探索常用寄存器名字的由来
 常用寄存器表;寄存器名字的来历;寄存器的演化过程
常用寄存器表;寄存器名字的来历;寄存器的演化过程
国内外教学对常用寄存器的名字往往一笔带过,似乎它们没什么意义,我们只需要懂得如何用 “抽屉” 放东西就行了。
但是我相信,对于真正怀有好奇心的初学者来说,探寻为什么这件事本身,就是极具意义的。
我收集汉化了两篇文章,足以解决大家对寄存器命名的疑惑。
文章较长,但比起花同样时间去死记硬背寄存器的名字,不如通过探索名字背后的有趣历史来理解记忆它们。
常用寄存器对应表
通用寄存器
| 缩写 | 名字 | 翻译 |
|---|---|---|
| EAX | Accumulator Register | 累加器寄存器 |
| EBX | Base Register | 基址寄存器 |
| ECX | Counter Register | 计数器寄存器 |
| EDX | Data Register | 数据寄存器 |
| ESI | Source Index | 来源索引 |
| EDI | Destination Index | 目的地索引 |
| EBP | Base Pointer | 基指针 |
| ESP | Stack Pointer | 堆栈指针 |
段寄存器
| 缩写 | 名字 | 翻译 | 作用 |
|---|---|---|---|
| CS | Code Segment | 代码段寄存器 | 存放当前正在运行的程序代码所在段的段基址,表示当前使用的指令代码可以从该段寄存器指定的存储器段中取得,相应的偏移量则由IP提供 |
| DS | Data Segment | 数据段寄存器 | 指出当前程序使用的数据所存放段的最低地址,即存放数据段的段基址 |
| SS | Stack Segment | 堆栈段寄存器 | 指出当前堆栈的底部地址,即存放堆栈段的段基址 |
| ES | Extra Segment | 附加段寄存器 | 指出当前程序使用附加数据段的段基址,该段是串操作指令中目的串所在的段 |
寄存器名字的来历
[原作者:William Swanson]
[翻译:nicere]
挑选英特尔寄存器的艺术
我为一家名为Scene Zine的在线杂志写了这篇文章。Scene Zine迎合了Demo Scene,这是一个数字艺术社区,致力于通过音乐、艺术和计算机编程的混合来挑战计算机的极限。演示场景制作的一个特殊类别,即4K介绍,侧重于最终产品的原始文件大小。其目标是将尽可能多的高质量音乐、图形和动画放入仅有的4096字节中。要做到这一点需要高度专业化的尺寸优化技术,因为4096字节的空间比两页打字的文本或一个真彩色的Windows XP图标还要小。这篇文章讨论了其中的一些技术。
有些人评论说,他们希望在Scene Zine中看到更多的专家编程文章。为了纠正这种情况,这篇文章是为所有汇编语言程序员准备的。它讨论了在你的代码中选择使用哪些寄存器的精细艺术。这些信息应该可以简化你的编码,帮助你写出更小的程序。
当英特尔的工程师设计最初的8086处理器时,他们对每个寄存器都有一个特殊的目的。当他们设计指令集时,他们根据预期每个寄存器的功能创建了许多优化和特殊指令。根据英特尔最初的计划使用寄存器可以使代码充分利用这些优化。不幸的是,这似乎是一门失传的艺术。很少有编码员意识到英特尔的整体设计,而且大多数编译器都过于简单,或者专注于执行速度,无法正确使用寄存器。然而,了解寄存器和指令集是如何结合在一起的,是通向毫不费力地进行大小编码的重要一步。
除了优化大小之外,持续使用寄存器还有其他好处。就像使用好的变量名一样,使用一致的寄存器可以使代码更有可读性。当它们被正确使用时,寄存器的含义几乎和高级语言中的循环计数器i一样清晰。事实上,我偶尔会用x86寄存器来命名我的C语言变量,因为寄存器的名字非常有描述性。有了正确的寄存器使用,x86汇编几乎可以像高级语言一样自我记录。
一致的寄存器使用带来的另一个好处是更好的压缩。在使用压缩器来打包最终构建的产品中,例如4K介绍,创造更多的冗余代码会导致更小的打包尺寸。当代码一致地使用寄存器时,相同的指令序列就会重复出现。这反过来又会提高压缩率。
作为回顾,所有x86-家族的CPU都有8个通用的寄存器。寄存器的宽度为32位,尽管16位的版本也可以通过一个特殊的一字节指令前缀来访问。在16位模式下,情况是相反的。默认情况下,低16位可以访问,而完整的寄存器只能通过前缀字节访问。
