重温Elasticsearch
什么是 Elasticsearch ?
Elasticsearch (ES) 是一个基于 Lucene 构建的开源、分布式、RESTful 接口全文搜索引擎。还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。它可以在很短的时间内在储、搜索和分析大量的数据。它通常作为具有复杂搜索场景情况下的核心发动机。
官网:https://www.elastic.co/downloads/elasticsearch
中文社区:https://es.xiaoleilu.com/
什么是PB级别:https://baike.baidu.com/item/PetaByte/5910820
为什么要用 Elasticsearch ?
1、提高搜索效率
如果使用数据库进行模糊查询,比如 like 语句,他会遍历整张表,同时进行字符串匹配,如果数据库数据量非常庞大的话,会非常消耗资源和时间。
在换用 Elasticsearch 后,TB级别数据也能在毫秒级就能返回检索结果。
原因:Elasticsearch是基于倒排索引的
2、自动分词
在使用数据库的前提下,组合词检索是非常困难的,比如,当用户在搜索框输入"四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
原因:数据库并不支持分词。如果人工去开发分词功能,费时费精力。
如果换用 Elasticsearch,使用云搜索服务后,就不用太过于关注分词了,因为 Elasticsearch 支持中文分词插件,很好地解决了问题。当用户使用Elasticsearch时进行搜索时,Elasticsearch 就自动帮他分好词了。
例如当输入“四川火锅”时,Elasticsearch会自动做下面两件事 :
- 将“四川火锅”分词成“四川”和“火锅”
- 查找包含这两个词的文档
3. 相关性
在用数据库做搜索时,结果经常会出现一系列文档。但是数据库并不支持相关性搜索。
例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。
- 到底什么文档是用户真正想要的呢?
- 怎么才能把用户想看的文档放在搜索列表最前面呢?
当使用了云搜索服务后,发现 Elasticsearch 能很好地支持相关性评分。通过合理的优化,云搜索服务能够返回精准的结果,满足用户的需求。
原因: Elasticsearch 支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。
所以,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
4、海量存储
Elasticsearch 是为高可用和可扩展而生的。可以通过购置性能更强的服务器来完成。
横向可扩展性:只需要增加台服务器,做一点儿配置,启动一下 Elasticsearch 就可以并入集群。
分片机制提供更好的分布性:同一个索引分成多个分片(sharding), 这点类似于HDFS的块机制;分而治之的方式可提升处理效率。
高可用:提供复制( replica) 机制,一个分片可以设置多个复制,使得某台服务器在宕机的情况下,集群仍旧可以照常运行,并会把服务器宕机丢失的数据信息复制恢复到其他可用节点上。
5、可视化界面
在使用数据库进行查询数据时,很多时候都是通过工程代码或者命令端完成。其实在分析结果时并不太方便,缺少一个可视化界面来提高效率。
原因: 数据库自身通常不带可视化界面。而在完成搜索相关的任务时,常常需要根据搜索结果来进行分析。
而 Kibana 可视化工具则完美支持 Elasticsearch。研发人员能够在上面快速地进行概念验证,分析结果,提高开发效率。
Elasticsearch基本概念
Elasticsearch是面向文档型数据库的,一条数据即一个文档,用 JSON 作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
关于Elasticsearch以及Kibana的安装请参考之前的一篇文章:<了解一下Elasticsearch的基本概念>
Elasticsearch是如何做到快速索引的?
首先 Elasticsearch 使用的是倒排索引,何为倒排索引?
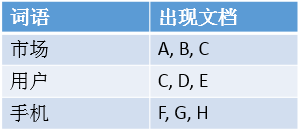
如上图,当用户搜索“手机”时,Elasticsearch 就会立即返回文档 F,G,H。这样就不用花多余的时间在其他文档上了,因此检索速度得到了数量级的提升。
也许你还不太了解倒排索引,甚至是正向索引也不了解?
什么是正向索引
正向索引是文档与关键词一一对应的数据结构。
其以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正向索引的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
为了进一步理解,在这举个例子:
我们假设有网页1和网页2:

网页1中仅包含一句话:厦门SEO顾问潇湘驭文为您提供厦门SEO培训服务。
网页2中也仅包含一句话:SEO是一门艺术。
经过搜索引擎初步分词之后,网页1和2的正向索引如下图所示:

假设使用正向索引,那么当你搜索SEO的时候,搜索引擎必须检索网页中的每一个关键词,假设一个网页中包含成千上百个关键词,可想而知,会造成大量的资源浪费。于是倒排索引应运而生。
什么是倒排索引
倒排索引是关键词与文档一一对应的数据结构。
其以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。
在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
概括:正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。
我们再来看一下上边的例子用倒排索引是什么样的。

从上图可以一目了然,倒排索引可以直接参与排名。
比如你搜索“SEO”,搜索引擎可以快速检索出包含“SEO”搜索词的网页1和网页2,为后续的相关度和权重计算奠定基础,从而大大加快了返回搜索结果的速度。
再看一个例子:

倒排索引会对以上文档内容进行关键词分词,可以使用关键词直接定位到文档内容。

当你搜索[科技公司]后,会立即返回序号id为[1,2,4,5]的文档,而不是去进行全文关键字匹配。
DSL语言查询与过滤
什么是DSL语言?
ES 中的查询请求有两种方式,一种是简易版的查询,另外一种是使用JSON完整的请求体,叫做结构化查询(DSL)。
由于DSL查询更为直观也更为简易,所以大都使用这种方式。
DSL查询是POST过去一个JSON,由于POST的请求是JSON格式的,所以存在很多灵活性,也有很多形式。
举个例子,详细的可自行查询了解:
根据名称精准查询姓名:
GET ttyy/user/_search
{
"query": {
"term": {
"name": "奶茶"
}
}
}
其中 term 是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇;类似的还有 Match;
分词器
什么是分词器
因为 Elasticsearch 中默认的标准分词器分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉字,因此引入中文分词器 ik 插件。
演示传统分词器
{
"analyzer": "standard",
"text": "奥迪a4l"
}
{
"tokens": [
{
"token": "奥",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "迪",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "a4l",
"start_offset": 2,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 2
}
]
}
采用 ik 分词器后:
{
"analyzer": "ik_smart",
"text": "奥迪"
}
{
"tokens": [
{
"token": "奥迪",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "a4l",
"start_offset": 2,
"end_offset": 5,
"type": "LETTER",
"position": 1
}
]
}
ES集群环境搭建
ES为什么要实现集群
在搭建集群之前先了解一下es为什么要实现集群。
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。
由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
简而言之就是提高查询的负载能力。
ES集群核心原理分析:
数据存储。
1、每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
注意:索引的主分片primary shards定义好后,后面不能做修改。
2、为了实现高可用数据的高可用,主分片可以有对应的备分片replics shards,replic shards分片承载了负责容错、以及请求的负载均衡。
**注意: **每一个主分片为了实现高可用,都会有自己对应的备分片,主分片对应的备分片不能存放同一台服务器上。,主分片primary shards可以和其他replics shards存放在同一个node节点上。
补充1:单台ES服务器中是没有备份分片的
补充2:主分片对应的备份分片不能存放在同一台服务器上。
如下图所示:
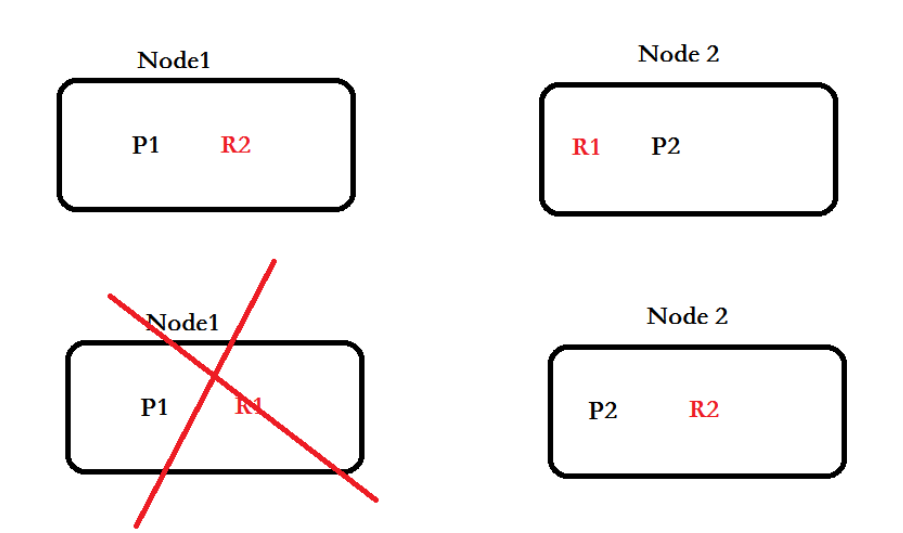
Node表示服务器,P表示主分片,R表示备份分片
服务器环境
准备三台服务器
| 服务器名称 | IP地址 |
|---|---|
| node-1 | 192.168.212.182 |
| node-2 | 192.168.212.183 |
| node-3 | 192.168.212.184 |
服务集群配置
vi elasticsearch.yml
cluster.name: myes ###保证三台服务器节点集群名称相同
node.name: node-1 #### 每个节点名称不一样 其他两台为 node-1 ,node-2
network.host: 192.168.212.180 #### 实际服务器ip地址
discovery.zen.ping.unicast.hosts: ["192.168.212.184", "192.168.212.185","192.168.212.186"]##多个服务集群ip
discovery.zen.minimum_master_nodes: 1
关闭防火墙 systemctl stop firewalld.service
默认底层开启9300 集群
验证集群效果:
http://192.168.212.185:9200/_cat/nodes?pretty
参考文章:
https://blog.csdn.net/weixin_39819880/article/details/82083034
https://www.cnblogs.com/dreamroute/p/8484457.html
我创建了一个java相关的公众号,用来记录自己的学习之路,感兴趣的小伙伴可以关注一下微信公众号哈:niceyoo


 浙公网安备 33010602011771号
浙公网安备 33010602011771号