16 Transformer 的编码器(Encodes)——我在做更优秀的词向量
Transformer 框架
seq(编码器)2seq(解码器)
- 通过编码器对序列进行向量化(词向量)
- 把词向量输入到解码器,得到结果(生成单词)
编码器概略图
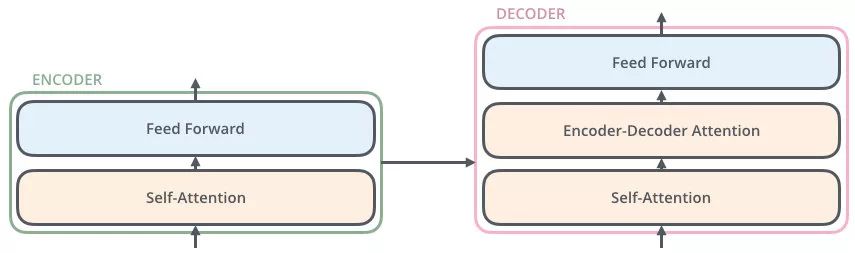
编码器包括两个子层,Self-Attention、Feed Forward
每一个子层的传输过程中都会有一个(残差网络+归一化)
编码器详细图

Thinking
--》得到绿色的 x1(词向量,可以通过 one-hot、word2vec 得到)+ 叠加位置编码(给 x1 赋予位置属性)得到黄色的 x1
--》输入到 Self-Attention 子层中,做注意力机制(x1、x2 拼接起来的一句话做),得到 z1(x1 与 x1,x2拼接起来的句子做了自注意力机制的词向量,表征的仍然是 thinking),也就是说 z1 拥有了位置特征、句法特征、语义特征的词向量
--》残差网络(避免梯度消失,w3(w2(w1x+b1)+b2)+b3,如果 w1,w2,w3 特别小,0.0000000000000000……1,x 就没了,【w3(w2(w1x+b1)+b2)+b3+x】),归一化(LayerNorm),做标准化(避免梯度爆炸),得到了深粉色的 z1
--》Feed Forward,Relu(w2(w1x+b1)+b2),(前面每一步都在做线性变换,wx+b,线性变化的叠加永远都是线性变化(线性变化就是空间中平移和扩大缩小),通过 Feed Forward中的 Relu 做一次非线性变换,这样的空间变换可以无限拟合任何一种状态了),得到 r1(是 thinking 的新的表征)
总结下(这是重点,上面听不懂都没关系):做词向量,只不过这个词向量更加优秀,让这个词向量能够更加精准的表示这个单词、这句话

 浙公网安备 33010602011771号
浙公网安备 33010602011771号