jieba库使用和好玩的词云

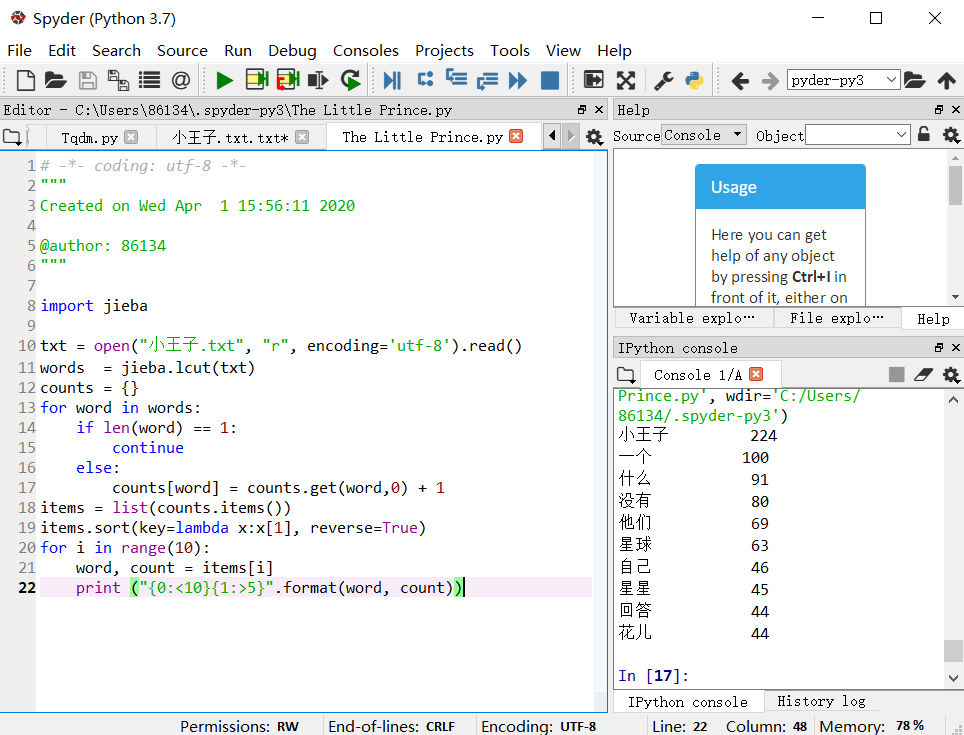
1、词频分析:
import jieba txt = open("小王子.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))
运行结果:
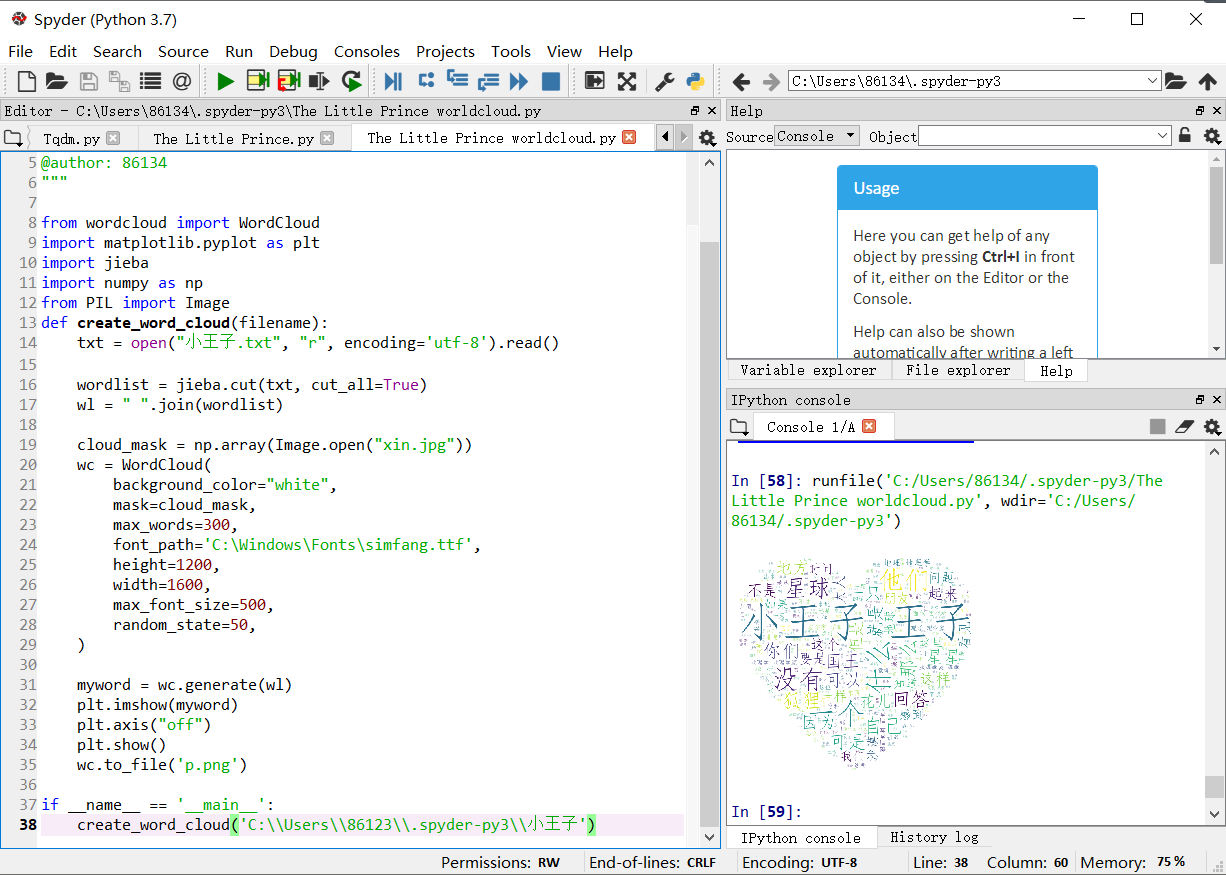
2、词云图:
from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba import numpy as np from PIL import Image def create_word_cloud(filename): txt = open("小王子.txt", "r", encoding='utf-8').read() wordlist = jieba.cut(txt, cut_all=True) wl = " ".join(wordlist) cloud_mask = np.array(Image.open("xin.jpg")) wc = WordCloud( background_color="white", mask=cloud_mask, max_words=300, font_path='C:\Windows\Fonts\simfang.ttf', height=1200, width=1600, max_font_size=500, random_state=50, ) myword = wc.generate(wl) plt.imshow(myword) plt.axis("off") plt.show() wc.to_file('p.png') if __name__ == '__main__': create_word_cloud('C:\\Users\\86123\\.spyder-py3\\小王子')
运行结果: