re模块
- 一、正则表达式
- 二、re模块的基本使用
- 三、re模块中常用功能函数
- 3.1 正则表达式的两种书写方式
- 3.2 re.compile(strPattern[, flag])函数
- 3.3 re.match(pattern, string[, flags])函数(常用)
- 3.4 分组函数
- 3.5 re.search(pattern, string[, flags])函数
- 3.6 re.findall(pattern, string[, flags])函数(常用)
- 3.7 re.split(pattern, string[, maxsplit])函数
- 3.8 re.sub(pattern, repl, string[, count])函数
- 3.9 re.subn(pattern, repl, string,[, count][, flags])函数
- 四、注意事项
- 五、计算器(经典)
Python从入门到放弃完整教程目录:https://www.cnblogs.com/nickchen121/p/10718112.html
一、正则表达式
正则表达式本身是一种小型的、高度专业化的编程语言,它并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。而在python中,通过内嵌集成re模块,程序员们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
下图展示了使用正则表达式进行匹配的流程:
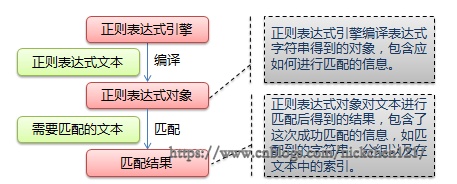
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
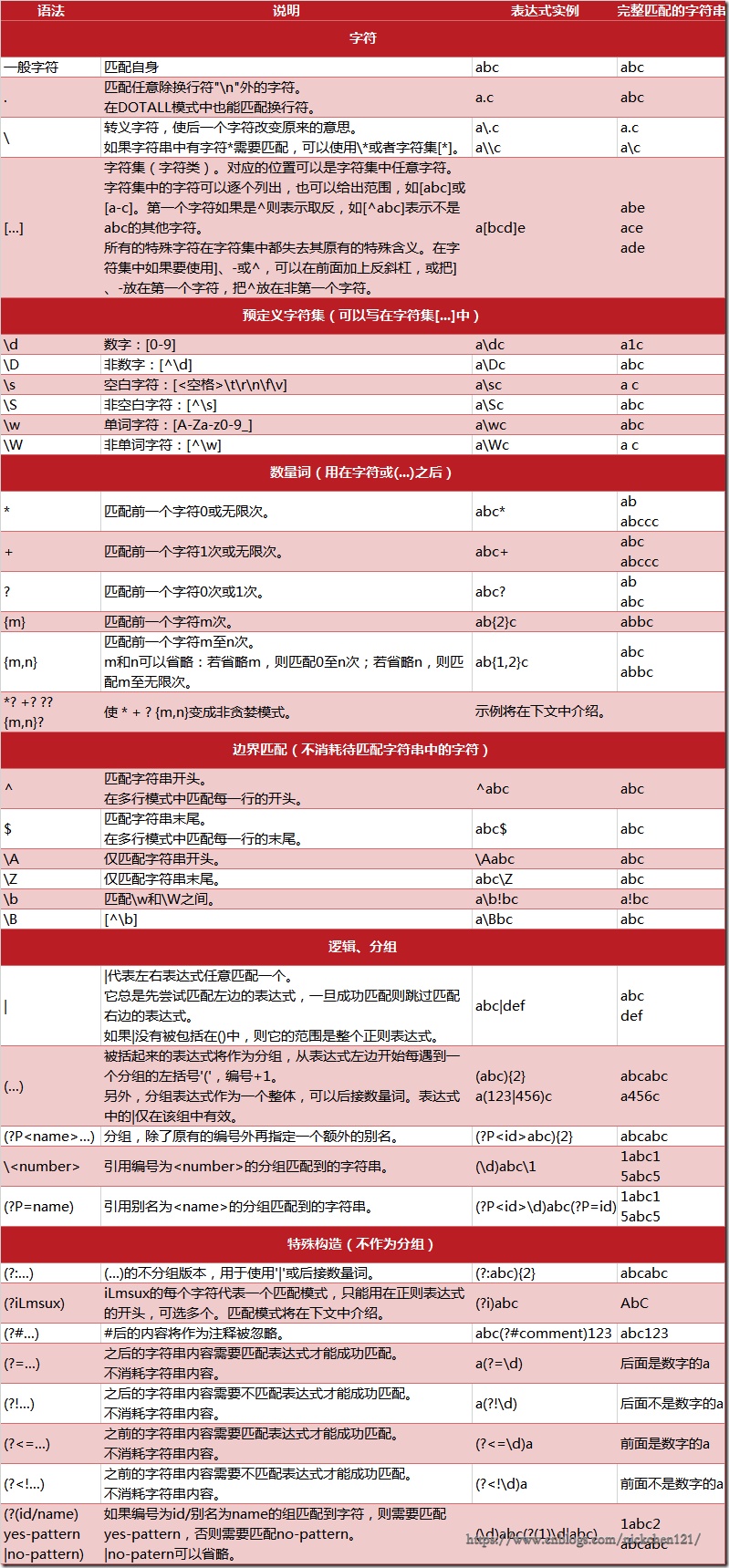
下图列出了Python支持的正则表达式元字符和语法:
1.1 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.2 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用\作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符\,那么使用编程语言表示的正则表达式里将需要4个反斜杠\\\\:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r'\\'表示。同样,匹配一个数字的\\d可以写成r'\d'。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.3 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
二、re模块的基本使用
正则表达式是用来匹配处理字符串的 python 中使用正则表达式需要引入re模块
import re # 第一步,要引入re模块
a = re.findall("匹配规则", "这个字符串是否有匹配规则的字符") # 第二步,调用模块函数
print(a) # 以列表形式返回匹配到的字符串
['匹配规则']
^元字符
字符串开始位置与匹配规则符合就匹配,否则不匹配
匹配字符串开头。在多行模式中匹配每一行的开头(Python3+已经失效,配合compile使用)
^元字符如果写到[]字符集里就是反取
import re
a = re.findall("^匹配规则", "匹配规则这个字符串是否匹配") # 字符串开始位置与匹配规则符合就匹配,否则不匹配
print(a)
#打印出 ['匹配规则']
['匹配规则']
[^a-z]反取
匹配出除字母外的字符,^元字符如果写到字符集里就是反取
import re
a = re.findall("[^a-z]", "匹配s规则这s个字符串是否s匹配f规则则re则则则") # 反取,匹配出除字母外的字符
print(a)
['匹', '配', '规', '则', '这', '个', '字', '符', '串', '是', '否', '匹', '配', '规', '则', '则', '则', '则', '则']
$元字符
字符串结束位置与匹配规则符合就匹配,否则不匹配
匹配字符串末尾,在多行模式中匹配每一行的末尾
import re
a = re.findall("匹配规则$", "这个字符串是否匹配规则") # 字符串结束位置与匹配规则符合就匹配,否则不匹配
print(a)
['匹配规则']
*元字符
需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0个或多个原本字符
匹配前一个字符0或多次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
如果规则里只有一个分组,尽量避免用*否则会有可能匹配出空字符串
import re
# 需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0或多个原本字符
a = re.findall("匹配规则*", "这个字符串是否匹配规则则则则则")
print(a)
['匹配规则则则则则']
+元字符
需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符
匹配前一个字符1次或无限次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
import re
# 需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符
a = re.findall("匹配+", "匹配配配配配规则这个字符串是否匹配规则则则则则")
print(a)
['匹配配配配配', '匹配']
?元字符(防止贪婪匹配)
需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符
匹配一个字符0次或1次
还有一个功能是可以防止贪婪匹配,详情见防贪婪匹配
import re
# 需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符
a = re.findall("匹配规则?", "匹配规这个字符串是否匹配规则则则则则")
print(a)
['匹配规', '匹配规则']
{}元字符(范围)
需要字符串里完全符合,匹配规则,就匹配,(规则里的 {} 元字符)前面的一个字符,是自定义字符数,位数的原本字符
{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次
{0,}匹配前一个字符0或多次,等同于*元字符
{+,}匹配前一个字符1次或无限次,等同于+元字符
{0,1}匹配前一个字符0次或1次,等同于?元字符
import re
# {m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次
a = re.findall("匹配规则{3}", "匹配规这个字符串是否匹配规则则则则则")
print(a)
['匹配规则则则']
[]元字符(字符集)
需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配
字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。
所有特殊字符在字符集中都失去其原有的特殊含义。用\反斜杠转义恢复特殊字符的特殊含义。
import re
