小白专场-FileTransfer-c语言实现
数据结构与算法_Python_C完整教程目录:https://www.cnblogs.com/nickchen121/p/11407287.html
更新、更全的《数据结构与算法》的更新网站,更有python、go、人工智能教学等着你:https://www.cnblogs.com/nickchen121/p/11407287.html
一、集合的简化表示
在上一节 集合及运算中,我们对集合使用二叉树表示,如下图所示:
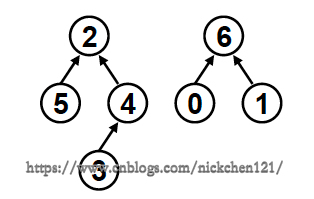
为了使用二叉树,我们在上一节中使用以下代码,构造二叉树:
/* c语言实现 */
typedef struct{
ElementType Data;
int Parent;
} SetType;
int Find(SetType S[], ElementType X)
{
// 在数组S中查找值为X的元素所属的集合
// MaxSize是全局变量,为数组S的最大长度
int i;
for (i = 0; i < MaxSize && S[i].Data != X; i++);
if (i >= MaxSize) return -1; // 未找到X,返回-1
for (; S[i].Parent >= 0; i = S[i].Parent);
return i; // 找到X所属集合,返回树根结点在数组S中的下标
}
使用二叉树构造集合,Find操作在差的情况下时间复杂度可能为\(O(n^2)\)
