

字符串、列表、字典
学习内容总结:


一,字符串 (str) 是重要的......... 创建方式 str1 = "abc" str2 = str() 常用操作 s.replace('a', 'b') 将s中的a替换成b str.capitalize() 将str中的首个字母大写 str.upper() 大写 str.lower() 小写 S.swapcase()大小写互转 str.startswith('xx') 判断是否由XX开头 str.endswith('g') 判断是否由g结尾 str.isnumeric() 判断是否为数字 list = str.split('.') 将list用 . 分割成列表,但是list中必须有 . '.'.join(list) 用.将list连接上 s.strip() 去除空格 sStr1.index(sStr2)或者sStr1.find(sStr2) 查找 len(sStr1) 字符串长度 split() 分割 a[0:3] 切片,指的是a中的>=0<3中间的元素 sStr1 = sStr1[::-1] 将sStr1字符串反转并赋值给sStr1 附加上:字符串中的转义字符: \\ 斜杠 \' 单引号 \" 双引号 \a 系统喇叭 \b 退格符 \n 换行符 \t 横向制表符 \v 纵向制表符 \r 回车符 \f 换页符 \o 八进制数代表的字符 \x 十六进制数代表的字符 \000 终止符,忽略\000后的全部字符 二,列表 (list 有序的,可变的)是重要的......... 创建方式 listA = ['a', 'b', 'c', 1, 2] list(obj) #把对象转换成列表,obj可以是元组,字典,字符串等 注意:列表可以支持多层嵌套。 注意:如果字符串中需要包含双引号,不要忘记转义 ,“\” “\” 常用操作 list.append() 追加成员,成员数据 list.pop() 删除成员,删除第i个成员,注意:可以单独给删除的给一个变量 list.count(x) 计算列表中参数x出现的次数 list.remove()删除列表中的成员,直接删除成员i list.extend(L)向列表中追加另一个列表L list.reverse()将列表中成员的顺序反转 list.index(x)获得参数x在列表中的位置 list.sort()将列表中的成员排序 list.insert()向列表中插入数据insert(a,b)向列表中插入数据 list.isinstance() 函数可以用来判断特定标识符是否包含某个特定类型的数据 三,元祖 (tuple,有序的,不可修改的)需要增加常用操作 创建方式 tuple1 =() tuple1 = tuple({1,2,3,4,5,'6'}) tuple1 = (1, 2, '3', 4, '5') 注意:定义了一个元组之后就无法再添加或修改元组中的元素,但是可以给 孙子以下(除元祖外)的元素修改,添加等 tuple1[-1]指的是,从元祖中最后一个开始计算 四,字典 (Dictionary,无序的,可修改的)是重要的......... 创建方式 ict1 = {'name' : 'LiuZhichao', 'age' : 24, 'sex' : 'Male'} ict1 = dict() 常用操作 dic.clear()清空字典 dic.keys()获得键的列表 dic.values()获得值的列表 dic.copy()复制字典 dic.pop(k)删除键k dic.get(k)获得键k的值 dic.update()更新成员,若成员不存在,相当于加入 dic.items()获得由键和值组成的列表 四,set (无序的,不能重复的) 创建方式 set1 = {1, 2, 3, 4, 5} set2 = set() 常用操作 set2.add(10) #添加新元素 10,要保证set2中没有10 否则就添加一个10 或添加一个obj set3 = frozenset(list1) set3.add(10) 固定集合不能添加元素 s.issubset(t) #如果s是t的子集,返回True,否则返回Falses. issuperset(t) #如果s是t的超集,返回True,否则返回Falses. union(t) #返回一个新集合, 该集合是s和t的并集 s.intersection(t) #返回一个新集合, 该集合是s和t的交集 s.difference(t) #返回一个新集合, 该集合是s的成员, 但不是t的成员, 即返回s不同于t的元素 s.copy() #返回一个s的浅拷贝, 效率比工厂要好 #不明白 s.update(t) #用t中的元素 修改s,即s现在包含s或t的成员 s.difference_update(t) #s存在,t不存在,更新t s.remove(obj) #从集合s中删除对象obj,如果obj不是集合s中的元素(obj not in s),将引发keyError错误 s.discard(obj) #如果obj是集合s中的元素,从集合s中删除对象obj s.pop() #删除集合s中得任意一个对象,并返回它 s.clear() #删除集合s中的所有元素 intersection() 方法返回一个新集合,包含在两个集合中同时出现的所有元素。 union() 方法返回一个新集合,包含在两个 集合中不一样的元素。 symmetric_difference() 方法返回一个新集合,包含所有只在其中一个集合中出现的元素。
#字符串
s="python"
# 索引
s[1]
print(s[1])
#切片
s[2:4]
print(s[2:4])
# 大小写
s.capitalize()
s.upper()
s.lower()
s.swapcase()
s.title()
# 位置
s.center(20)
s.startswith()
s.endswith()
s.expandtabs()
#计数
s.count()
# 修改
s.find()
s.index()
s.strip()
s.split()
s.replace()
s.format()
s.isalnum()
s.isalpha()
s.isdigit()
# 列表
s1=["alex","ritian",1,2,3]
#索引
s1[2]
#切片
s1[2:4]
#增加
s1.append()
s1.insert()
s1.extend()
#删
s1.pop()
s1.remove()
s1.clear()
del s1[2]
#改
s1[2]=""
s1[0:2]=""
#查
print(s1[2])
#计数
s1.count()
s1.sort()
s1.reverse()
# 字典
s2={"name":["xiaomei","me"],"age":["26","25"]}
#索引
print(s2["name"])
#增加
s2[""]=""
s2.setdefault("")
#删
s2.pop("")
s2.clear()
del s2[""]
#改
s2[""]=""
s2.update(s1)
#查
print(s2[""])
print(s2.get(""))
print(s2.keys())
print(s2.values())
print(s2.items())
1、 模块
写模块的时候尽量不要和系统自带的模块的名字相同
调用模块的时候,会先在当前目录下查找是否有这个模块,然后再会如python的环境变量中查找
a.模块1:sys
代码如下:
1 import sys 2 print(sys.path)
该代码的作用就是打印出python环境变量如下所示:
D:\\python培训\\s14\\day2
D:\\python培训\\s14
D:\\python35\\python35.zip
D:\\python35\\DLLs
D:\\python35\\lib
D:\\python35
D:\\python35\\lib\\site-packages 第三方库会放在这里
print(sys.argv) #打印当前文件的相对路径,但是在pycharm中打印的是绝对路径 打印结果如下所示:
['D:/python培训/s14/day2/sys_mod.py']
b. 模块2:os
代码如下:
1 import os
2 cmd = os.system("dir") #执行命令,不保存结果
3 cmd_res = os.popen("dir").read() #执行命令,保存结果
4 print("--->",cmd_res)
5 os.mkdir("new_dir") #创建目录
2、数据类型:
数字:整型(int) float(浮点型),无论多大在3.0python中都是int 即3.0没有长整型这个概念
布尔值:真或假 1或0
字符串
关于字符串的操作例子:

name="zhaofan"
print(name.capitalize()) #将字符串首字母大写
print(name.count("a")) #查找字符串中a的个数
print(name.center(50,"-")) #显示结果如下:
---------------------zhaofan----------------------
print(name.endswith("an")) #判断字符串的结尾是否为an
print("My name is zhaofan".find("name")) #返回字符串的索引
print(name.isalnum()) #如果字符串中包括文字和数字的都返回true
print("zhaofan".isalpha()) #如果字符串中都为字母则返回true
print("123123".isdigit()) #判断字符串中是否都为数字
print("ZZZZ".islower()) #判断字符串是否为小写
name.strip() 去掉前和后面的空格
name.lstrip()去掉左边的空格
name.rstrip()去掉右边的空格
name.replace() 替换
name.rfind(“字符”) 查找字符串中最右边的那个字符的下标
name.split() 分割字符串,默认是以空格分割
python3中的不等于只能用!= 取消了2.0中的<>
3、列表
列表的特点:列表是有序的,列表可以有重复的值
list[数字] 就可以取出列表中相对应的值
关于列表切片:
list[1:2]从第二个位置开始取,包括其实位置,但是不包含结尾,即取出列表的第二个值list[1],list[1:3]就可以取出第2个和第3个值
list[-1] 取出列表的最后一个值
list[-2]取出列表倒数两个值
list[:3]取出列表的前两个值
列表的增加
list.append(“元素名”) 给列表的最后追加一个元素
列表的插入
list.insert(1,“元素名”)在列表的第一个第2个位置插入一个元素
列表的修改
name[2]=”新的元素名” 将列表的第3个元素进行更改
列表的删除
name.remove(“元素名”)删除列表中对应的元素
del names[1] 删除列表中相应的元素
name.pop()如果没有输出下标则删除列表中的最后一个值,如果删除数字下标就可以删除相对应的元素
查找列表中某个元素的位置,即下标
name.index(“元素名”)