# 需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配
a = re.findall("匹配[a,b,c]规则", "匹配a规则这个字符串是否匹配b规则则则则则")
print(a)
['匹配a规则', '匹配b规则']
[^]
非,反取,匹配出除[^]里面的字符,^元字符如果写到字符集里就是反取
import re
a = re.findall("[^a-z]", "匹配s规则这s个字符串是否s匹配f规则则re则则则") # 反取,匹配出除字母外的字符
print(a)
['匹', '配', '规', '则', '这', '个', '字', '符', '串', '是', '否', '匹', '配', '规', '则', '则', '则', '则', '则']
反斜杠后边跟普通字符实现特殊功能(预定义字符)
预定义字符是在字符集和组里都是有用的
\d匹配任何十进制数,它相当于类[0-9]
import re
a = re.findall("\d", "匹配规则这2个字符串3是否匹配规则5则则则7则") # \d匹配任何十进制数,它相当于类[0-9]
print(a)
['2', '3', '5', '7']
\d+
匹配一位或者多位数的数字时用
import re
a = re.findall("\d+", "匹配规则这2个字符串134444是否匹配规则5则则则7则") # \d+如果需要匹配一位或者多位数的数字时用
print(a)
['2', '134444', '5', '7']
\D
匹配任何非数字字符,它相当于类[^0-9]
import re
a = re.findall("\D", "匹配规则这2个字符串3是否匹配规则5则则则7则") # \D匹配任何非数字字符,它相当于类[^0-9]
print(a)
['匹', '配', '规', '则', '这', '个', '字', '符', '串', '是', '否', '匹', '配', '规', '则', '则', '则', '则', '则']
\s
匹配任何空白字符,它相当于类[\t\n\r\f\v]
import re
# \s匹配任何空白字符,它相当于类[\t\n\r\f\v]
a = re.findall("\s", "匹配规则 这2个字符串3是否匹\n配规则5则则则7则")
print(a)
[' ', ' ', ' ', '\n']
\S
匹配任何非空白字符,它相当于类[^\t\n\r\f\v]
import re
# \S匹配任何非空白字符,它相当于类[^\t\n\r\f\v]
a = re.findall("\S", "匹配规则 这2个字符串3是否匹\n配规则5则则则7则")
print(a)
['匹', '配', '规', '则', '这', '2', '个', '字', '符', '串', '3', '是', '否', '匹', '配', '规', '则', '5', '则', '则', '则', '7', '则']
\w
匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9_]
import re
# \w匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9_]
a = re.findall('\w', "https://www.cnblogs.com/")
print(a)
['h', 't', 't', 'p', 's', 'w', 'w', 'w', 'c', 'n', 'b', 'l', 'o', 'g', 's', 'c', 'o', 'm']
\W
匹配非任何字母数字字符包括下划线在内,它相当于类[^a-zA-Z0-9_]
import re
# \w匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9_]
a = re.findall('\W', "https://www.cnblogs.com/")
print(a)
[':', '/', '/', '.', '.', '/']
()元字符(分组)
也就是分组匹配,()里面的为一个组也可以理解成一个整体
如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是()里的整体内容,不再是前导一个字符
import re
# 也就是分组匹配,()里面的为一个组也可以理解成一个整体
a = re.search("(a4)+", "a4a4a4a4a4dg4g654gb") # 匹配一个或多个a4
b = a.group()
print(b)
a4a4a4a4a4
import re
# 也就是分组匹配,()里面的为一个组也可以理解成一个整体
# 匹配 (a) (\d0-9的数字) (+可以是1个到多个0-9的数字)
a = re.search("a(\d+)", "a466666664a4a4a4dg4g654gb")
b = a.group()
print(b)
a466666664
|元字符(或)
|或,或就是前后其中一个符合就匹配
import re
a = re.findall(r"你|好", "a4a4a你4aabc4a4dgg好dg4g654g") # |或,或就是前后其中一个符合就匹配
print(a)
['你', '好']
三、re模块中常用功能函数
3.1 正则表达式的两种书写方式
1.一种是直接在函数里书写规则,推荐使用
import re
a = re.findall("匹配规则", "这个字符串是否有匹配规则的字符")
print(a)
['匹配规则']
2.另一种是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print(match.group())
hello
3.2 re.compile(strPattern[, flag])函数
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
下表是所有的正则匹配模式:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
3.2.1 re.S
- 在Python的正则表达式中,有一个参数为re.S。它表示 “.” 的作用扩展到整个字符串,包括“\n”。看如下代码:
import re
a = '''asdfhellopass:
worldaf
'''
b = re.findall('hello(.*?)world', a)
c = re.findall('hello(.*?)world', a, re.S)
print('b is ', b)
print('c is ', c)
b is []
c is ['pass:\n ']
正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
3.2.2 re.I
- 不区分大小写
res = re.findall(r"A", "abc", re.I)
print(res)
['a']
3.2.3 re.M
- 将所有行的尾字母输出(python3+已经无效)
s = '12 34/n56 78/n90'
re.findall(r'^/d+', s, re.M) # 匹配位于行首的数字 # ['12', '56', '90']
re.findall(r'/A/d+', s, re.M) # 匹配位于字符串开头的数字 # ['12']
re.findall(r'/d+$', s, re.M) # 匹配位于行尾的数字 # ['34', '78', '90']
re.findall(r'/d+/Z', s, re.M) # 匹配位于字符串尾的数字 # ['90']
3.2.4 re.sub
# 要求结果:['12', '23', '34']
l = ['1 2 ', '2 3', ' 3 4']
