中英文互译赫尔辛基大学翻译模型安装与测试
引子
近期接到一个文本中英互译的任务,一直以为这种翻译应该很成熟,各种商用版本很多。那么开源的一定也不少,经过网络搜索发现,近两年还真的出现了很多优秀的开源翻译项目。找到了赫尔辛基大学开源免费的多语言翻译模型,开发了1400多个多语种翻译模型。其中就包含了中译英和英译中。OK,那就让我们开始吧。
一、环境安装
1、模型下载
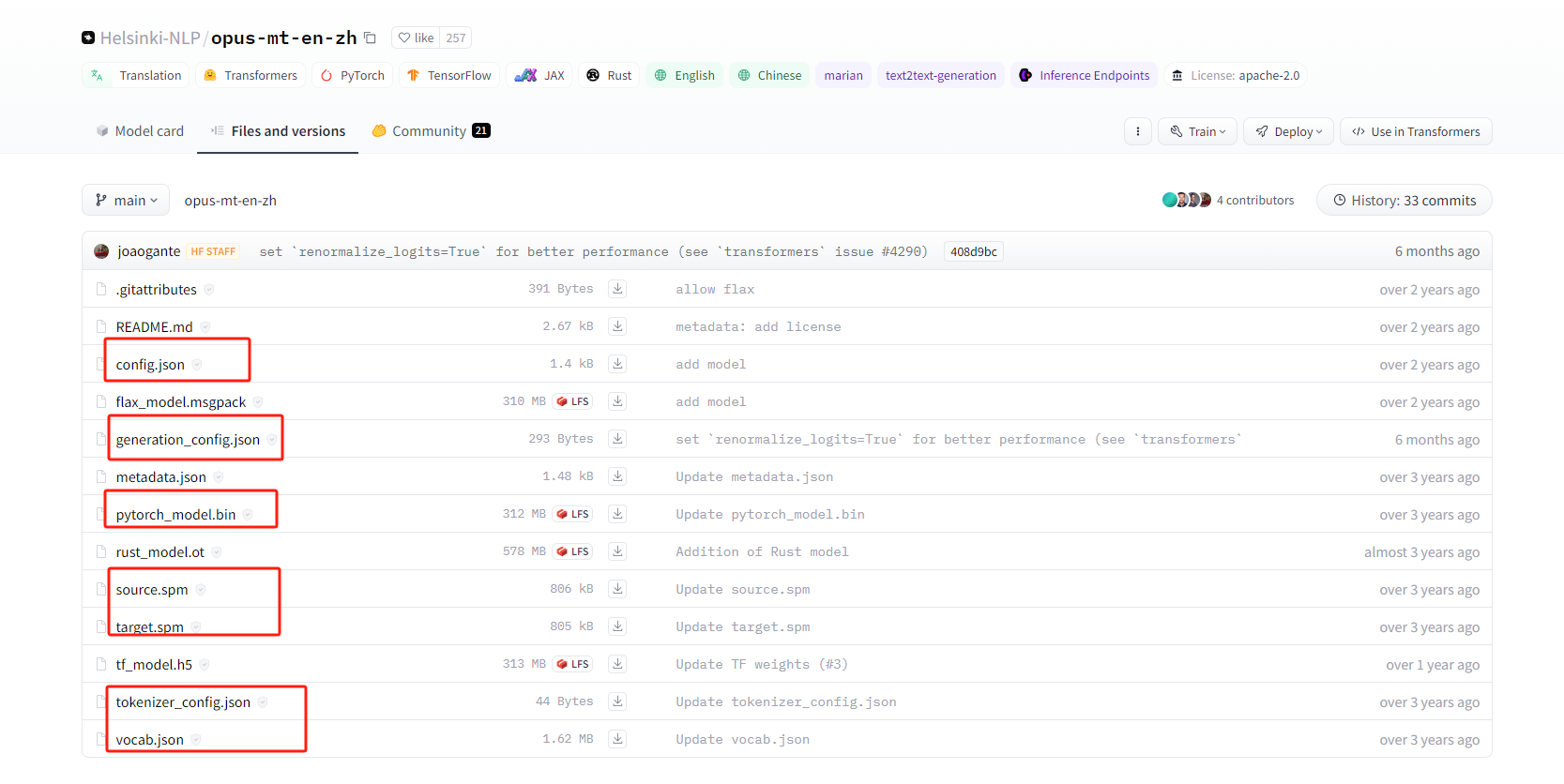
中译英 https://huggingface.co/Helsinki-NLP/opus-mt-zh-en/tree/main下载红框中的7个文件即可,下载完成后,文件放入指定两个不同文件夹中
2、anaconda环境
conda create -n translation python==3.10
conda activate translation
pip install transformers[sentencepiece] -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sacremoses
二、测试
1、中译英 python zh_en_test.py
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM from transformers import pipeline model_path = './zh-en/' #创建tokenizer tokenizer = AutoTokenizer.from_pretrained(model_path) #创建模型 model = AutoModelForSeq2SeqLM.from_pretrained(model_path) #创建pipeline pipeline = pipeline("translation", model=model, tokenizer=tokenizer) chinese=""" 中国男子篮球职业联赛(Chinese Basketball Association),简称中职篮(CBA),是由中国篮球协会所主办的跨年度主客场制篮球联赛,中国最高等级的篮球联赛,其中诞生了如姚明、王治郅、易建联、朱芳雨等球星。""" result = pipeline(chinese) print(result[0]['translation_text'])

2、英译中 python en_zh_test.py
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM from transformers import pipeline model_path = './en-zh/' #创建tokenizer tokenizer = AutoTokenizer.from_pretrained(model_path) #创建模型 model = AutoModelForSeq2SeqLM.from_pretrained(model_path) #创建pipeline pipeline = pipeline("translation", model=model, tokenizer=tokenizer) english=""" The official site of the National Basketball Association. Follow the action on NBA scores, schedules, stats, news, Team and Player news. """ result = pipeline(english) print(result[0]['translation_text'])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号