

redis代码解析-dictionary类型
2017-09-19 11:00 NicGanon 阅读(538) 评论(0) 编辑 收藏 举报dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。
redis中的dict传统的哈希算法类似,它采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing).在一个dict中有两个hash表,目的是来实现逐步的rehash,同时rehash时仍然可以访问dict.
正常使用的是ht[0],在rehash的时候先设置ht[1]大小为rehash后的需要的大小,然后逐步的将ht[0]中的内容rehash到ht[1]中,rehashidx记录着当前rehash到的index,在全部rehash完成之后,将ht[1]给ht[0],再reset ht[1].
当前dict是否处于rehash过程中可以通过rehashidx的值来判断,rehash时记录的是已经进行到的index,非rehash时为-1.
逐步的rehash是将rehash操作分散到对于dict的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict这样设计避免重哈希期间单个请求的响应时间的剧烈增加
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
一个hash table即dictht中的table是一个dictEntry数组,dict每次rehash时,table扩容或者缩小的时候都是2的n次方大小.
同时dictht还记录了当前table的大小,以及存在的dictEntry的数量.判断是否需要rehash就是通过used/size==1为需要rehash,used/size==5需要强制rehash
dictht中sizemask的值为size-1,因为size总是2的n次方,所以sizemask是n位的1,用来一个key的hash&sizemask定位出这个key应该在table中的位置.
同时,解决hash冲突的方法是链式
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
一个dict的图示如下:
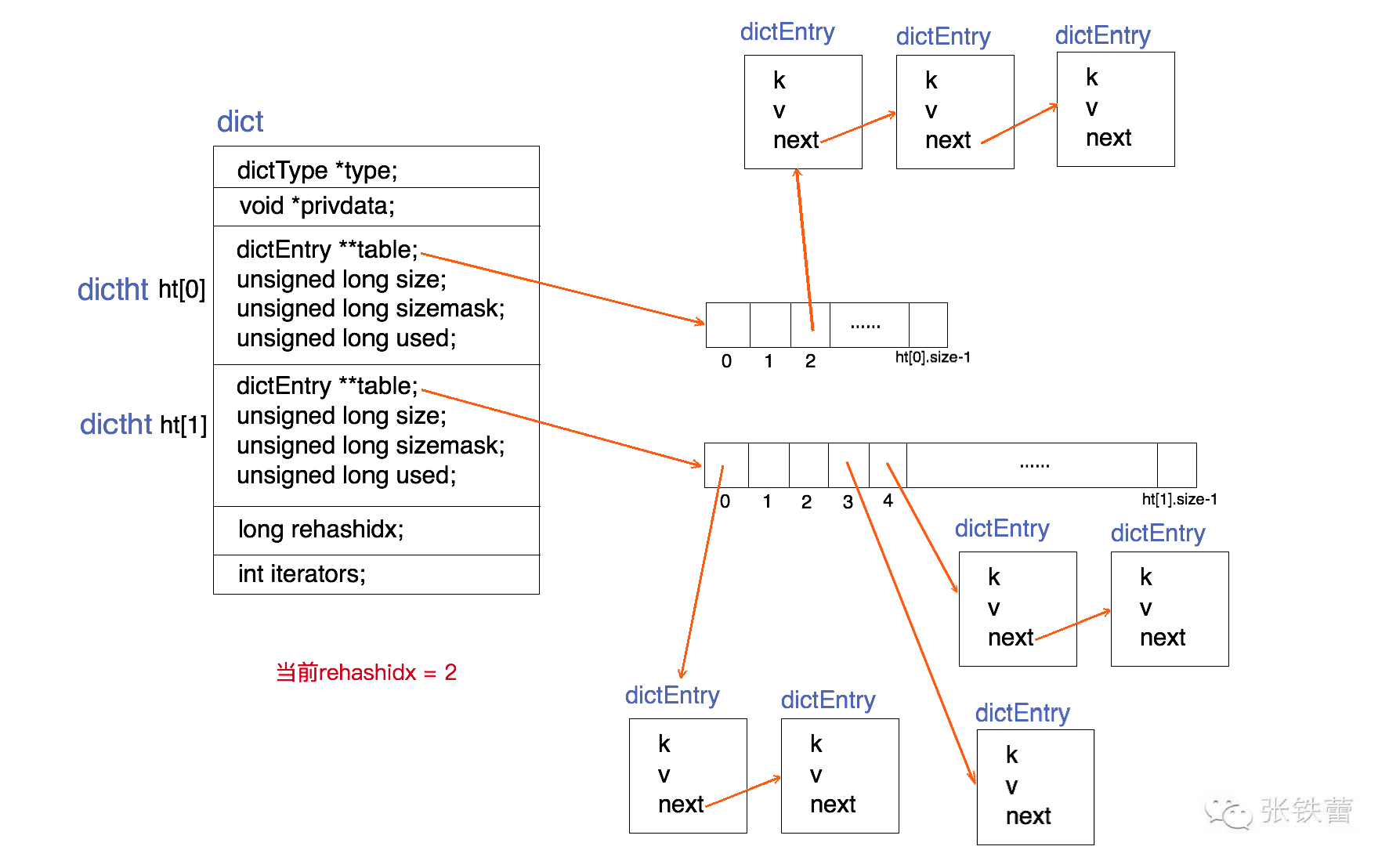
图片引用自:http://zhangtielei.com/posts/blog-redis-dict.html
dict的其他操作都非常简单,都是正常的对hash table的操作
dict scan还有点意思,因为redis中dict数据结构的关系,所以没办法使用传统的顺序遍历,因为
1 如果发生了扩容,原来的表大小是8,扩容之后是16,就会把原来的1-8rehash到新的1-16个slot中.如果现在要顺序访问8,则从8-16之前的其实全部在旧的表中1-7中访问过,会有大量的重复访问.
2 如果发生了缩表,原来的16缩小到8,就正好相反会有遗漏.
3 如果正在rehash,t0表中的数据是不全的也依然肯定有问题.
所以,redis中dict scan设计了一种新的遍历方法:对二进制高位进行加1遍历.
如果表的大小是8的话,和大小为2的访问顺序会是如下:
000 -> 0 00-> 0 100 -> 4 10-> 2 010 -> 2 01-> 1 110 -> 6 11-> 3 001 -> 1 101 -> 5 011 -> 3 111 -> 7
1 表扩容,先访问n,然后是访问n+2的n次方,不会重复,不会遗漏.
2 表缩小,通过n&m0(size mask)定位,可能会有重复的情况,不会遗漏.
3 如果正在rehash过程中,访问n的时候,会先在容量小的表中访问(n&m0),然后在大的表中遍历出全部的n&m0对应的位置.
dict scan 详细可参考这篇blog,http://chenzhenianqing.cn/articles/1101.html
