0902-用GAN生成动漫头像
0902-用GAN生成动漫头像
pytorch完整教程目录:https://www.cnblogs.com/nickchen121/p/14662511.html
一、概述
本节将通过 GAN 实现一个生成动漫人物头像的例子。
在日本的技术博客网站上有个博主,利用 DCGAN 从 20 万张动漫头像中学习,最终能够利用程序自动生成动漫头像。源程序是利用 Chainer 框架实现的,在这里我们将尝试利用 Pytorch 实现。
原始的图片是从网站中采集的,并利用 OpenCV 截取头像,处理起来非常麻烦。因此我们在这里通过之乎用户 何之源 爬取并经过处理的 5 万张图片,想要图片的百度网盘链接的可以加我微信:chenyoudea。需要注意的是,这里图片的分辨率是 3×96×96,而不是论文中的 3×64×64,因此需要相应地调整网络结构,使生成图像的尺寸为 96。
二、代码结构
下面我们首先来看下我们未来的一个代码结构。
checkpoints/ # 无代码,用来保存模型
imgs/ # 无代码,用来保存生成的图片
data/ # 无代码,用来保存训练所需要的图片
main.py # 训练和生成
model.py # 模型定义
visualize.py # 可视化工具 visdom 的开发
requirement.txt # 程序中用到的第三方库
README.MD # 说明
三、model.py
model.py 主要是用来定义生成器和判别器的。
3.1 生成器
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Coding by https://www.cnblogs.com/nickchen121/
# Datatime:2021/5/10 10:37
# Filename:model.py
# Toolby: PyCharm
from torch import nn
class NetG(nn.Module):
"""
生成器定义
"""
def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器 feature map 数
self.main = nn.Sequential(
# 输入是 nz 维度的噪声,可以认识它是一个 nz*1*1 的 feature map
# H_{out} = (H_{in}-1)*stride - 2*padding + kernel_size
# 以下面一行代码的ConvTranspose2d举例(初始 H_{in}=1):H_{out} = (1-1)*1-2*0+4 = 4
nn.ConvTranspose2d(opt.nz, ngf * 8, (4, 4), (1, 1), (0, 0), bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 上一步的输出形状:(ngf*8)*4*4,其中(ngf*8)是输出通道数,4 为 H_{out} 是通过上述公式计算出来的
# 以下面一行代码的ConvTranspose2d举例(初始 H_{in}=4):H_{out} = (4-1)*2-2*1+4 =8
nn.ConvTranspose2d(ngf * 8, ngf * 4, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 上一步的输出形状:(ngf*4)*8*8
nn.ConvTranspose2d(ngf * 4, ngf * 2, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 上一步的输出形状是:(ngf*2)*16*16
nn.ConvTranspose2d(ngf * 2, ngf, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的输出形状:(ngf)*32*32
nn.ConvTranspose2d(ngf, 3, (5, 5), (3, 3), (1, 1), bias=False),
nn.Tanh()
# 输出形状:3*96*96
)
def forward(self, inp):
return self.main(inp)
从上述生成器的代码可以看出生成器的构建比较简单,直接用 nn.Sequential 把上卷积、激活等操作拼接起来就行了。这里稍微注意下 ConvTranspose2d 的使用,当 kernel size 为 4、stride 为 2、padding 为 1 时,根据公式 \(H_{out} = (H_{in}-1)*stride - 2*padding + kernel_size\),输出尺寸刚好变成输入的两倍。
最后一层我们使用了 tanh 把输出图片的像素归一化至 -1~1,如果希望归一化到 0~1,可以使用 sigimoid 方法。
3.2 判别器
class NetD(nn.Module):
"""
判别器定义
"""
def __init__(self, opt):
super(NetD, self).__init__()
ndf = opt.ndf
self.main = nn.Sequential(
# 输入 3*96*96
nn.Conv2d(3, ndf, (5, 5), (3, 3), (1, 1), bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf)*32*32