每个寄存器的名称实际上是一个缩写。即使是 "字母 "寄存器EAX、EBX、ECX和EDX也是如此。下面的列表显示了寄存器的名称和它们的含义。
EAX - 累加器寄存器
EBX - 基址寄存器
ECX - 计数器寄存器
EDX - 数据寄存器
ESI - 来源索引
EDI - 目的地索引
EBP - 基指针
ESP - 堆栈指针
除了全尺寸的通用寄存器外,x86处理器还有8个字节大小的寄存器。由于这些寄存器直接映射到EAX、EBX、ECX和EDX,大多数人把它们看作是大寄存器的一部分。然而,从指令集的角度来看,这些8位寄存器是独立的实体。例如,CL和CH寄存器没有分享ECX寄存器的任何有用属性。除了AL和AH,其他的8位寄存器在指令集中没有任何特殊的意义,所以本文没有提到它们。
EAX: The Accumulator
有三种主要的处理器架构:寄存器、堆栈和累加器(register, stack, and accumulator)。在寄存器结构中,加法或减法等操作可以发生在任何两个任意的寄存器之间。在堆栈结构中,操作发生在堆栈的顶部和堆栈上的其他项目之间。在累加器结构中,处理器有一个称为累加器的计算寄存器。所有的计算都发生在累加器中,而其他寄存器作为简单的数据存储位置。
很明显,X86处理器没有累加器结构。然而,它确实有一个类似累加器的寄存器。EAX / AL。尽管大多数计算可以发生在任何两个寄存器之间,但指令集给予累加器作为计算寄存器的特殊优先权。例如,所有九个基本操作(ADD, ADC, AND, CMP, OR, SBB, SUB, TEST, 和 XOR)都有特殊的一字节操作码,用于在累加器和常数之间进行操作。特殊的操作,如乘法、除法、符号扩展和BCD校正,只能在累加器中进行。
由于大多数计算发生在累加器中,x86架构包含许多优化指令,用于将数据移入和移出该寄存器。首先,处理器有16个字节大小的XCHG操作码,用于在累加器和任何其他寄存器之间交换数据。这些指令并不十分有用,但它们显示了英特尔工程师对累加器比对其他寄存器有多么强烈的偏好。对他们来说,把数据换到累加器中,比在原地工作要好。其他将数据移入和移出累加器的指令有LODS, STOS, IN, OUT, INS, OUTS, SCAS, 和XLAT. 最后,MOV指令有一个特殊的单字节操作码,用于将数据从一个恒定的内存位置移入累加器。
在你的代码中,尽量在累加器中执行更多的工作。正如你所看到的,其余七个通用寄存器的存在主要是为了支持在累加器中进行的计算。
EDX: The Data Register
在剩下的七个通用寄存器中,数据寄存器EDX与累加器的关系最为密切。处理过大数据项的指令,如乘法、除法、CWD和CDQ,将最有意义的位存储在数据寄存器中,将最没有意义的位存储在累加器中。在某种意义上,数据寄存器是累加器的64位扩展。数据寄存器在IO指令中也起作用。在这种情况下,累加器持有要从端口读取或写入的数据,而数据寄存器持有端口地址。
在你的代码中,数据寄存器对存储与累加器的计算有关的数据最有用。根据我的经验,如果书写得当,大多数计算只需要这两个寄存器来存储。
ECX: The Count Register
计数寄存器ECX是x86中无处不在的循环变量i的等价物,x86中每个与计数有关的指令都使用ECX。最明显的计数指令是LOOP、LOOPZ和LOOPNZ。另一条基于计数器的指令是JCXZ,顾名思义,当计数器为0时就会跳转。 计数寄存器也出现在一些移位操作中,它持有要执行的移位次数。最后,计数寄存器通过REP、REPE和REPNE的前缀来控制字符串指令。在这种情况下,计数寄存器决定了操作的最大重复次数。
特别是在演示中,大多数计算都是在一个循环中发生的。在这种情况下,ECX是循环计数器的合理选择,因为没有其他寄存器围绕它有这么多的分支操作。唯一的问题是,这个寄存器是向下计数的,而不是像高级语言中那样向上计数。然而,设计一个向下计数并不难,所以这只是一个小困难。
EDI: The Destination Index
每个产生数据的循环都必须在内存中存储结果,这样做需要一个移动指针。目的索引,EDI,就是这个指针。目标索引持有所有字符串操作的隐含写入地址。值得注意的是,最有用的字符串指令是很少使用的STOS。STOS将数据从累加器复制到内存,并增加目标索引。这条单字节指令非常完美,因为任何计算的最终结果都应该在累加器中,而将结果存储在一个移动的内存地址中是一项常见的任务。
