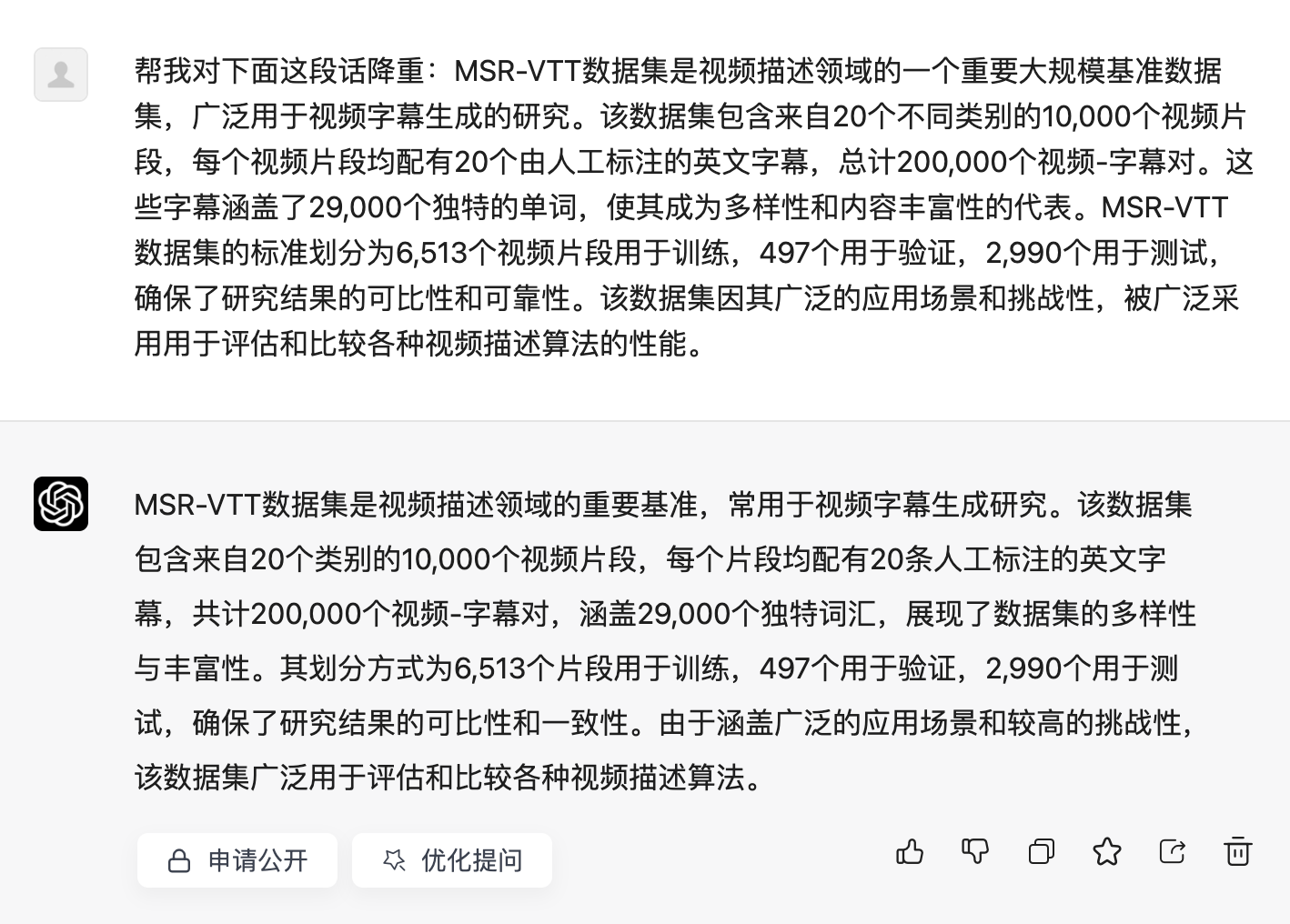
先缩写后扩写
缩写

扩写

中日英互译
中翻日
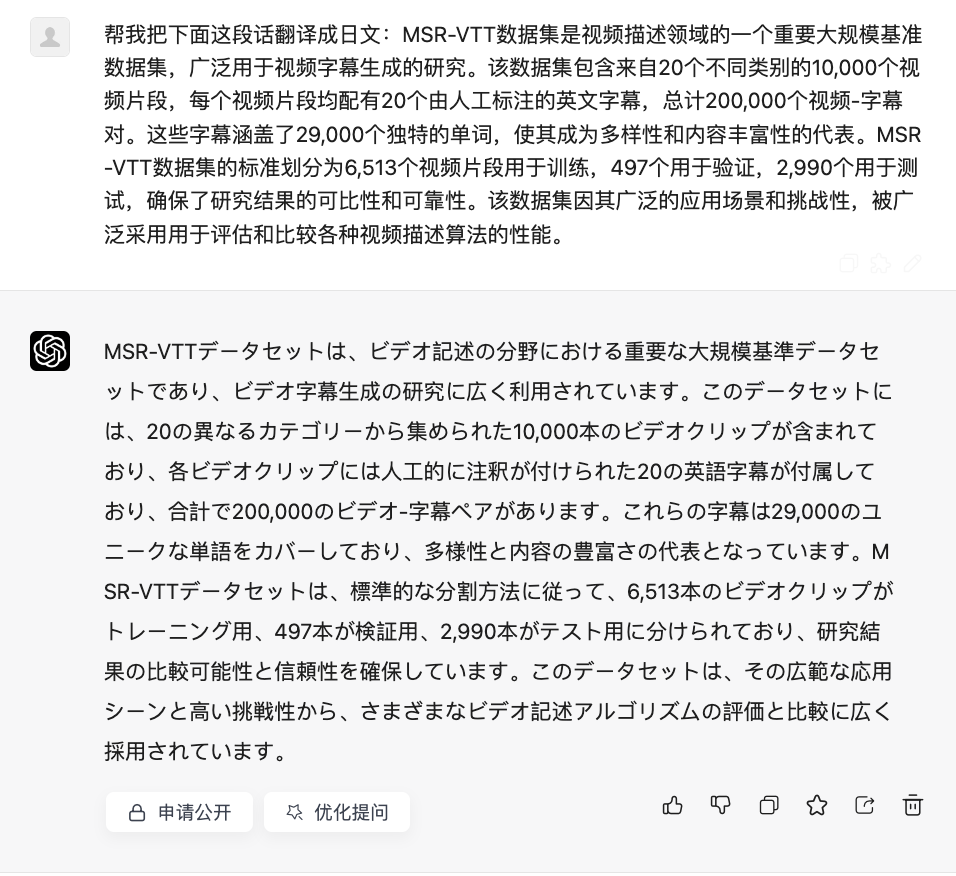
日翻英

英翻中

效果
原:MSR-VTT数据集是视频描述领域的一个重要大规模基准数据集,广泛用于视频字幕生成的研究。该数据集包含来自20个不同类别的10,000个视频片段,每个视频片段均配有20个由人工标注的英文字幕,总计200,000个视频-字幕对。这些字幕涵盖了29,000个独特的单词,使其成为多样性和内容丰富性的代表。MSR-VTT数据集的标准划分为6,513个视频片段用于训练,497个用于验证,2,990个用于测试,确保了研究结果的可比性和可靠性。该数据集因其广泛的应用场景和挑战性,被广泛采用用于评估和比较各种视频描述算法的性能。
将重后:MSR-VTT数据集是一个大规模的基准数据集,在视频描述领域中发挥着重要作用,并且广泛用于视频字幕生成的研究。该数据集包含从20个不同类别中收集的10,000个视频片段,每个片段附有20个人工标注的英文字幕,总计200,000个视频-字幕对。这些字幕涵盖了29,000个独特的单词,代表了高度的多样性和内容丰富性。MSR-VTT数据集根据标准划分为:6,513个视频片段用于训练,497个用于验证,2,990个用于测试,确保了研究结果的可比性和可靠性。由于其广泛的应用范围和高挑战性,该数据集被广泛用于各种视频描述算法的评估和比较。
润色(必须得进行)
GPT润色
自行编辑提示词,按照你的需求来就行。

人工润色(推荐)
