
sparkSql使用hive数据源
1.pom文件
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/oracle/ojdbc6 -->
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.verson}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.verson}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.verson}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.verson}</version>
</dependency>
2.代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
object HiveDataSource extends App {
val config = new SparkConf().setAppName("HiveDataSource").setMaster("local")
val sc = new SparkContext(config)
val sqlContext = new HiveContext(sc)
sqlContext.sql("drop table if exists default.student_infos")
sqlContext.sql("create table if not exists default.student_infos (name string,age int) row format delimited fields terminated by ',' stored as textfile")
sqlContext.sql("load data inpath '/tmp/student_infos.txt' into table default.student_infos")
// 用同样的方式,给student_scores导入数据
sqlContext.sql("DROP TABLE IF EXISTS default.student_scores")
sqlContext.sql("create table if not exists default.student_scores (name string,score int) row format delimited fields terminated by ',' stored as textfile")
sqlContext.sql("load data inpath '/tmp/student_scores.txt' into table default.student_scores")
// 关联两张表执行查询,查询成绩大于80分的学生
val goodStudentDf = sqlContext.sql("select t1.name,t1.age,t2.score from default.student_infos t1 join default.student_scores t2 on t1.name = t2.name")
goodStudentDf.show()
}
3.拷贝hive/config下的hive-site.xml到src/main/resources中
4.编译打包
5.jar包放到服务器上
6.添加脚本:
/home/hadoop/app/spark/bin/spark-submit \
--class com.dsj361.HiveDataSource \
--master local[*] \
--num-executors 2 \
--driver-memory 1000m \
--executor-memory 1000m \
--executor-cores 2 \
/home/hadoop/sparksqlapp/jar/sparkSqlStudy.jar7.运行即可
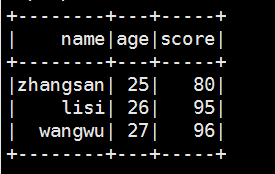
比hive快很多
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号