许多编码员把目标索引看作不过是额外的存储空间。这是个错误。所有的例程都必须存储数据,而一些寄存器必须作为存储指针。由于目标索引是为这项工作设计的,用它来做额外的存储空间是一种浪费。使用堆栈或其他的寄存器进行存储,并使用EDI作为你的全局写指针。
ESI: The Source Index
源索引,ESI,具有与目的索引相同的属性。唯一的区别是,源索引是用于读而不是写。尽管所有的数据处理程序都是写的,但并不是所有的都是读的,所以源索引并不是那么普遍的有用。然而,当需要使用它的时候,源索引和目的索引一样强大,并且有相同类型的指令。
当然,在你的代码不读取任何种类的数据的情况下,使用源索引以方便存储空间是可以接受的。
ESP and EBP: The Stack Pointer and the Base Pointer
在八个通用寄存器中,只有堆栈指针ESP和基数指针EBP被广泛用于其最初的用途。这两个寄存器是x86函数调用机制的核心。当一个代码块调用一个函数时,它把参数和返回地址推到堆栈上。一旦进入,函数将基础指针设置为等于堆栈指针,然后将自己的内部变量放在堆栈上。从那时起,函数就相对于基指针而不是堆栈指针来引用其参数和变量。为什么不是堆栈指针?由于某些原因,堆栈指针的寻址模式很糟糕。在16位模式下,它根本不可能是一个方括号的内存偏移。在32位模式下,它只能通过在操作码中添加一个昂贵的SIB字节来出现在方括号中。
在你的代码中,从来没有理由将堆栈指针用于堆栈以外的任何地方。然而,基点指针是可以使用的。如果你的例程通过寄存器而不是通过堆栈传递参数(他们应该这样做),就没有理由把堆栈指针复制到基本指针中。基准指针成为一个自由的寄存器,可以用于你需要的任何东西。
EBX: The Base Register
在16位模式下,基础寄存器EBX作为一个通用的指针。除了专门的ESI、EDI和EBP寄存器外,它是唯一可以出现在方括号内存访问中的通用寄存器(例如,MOV [BX], AX)。然而,在32位的世界中,任何寄存器都可以作为内存偏移,所以基数寄存器不再特殊。
基准寄存器的名字来自XLAT指令。XLAT使用AL作为索引,EBX作为基数,在表中查找一个值。XLAT相当于MOV AL, [BX+AL],如果你需要用表中的一个8位值替换另一个8位值,有时是很有用的(想想颜色查询)。
所以,在所有的通用寄存器中,EBX是唯一一个没有重要专用用途的寄存器。它是一个存储额外指针或计算步骤的好地方,但没有更多的用途。
总结
x86处理器系列中的八个通用寄存器都有一个独特的用途。每个寄存器都有特殊的指令和操作码,使实现这一目的更加方便或有效。下面简要介绍一下这些寄存器及其用途。
EAX - 所有主要的计算都在EAX中进行,因此它类似于一个专门的累加器寄存器。
EDX - 数据寄存器是对累加器的扩展。它对于存储与累加器当前计算有关的数据最为有用。
ECX - 和高级语言中的变量i一样,计数寄存器是通用的循环计数器。
EDI - 每个循环都必须将其结果存储在某个地方,目的索引指向那个地方。通过单字节的STOS指令将数据从累加器中写出来,这个寄存器使数据操作的大小更加有效。
ESI - 在处理数据的循环中,源索引持有输入数据流的位置。和目的索引一样,EDI也有一个方便的单字节指令,用于将数据从内存加载到累加器中。
ESP - ESP是神圣的堆栈指针。由于重要的PUSH、POP、CALL和RET指令都需要它的值,所以从来没有一个好的理由将堆栈指针用于其他方面。
EBP--在将参数或变量存储在堆栈上的函数中,基础指针持有当前堆栈帧的位置。然而,在其他情况下,EBP是一个自由的数据存储寄存器。
EBX - 在16位模式下,基数寄存器作为一个指针很有用。现在它是完全自由的额外存储空间。
下面是一个典型例程的概要,作为这些寄存器如何相互配合的例子。
点击查看代码
mov esi, source_address
mov edi, destination_address
mov ecx, loop_count
my_loop: lodsd
;Do some calculations with eax here.
