
一 mongodb介绍
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 Nosql 技术门类 redis 内存型 mongodb 文档型
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
二 MongoDB的特点
l 面向集合存储,易存储对象类型的数据
l 支持查询,以及动态查询
l 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言
l 文件存储格式为BSON(一种JSON的扩展)
l 支持复制和故障恢复和分片
三 MongoDB的安装和使用
下载地址 mongodb 官网 Download MongoDB Community Server | MongoDB
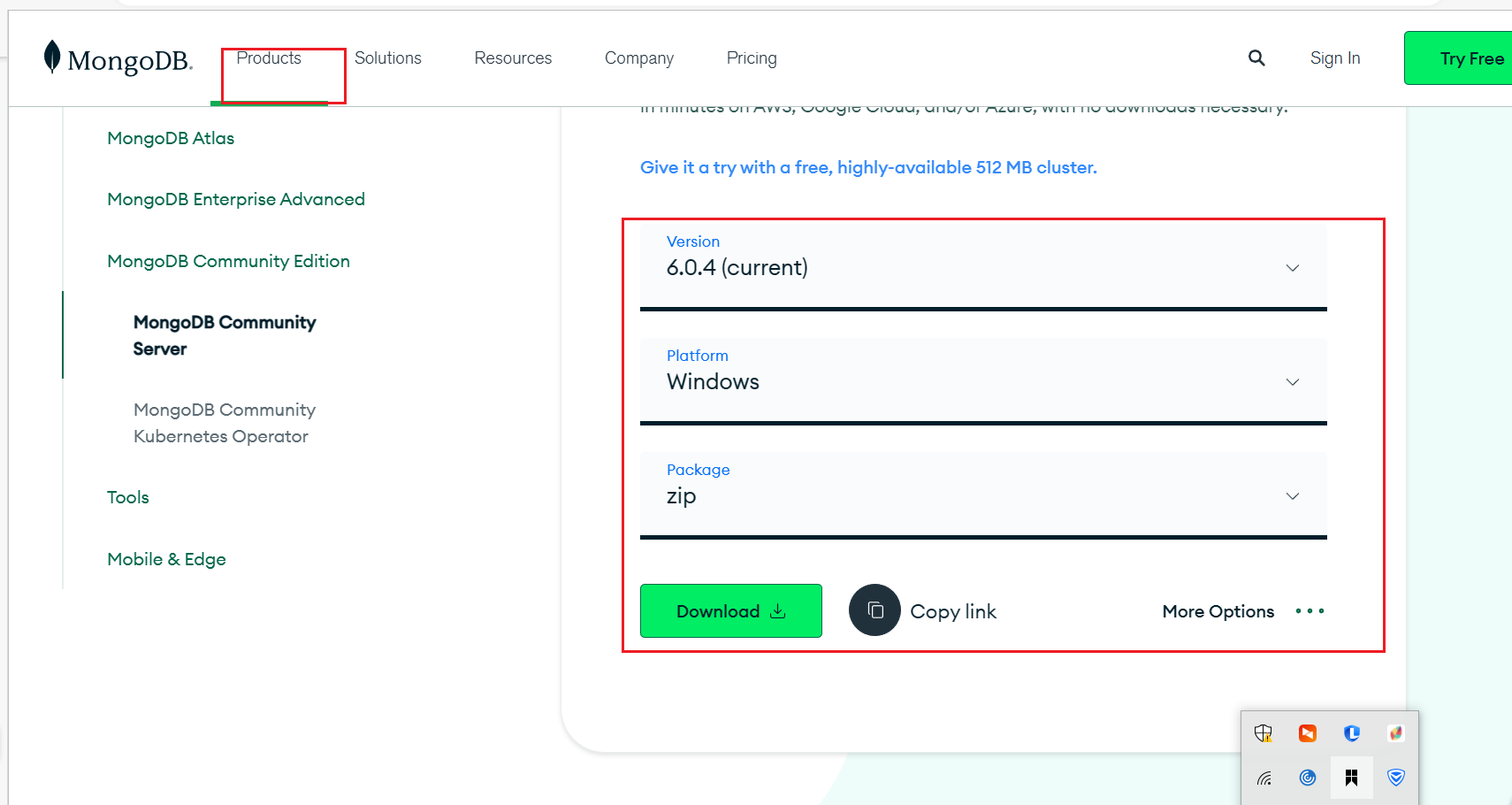
下载界面 选择版本和运行的环境 (我这边就以win 为例的下载 和部署 都是大同小异的)
解压后的bin目录:
当然 mongodbsh.exe 这个一开始是没有的
MongoDB Shell Download | MongoDB

四 服务器的运行和连接
新建 dapath 目录 和 logpath 目录
进入mongo的bin目录中找到如下指令 cmd
mongod.exe --port 27017 --dbpath D:\mongoDB\testItme\data1 --logpath D:\mongoDB\testItme\log\mongodb.log
这个歌时候单节点的服务就启动完成
现在是客户端连接:
mongosh.exe --port 27017 到这里就连接完成 至于命令脚本就自己去官网学习了
五 Java操作mongoDB
- pom配置
pom包里面添加spring-boot-starter-data-mongodb包引用
|
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> </dependencies> |
在application.properties中添加配置
spring.data.mongodb.uri=mongodb://localhost:27017/test
在代码中使用 mongoTemplate 来和数据库做交互(具体的参照springboot官网教程)
六 mongodb的副本集(这边是以win环境部署的 其他环境大同小异)
一、问题引出
假设我们生产上的mongodb是单实例在跑,如果此时发生网络发生问题或服务器上的硬盘发生了损坏,那么这个时候我们的mongodb就使用不了。此时我们就需要我们的mongodb实现高可用,当一个mongod实例出现问题后,其余的mongod实例可以继续提供服务,即自动故障转移。mongodb的复制集(replica set)就可以实现我们的这个需求。