import re
print(eval(re.sub(r'\s*', '', str(l))))
['12', '23', '34']
3.3 re.match(pattern, string[, flags])函数(常用)
match,从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
match(pattern, string, flags=0)
- pattern: 正则模型
- string : 要匹配的字符串
- falgs : 匹配模式
注意:match()函数 与 search()函数基本是一样的功能,不一样的就是match()匹配字符串开始位置的一个符合规则的字符串,search()是在字符串全局匹配第一个合规则的字符串
import re
# 无分组
origin = "hello egon bcd egon lge egon acd 19"
r = re.match("h\w+", origin) # match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
hello
()
{}
# 有分组
# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)
r = re.match("h(\w+)", origin) # match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
hello
('ello',)
{}
# 有两个分组定义了key
# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)
# ?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容
r = re.match("(?P<n1>h)(?P<n2>\w+)", origin)
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
hello
('h', 'ello')
{'n1': 'h', 'n2': 'ello'}
3.4 分组函数
?P<n1> # ?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容(只对正则函数返回对象时有用)
取出匹配对象方法
只对正则函数返回对象的有用
- group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
- groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
- groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
3.5 re.search(pattern, string[, flags])函数
search,浏览全部字符串,匹配第一符合规则的字符串,浏览整个字符串去匹配第一个,未匹配成功返回None
search(pattern, string, flags=0)
- pattern: 正则模型
- string : 要匹配的字符串
- falgs : 匹配模式
注意:match()函数 与 search()函数基本是一样的功能,不一样的就是match()匹配字符串开始位置的一个符合规则的字符串,search()是在字符串全局匹配第一个合规则的字符串
import re
# 无分组
origin = "hello alex bcd alex lge alex acd 19"
# search浏览全部字符串,匹配第一符合规则的字符串,浏览整个字符串去匹配第一个,未匹配成功返回None
r = re.search("a\w+", origin)
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
alex
()
{}
# 有分组
# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)
r = re.search("a(\w+).*(\d)", origin)
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
alex bcd alex lge alex acd 19
('lex', '9')
{}
# 有两个分组定义了key
# 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来)
# ?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容
r = re.search("a(?P<n1>\w+).*(?P<n2>\d)", origin)
print(r.group()) # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来
print(r.groups()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
print(r.groupdict()) # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
alex bcd alex lge alex acd 19
('lex', '9')
{'n1': 'lex', 'n2': '9'}
3.6 re.findall(pattern, string[, flags])函数(常用)
findall(pattern, string, flags=0)
- pattern: 正则模型
- string : 要匹配的字符串
- falgs : 匹配模式
浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表
注意:一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配
import re
# 无分组
r = re.findall("\d+\w\d+", "a2b3c4d5") # 浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中
print(r) # 注意:匹配成功的字符串,不在参与下次匹配,所以3c4也符合规则但是没匹配到
['2b3', '4d5']
注意:如果没写匹配规则,也就是空规则,返回的是一个比原始字符串多一位的,空字符串列表
import re
# 无分组
r = re.findall("", "a2b3c4d5") # 浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中
print(r) # 注意:如果没写匹配规则,也就是空规则,返回的是一个比原始字符串多一位的,空字符串列表
['', '', '', '', '', '', '', '', '']
注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串
注意:正则只拿组里最后一位,如果规则里只有一个组,匹配到的字符串里在拿组内容是,拿的是匹配到的内容最后一位
import re
origin = "hello alex bcd alex lge alex acd 19"
r = re.findall("(a)*", origin)
print(r)