因此对于任何有限集合的(N个)元素都可以被一一映射为整数 0~N-1。即对于集合 {2, 5, 4, 3} 和 {6, 0, 1} 我们可以使用如下图所示的数组表示:
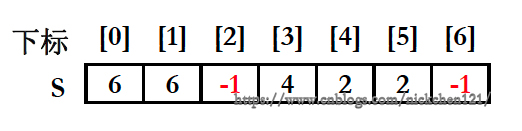
对于上述的数组,我们可以使用如下代码构造:
/* c语言实现 */
typedef int ElementType; // 默认元素可以用非负整数表示
typedef int SetName; //默认用根结点的下标作为集合名称
typedef ElementType SetType[MaxSize];
SetName Find(SetType S, ElementType X)
{
// 默认集合元素全部初始化为-1
for (; S[X] >= 0; X = S[X]);
return X;
}
void Union(SetType S, SetName Root1, SetName Root2)
{
// 这里默认Root1和Root2是不同集合的根节点
S[Root2] = Root1;
}
二、题意理解
根据输入样例,以此来判断计算机之间有多少个组成,如下图所示
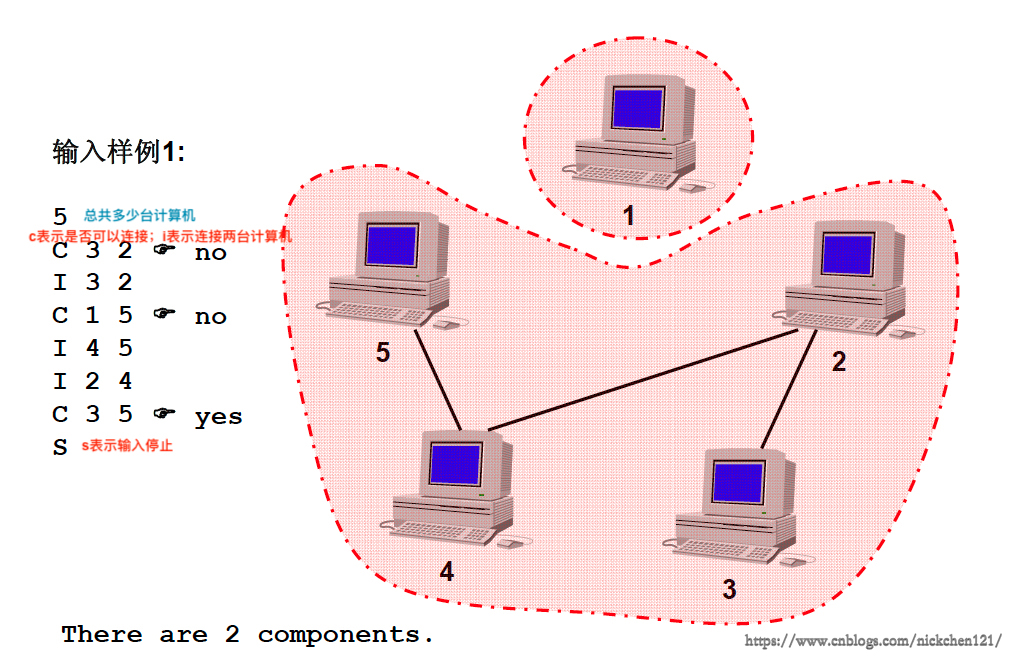
上图动态变化如下图所示:
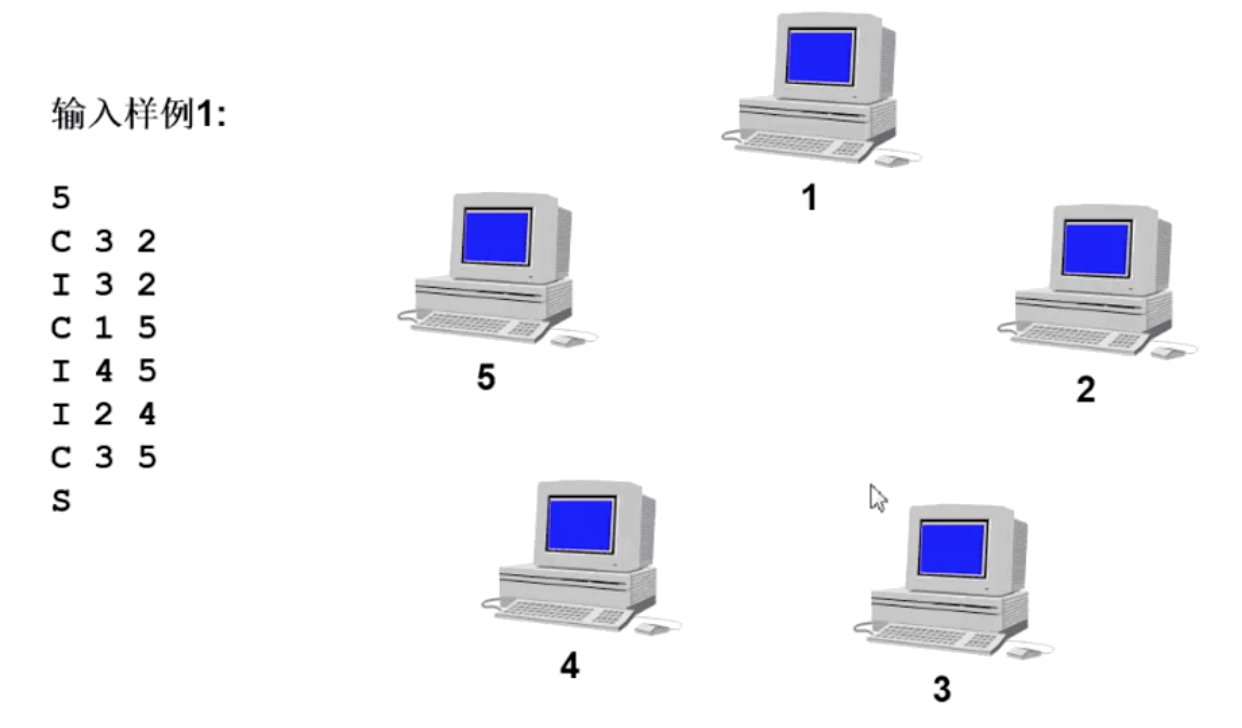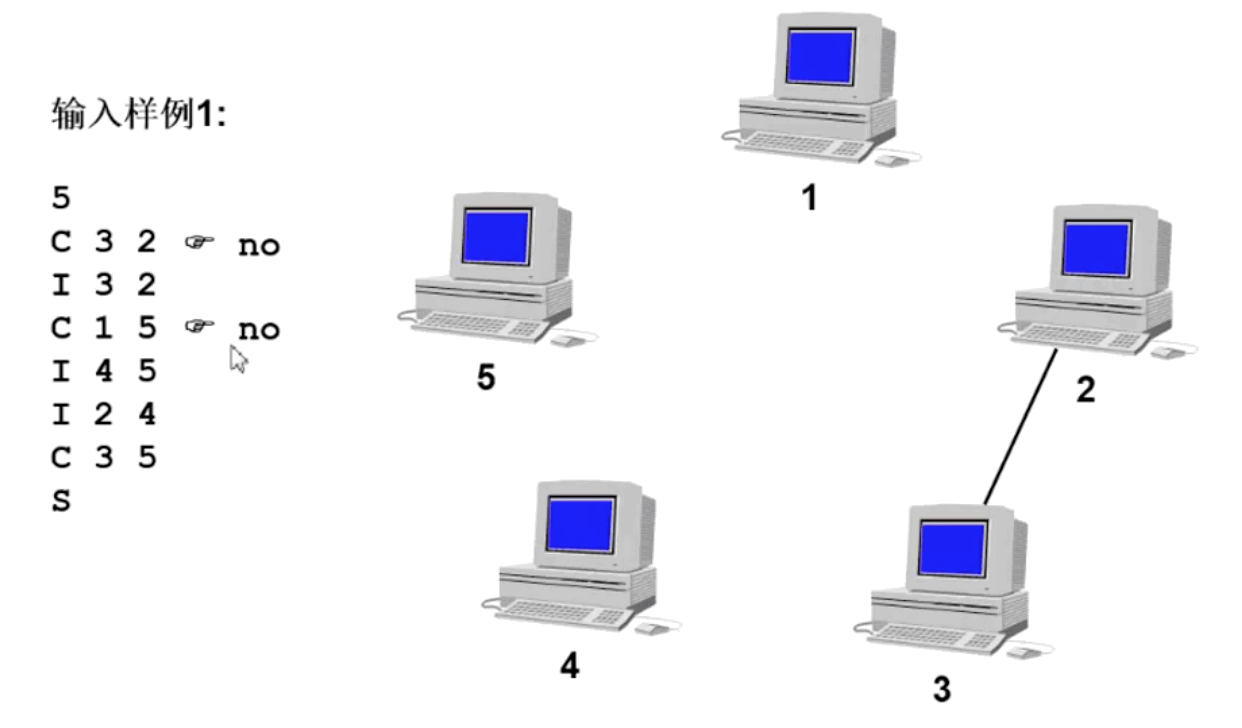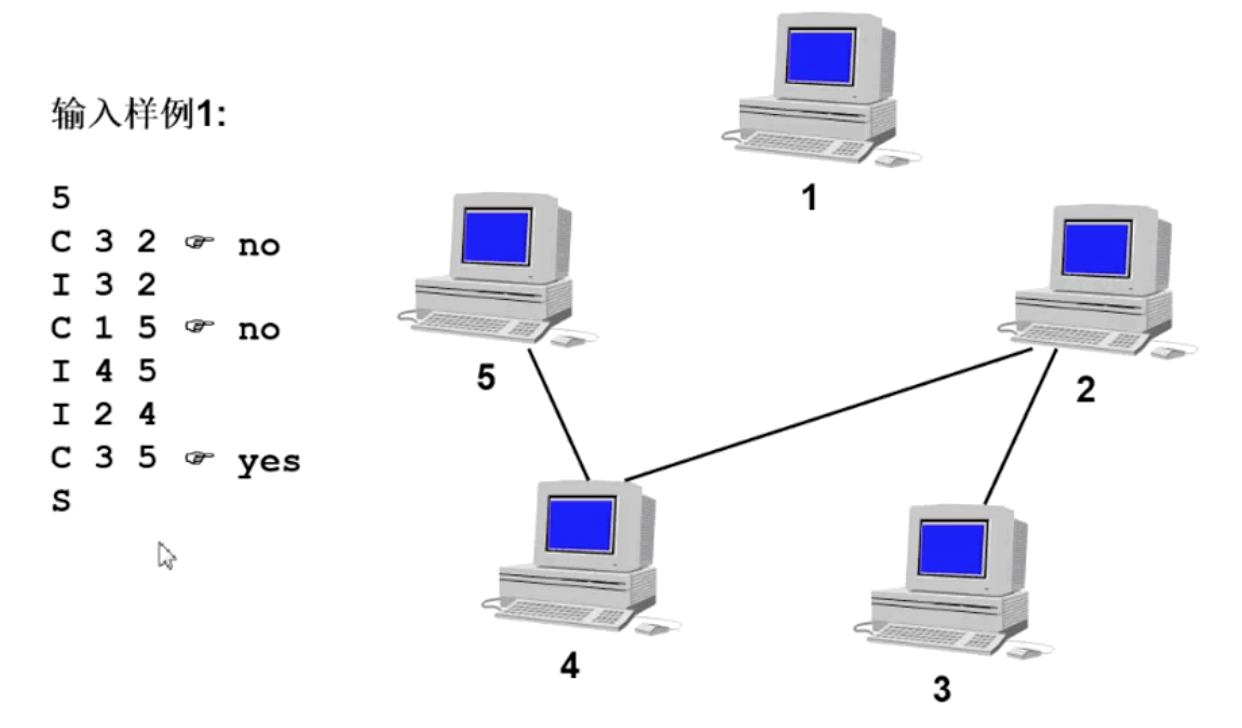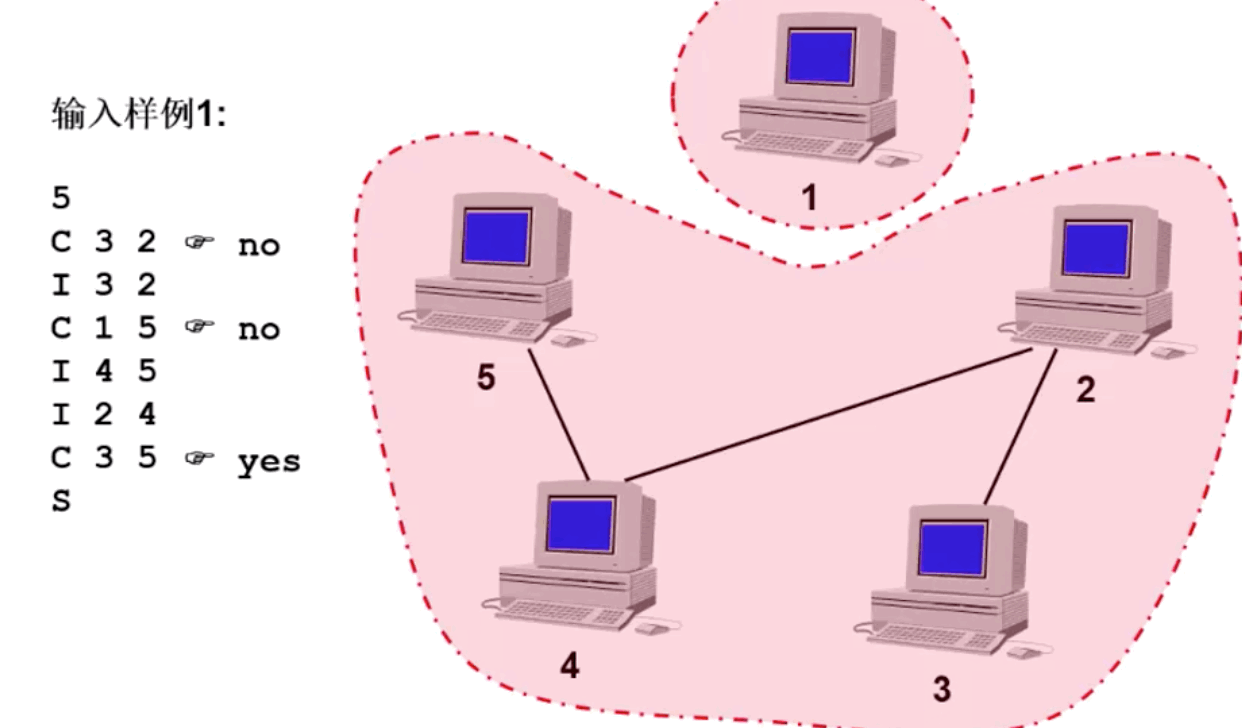
下图为五台计算机之间形成全连接状态,因此看成一个整体:
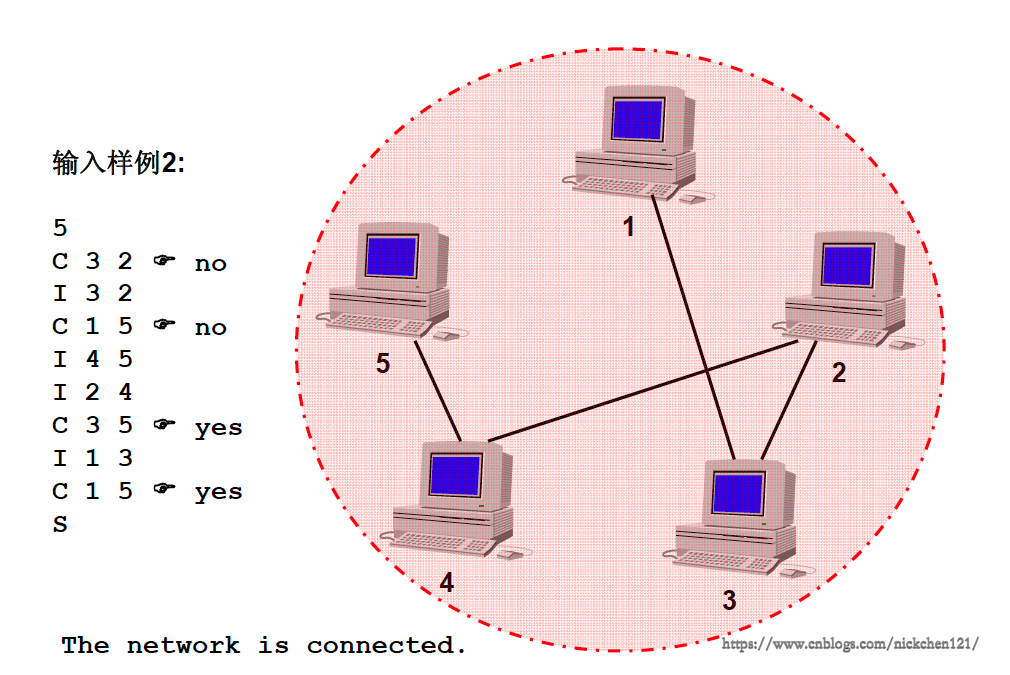
三、程序框架搭建
/* c语言实现 */
int main()
{
初始化集合;
do {
读入一条指令;
处理指令;
} while (没结束);
return 0;
}
int main()
{
SetType S;
int n;
char in;
scanf("%d\n", &n);
Initialization(S, n);
do {
scanf("%c", &in);
switch (in) {
case 'I': Input_connection(S); break; // Union(Find)
case 'C': Check_connection(S); break; // Find
case 'S': Check_network(S, n); break; // 数集合的根,判断计算机网络的组成个数
}
} while (in != 'S');
return 0;
}
3.1 Input_connection
/* c语言实现 */
void Input_connection(SetType S)
{
ElementType u, v;
SetName Root1, Root2;
scanf("%d %d\n", &u, &v);
Root1 = Find(S, u-1);
Root2 = Find(S, v-1);
if (Root1 != Root2)
Union(S, Root1, Root2);
}
3.2 Check_connection
/* c语言实现 */
void Check_connection(SetType S)