二、什么是复制集
mongodb的复制集指的是一组拥有相同实例的mongod实例所组成的集群。其中有一台服务器充当主节点(Primary Node),主节点可以实现数据的写入和读取操作。其余的节点可以充当备份节点(Secondary Node),备份节点用于保存主节点的数据备份,如果主节点挂了,那么Secondary Node会被选举中Primary Node。在mongodb 中还存在一种仲裁节点(Arbiter Node),仲裁节点只是用于进行投票选举Primary Node,不进行数据的存储。
三、复制集小知识点
1、在复制集中,主节点(primary Node)是唯一的,但是它是不固定的,当主节点宕机后,会重新选举出新的主节点。
2、仲裁节点(Arbiter Node)无法进行存储数据,只是用于充当选举的
3、当复制集中的节点 <= 1/2 时集群只可以读,不可进行写入。
4、对于同一个复制集而言,其配置参数 replSet 的值必须是一样的。
5、数据目录必须要先存在,否则会报错。
6、在window 上使用 --config 指定启动mongod的配置文件路径,liunx上使用 -f
7、复制集的初始化必须要在admin集合上进行操作。
8、仲裁节点只可以存在一个。
9、从节点默认不可查询数据,需要 执行 rs.slaveOk(true) 命令后,才可以查询出数据。
10、如果复制集中有某一台机器的性能明显比别的机器好,那么我们希望该节点成为主节点的概率大一些,此时我们就需要设置 priority(0-1000) 属性的值大一些,该值是复制集的参数选项,见下方表格中复制集的初始化。(注意:如果a节点的priority值最大,此时它宕机了,主节点被b节点获取到了,过一段时间a节点恢复了,那么a节点就会再次获取到主节点,b节点变成从节点。)
11、隐藏节点: priority=0 && hidden=true 该节点拥有和主节点一样的数据,但是不可以被客户端程序发现,使用rs.isMaster()方法无法查询到此节点,rs.status() 可以看到此节点。
12、延时节点: priority=0 && hidden=true && slaveDelay=3600 表示和主节点的数据延时3600秒,即该节点的数据和主节点的数据会存在一个小时的延时。
13、如果要对复制集的某个节点进行维护,那么可以先将这个节点关闭,然后注释掉这个节点中的配置文件中的replSet属性,以单节点的方式启动,维护好后,关闭节点,恢复这个属性,然后再以复制集进行启动。
四、复制集节点数量
在mongodb的复制集中,如果要一个复制集是可用的,那么存活的节点数必须要 > 1/2 的总节点数,即当有一个4个节点的复制集和3个节点的复制集,当复制集不可用时,都是有2个节点挂掉,此时存活的节点会降级成从节点。所以我们复制集一般使用奇数个几点,假设我们没有那么多的机器,那么我们可以添加一个仲裁节点。