['', '', '', '', '', '', 'a', '', '', '', '', '', '', '', '', 'a', '', '', '', '', '', '', '', '', 'a', '', '', '', '', 'a', '', '', '', '', '', '']
无分组:匹配所有合规则的字符串,匹配到的字符串放到一个列表中
import re
# 无分组
origin = "hello alex bcd alex lge alex acd 19"
r = re.findall("a\w+", origin) # 浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中
print(r)
['alex', 'alex', 'alex', 'acd']
有分组:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法
import re
origin = "hello alex bcd alex lge alex acd 19"
r = re.findall("a(\w+)", origin) # 有分组:只将匹配到的字符串里,组的部分放到列表里返回
print(r)
['lex', 'lex', 'lex', 'cd']
多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返
相当于在group()结果里再将组的部分,分别,拿出来放入一个元组,最后将所有元组放入一个列表返回
import re
origin = "hello alex bcd alex lge alex acd 19"
# 多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返回
r = re.findall("(a)(\w+)", origin)
print(r)
[('a', 'lex'), ('a', 'lex'), ('a', 'lex'), ('a', 'cd')]
分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
import re
origin = "hello alex bcd alex lge alex acd 19"
# 分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
r = re.findall("(a)(\w+(e))", origin)
print(r)
[('a', 'le', 'e'), ('a', 'le', 'e'), ('a', 'le', 'e')]
?:在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()
import re
origin = "hello alex bcd alex lge alex acd 19"
# ?:在有分组的情况下,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()
b = re.findall("a(?:\w+)", origin)
print(b)
['alex', 'alex', 'alex', 'acd']
3.7 re.split(pattern, string[, maxsplit])函数
根据正则匹配分割字符串,返回分割后的一个列表
split(pattern, string, maxsplit=0, flags=0)
- pattern: 正则模型
- string : 要匹配的字符串
- maxsplit:指定分割个数
- flags : 匹配模式
按照一个字符将全部字符串进行分割
import re
origin = "hello alex bcd alex lge alex acd 19"
r = re.split("a", origin) # 根据正则匹配分割字符串
print(r)
['hello ', 'lex bcd ', 'lex lge ', 'lex ', 'cd 19']
将匹配到的字符串作为分割标准进行分割
import re
origin = "hello alex bcd alex lge alex 2acd 19"
r = re.split("a\w+", origin) # 根据正则匹配分割字符串
print(r)
['hello ', ' bcd ', ' lge ', ' 2', ' 19']
3.8 re.sub(pattern, repl, string[, count])函数
替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0)
- pattern: 正则模型
- repl : 要替换的字符串
- string : 要匹配的字符串
- count : 指定匹配个数
- flags : 匹配模式
import re
origin = "hello alex bcd alex lge alex acd 19"
r = re.sub("a", "替换", origin) # 替换匹配成功的指定位置字符串
print(r)
hello 替换lex bcd 替换lex lge 替换lex 替换cd 19
# re.sub 和分组命名一起使用
s = '''在PyTorch调用CuDNN报错时'''
# (?P<a>[A-z]+)把[A-z]+这个匹配模式命名为“a”,然后通过\g<a>这个语法把命名为“a”的匹配结果拿出来使用
s = re.sub('(?P<a>[A-z]+)', ' \g<a> ', s) # 对英文字母两边添加空格
print(s) # 在 PyTorch 调用 CuDNN 报错时
3.9 re.subn(pattern, repl, string,[, count][, flags])函数
替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
subn(pattern, repl, string, count=0, flags=0)
- pattern: 正则模型
- repl : 要替换的字符串
- string : 要匹配的字符串
- count : 指定匹配个数
- flags : 匹配模式
import re
origin = "hello alex bcd alex lge alex acd 19"
a, b = re.subn("a", "替换", origin) # 替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
print(a)
print(b)
hello 替换lex bcd 替换lex lge 替换lex 替换cd 19
4
四、注意事项
-
r原生字符:让在python里有特殊意义的字符如\b,转换成原生字符(就是去除它在python的特殊意义),不然会给正则表达式有冲突,为了避免这种冲突可以在规则前加原始字符r
-
正则表达式,返回类型为表达式对象的,如:<_sre.SRE_Match object; span=(6, 7), match='a'>,返回对象时,需要用正则方法取字符串,方法有:
- group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
- groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
- groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
-
匹配到的字符串里出现空字符:注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串
-
