
智谱AI Emu3环境搭建&推理测试
OpenAI前首席科学家、联合创始人Ilya Sutskever曾在多个场合表达观点:只要能够非常好的预测下一个token,就能帮助人类达到通用人工智能(AGI)。虽然,下一token预测已在大语言模型领域实现了ChatGPT等突破,但是在多模态模型中的适用性仍不明确。多模态任务仍然由扩散模型(如Stable Diffusion)和组合方法(如结合 CLIP视觉编码器和LLM)所主导。2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。OK,那就让我们开始吧。
一、模型介绍
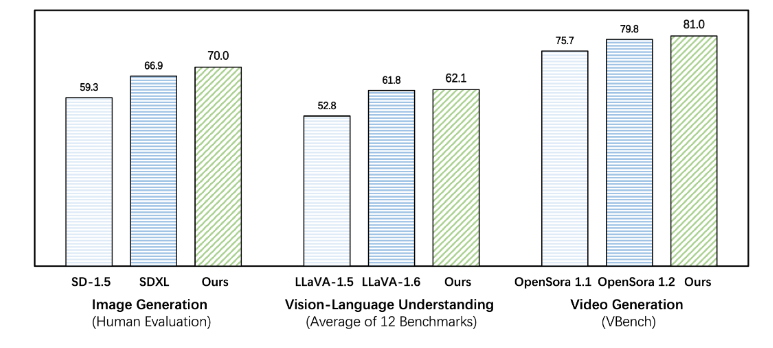
Emu3在图像生成、视频生成、视觉语言理解等任务中超过了SDXL 、LLaVA、OpenSora等知名开源模型,但是无需扩散模型、CLIP视觉编码器、预训练的LLM等技术,只需要预测下一个token。Emu3提供了一个强大的视觉tokenizer,能够将视频和图像转换为离散token。这些视觉离散token可以与文本tokenizer输出的离散token一起送入模型中。与此同时,该模型输出的离散token可以被转换为文本、图像和视频,为Any-to-Any的任务提供了更加统一的研究范式。而在此前,社区缺少这样的技术和模型。
二、环境搭建
模型下载:
pip install modelscope
modelscope download --model BAAI/Emu3-Gen
代码下载:
git clone
docker run -it --rm --gpus=all -v /datas/work/zzq:/workspace pytorch/pytorch:2.2.2-cuda12.1-cudnn8-devel bash
cd :/workspace/Emu3/Emu3-main
pip install -r requirements.txt -i
三、推理测试
cd /workspace/Emu3/Emu3-main
python image_generation.py
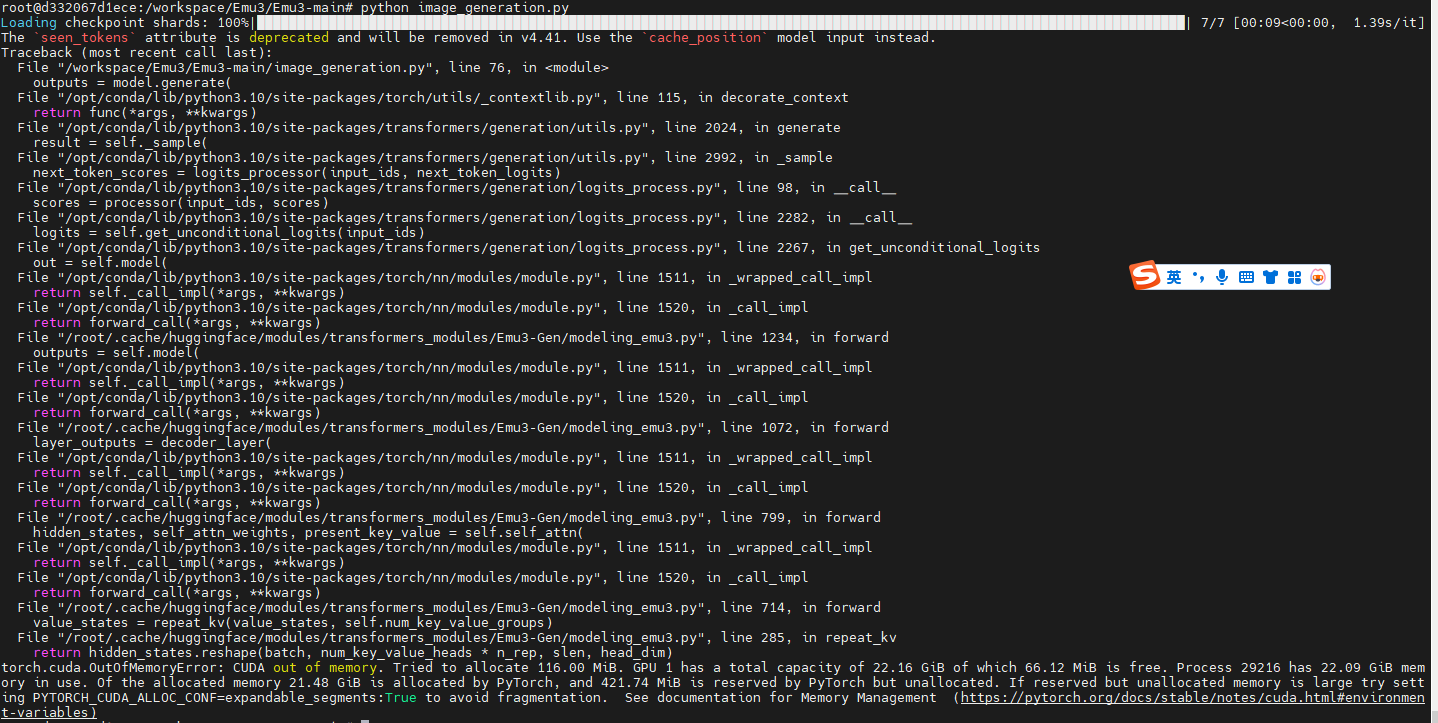
OK,显存不够 ,那就这样子吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号