02-23 决策树CART算法
人工智能从入门到放弃完整教程目录:https://www.cnblogs.com/nickchen121/p/11686958.html
决策树CART算法
决策树C4.5算法虽然对决策树ID3算法做了很大的改良,但是缺点也是很明显的,无法处理回归问题、使用较为复杂的熵来作为特征选择的标准、生成的决策树是一颗较为复杂的多叉树结构,CART算法针对这些问题又做了进一步的优化。
一、决策树CART算法学习目标
- 基尼指数和熵
- CART算法对连续值和特征值的处理
- CART算法剪枝
- 决策树CART算法的步骤
- 决策树CART算法的优缺点
二、决策树CART算法详解
CART的英文名全称是classification and regression tree,所以有时候也把CART称它为分类回归树,分类回归树由特征选择、树的生成以及剪枝组成,既可以用于分类也可以用于回归。
2.1 基尼指数和熵
# 基尼指数和熵示例图
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
p = np.arange(0.001, 1, 0.001)
gini = 2*p*(1-p)
entropy = -(p*np.log2(p) + (1-p)*np.log2(1-p))/2
error = 1-np.max(np.vstack((p, 1-p)), 0)
plt.plot(p, entropy, 'r-', label='基尼指数')
plt.plot(p, gini, 'g-', label='熵之半$(1/2*H(p))$')
plt.plot(p, error, 'b-', label='分类误差率')
plt.xlabel('p', fontproperties=font)
plt.ylabel('损失', fontproperties=font)
plt.legend(prop=font)
plt.show()
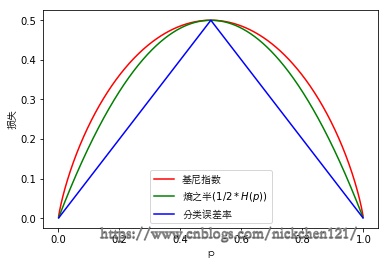
上图可以看出二分类问题中基尼指数和熵的曲线非常接近,因此基尼指数可以作为熵的一个近似替代。而CART算法就是使用了基尼指数来选择决策树的特征,同时为了进一步简化基尼指数的计算,CART算法每次对某个特征进行二分,因此CART算法构造的决策树是一颗二叉树模型。
2.2 CART算法对连续值特征的处理
CART算法类似于C4.5算法对连续值特征的处理,只是CART算法使用基尼指数取代了信息增益比对连续值做了处理。
假设现有一个特征\(F\)的特征值为连续值,从大到小排序为\(f_1,f_2,\ldots,f_m\),CART算法对相邻样本间的特征值\(f_i,f_{i+1}\)取平均数,一共可以得到\(m-1\)个划分点,其中第\(j\)个划分点可以表示为
对于这\(m-1\)个划分点,分别计算以该点作为二元分类点的基尼指数,选择基尼指数最小的点作为该连续特征的二元离散分类点,把改点记作\(f_t\),则特征值小于\(f_t\)的点记作\(c_1\);特征值大于\(f_t\)的点记作\(c_2\),这样就实现了连续特征值的离散化。
2.3 CART算法对离散值特征的处理
CART算法对离散值特征的处理采用的是不停的二分离散化特征的思想。
假设一个训练集\(D\)的某个特征\(F\)有\(f_1,f_2,f_3\)三种类别。如果我们使用的是ID3算法或者是C4.5算法,则会生成\(3\)个子节点,即三叉子节点,也因此导致决策树变成一颗多叉树。但是CART算法会基于这三个特征形成\(f_1\)和\(f_2,f_3\)、\(f_2\)和\(f_1,f_3\)、\(f_3\)和\(f_1,f_2\)这三种组合,并且在这三个组合中找到基尼指数最小的组合,然后生成二叉子节点。
假设\(f_1\)和\(f_2,f_3\)在这三者中基尼指数最小,则生成的二叉做子节点为\(f_1\),二叉右子节点为\(f_2,f_3\)。由于右子节点并没有被完全分开,因此在之后会继续求出\(f_2\)和\(f_3\)的基尼指数,然后找到最小的基尼指数来划分特征\(F\)。
2.4 CART算法剪枝
回归CART树和分类CART树剪枝策略除了在特征选择的时候一个使用了均方误差,另一个使用了基尼指数,其他内容都一样。
无论是C4.5算法还是CART算法形成的决策树都很容易对训练集过拟合,因此可以使用剪枝的方式解决过拟合问题,这类似于线性回归中的正则化。
