0901-生成对抗网络GAN的原理简介
0901-生成对抗网络GAN的原理简介
pytorch完整教程目录:https://www.cnblogs.com/nickchen121/p/14662511.html
一、GAN 概述
GAN(生成对抗网络,Generative Adversarial Networks) 的产生来源于一个灵机一动的想法:What I cannot create, I do not understand.(那些我所不能创造的,我也没有真正地理解它。)。
类似的,如果深度学习不能创造图片,那么它也没有真正地理解图片。那段时间深度学习已经开始在各类计算机视觉领域中达到了一个较高的成就,在很多任务中都取得了突破,但是人们一直对神经网络的黑盒模型表示质疑,也因此更多的人想从可视化的角度来套索卷及网络所学习的特征和特征间的组合,而 GAN 则从生成学习的角度展示了神经网络的强大能力。
GAN 解决了非监督学习中的著名问题:给定一批样本,训练一个系统能够生成类似的样本。
二、GAN 的网络结构

GAN 的网络结构图如上图所示,主要包含以下两个子网络:
- 生成器(generator):输入一个随机噪声,生成一张图片
- 判别器(discriminator):判断输入的图片时真图片还是假图片
训练判别器的时候,需要利用生成器生成的假图片和真实图片;训练生成器的时候,只需要用噪声生成假图片。判别器用来评估生成的假图片的质量,促使生成器相应地调整参数。
生成器的目标是尽可能地生成以假乱真的图片,让判别器以为这是真的图片;判别器的目标是将生成器生成的图片和真实图片区分开。可以看出这两者的目标相反,在训练过程中相互对抗,这也是它被称作生成对抗网络的原因。
三、通过一个举例具体化 GAN
上述的描述可能过于抽象,现在让我们用收藏齐白石作品的书画收藏家和假画贩子的例子来说明。
下图为齐白石画虾图真迹。

假画贩子相当于是生成器,他们希望能够模仿大师真迹伪造出以假乱真的假画,骗过收藏家;书画收藏家则希望把赝品和真迹区分开。在下述的例子中,假画贩子和收藏家所交易的画,主要都是齐白石画的虾。
在这个例子中,假设一开始假画贩子和收藏家都是新手,他们对真迹和赝品的概念都很模糊。假画贩子仿造出来的画几乎都是鬼画符,而收藏家也傻啦吧唧的把不少赝品当做了真迹,也有很多真迹当做了赝品。
起初,收藏家通过一堆赝品和真迹,发现画中的虾有一对大钳子,如果画中没有这个大钳子,则一概过滤掉,当做是赝品;假画贩子中的一堆画中没有大钳子的赝品基本都血本无归,只有有大钳子的赝品才被收藏家傻乎乎的买去了,因此假画贩子吸取经验,在所有的赝品中都加上了大钳子,其他部分还是鬼画符。
下图为假画贩子的第一版赝品。
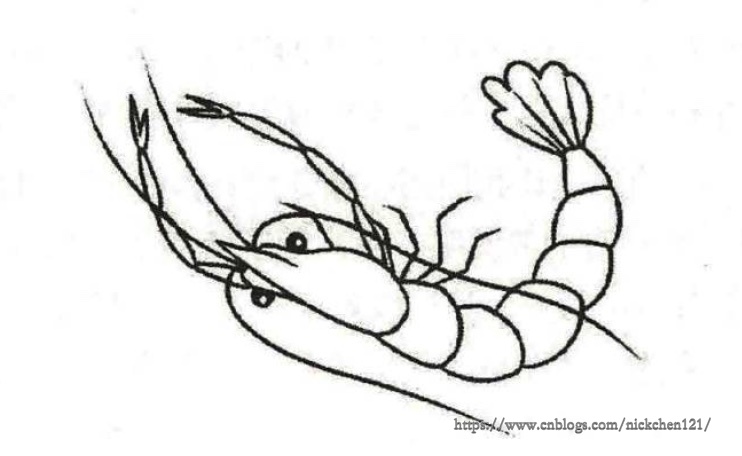
魔高一尺道高一丈,收藏家买了所有的画都有了大钳子,但是收藏家发现还是不对劲,因为还是有些画是赝品,因此收藏家又一次闭关修炼,发现齐白石画的虾不仅有大钳子,虾还有弯曲的形状,并且虾须很长;假画贩子也发现了不对劲,只有大钳子的假画很多卖不出去了,因此假画贩子开始日夜作画,渐渐地,他发现只要这幅画有大钳子,虾有弯曲的形状,虾须很长,收藏家就会买,因此假画贩子又一次占了上风。
下图为假画贩子的第二版赝品。