()分组:注意:分组的意义,就是在匹配成功的字符串中,再提取()里的内容,也就是组里面的字符串
-
?:在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()
五、计算器(经典)
基于递归和正则将下面的字符串翻译成计算器表达式,并且获取最终结果:expression='-1-2\\\*((60+2\\\*(-3-40.0+42425/5)\\\*(9-2\\\*5/3+357/553/3\\\*99/4\\\*2998+10\\\*568/14))-(-4\\\*3)/(16-3\\\*2))+56+(56-45)'
如果代码正确,计算结果为:-553071849.7670887
提示:content=re.search('\((\\\[\-\+\\\\*\/\\\]\\\*\d+\.?\d\\\*)+\)',expression).group() #(-3-40.0/5)
5.1 复杂版本
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
该计算器思路:
1、递归寻找表达式中只含有 数字和运算符的表达式,并计算结果
2、由于整数计算会忽略小数,所有的数字都认为是浮点型操作,以此来保留小数
使用技术:
1、正则表达式
2、递归
"""
import re
def compute_mul_div(arg):
""" 操作乘除
:param expression:表达式
:return:计算结果
"""
val = arg[0]
mch = re.search('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val)
if not mch:
return
content = re.search('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val).group()
if len(content.split('*')) > 1:
n1, n2 = content.split('*')
value = float(n1) * float(n2)
else:
n1, n2 = content.split('/')
value = float(n1) / float(n2)
before, after = re.split('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val, 1)
new_str = "%s%s%s" % (before, value, after)
arg[0] = new_str
compute_mul_div(arg)
def compute_add_sub(arg):
""" 操作加减
:param expression:表达式
:return:计算结果
"""
while True:
if arg[0].__contains__('+-') or arg[0].__contains__("++") or arg[
0].__contains__('-+') or arg[0].__contains__("--"):
arg[0] = arg[0].replace('+-', '-')
arg[0] = arg[0].replace('++', '+')
arg[0] = arg[0].replace('-+', '-')
arg[0] = arg[0].replace('--', '+')
else:
break
if arg[0].startswith('-'):
arg[1] += 1
arg[0] = arg[0].replace('-', '&')
arg[0] = arg[0].replace('+', '-')
arg[0] = arg[0].replace('&', '+')
arg[0] = arg[0][1:]
val = arg[0]
mch = re.search('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val)
if not mch:
return
content = re.search('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val).group()
if len(content.split('+')) > 1:
n1, n2 = content.split('+')
value = float(n1) + float(n2)
else:
n1, n2 = content.split('-')
value = float(n1) - float(n2)
before, after = re.split('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val, 1)
new_str = "%s%s%s" % (before, value, after)
arg[0] = new_str
compute_add_sub(arg)
def compute(expression):
""" 操作加减乘除
:param expression:表达式
:return:计算结果
"""
inp = [expression, 0]
# 处理表达式中的乘除
compute_mul_div(inp)
# 处理
compute_add_sub(inp)
if divmod(inp[1], 2)[1] == 1:
result = float(inp[0])
result = result * -1
else:
result = float(inp[0])
return result
def exec_bracket(expression):
""" 递归处理括号,并计算
:param expression: 表达式
:return:最终计算结果
"""
# 如果表达式中已经没有括号,则直接调用负责计算的函数,将表达式结果返回,如:2*1-82+444
if not re.search('\(([\+\-\*\/]*\d+\.*\d*){2,}\)', expression):
final = compute(expression)
return final
# 获取 第一个 只含有 数字/小数 和 操作符 的括号
# 如:
# ['1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
# 找出:(-40.0/5)
content = re.search('\(([\+\-\*\/]*\d+\.*\d*){2,}\)', expression).group()
# 分割表达式,即:
# 将['1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
# 分割更三部分:['1-2*((60-30+( (-40.0/5) *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
before, nothing, after = re.split('\(([\+\-\*\/]*\d+\.*\d*){2,}\)',
expression, 1)
print('before:', expression)
content = content[1:len(content) - 1]
# 计算,提取的表示 (-40.0/5),并活的结果,即:-40.0/5=-8.0
ret = compute(content)
print('%s=%s' % (content, ret))
