内存中的线程
Python从入门到放弃完整教程目录:https://www.cnblogs.com/nickchen121/p/10718112.html
一、内存中的线程

多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是CPU在多个线程之间的快速切换。
不同的进程之间是充满敌意的,彼此是抢占、竞争CPU的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃CPU,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
- 父进程有多个线程,那么开启的子线程是否需要同样多的线程。
- 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢?
因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
二、用户级线程和内核级线程(了解)
线程的实现可以分为两类:用户级线程(User-Level Thread)和内核线线程(Kernel-Level Thread),后者又称为内核支持的线程或轻量级进程。在多线程操作系统中,各个系统的实现方式并不相同,在有的系统中实现了用户级线程,有的系统中实现了内核级线程。
2.1 用户级线程
内核的切换由用户态程序自己控制内核切换,不需要内核干涉,少了进出内核态的消耗,但不能很好的利用多核CPU。
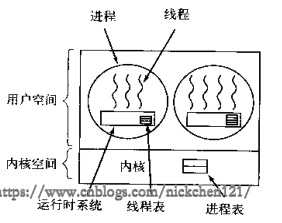
在用户空间模拟操作系统对进程的调度,来调用一个进程中的线程,每个进程中都会有一个运行时系统,用来调度线程。此时当该进程获取CPU时,进程内再调度出一个线程去执行,同一时刻只有一个线程执行。
2.2 内核级线程
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态;可以很好的利用smp,即利用多核CPU。windows线程就是这样的。

2.3 用户级与内核级线程的对比
2.3.1 用户级线程和内核级线程的区别
- 内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
- 用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
- 用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
- 在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
- 用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
2.3.2 内核线程的优缺点
优点:当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:由内核进行调度。
2.3.3 用户级线程的优缺点
- 优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
允许每个进程定制自己的调度算法,线程管理比较灵活。
线程能够利用的表空间和堆栈空间比内核级线程多。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程* 都会被挂起。另外,页面失效也会产生同样的问题。
- 缺点:
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
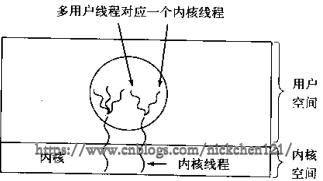
2.4 混合实现
用户级与内核级的多路复用,内核同一调度内核线程,每个内核线程对应n个用户线程。
2.4.1 linux操作系统的 NPTL
历史:在内核2.6以前的调度实体都是进程,内核并没有真正支持线程。它是能过一个系统调用clone()来实现的,这个调用创建了一份调用进程的拷贝,跟fork()不同的是,这份进程拷贝完全共享了调用进程的地址空间。LinuxThread就是通过这个系统调用来提供线程在内核级的支持的(许多以前的线程实现都完全是在用户态,内核根本不知道线程的存在)。非常不幸的是,这种方法有相当多的地方没有遵循POSIX标准,特别是在信号处理,调度,进程间通信原语等方面。
很显然,为了改进LinuxThread必须得到内核的支持,并且需要重写线程库。为了实现这个需求,开始有两个相互竞争的项目:IBM启动的NGTP(Next Generation POSIX Threads)项目,以及Redhat公司的NPTL。在2003年的年中,IBM放弃了NGTP,也就是大约那时,Redhat发布了最初的NPTL。
NPTL最开始在redhat linux 9里发布,现在从RHEL3起内核2.6起都支持NPTL,并且完全成了GNU C库的一部分。
设计:NPTL使用了跟LinuxThread相同的办法,在内核里面线程仍然被当作是一个进程,并且仍然使用了clone()系统调用(在NPTL库里调用)。但是,NPTL需要内核级的特殊支持来实现,比如需要挂起然后再唤醒线程的线程同步原语futex.
NPTL也是一个1*1的线程库,就是说,当你使用pthread_create()调用创建一个线程后,在内核里就相应创建了一个调度实体,在linux里就是一个新进程,这个方法最大可能的简化了线程的实现。
除NPTL的1*1模型外还有一个m*n模型,通常这种模型的用户线程数会比内核的调度实体多。在这种实现里,线程库本身必须去处理可能存在的调度,这样在线程库内部的上下文切换通常都会相当的快,因为它避免了系统调用转到内核态。然而这种模型增加了线程实现的复杂性,并可能出现诸如优先级反转的问题,此外,用户态的调度如何跟内核态的调度进行协调也是很难让人满意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号