name.clear() 情况列表
name.count(“元素名”) 找出列表的某个元素的个数
name.reverse() 将列表中元素进行反转
name.sort()将列表元素进行排序
name.extend(names2) 将name2并入到name列表中
del name2 就可以删除name2列表
4、关于列表的深浅拷贝
首先浅拷贝
name.copy() 就是浅拷贝
下面是关于浅拷贝的代码例子:
1 names = ["ZhaFan","Dean",[1,2,3,4],"Dean","Dan","jack","Yes","A","a"] 2 names2 = names.copy() 3 print(names) 4 print(names2) 5 names2[1]="zhaofan" 6 print(names) 7 print(names2) 8 9 names[2][0]=100 10 print(names) 11 print(names2)
上述代码的的运行结果如下:
D:\python35\python.exe D:/python培训/s14/day2/copy_qian.py
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'zhaofan', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [100, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'zhaofan', [100, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
总结:从上述结果可以看出,names.copy()复制出一个与names列表一样的列表当修改列表中的内容时,
如果列表中嵌套有列表,那么如果修改是列表的第一层,那么只会更改修改的那个列表,如果修改的是嵌套里的列表的内容,则两个列表的内容的都会更改
如下图:
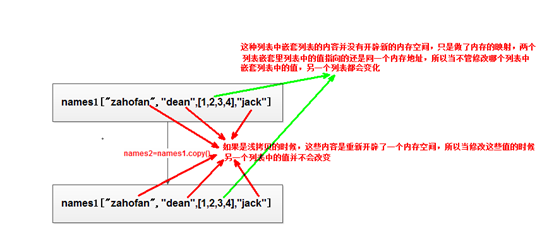
下面是关于深拷贝
深拷贝需要借助模块copy
深拷贝的时候,就是完全都开辟出另外一个内存空间,及修改其中一个列表中任意一个值,另外一个列表都不会发生变化:
代码例子如下:
1 import copy 2 names = ["ZhaFan","Dean",[1,2,3,4],"Dean","Dan","jack","Yes","A","a"] 3 names2 = copy.deepcopy(names) 4 print(names) 5 print(names2) 6 names[2][1]=10000 7 print(names) 8 print(names2)
运行结果如下:
D:\python35\python.exe D:/python培训/s14/day2/copy_deep.py
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [1, 10000, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
['ZhaFan', 'Dean', [1, 2, 3, 4], 'Dean', 'Dan', 'jack', 'Yes', 'A', 'a']
从代码可以看出,修改一起种一个列表中的内容,另外一个并不会发生变化
列表中打印每个元素
for I in names:
print I
5、元组tuple
元组就是不可变的列表,即tuple一旦被初始化就不能修改,所以tuple不能用类似于list列表中的append(),insert()等这些修改的方法
关于元组的代码例子如下:
1 tt_tuple = ("zhaofan","dean","jack")
2 print(tt_tuple.count("dean"))
3 print(tt_tuple.index("jack"))
4 print(tt_tuple[-1])
运行结果如下:
D:\python35\python.exe D:/python培训/s14/day2/tuple_ex.py
1
2
jack
7、关于用list列表编写一个简单的购物车的例子:
程序要求:
a. 启动程序后,让用户输入工资,然后打印商品列表
b. 允许用户根据商品编号购买商品
c. 用户选择商品后,检测余额是否够,够就直接扣款,不够就提示用户
d. 可以随时退出,退出时,打印已经购买的商品和余额
1 goods_list=[["Iphone",5288],["Bike",1200],["Coffee",20],["Ipad",1800]]
2 shopping_list=[]
3 user_salary = input("请输入你的工资是:")
4 if user_salary.isdigit() is True:
5 user_salary = int(user_salary)
6 while True:
7 for key,iterm in enumerate(goods_list):
8 print(key,iterm[0],iterm[1])
9 user_choice = input("你想要买什么(输入商品的序号,q表示退出系统):")
10 if user_choice.isdigit() is True:
11 user_choice=int(user_choice)
12 if user_choice > len(goods_list):