CART算法采用的事后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择返回泛化能力最好的剪枝方法。即CART树的剪枝方法可分为两步:
- 使用原始的决策树\(T_0\)从它的底端开始不断剪枝,直到\(T_0\)的根节点生成一个子树序列\(\{T_0,T_1,\ldots,T_n\}\)
- 通过交叉验证法选择泛化能力最好的剪枝后的树作为最终的CART树,即最优子树
2.4.1 生成剪枝后的决策树
在剪枝过程中,子树\(T\)的损失函数为
其中\(T\)是任意子树,\(\alpha \quad \alpha\geq0\)为正则化参数,它权衡训练数据的拟合程度与模型的复杂度;\(C(T)\)是训练数据的预测误差(分类树使用基尼指数度量,回归树使用均方差度量),\(|T|\)是子树\(T\)的叶子节点的数量。
当\(\alpha=0\)时没有正则化,即原始的决策树为最优子树;当\(\alpha\)逐渐增大时,则正则化强度越大,生成的最优子树相比较原生的子树就越小;当\(\alpha=\infty\)时,即正则化强度达到最大,此时由原始的决策树的根节点组成的单节点树为最优子树。因此对于固定的\(\alpha\),从子树的损失函数中可以看出一定存在使损失函数\(C_\alpha(T)\)最小的唯一子树\(T_a\),\(T_a\)在损失函数最小的意义下是最优的。
可以递归的方法对书进行剪枝。将\(\alpha\)从小增大,\(0=\alpha_0<\alpha_1<\cdots\alpha_n<+\infty\),产生一系列的区间\([\alpha_i,\alpha_{i+1}),i=0,1,\ldots,n\);剪枝得到的子序列对应着区间\(\alpha{\in}{[\alpha_i,\alpha_{i+1})}\)的最优子树序列\(\{T_0,T_1,\ldots,T_n\}\)(注:每个区间内是有可能有多个子树的),序列中的子树是嵌套的。
从原始的决策树\(T_0\)开始剪枝,对\(T_0\)的任意内部节点\(t\),以\(t\)为单结点树的损失函数是
以\(t\)为根节点的子树\(T_t\)的损失函数是
当\(\alpha=0\)以及\(\alpha\)充分小时(最优子树为原始的决策树),有不等式
当\(\alpha\)增大时,在某一\(\alpha\)有
当\(\alpha\)继续增大时(最优子树为根节点组成的单节点树),有
并且只要当\(\alpha = {\frac {C(t)-C(T_t)} {|T_t|-1} }\)(注:当\(T_t\)和\(t\)有相同的损失函数时该公式由\(t\)和\(T_t\)的损失函数联立得到)。由于\(t\)的节点少,因此\(t\)比\(T_t\)更可取,因此可以对子树\(T_t\)剪枝,也就是将它的子节点全部剪掉,变为一个叶子节点\(t\)。
2.4.2 选择最优子树
上面说到可以计算出每个子树是否剪枝的阈值\(\alpha\),如果把所有的节点是否剪枝的值\(\alpha\)都计算出来,然后分别针对不同的\(\alpha\)所对应的剪枝后的最优子树做交叉验证,这样就可以选择一个最优的\(\alpha\),通过这个\(\alpha\)则可以用对应的最优子树作为最终结果。
2.5 CART算法剪枝流程
2.5.1 输入
假设现在有一个原始的决策树\(T_0\)。
2.5.2 输出
最优子树\(T_\alpha\)。
2.5.3 流程
- 初始化\(\alpha_{min}=\infty\),最优子树集合\(s=\{T\}\)
- 自下而上的对各内部结点\(t\)计算\(C(T_t)\)、\(|T_t|\)以及正则化阈值\(\alpha = min\{\alpha_{min},g(t)={\frac{C(t)-C(T_t)}{|T_t|-1}}\}\)(注:\(g(t)\)由\(t\)和\(T_t\)的损失函数联立得到,即表示剪枝后整体损失函数的减少程度),并且更新\(\alpha_{min}=\alpha\)。其中\(T_t\)表示以\(t\)为根节点的子树,\(C(T_t)\)是训练数据的预测误差,\(|T_t|\)是\(T_t\)的叶节点个数
- 得到所有节点的\(\alpha\)值的集合\(M\)
