LongWriter环境安装&推理测试
一口气生成2万字,大模型输出也卷起来了!清华&智谱AI最新研究,成功让GLM-4、Llama-3.1输出长度都暴增。相同问题下,输出结果直接从1800字增加到7800字,翻4倍。大模型的生成内容一般都不会太长,这对于内容创作、问题回答等都存在影响,可能导致模型回答问题不全面、创造性能降低等。LongWrite由智谱AI创始人、清华大学教授李涓子和唐杰共同领衔。OK,让我们开始吧。
一、模型介绍
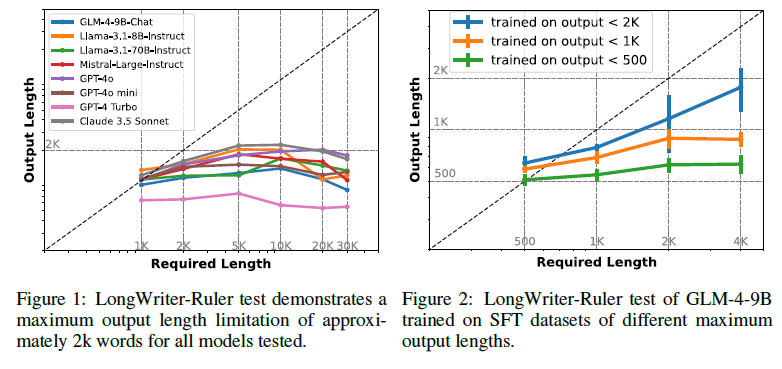
本项研究主要包括3方面工作。(1)分析文本生成长度限制因素(2)提出AgentWrite(3)扩展LLM输出窗口大小。首先,研究人员构建了一个测试工具LongWrite-Ruler。通过测试多个大模型,他们发现所有模型在生成超过2000字的文本时都遇到了困难。进一步分析用户和大模型的交互日志,研究人员发现只有超过1%的用户请求明确提到要生成超过2000字的文本。为此,他们改变了模型在监督式微调(SFT)阶段使用的数据集的最大输出长度。结果发现,模型的最大输出长度与SFT数据集中的最大输出长度呈显著正相关。所以得出结论,现有模型在输出长度上受限主要是因为SFT数据集中缺少长输出样本。即使模型在预训练阶段见过更长的序列,但是SFT阶段缺乏长文本样本,还是会影响输出长度。
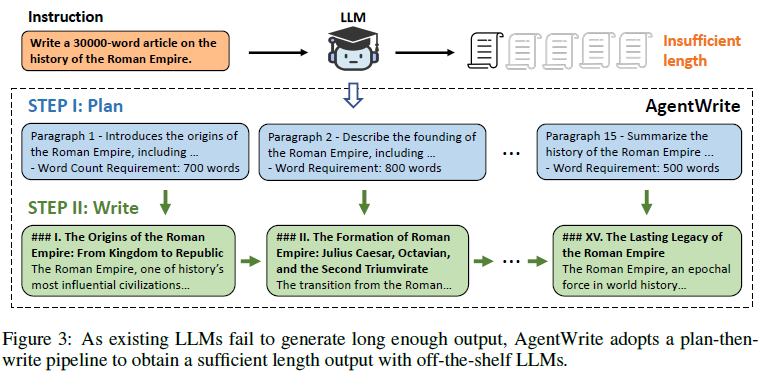
为了克服这个限制,研究人员提出了AgentWrite。这是一个基于Agent的pipline。
![]()
二、环境安装
代码下载
git clone
下载模型
环境安装
docker run -it -v /datas/work/zzq/:/workspace --gpus=all pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel bash
cd /workspace/LongWriter/LongWriter-main
pip install -r requirements.txt -i
pip install accelerate -i
pip install tiktoken -i
三、推理测试
测试代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("models", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("models", torch_dtype=torch.float16, trust_remote_code=True, device_map="auto")
model = model.eval()
query = "写一篇10000字的中国旅游指南"
print("start")
response, history = model.chat(tokenizer, query, history=[], max_new_tokens=32768, temperature=0.5)
print(response)结果如下:
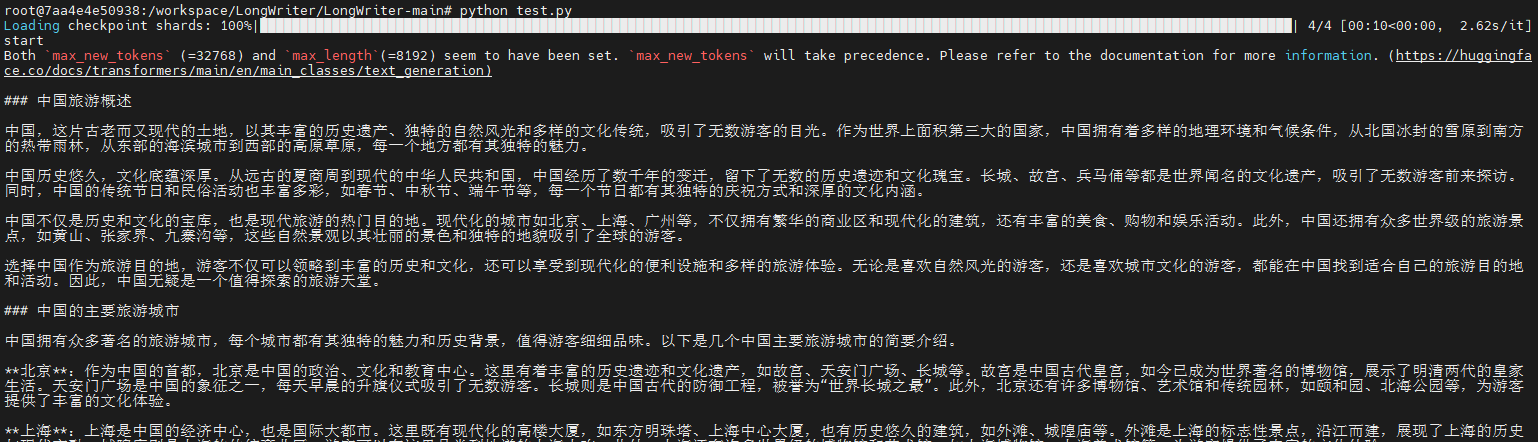
粘贴到Word中计算字数:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号