nn.Conv2d(ndf, ndf * 2, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*2)*16*16
nn.Conv2d(ndf * 2, ndf * 4, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*4)*8*8
nn.Conv2d(ndf * 4, ndf * 8, (4, 4), (2, 2), (1, 1), bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*8)*4*4
nn.Conv2d(ndf * 8, 1, (4, 4), (1, 1), (0, 0), bias=False),
nn.Sigmoid() # 输出一个数:概率
)
def forward(self, inp):
return self.main(inp).view(-1)
从上述代码可以看到判别器和生成器的网络结构几乎是对称的,从卷积核大小到 padding、stride 等设置,几乎一模一样。
需要注意的是,生成器的激活函数用的是 ReLU,而判别器使用的是 LeakyReLU,两者其实没有太大的区别,这种选择更多的是经验的总结。
判别器的最终输出是一个 0~1 的数,表示这个样本是真图片的概率。
四、参数配置
在开始写训练函数前,我们可以先配置模型参数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Coding by https://www.cnblogs.com/nickchen121/
# Datatime:2021/5/11 15:14
# Filename:config.py
# Toolby: PyCharm
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = 4 # 多进程加载数据所用的进程数
image_size = 96 # 图片尺寸
batch_size = 256
max_epoch = 200
lr1 = 2e-4 # 生成器的学习率
lr2 = 2e-4 # 判别器的学习率
beta1 = 0.5 # Adam 优化器的 beta1 参数
use_gpu = False # 是否使用 GPU
nz = 100 # 噪声维度
ngf = 64 # 生成器的 feature map 数
ndf = 64 # 判别器的 feature map 数
save_path = 'imgs/' # 生成图片保存路径
vis = True # 是否使用 visdom 可视化
env = 'GAN' # visdom 的 env
plot_every = 20 # 每隔 20 个 batch,visdom 画图一次
debug_file = '/tmp/debuggan' # 存在该文件则进入 debug 模式
d_every = 1 # 每 1 个 batch 训练一次判别器
g_every = 5 # 每 5 个 batch 训练一次生成器
decay_everty = 10 # 每 10 个 epoch 保存一次模型
save_every = 10 # 每 10个epoch保存一次模型
netd_path = 'checkpoints/netd_211.pth' # 预训练模型
netg_path = 'checkpoints/netg_211.pth'
# 测试时用的参数
gen_img = 'result.png'
# 从 512 张生成的图片路径中保存最好的 64 张
gen_num = 64
gen_search_num = 512
gen_mean = 0 # 噪声的均值
gen_std = 1 # 噪声的方差
opt = Config()
上述这些都只是模型的默认参数,还可以利用 Fire 等工具通过命令行传入,覆盖默认值。
除此之外,还可以使用 opt.atrr,还可以利用 IDE/Python 提供的自动补全功能,十分方便。
上述的超参数大多是照搬 DCGAN 论文的默认值,这些默认值都是坐着经过大量的实验,发现这些参数能够更快地去训练出一个不错的模型。
五、数据处理
当我们下载完数据之后,需要把所有图片放在一文件夹,然后把文件夹移动到 data 目录下(并且要确保 data 下没有其他的文件夹)。使用这种方法是为了能够直接使用 pytorchvision 自带的 ImageFolder 读取图片,而没有必要自己写一个 Dataset。
数据读取和加载的代码如下所示。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Coding by https://www.cnblogs.com/nickchen121/
# Datatime:2021/5/12 09:43
# Filename:dataset.py
# Toolby: PyCharm
import torch as t
import torchvision as tv
from torch.utils.data import DataLoader
from config import opt
# 数据处理,输出规模为 -1~1
transforms = tv.transforms.Compose([
tv.transforms.Scale(opt.image_size),
tv.transforms.CenterCrop(opt.image_size),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据集
dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms)
dataloader = DataLoader(
dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
从上述代码中可以发现,用 ImageFolder 配合 DataLoader 加载图片十分方便。
六、训练
在训练之前,我们还需要定义几个变量:模型、优化器、噪声等。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Coding by https://www.cnblogs.com/nickchen121/
# Datatime:2021/5/10 10:37
# Filename:main.py
# Toolby: PyCharm
import os
import ipdb
import tqdm
import fire
import torch as t
import torchvision as tv
from visualize import Visualizer
from torch.autograd import Variable
from torchnet.meter import AverageValueMeter
from config import opt
from dataset import dataloader
from model import NetD, NetG
def train(**kwargs):
# 定义模型
netd = NetD()
netg = NetG()
# 定义网络
map_location = lambda storage, loc: storage
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
# 定义优化器和损失
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss()
# 真图片 label 为 1,假图片 label 为 0,noises 为生成网络的输入噪声
true_labels = Variable(t.ones(opt.batch_size))
fake_labels = Variable(t.zeros(opt.batch_size))
fix_noises = Variable(t.randn(opt.batch_size, opt.nz, 1, 1))
noises = vars(t.randn(opt.batch_size, opt.nz, 1, 1))
# 如果使用 GPU 训练,把数据转移到 GPU 上
if opt.use_gpu:
netd.cuda()
netg.cuda()
criterion.cuda()
true_labels, fake_labels = true_labels.cuda(), fake_labels.cuda()
fix_noises, noises = fix_noises.cuda(), noises.cuda()
在加载预训练模型的时候,最好指定 map_location。因为如果程序之前在 GPU 上运行,那么模型就会被存成 torch.cuda.Tensor,这样加载的时候会默认把数据加载到显存上。如果运行该程序的计算机中没有 GPU,则会报错,因此指定 map_location 把 Tensor 默认加载到内存上,等有需要的时候再加载到显存中。
下面开始训练网络,训练的步骤如下所示:
- 训练判别器:
- 固定生成器
- 对于真图片,判别器的输出概率值尽可能接近 1
- 对于生成器生成的图片,判别器尽可能输出 0
- 训练生成器
- 固定判别器
- 生成器生成图片,尽可能让判别器输出 1
- 返回第一步,循环交替训练
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = Variable(img)
if opt.use_gpu:
real_img = real_img.cuda()
# 训练判别器
if (ii + 1) % opt.d_every == 0:
optimizer_d.zero_grad()
# 尽可能把真图片判别为 1
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
# 尽可能把假图片判别为 0
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises).detach() # 根据照片生成假图片
fake_ouput = netd(fake_img)
error_d_fake = criterion(fake_ouput, fake_labels)
error_d_fake.backward()
optimizer_d.step()
# 训练生成器
if (ii + 1) % opt.g_every == 0:
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises)
fake_output = netd(fake_img)
# 尽可能让判别器把假图片也判别为 1
error_g = criterion(fake_output, true_labels)
error_g.backward()
optimizer_g.step()