{
ElementType u, v;
scnaf("%d %d\n", &u, &v);
Root1 = Find(S, u-1);
Root2 = Find(S, v-1);
if (Root1 == Root2)
printf("yes\n");
else printf("no\n");
}
3.3 Check_network
/* c语言实现 */
void Check_network(SetType S, int n)
{
int i, counter = 0;
for (i = 0; i < n; i++){
if (S[i] < 0) counter++;
}
if (counter == 1)
printf("The network is connected.\n");
else
printf("There are %d components.\n", counter);
}
四、pta测试
/* c语言实现 */
typedef int ElementType; // 默认元素可以用非负整数表示
typedef int SetName; //默认用根结点的下标作为集合名称
typedef ElementType SetType[MaxSize];
SetName Find(SetType S, ElementType X)
{
// 默认集合元素全部初始化为-1
for (; S[X] >= 0; X = S[X]);
return X;
}
void Union(SetType S, SetName Root1, SetName Root2)
{
// 这里默认Root1和Root2是不同集合的根节点
S[Root2] = Root1;
}
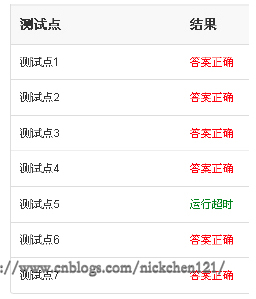
对于上述的代码,如果我们放入pta中测试,会发现测试点6运行超时,如下图所示:

因此,我们会考虑是不是因为出现了某种情况,导致Root2为根结点的树过大了,因此我们修改代码为:
/* c语言实现 */
typedef int ElementType; // 默认元素可以用非负整数表示
typedef int SetName; //默认用根结点的下标作为集合名称
typedef ElementType SetType[MaxSize];
SetName Find(SetType S, ElementType X)
{
// 默认集合元素全部初始化为-1
for (; S[X] >= 0; X = S[X]);
return X;
}
void Union(SetType S, SetName Root1, SetName Root2)
{
// 这里默认Root1和Root2是不同集合的根节点
// S[Root2] = Root1;
S[Root1] = Root2;
}
发现更换代码后,测试点5却运行超时了,为了解决上述问题,我们可以使用下面将要讲到了按秩归并的思想修改代码。
五、按秩归并
为什么需要按秩归并呢?因为我们使用pta测试程序,发现代码总是超时,因此我们可以考虑是否出现这种情况——我们再不断地往一颗树上累加子树,如下图所示:
/* c语言实现 */
Union(Find(2), Find(1));
Union(Find(3), Find(1));
……;