将重后:MSR-VTT数据集是一个大规模的基准数据集,在视频描述领域中发挥着重要作用,并且广泛用于视频字幕生成的研究。该数据集包含从20个不同类别中收集的10,000个视频片段,每个片段附有20个人工标注的英文字幕,总计200,000个视频-字幕对。这些字幕涵盖了29,000个独特的单词,代表了高度的多样性和内容丰富性。MSR-VTT数据集根据标准划分为:6,513个视频片段用于训练,497个用于验证,2,990个用于测试,确保了研究结果的可比性和可靠性。由于其广泛的应用范围和高挑战性,该数据集被广泛用于各种视频描述算法的评估和比较。
微软研究视频到文本(翻译的结果,但是这是有问题的)Microsoft research‐video to text(MSR-VTT)[17] 数据集包含10,000个视频片段,分为三个部分:训练、验证和测试。每个视频片段标注了大约20个英文字幕,总共200,000个字幕。此外,MSR-VTT还为每个视频提供类别信息(共20个类别)。根据这些论文中的实验[9, 12],我们将使用公开的划分进行训练和测试,包括6,513个视频片段用于训练,497个片段用于验证,2,990个片段用于测试。
一时半会找不出好的例子,但是上面两段话应该足够了。无论是拼凑的段落,还是GPT润色后的段落,都要进行人工润色:一般就是对专业词进行修改,通读一两遍保证逻辑顺畅,尤其是要保证上下文的逻辑顺畅
不可否认的是,GPT很强大,特别强大,但一定要人工润色!
不可否认的是,GPT很强大,特别强大,但一定要人工润色!!
不可否认的是,GPT很强大,特别强大,但一定要人工润色!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号