Hadoop Ubuntu18.04下安装&测试
引子
因为工作需要,接触下大数据,那么接下来一些学习笔记会陆续记录着,OK,让我们开始吧。
一、Hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
二、安装
1、下载
Hadoop
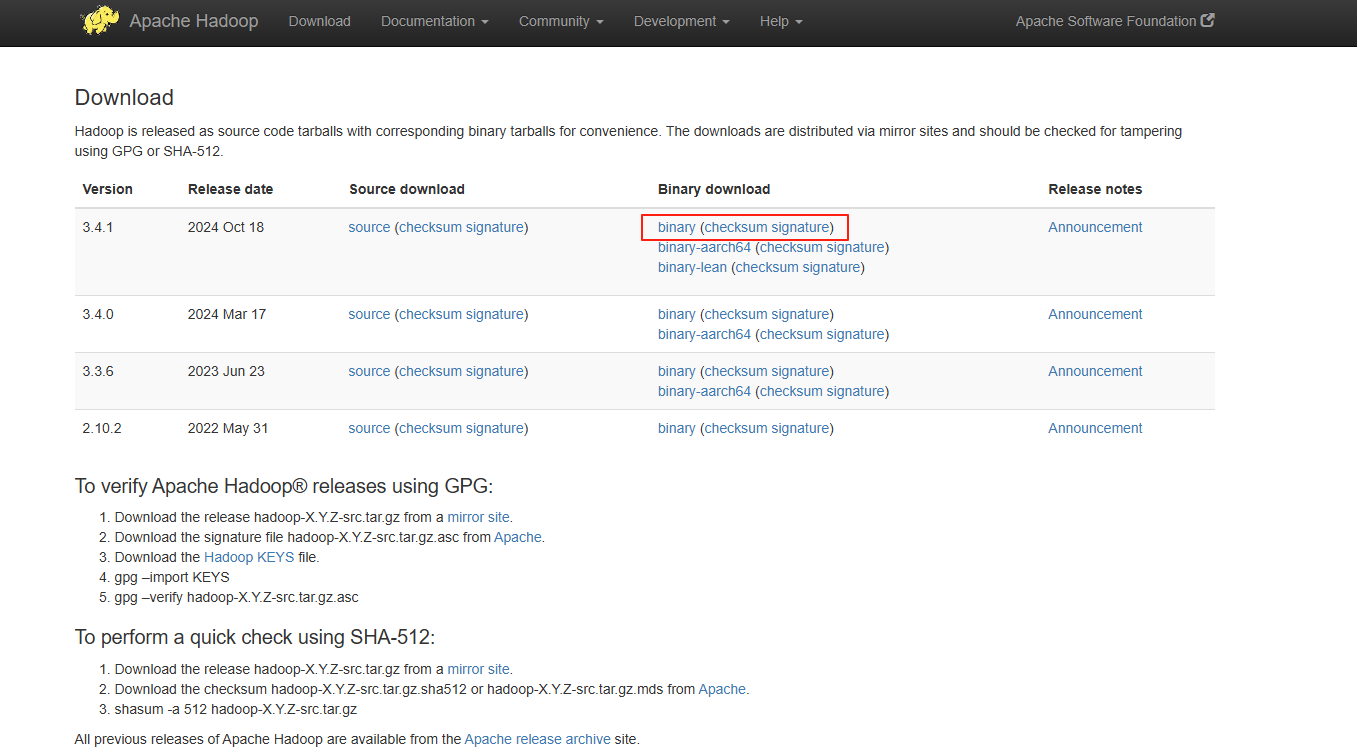
Javac
2、安装
Java
mkdir /urs/local/hadoop
tar -zxvf jdk-8u221-linux-x64.tar.gz
mkdir /usr/local/hadoop
tar -zxvf hadoop-3.4.1.tar.gz
3、配置
vi /usr/local/hadoop/hadoop-3.4.1/etc/hadoop/hadoop-env.sh
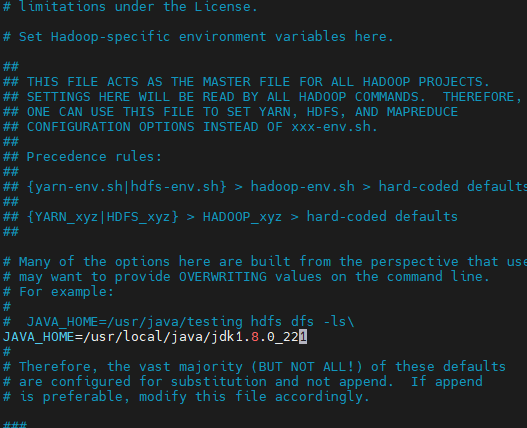
vi /etc/profile
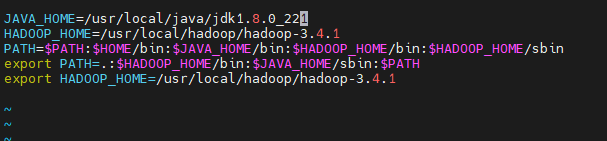
source /etc/profile
验证:
hadoop version