# 将执行结果拼接,['1-2*((60-30+( -8.0 *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
expression = "%s%s%s" % (before, ret, after)
print('after:', expression)
print("=" * 10, '上一次计算结束', "=" * 10)
# 循环继续下次括号处理操作,本次携带者的是已被处理后的表达式,即:
# ['1-2*((60-30+ -8.0 *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
# 如此周而复始的操作,直到表达式中不再含有括号
return exec_bracket(expression)
# 使用 __name__ 的目的:
# 只有执行 python index.py 时,以下代码才执行
# 如果其他人导入该模块,以下代码不执行
if __name__ == "__main__":
print(
'*' * 20, "请计算表达式:",
"1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )",
'*' * 20)
# inpp = '1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) '
inpp = '-1-2*((60+2*(-3-40.0+42425/5)*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)'
# inpp = "1-2*-30/-12*(-20+200*-3/-200*-300-100)"
# inpp = "1-5*980.0"
inpp = re.sub('\s*', '', inpp)
# 表达式保存在列表中
result = exec_bracket(inpp)
print(result)
******************** 请计算表达式: 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) ********************
before: -1-2*((60+2*(-3-40.0+42425/5)*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)
-3-40.0+42425/5=8442.0
after: -1-2*((60+2*8442.0*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*((60+2*8442.0*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)
9-2*5/3+357/553/3*99/4*2998+10*568/14=16378.577154912598
after: -1-2*((60+2*8442.0*16378.577154912598)-(-4*3)/(16-3*2))+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*((60+2*8442.0*16378.577154912598)-(-4*3)/(16-3*2))+56+(56-45)
60+2*8442.0*16378.577154912598=276535956.68354434
after: -1-2*(276535956.68354434-(-4*3)/(16-3*2))+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*(276535956.68354434-(-4*3)/(16-3*2))+56+(56-45)
-4*3=-12.0
after: -1-2*(276535956.68354434--12.0/(16-3*2))+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*(276535956.68354434--12.0/(16-3*2))+56+(56-45)
16-3*2=10.0
after: -1-2*(276535956.68354434--12.0/10.0)+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*(276535956.68354434--12.0/10.0)+56+(56-45)
276535956.68354434--12.0/10.0=276535957.8835443
after: -1-2*276535957.8835443+56+(56-45)
========== 上一次计算结束 ==========
before: -1-2*276535957.8835443+56+(56-45)
56-45=11.0
after: -1-2*276535957.8835443+56+11.0
========== 上一次计算结束 ==========
-553071849.7670887
5.2 简单易懂版
import re
expression = '-1-2*((60+2*(-3-40.0+42425/5)*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)'
question = eval(expression)
print(question)
def arithmetic(expression='1+1'):
# content = re.search('\(([\-\+\*\/]*\d+\.?\d*)+\)', expression) # (-3-40.0/5)
content = re.search('\(([-+*/]*\d+\.?\d*)+\)', expression) # (-3-40.0/5)
if content:
content = content.group()
content = content[1:-1]
print('content:', content)
replace_content = next_arithmetic(content)
expression = re.sub('\(([-+*/]*\d+\.?\d*)+\)',
replace_content,
expression,
count=1)
print('next_expression:', expression)
else:
answer = next_arithmetic(expression)
return answer
return arithmetic(expression)
def next_arithmetic(content):
while True:
next_content_mul_div = re.search('\d+\.?\d*[*/][-+]?\d+\.?\d*',
content) # 找出带有*/的式子
if next_content_mul_div: # 如果content含有带有*/的式子
next_content_mul_div = next_content_mul_div.group()
print('next_content_mul_div:', next_content_mul_div)
mul_div_content = mul_div(next_content_mul_div) # 计算出带有*/的式子
print('mul_div_content:', mul_div_content)
content = re.sub('\d+\.?\d*[*/][-+]?\d+\.?\d*',
str(mul_div_content),
content,
count=1) # 把带有*/的式子计算出来后替换掉