# 可视化
if opt.vis and ii % opt.plot_every == opt.plot_every - 1:
# 定义可视化窗口
vis = Visualizer(opt.env)
if os.path.exists(opt.debug_file):
ipdb.set_trace()
global fix_fake_imgs
fix_fake_imgs = netg(fix_noises)
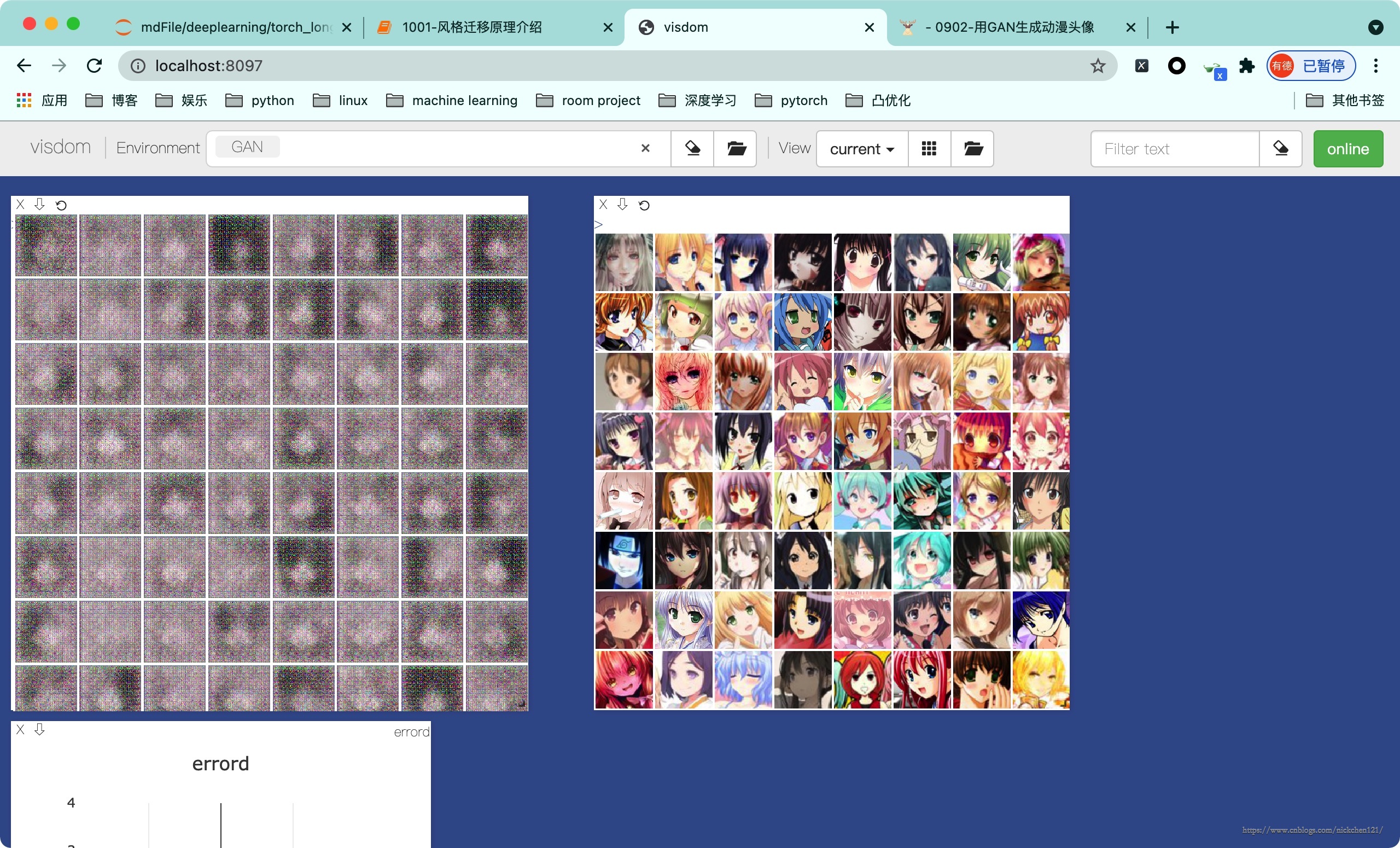
vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake')
vis.images(real_img.data.cpu().numpy()[:64] * 0.5 + 0.5, win='real')
vis.plot('errord', errord_meter.value()[0])
vis.plot('errorg', errorg_meter.value()[0])
if (epoch + 1) % opt.save_every == 0:
# 保存模型、图片
tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True,
range=(-1, 1))
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
errord_meter.reset()
errorg_meter.reset()
在上述训练代码中,需要注意以下几点:
- 训练生成器的时候,不需要调整判别器的参数;训练判别器的时候,也不需要调整生成器的参数
- 在训练判别器的时候,需要对生成器生成的图片用 detach 操作进行计算图截断,避免反向传播把梯度传到生成器中。因为在训练判别器的时候我们不需要训练生成器,也就不需要生成器的梯度。
- 在训练分类器的时候,需要反向传播两次,一次是希望把真图片判为 1,一次是希望把假图片判为 0.也可以把这个两者的数据放到一个 batch 中,进行一次前向传播和一次反向传播即可。但是人们发现,在一个 batch 中只包含真图片或者只包含假图片的做法最好。
- 对于假图片,在训练判别器的时候,我们希望它输出为 0;而在训练生成器的时候,我们希望它输出为 1.因此可以看到一堆相互矛盾的代码:
error_d_fake = criterion(fake_output,fake_labels)和error_g = criterion(fake_output, true_labels)。其实这也很好理解,判别器希望能够把假图片判别为 fake_label,而生成器希望能把它判别为 true_label,判别器和生成器相互对抗提升。 - 其中的 Visualize 模块类似于上一章自己的写的模块,可以直接复制粘贴源码中的代码。
七、随机生成图片
除了上述所示的代码外,还提供了一个函数,能加载预训练好的模型,并且利用噪声随机生成图片。
@t.no_grad()
def generate():
# 定义噪声和网络
netg, netd = NetG(opt), NetD(opt)
noises = t.randn(opt.gen_search_num, opt.nz, 1, 1).normal_(opt.gen_mean, opt.gen_std)
noises = Variable(noises)
# 加载预训练的模型
netd.load_state_dict(t.load(opt.netd_path))
netg.load_state_dict(t.load(opt.netg_path))
# 是否使用 GPU
if opt.use_gpu:
netd.cuda()
netg.cuda()
noises = noises.cuda()
# 生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).data
# 挑选最好的某几张
indexs = scores.topk(opt.gen_num)[1]
result = []
for ii in indexs:
result.append(fake_img.data[ii])
# 保存图片
tv.utils.save_image(t.stack(result), opt.gen_num, normalize=True, range=(-1, 1))
八、训练模型并测试
完整的代码可以添加我微信:chenyoudea,其实上述代码已经很完整了,或者去github https://github.com/chenyuntc/pytorch-book/tree/master/chapter07-AnimeGAN下载。
这里假设你是拥有完整的代码,那么准备好数据后,可以用下面的命令开始训练:
python main.py train --gpu=True --vis=True --batch-size=256 --max-epoch=200
如果使用了 visdom,此时打开 http://localhost:8097 就能看到生成的图像。
训练完成后,我们就可以利用生成网络随机生成动漫头像,输入命令如下:
python main.py generate --gen-img='result.5w.png' --gen-search-num=15000
下图是 10 个 epoch 的展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号