05 神经网络语言模型(独热编码+词向量的起源)
统计语言模型
统计+语言模型--》用统计的方法去完成以下两个和人说的话相关的任务
语言模型 = 语言(人说的话) + 模型(去完成两个任务)
- 比较,“词性”,“磁性”
- 预测下一个单词(填空)
n 元语言模型
取 a(2,3,4) 个词
神经网络语言模型
神经网络+语言模型--》用神经网络的方法去完成以下两个和人说的话相关的任务。
第二个任务:
“判断”,“一个”,“词”,“的”,“___”
假设词库里有“词性”和“火星”
P(__|“判断”,“一个”,“词”,“的”)
词性
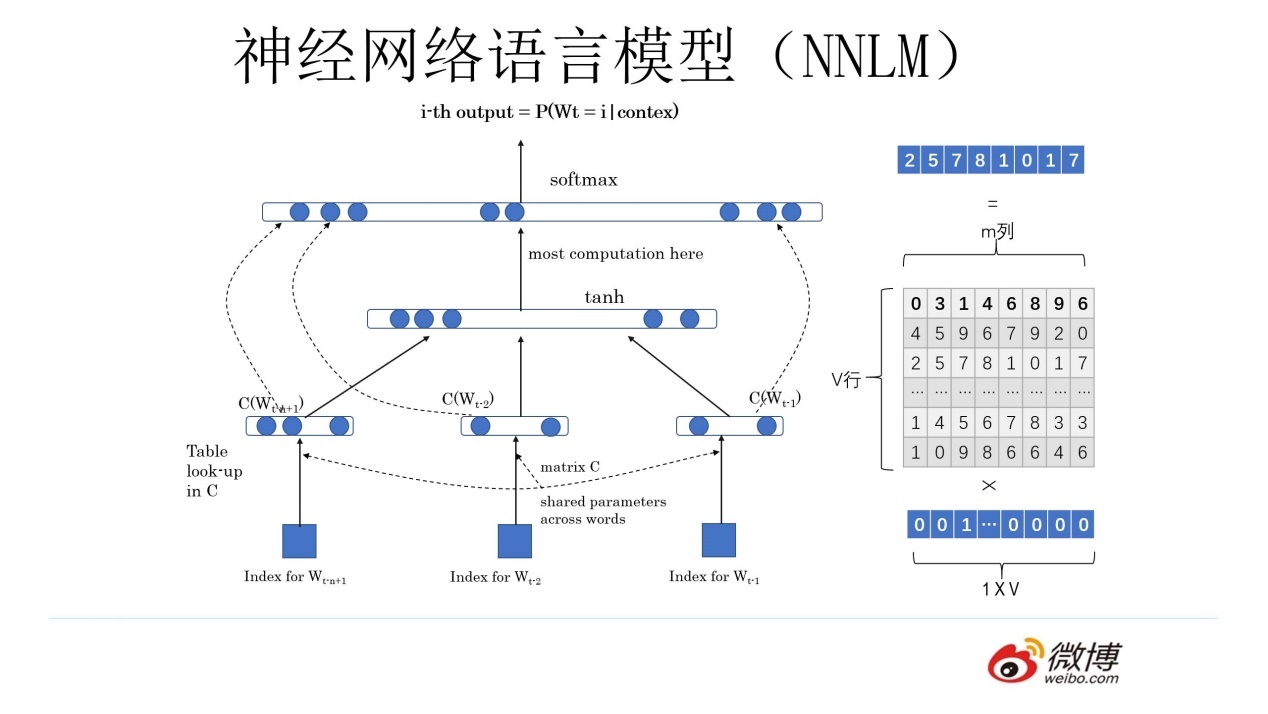
w1,w2,w3,w4(上述 4 个单词的独热编码)
w1*Q=c1,
w2*Q=c2,
w3*Q=c3,
w4*Q=c4,
C=[c1,c2,c3,c4]
Q就是一个随机矩阵,是一个参数(可学习)
“判断”,“这个”,“词”,“的”,“词性”
softmax(U[tanh(WC+b1)]+b2)== [0.1, 0.1, 0.2, 0.2, 0.4] \(\in[1,V_L]\)
独热编码 (one-hot 编码)
独热编码:让计算机认识单词
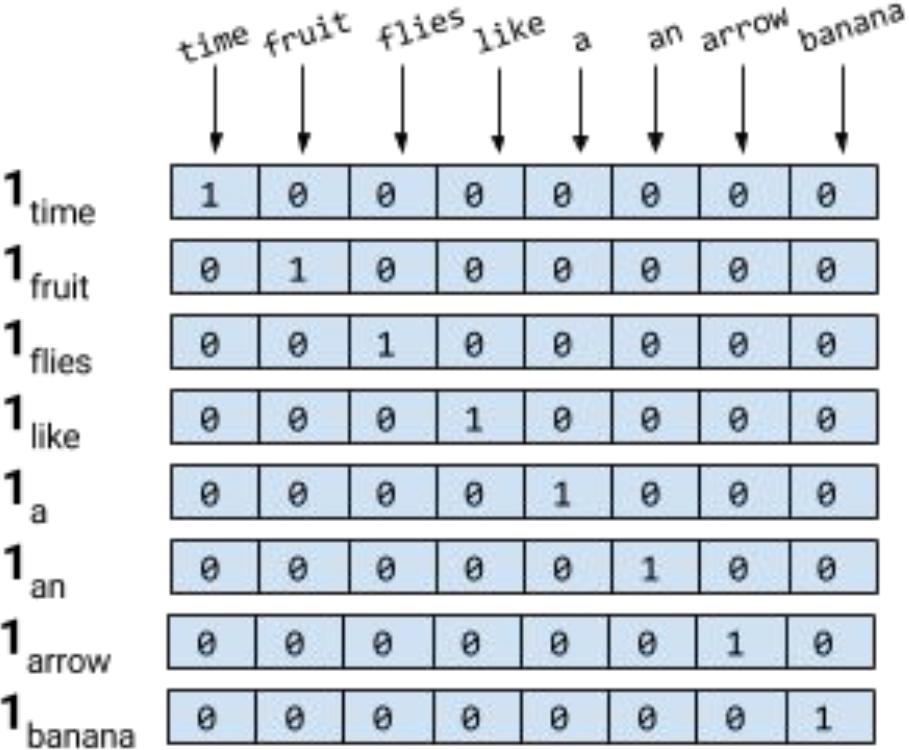
词典 V(新华字典里面把所有词集合成一个集合 V)
假设词典里面只有 8 个单词
计算机不认识单词的
但是我们要计算机认识单词
“fruit”
独热编码:给出一个 8*8 的矩阵
“time” --》 10000000
“fruit” --》 01000000
“banana” --》 00000001
余弦相似度 去计算两者的相似度(0)--词向量(矩阵乘法)
词向量(神经网络语言模型的副产品 Q)
给我任何一个词,
“判断” --》 独热编码w1 [1,0,0,0,0]
w1*Q =c1 (“判断”这个词的词向量)
词向量:就是用一个向量来表示一个单词
可以控制词向量的维度(大小)
如果我们得到的词向量,第一个问题也被解决了,(下游任务)
总结
神经网络语言模型:通过神经网络解决两个人说的话的问题
有一个副产品:Q 矩阵--》新的词向量(词向量可以选择词向量的维度,可以求两个词之间的相似程度)
下游任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号