Union(Find(n), Find(1));
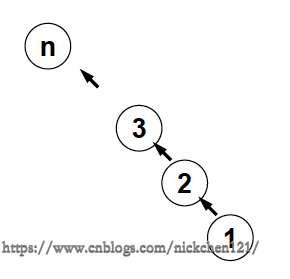
从上图可以看出,此过程的时间复杂度为:\(T(n) = O(n^2)\)
除了上述这种情况,会导致树的高度越来越高,如果我们把高树贴在矮树上,那么树高也会快速增长,因此我们应该考虑把矮树贴在高数上。
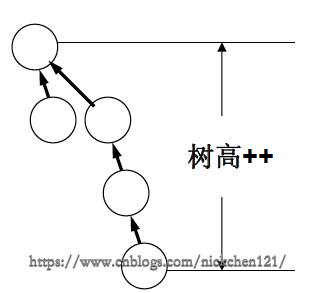
对于上述问题的解决,我们给出以下两个解决方法,这两种方法统称为按秩归并。
5.1 方法一:树高替代
为了解决上述问题,我们可以把根结点从-1替代为-树高,代码如下:
/* c语言实现 */
if ( Root2高度 > Root1高度 )
S[Root1] = Root2;
else {
if ( 两者等高 ) 树高++;
S[Root2] = Root1;
}
if ( S[Root2] < S[Root1] )
S[Root1] = Root2;
else {
if ( S[Root1]==S[Root2] ) S[Root1]--;
S[Root2] = Root1;
}
5.2 方法二:规模替代
为了解决上述问题,我们也可以把根结点从**-1替代为-元素个数(把小树贴到大树上),代码如下:
/* c语言实现 */
void Union( SetType S, SetName Root1, SetName Root2 )
{
if ( S[Root2]<S[Root1] ){
S[Root2] += S[Root1];
S[Root1] = Root2;
} else {
S[Root1] += S[Root2];