stosd
loop my_loop
总而言之,按照英特尔的意图使用寄存器有几个好处。在第一种情况下,它可以使你的代码利用许多优化和特殊指令。它还可以使代码更易读,因为寄存器执行的是可预测的功能。最后,通过促进更多的重复性指令序列,持续使用寄存器会导致更好的压缩。
寄存器名字的演化
[原作者:Vladimir Keleshev]
[翻译:nicere]
通常,x86教程不会花太多时间解释设计和命名决定的历史观点。在学习x86汇编时,通常会告诉你一些大致的内容。这里是EAX。它是一个寄存器。使用它。
那么,这些字母到底代表什么?E-A-X。
我恐怕没有简短的答案! 我们必须回到1972年...
8008
1972年,经过一连串奇怪的事件,英特尔推出了世界上第一个8位微处理器--8008。那时,英特尔主要是一个存储芯片的供应商。8008是由计算机终端公司(CTC)为其新的Datapoint 2200可编程终端委托生产的。但该芯片被推迟了,没有达到CTC的预期。因此,英特尔为它增加了一些通用指令,并将该芯片推销给其他客户。
8008有七个8位寄存器:
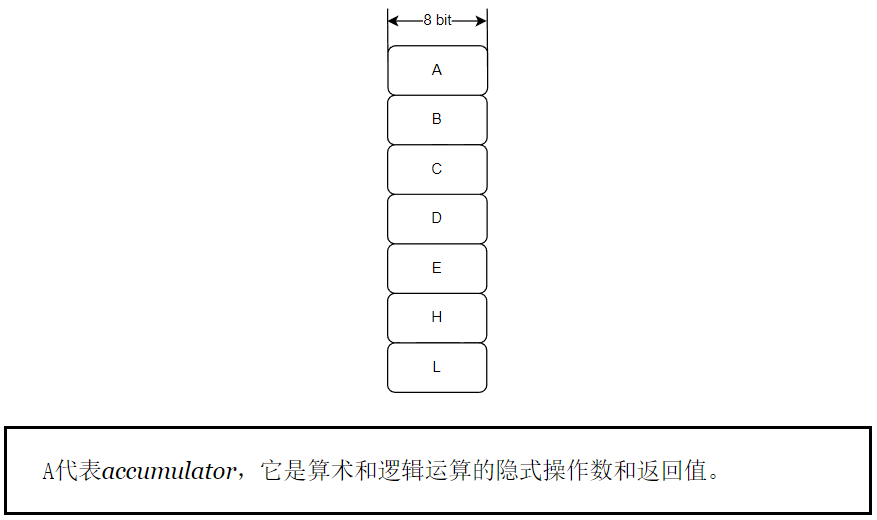
你可能会想--哎呀,7个寄存器是一个非常奇怪的数字--这就对了!你会发现,这是个很好的例子。寄存器被编码为指令的三个比特,所以它允许有八个组合。最后一个是一个叫做M的伪寄存器,它代表内存。M指的是由寄存器H和L组合指向的内存位置。H代表高阶字节,而L代表内存地址的低阶字节。这是8008中唯一可以用来引用内存的方法。
所以,A是一个累加器,H和L也被用来寻址内存。然而,B、C、D、E是完全通用的,可以互换的。
8086
1979年,英特尔已经是一家微处理器公司,他们的旗舰处理器iAPX 432被推迟了。因此,作为权宜之计,他们推出了8086,一个从8080衍生出来的16位微处理器,而8080本身又是从8008衍生出来的。
为了利用其现有的客户群,英特尔使8086的软件兼容到8008。一个简单的翻译程序可以将8008汇编翻译成8086汇编。为了使其顺利运行,8086的指令集结构必须很好地映射到8008,并继承了许多设计决定。