print('content:', content)
continue
next_content_add_sub = re.search('-?\d+\.?\d*[-+][-+]?\d+\.?\d*',
content) # 找出带有-+的式子
if next_content_add_sub: # 如果content含有带有+-的式子
next_content_add_sub = next_content_add_sub.group()
print('next_content_add_sub:', next_content_add_sub)
add_sub_content = add_sub(next_content_add_sub) # 计算出带有-+的式子
print('add_sub_content:', add_sub_content)
add_sub_content = str(add_sub_content)
content = re.sub('-?\d+\.?\d*[-+]-?\d+\.?\d*',
str(add_sub_content),
content,
count=1) # 把带有-+的式子计算出来后替换掉
print('content:', content)
continue
else:
break
return content
def add_sub(content):
if '+' in content:
content = content.split('+')
print(content)
content = float(content[0]) + float(content[1])
return content
elif '-' in content:
content = content.split('-')
# 减法情况有多种
if content[0] == '-' and content[2] == '-':
# content = content.split('-')
print(content)
content = -float(content[1]) - float(content[-1])
return content
if content[0] == '-':
# content = content.split('-')
print(content)
content = -float(content[1]) - float(content[-1])
return content
if content[1] == '-' and content[2] == '-':
# content = content.split('-')
print(content)
content = -float(content[0]) + float(content[-1])
return content
if content[1] == '':
# content = content.split('-')
print(content)
content = float(content[0]) - float(content[2])
return content
if content[0] == '' and content[2] != '':
print(content)
content = -float(content[1]) - float(content[2])
return content
if content[0] == '' and content[2] == '':
print(content)
content = -float(content[1]) + float(content[3])
return content
else:
# content = content.split('-')
print(content)
content = float(content[0]) - float(content[1])
return content
def mul_div(content):
if '*' in content:
content = content.split('*')
print(content)
content = float(content[0]) * float(content[1])
return content
elif '/' in content:
content = content.split('/')
print(content)
content = float(content[0]) / float(content[1])
return content
# expression = '1-2*((60+2*(-3-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))'
expression = '-1-2*((60+2*(-3-40.0+42425/5)*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)'
answer = arithmetic(expression)
print(answer)
-553071849.7670887
content: -3-40.0+42425/5
next_content_mul_div: 42425/5
['42425', '5']
mul_div_content: 8485.0
content: -3-40.0+8485.0
next_content_add_sub: -3-40.0
['', '3', '40.0']
add_sub_content: -43.0
content: -43.0+8485.0
next_content_add_sub: -43.0+8485.0
['-43.0', '8485.0']
add_sub_content: 8442.0
content: 8442.0
next_expression: -1-2*((60+2*8442.0*(9-2*5/3+357/553/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))+56+(56-45)
content: 9-2*5/3+357/553/3*99/4*2998+10*568/14
next_content_mul_div: 2*5
['2', '5']
mul_div_content: 10.0
content: 9-10.0/3+357/553/3*99/4*2998+10*568/14
next_content_mul_div: 10.0/3
['10.0', '3']
mul_div_content: 3.3333333333333335
content: 9-3.3333333333333335+357/553/3*99/4*2998+10*568/14
next_content_mul_div: 357/553
['357', '553']
mul_div_content: 0.6455696202531646
content: 9-3.3333333333333335+0.6455696202531646/3*99/4*2998+10*568/14
next_content_mul_div: 0.6455696202531646/3
['0.6455696202531646', '3']
mul_div_content: 0.21518987341772153
content: 9-3.3333333333333335+0.21518987341772153*99/4*2998+10*568/14
next_content_mul_div: 0.21518987341772153*99
