敏感词检测-DFA算法笔记及实现
引子
敏感词检测,这个是很多文字类服务都要遇到的问题,最近项目上接触到,特此调研梳理下这部分的内容。比如当我们输入一些包含暴力或者色情的文本,系统会阻止信息提交。敏感词过滤就是检查用户输入的内容有没有敏感词。OK,让我们开始吧。
一、算法原理简介
一般敏感词检测之后有两个处理策略。(1)直接阻止信息保存,接口返回错误信息(2)允许信息保存,但是会把敏感词替换为***。不管是哪种策略,首先都得找到是否包含敏感词,这个判断一般是在服务端完成的。要判断用户输入有无敏感词,就需要有个敏感词库。例如,现在敏感词库中有两个敏感词:“abcd”和“cdef”。最容易想到的方法是遍历敏感词库,依次判断输入内容是否有“abcd”和“cdef”。这种方法是可靠的,但是真实的敏感词库里存放的敏感词是非常多的,如果遍历敏感词库的性能较低,而且大部分情况下用户输入的内容都是不包含敏感词的,大部分情况下遇到的都是算法计算量大的情况,那么就需要找到一种高效的敏感词检测方法。经过调研,发现DFA算法可以做到。
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。敏感词过滤很适合用DFA算法,用户每次输入都是状态的切换,如果出现敏感词,即是终态,就可以结束判断。我们把数组形式的敏感词整理为一个树状结构,准确的说是一个森林。
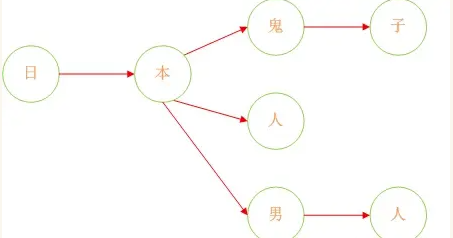
这样,就把查找敏感词就变成了一个查找路径的问题,如果用户输入的内容中包含一个从根节点到叶子节点的完整路径,就说明包含敏感词。算法实现逻辑是循环用户输入的字符串,依次查找每个字符是否出现在树的节点上,比如用户输入“打倒日本人”,从第一个字开始判断,“打”不在树的根节点上,进入下一步,“倒”也不在根节点上,进入下一步,“日”出现在了根节点上,这时状态切换,下一步的查找范围变为“日”的子节点;“本”出现在子节点中,状态再次切换为“本”的子节点,“人”出现在子节点中,并且为叶子节点,所以包含敏感词。
二、部分代码
class SensitiveWords():
def __init__(self, model_file,resp_json):
with open(model_file,'rb') as f:
self.keywords = [x.decode('utf8').strip() for x in f.readlines()]
# print("self.keywords=", self.keywords)
self.dfa = DFA(self.keywords)
def __call__(self, message):
text = message["datas"][0]
# print("message=", message)
res = []
for start_index, end_index in self.dfa.search(text):
res.append([start_index, end_index])
return res

 浙公网安备 33010602011771号
浙公网安备 33010602011771号