三、测试
1、修改配置文件
vi /usr/local/hadoop/hadoop-3.4.1/etc/hadoop/core-site.xml
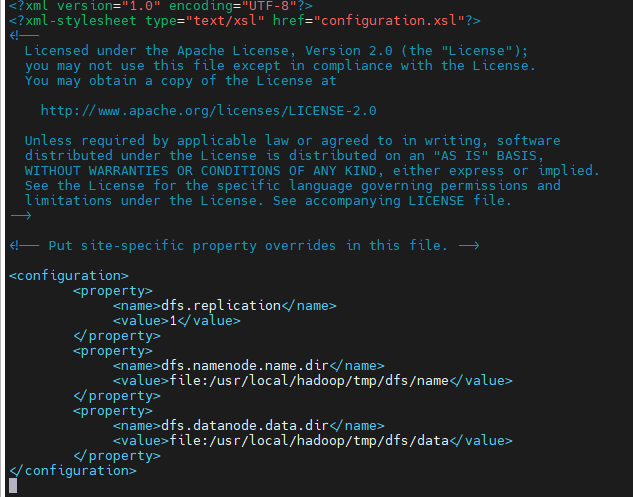
vi /usr/local/hadoop/hadoop-3.4.1/etc/hadoop/hdfs-site.xml
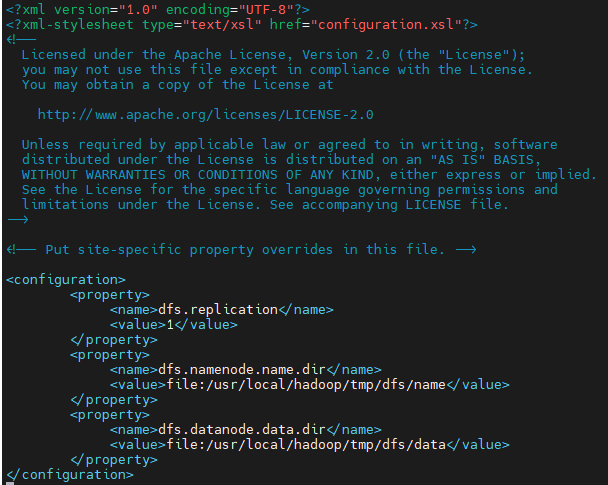
2、测试,启动
hadoop namenode -format

3、官方例子
cd /usr/local/hadoop/hadoop-3.4.1
mkdir input
cp ./etc/hadoop//*.xml input/
hadoop jar /usr/local/hadoop/hadoop-3.4.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar grep ./input/ ./output 'df[a-z.]+'
cat ./output/*


 浙公网安备 33010602011771号
浙公网安备 33010602011771号