['0.21518987341772153', '99']
mul_div_content: 21.303797468354432
content: 9-3.3333333333333335+21.303797468354432/4*2998+10*568/14
next_content_mul_div: 21.303797468354432/4
['21.303797468354432', '4']
mul_div_content: 5.325949367088608
content: 9-3.3333333333333335+5.325949367088608*2998+10*568/14
next_content_mul_div: 5.325949367088608*2998
['5.325949367088608', '2998']
mul_div_content: 15967.196202531646
content: 9-3.3333333333333335+15967.196202531646+10*568/14
next_content_mul_div: 10*568
['10', '568']
mul_div_content: 5680.0
content: 9-3.3333333333333335+15967.196202531646+5680.0/14
next_content_mul_div: 5680.0/14
['5680.0', '14']
mul_div_content: 405.7142857142857
content: 9-3.3333333333333335+15967.196202531646+405.7142857142857
next_content_add_sub: 9-3.3333333333333335
['9', '3.3333333333333335']
add_sub_content: 5.666666666666666
content: 5.666666666666666+15967.196202531646+405.7142857142857
next_content_add_sub: 5.666666666666666+15967.196202531646
['5.666666666666666', '15967.196202531646']
add_sub_content: 15972.862869198312
content: 15972.862869198312+405.7142857142857
next_content_add_sub: 15972.862869198312+405.7142857142857
['15972.862869198312', '405.7142857142857']
add_sub_content: 16378.577154912598
content: 16378.577154912598
next_expression: -1-2*((60+2*8442.0*16378.577154912598)-(-4*3)/(16-3*2))+56+(56-45)
content: 60+2*8442.0*16378.577154912598
next_content_mul_div: 2*8442.0
['2', '8442.0']
mul_div_content: 16884.0
content: 60+16884.0*16378.577154912598
next_content_mul_div: 16884.0*16378.577154912598
['16884.0', '16378.577154912598']
mul_div_content: 276535896.68354434
content: 60+276535896.68354434
next_content_add_sub: 60+276535896.68354434
['60', '276535896.68354434']
add_sub_content: 276535956.68354434
content: 276535956.68354434
next_expression: -1-2*(276535956.68354434-(-4*3)/(16-3*2))+56+(56-45)
content: -4*3
next_content_mul_div: 4*3
['4', '3']
mul_div_content: 12.0
content: -12.0
next_expression: -1-2*(276535956.68354434--12.0/(16-3*2))+56+(56-45)
content: 16-3*2
next_content_mul_div: 3*2
['3', '2']
mul_div_content: 6.0
content: 16-6.0
next_content_add_sub: 16-6.0
['16', '6.0']
add_sub_content: 10.0
content: 10.0
next_expression: -1-2*(276535956.68354434--12.0/10.0)+56+(56-45)
content: 276535956.68354434--12.0/10.0
next_content_mul_div: 12.0/10.0
['12.0', '10.0']
mul_div_content: 1.2
content: 276535956.68354434--1.2
next_content_add_sub: 276535956.68354434--1.2
['276535956.68354434', '', '1.2']
add_sub_content: 276535955.48354435
content: 276535955.48354435
next_expression: -1-2*276535955.48354435+56+(56-45)
content: 56-45
next_content_add_sub: 56-45
['56', '45']
add_sub_content: 11.0
content: 11.0
next_expression: -1-2*276535955.48354435+56+11.0
next_content_mul_div: 2*276535955.48354435
['2', '276535955.48354435']
mul_div_content: 553071910.9670887
content: -1-553071910.9670887+56+11.0
next_content_add_sub: -1-553071910.9670887
['', '1', '553071910.9670887']
add_sub_content: -553071911.9670887
content: -553071911.9670887+56+11.0
next_content_add_sub: -553071911.9670887+56
['-553071911.9670887', '56']
add_sub_content: -553071855.9670887
content: -553071855.9670887+11.0
next_content_add_sub: -553071855.9670887+11.0
['-553071855.9670887', '11.0']
add_sub_content: -553071844.9670887
content: -553071844.9670887
-553071844.9670887

 浙公网安备 33010602011771号
浙公网安备 33010602011771号