8086有8个16位寄存器和8个8位寄存器,它们的重叠情况如下:
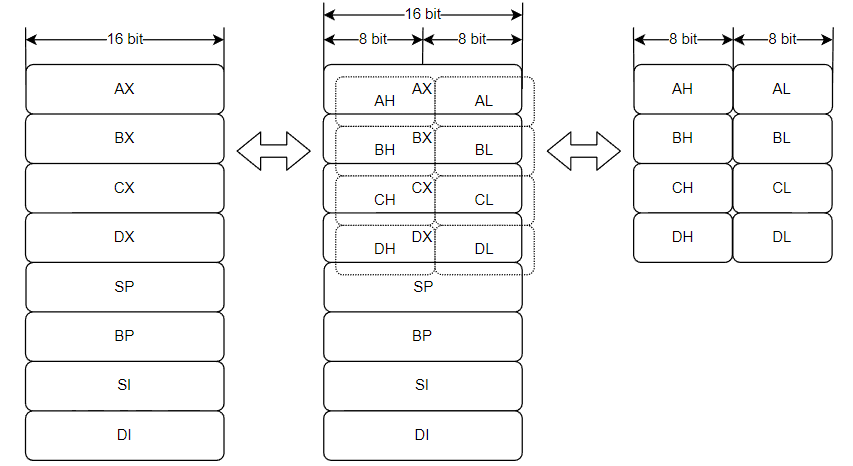
8086指令有一个位标志,指定一个寄存器的3位编码是指8个8位寄存器中的一个,还是指8个16位寄存器中的一个。
从上图可以看出,前四个16位寄存器中的数据也可以通过八个8位寄存器中的一个来访问。
| AX是一个 16 位累加器,而AH和AL 可以被认为是它们自己的 8 位寄存器或作为访问 . 的高位和低位 字节的一种方式AX。XinAX是一个占位符, 代表H和L。这在某种程度上类似于 x86 中的“x”指代 8086、80186、80286 等的时间。 |
|---|
由于8008有7个8位寄存器,它们可以很好地被映射到8086的8个寄存器中,并有一个空余。
由于8086允许多种内存寻址模式,M伪寄存器不再需要了。因此,它释放了一个额外寄存器的编码。
在下图中,你可以看到8008的寄存器是如何被映射到8086的寄存器中的:
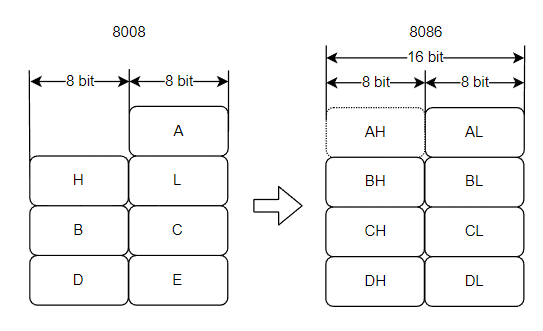
尽管许多算术和逻辑运算可以在这些寄存器中的任何一个上工作,但在这一点上没有一个寄存器是真正通用的。每个寄存器都有一些指令,这些指令对其中一个寄存器起作用,但对其他寄存器不起作用。记忆法是。BX是基础寄存器,CX是计数寄存器,DX是数据寄存器,AX仍然是累加器。
新的SP是堆栈指针,BP是基础指针,SI是源索引,DI是目的索引。但我们在这里不对它们进行详细介绍。
8086也引入了段式寄存器,但它们在很大程度上是一种独立的野兽。分段式结构值得单独讲一讲,因为它是保持向后兼容8080的结果。
x86
1985年,英特尔推出了80386,这是x86系列中的第一个32位处理器。早期的一批处理器在一个32位操作中存在缺陷。它们被标记为仅适用于16位的软件,但还是出售了。
许多新功能被引入,但80386继续(大部分)与8086的二进制兼容。
主要的寄存器通过添加一个E前缀扩展到32位:
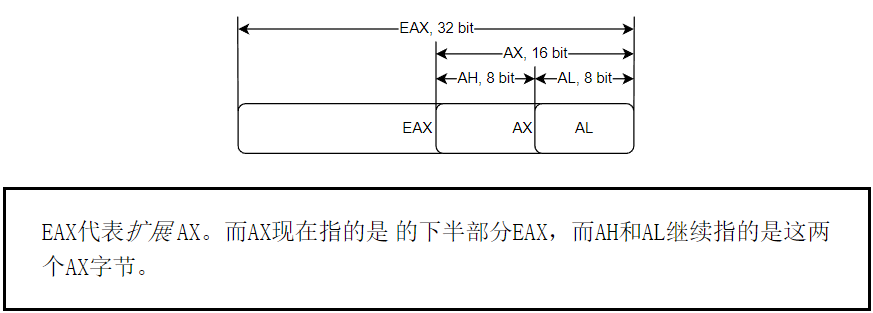
这就是EAX名字的由来。
但是,故事并没有到此为止!