- 从\(M\)中选择最大的值\(\alpha_i\),自上而下的访问子树\(t\)的内部节点,如果\({\frac{C(t)-C(T_t)}{|T_t|-1}}\leq\alpha_i\)(注:\(g(t)=C_\alpha(t)-C_\alpha(T_t)+\alpha\),如果\(g(t)\leq\alpha\),则\(C_\alpha(t)-C_\alpha(T_t)<0\),则\(C_\alpha(t)<C_\alpha(T_t)\),则以\(t\)为单节点的树的误差会更小),进行剪枝并决定叶节点的值。如果是分类树,则是概率最高的类别;如果是回归树,则是所有样本输出的均值或所有样本的中位数。然后得到\(\alpha_i\)对应的最优子树\(T_k\)
- 最优子树集合\(s=s\bigcup{T_i}\),\(M=M-{a_i}\)
- 如果\(M\)不为空,回到步骤4,否则已经得到了所有可能的最优子树集合\(s\)
- 采用交叉验证在\(s\)中选择最优子树\(T_\alpha\)
三、决策树CART算法流程
3.1 输入
假设有训练数据集\(D\),停止计算的条件:节点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值,或没有更多特征。
3.2 输出
CART树
3.3 分类CART树算法流程
CART算法从根节点开始,用训练集递归的建立CART树。
- 设节点的训练集为\(D\),计算现有的所有特征对该训练集的基尼指数。此时对每一个特征\(F\),对其可能取的每个值\(f\),根据样本点对\(F=f\)的测试为“是”或“否”将\(D\)分割成\(D_1\)和\(D_2\)两个子集,利用基尼指数公式计算\(F=f\)时的基尼指数。
- 在所有可能的特征\(T\)以及它们所有可能的切分点\(t\)中,选择基尼指数最小的特征与其对应的切分点作为最优切分点,依据该最优切分点切割,生成两个子节点,左子节点为\(D_1\),右子节点为\(D_2\)。
- 对两个子节点递归调用步骤\(1-2\),直至满足停止条件生成一颗完整的二叉CART决策树。
- 对生成的分类CART决策树做预测的时候,如果测试集里的某个样本\(A\)落到了某个叶子节点,该叶子节点里存在多个类别的训练样本,则概率最大的训练样本则是样本\(A\)的类别。
3.4 回归CART树算法流程
回归CART树和分类CART树的建立算法和过程大部分是相同的,所以本文只讨论两者生成决策树的区别,两者的区别有以下两点
- 回归CART树和分类CART树最大的区别在于样本输出,如果输出的是离散值,则它是一颗分类树;如果输出的是连续值,则它是一颗回归树。
- 两者的区别在于对连续值处理的方式不同以及决策树建立后做预测的方式不同。
3.4.1 处理连续值
分类CART树用基尼指数最小化准则,而回归CART树用均方误差最小化准则作为特征和划分点选择的方法。
对任意的划分特征\(F\),对应的任意划分点\(s\)把训练集\(D\)划分成两个子集\(D_1\)和\(D_2\),求出使得两个子集\(D_1\)和\(D_2\)以及两个子集之和的均方差最小的对应划分点\(s\)特征\(F\)和划分点\(s\),即
其中已经假设样本按照某个特征\(F\)和划分点\(s\)划分成功,则输入一个\(x\)会有一个输出值\(c_m\)。\(c_1\)则是\(D_1\)数据集中所有的\(x\)的样本输出均值,\(c_2\)是\(D_2\)数据集中所有的\(x\)的样本输出均值。
使用该方法生成的回归CART树通常称作最小二乘回归树(least squares regression tree)。
3.4.2 预测结果
分类CART树选择概率最大的类别作为样本\(A\)的类别的方式不同的是:回归CART树由于输出的不是类别,而是一个连续值,因此它通常采用的是使用最终叶子的均值或者中位数来预测输出结果。
四、决策树CART算法优缺点
4.1 优点
- 既可以做分类又可以做回归
4.2 缺点
- 你要说缺点其实还真的有,CART算法做特征分类决策的时候是由某一个特征决定的,而真实情况应该是由一组特征决定的,这样决策得到的决策树更加准确,这个决策树叫做多变量决策树(mutil-variate decision tree),这个算法的代表是OC1,这里不多赘述。
五、小结
CART树是决策树的一次创新,摒弃了信息熵使用了基尼指数,基于C4.5算法可以处理回归问题,可以使用剪枝防止过拟合,解释型强。
CART树可以说是完美的,但是它最大的一个问题就是CART算法会把所有的特征全部用于构造决策树中,这对于生成决策树来讲是一个非常大的问题,在集成学习中使用随机森林将能一点程度的减轻该问题。
由于随机森林属于集成学习,所以下一篇很遗憾的告诉你不是讲随机森林,而将带你走入概率的天堂,即朴素贝叶斯法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号