S[Root2] = Root1;
}
}
六、路径压缩
对于上述代码超时的问题,我们也可以使用路径压缩的方法优化代,即压缩给定元素到集合根元素路径中的所有元素,详细情况如下图所示:
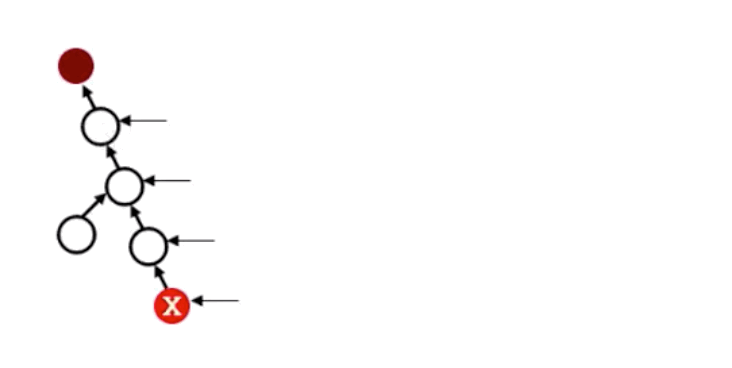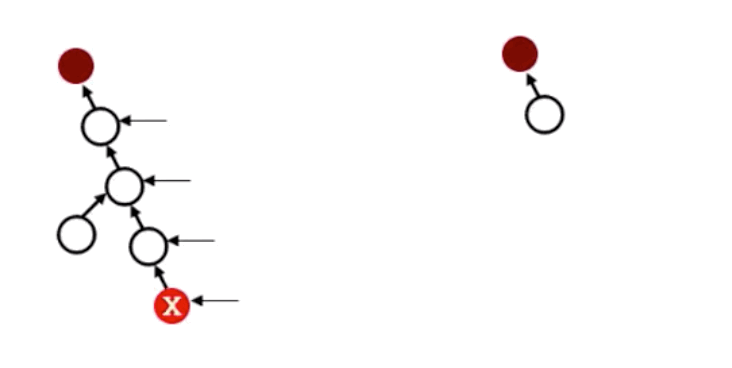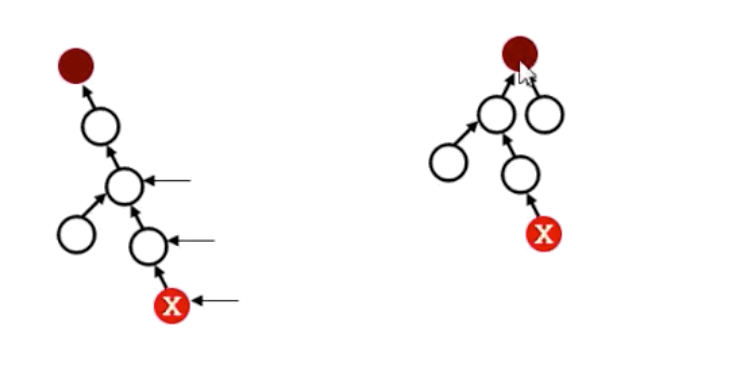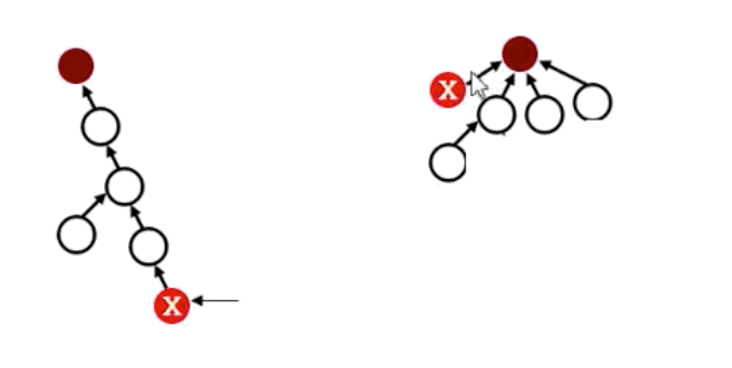
上图代码可表示为:
/* c语言实现 */
SetName Find(SetType S, ElementType X)
{
// 找到集合的根
if (S[X] < 0)
return X;
else
return S[X] = Find(S, S[X]);
}
总之上述代码干了这三件事:
- 先找到根;
- 把根变成X的父结点;
- 再返回根
因此,路径压缩第一次执行的时间比较长,但是如果频繁使用查找命令,第一次将路径压缩,大大减小树的高度,后续查找速度将大大增加
6.1 路径压缩时间复杂度计算
由于pta并没有严格控制时间限制,使用java这种语言,不使用路径压缩,问题不大,我写这个也只是为了回顾算法,来放松放松,不是为了折腾自己,因此。
给你一个眼神自己体会,给你一个网址亲自体会https://www.icourse163.org/learn/ZJU-93001?tid=1206471203#/learn/content?type=detail&id=1211167097&sm=1,我是懒得研究下图所示了。