正所谓道高一尺魔高一丈,假画贩子和收藏家就在这种的博弈情况下,一个鉴定假画的能力越来越强,一个作假画的水平越来越高超,两个人在博弈对抗中,还不断地促使对方学习进步,进而达到了共同提升的目的。
在这个例子中,假画贩子相当于一个生成器,收藏家相当于一个判别器。一开始生成器和判别器的水平都很差,因为二者都是随机初始化。
训练过程分为两步交替进行:
- 第一步是训练判别器(只修改判别器的参数,固定生成器),目标是把真迹和赝品区分开
- 第二步是训练生成器(只修改生成器的参数,固定判别器),为的是生成的假画能够被判别器判别为真迹
上述两步交替进行,进而分类器和判别器最终都会达到一个较高的水平,直至最后,生成器生成的虾的图片和齐白石的真迹几乎没有区别。
下图所示便是生成器生成的虾。

四、GAN 的设计细节
下面我们来思考网络结构的设计。
判别器的目标是判断输入的图片是真迹还是赝品,所以可以看成是一个二分类网络,可以设计一个简单的卷积网络完成。
生成器的目标是从噪声中生成一张彩色图片,这里我们采用广泛使用的 DCGAN(Deep Convolutional Generative Adversarial Networks)结构,也就是全卷机网络,它的结构如下图所示。
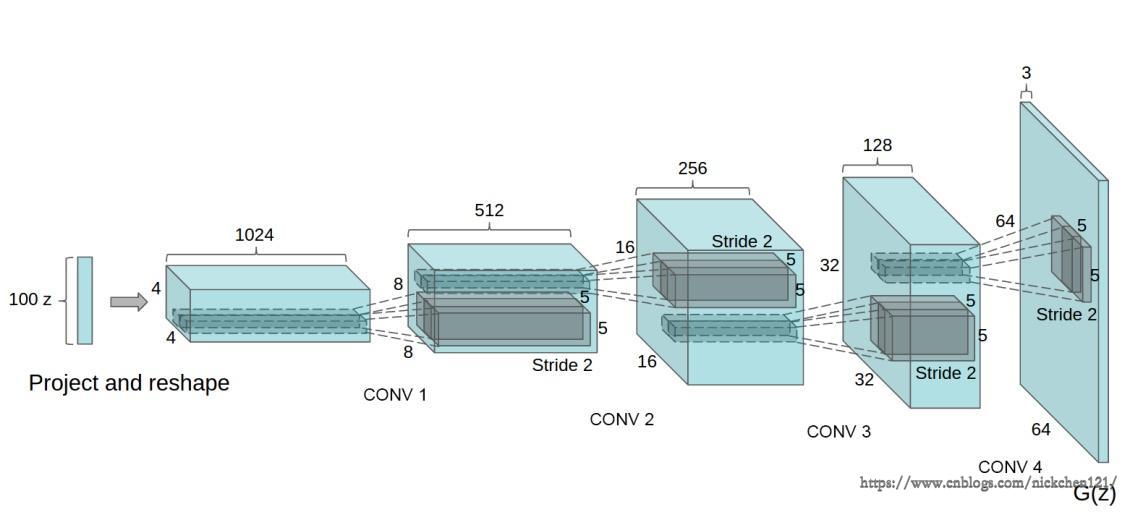
网路的输入是一个 100 维的噪声,输出是一个 3×64×64 的图片。其中这里的输入可以看成是一个 100×1×1 的图片,通过上卷积慢慢增大为 4×4、8×8、16×16、32×32 和 64×64。
上卷积,或称为转置卷积,是一种特殊的卷积操作,类似于卷及操作的逆运算。当卷积的 side 为 2 时,输出相比输入会下采样到一半的尺寸;而当上卷积的 side 为 2时,输出会上采样到输入的两倍尺寸。
这种上采样的方法可以理解为图片的信息保存于 100 个向量之中,神经网络根据这 100 个向量描述的信息,前几步的上采样先勾勒出轮廓、色调等基础信息,后几步上采样慢慢完善细节。网络越深,细节越详细。
在 DCGAN 中,判别器的结构和生成器对称:生成器中采用上采样的卷积,判别器中就采用下采样的卷积,生成器是根据噪声输出一张 64×64×3 的图片,而判别器则是根据输入的 64×64×3 的图片输出图片属于正负样本的分数(概率)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号