13 print("\033[31;1m你输入的商品编号不存在\033[0m")
14 continue
15 if goods_list[user_choice][1] < user_salary and user_choice > 0:
16 shopping_list.append(goods_list[user_choice])
17 user_salary -= goods_list[user_choice][1]
18 print("\033[31;1m%s\033[0m 已经被添加到购物车,你的钱还剩余\033[31;1m%s\033[0m" %(goods_list[user_choice][0],user_salary))
19 continue
20 else:
21 print("\033[31;1m你没有足够的钱了,你只剩下%s人民币了\033[0m" %user_salary)
22
23 if user_choice == "q":
24 print("你的购物车".center(50,"-"))
25 for key,iterm in enumerate(shopping_list):
26 print(key,iterm[0],iterm[1])
27 print("你还剩余\033[31;1m%s\033[0m人民币" %user_salary)
28 break
29 else:
30 print("请输入正确的工资")
8、关于字典dict
字典有如下特点:
1) key-value格式,key是唯一的
2) 无序的
3) 查询速度快
一个简单的dcit字典的例子:
1 info = {'name':'Dean',
2 'job':'IT',
3 'age':23,
4 'company':'XDHT'
5 }
6 print(info)
运行结果如下:
D:\python35\python.exe D:/python培训/s14/day2/dcit-2.py
{'company': 'XDHT', 'name': 'Dean', 'age': 23, 'job': 'IT'}
从这里也可看出字典是无序的
字典的增删查改

还有一种删除数据,但是如果字典为空的时候会报错,info.pop("name")
代码例子如下:
1 info = {'name':'Dean',
2 'job':'IT',
3 'age':23,
4 'company':'XDHT'
5 }
6 print(info)
7 info.pop("name")
程序运行结果如下:
D:\python35\python.exe D:/python培训/s14/day2/dcit-2.py
{'name': 'Dean', 'company': 'XDHT', 'age': 23, 'job': 'IT'}
{'company': 'XDHT', 'age': 23, 'job': 'IT'}
Process finished with exit code 0
但是如果用info.pop()的时候,删除的数据不存在就会报错
将dict的key,value转换成列表的形式显示
print(info.items())
效果如下:
D:\python35\python.exe D:/python培训/s14/day2/dcit-2.py
dict_items([('job', 'IT'), ('company', 'XDHT'), ('age', 23), ('name', 'Dean')])
特别说明一下,在python3.0中取消了has_key()的用法
而代替的方法是可以in或者not in
代码例子:
if "name" in info:
print("ok")
根据列表abc来创建dict里的key,后面的test是默认的value,如果不指定就是None
info = {}
info = info.fromkeys(["a","b","c"],"test")
print(info)
运行结果如下:
info = {}
info = info.fromkeys(["a","b","c"],"test")
print(info)
info.keys() #打印出字典的key
info.values() #打印出字典的value
方法1
for key in info:
print(key,info[key])
方法2
for k,v in info.items():
print(k,v)
在实际中尽量不要用方法2,因为方法2的效率比方法1的效率低,方法2会先把dict字典转换成list,所以数据大的时候不要用
9、关于字典的嵌套,代码例子如下:
1 menu_dict={
2 "河南省":{
3 "焦作市":{
4 "修武县":{"AA","BB","CC"},
5 "武陟县":{"DD","EE","FF"},
6 "博爱县":{"GG","HH","II"}
7 },
8 "新乡市":{
9 "辉县":{"AA","BB","CC"},
10 "封丘县":{"DD","EE","FF"},
11 "延津县":{"GG","HH","II"}
12 }
13 },
14 "河北省":{
15 "邢台":{
16 "宁晋县":{"AA","BB","CC"},
17 "内丘县":{"DD","EE","FF"},
18 "邢台县":{"GG","HH","II"}
19 },
20 "唐山":{
21 "乐亭县":{"AA","BB","CC"},
22 "唐海县":{"DD","EE","FF"},
23 "玉田县":{"GG","HH","II"}
24 }
25 }
26 }