x86-64
2003年,AMD有效地接管了架构领导权,并推出了x86系列中的第一个64位处理器。在传统模式下,它可以向后兼容到8086。
八个主寄存器被扩展到64位。
扩展的寄存器有一个R前缀,取代了E前缀。所以累加器现在被称为RAX:
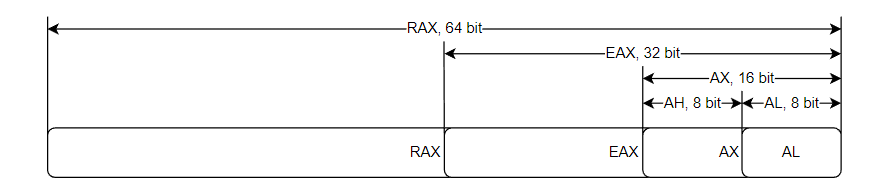
为什么是R?
嗯,AMD想简化寄存器的处理。他们引入了八个新的寄存器,称为R8到R15。他们甚至讨论过将现有的八个寄存器的扩展称为R0到R7。但他们认识到,许多指令的记忆法都是指其中一个寄存器的字母,如A或B,所以他们保留了原来的名字,用R代替E。
| 因此,RAX中的R代表寄存器,是一种统一命名的方式,以便与新的R8-R15寄存器更加一致。 |
|---|
新的寄存器也有它们的 "狭窄 "版本。以R15为例:
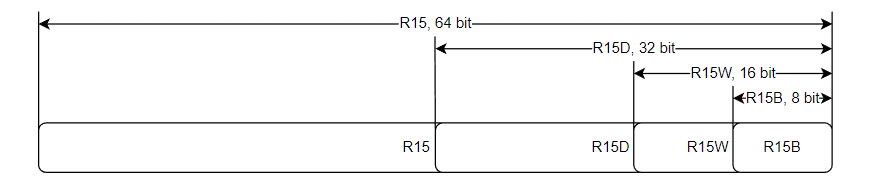
这就是X86累加器的快速发展史! 从8008的8位A,到8086的16位AX,到80386的32位EAX,到64位RAX。
扩充:寄存器中的X究竟代表什么?
在8086之前,寄存器都是单个字母,如A、B、C、D,每个都是一个8位寄存器。8086有16位寄存器,可以一次引用8位,也可以一次引用全部16位。
例如,我们可以引用A寄存器的8个高阶位,A寄存器的8个低阶位,或A寄存器的全部16位。前两者的命名被选为AL和AH,其中L/H表示低阶或高阶的一半。现在我们需要一个术语来指定完整的16位。
因此,字母X被选中。X只是一个任意的字母,结合了L和H--有点像代数中使用X来指定未知数。至于X代表什么(如果有的话),真的没有考虑太多--它只是一个需要用来识别通用寄存器(AX、BX、CX、DX)的字母,而不是指针和索引寄存器(SP、BP、SI、DI),以及分段寄存器(CS、DS、ES、SS)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号