大多数原则:当集群中的存活的节点数量小于集群总数的 1/2时,集群不可用。
大多数原则举例:假设我们有2个机房,上海机房和北京机房,总共署了7个节点,其中上海机房有4个mongod节点,北京机房有3个mongod节点,主节点在上海机房。此时北京机房的网络发生问题无法连接到上海的机房,如果没有大多数原则,那么北京机房将发生master选举,此时就会存在mongodb集群中就会存在2个主节点。如果存在大多数原则,因为总节点是7个,北京机房只有3个节点,3个节点小于总节点的1/2,因此不会发生master选举。
1 在本地盘 创建文件夹
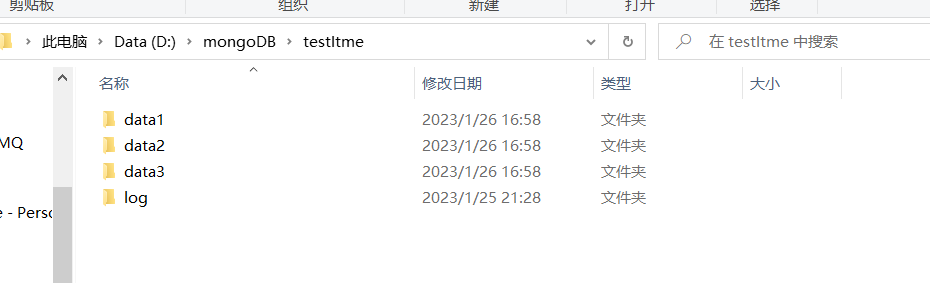
2 配置文件的内容
27017.conf
#mongodb端口
port=27017
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\testItme\log\mongodb1.log
# 数据文件的目录
dbpath=D:\mongoDB\testItme\data1
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace
27018.conf
#mongodb端口
port=27018
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\testItme\log\mongodb2.log
# 数据文件的目录
dbpath=D:\mongoDB\testItme\data2
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace
27019.conf
#mongodb端口
port=27019
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\testItme\log\mongodb3.log
# 数据文件的目录
dbpath=D:\mongoDB\testItme\data3
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace
注意:
1、三个配置文件的 replSet 的值必须是一致的。 2、dbpath这个目录必须要先存在。
3、oplogSize的值但是是MB,这个值最好大一些,这个值决定了主节点上local数据库中oplog这个固定集合的大小,从节点从这个固定集合中实现数据的复制。
4、oplog的默认大小:(对于windows和unix系统,默认是系统磁盘可用的5%,不同的引擎存在不同的上下限)
准备工作完成 启动服务
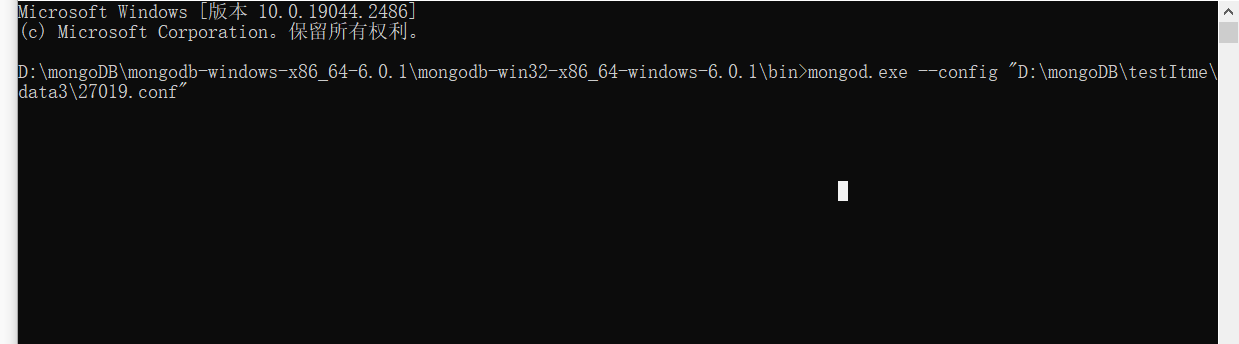
mongod.exe --port 27017 --dbpath D:\mongoDB\testItme\data1 --logpath D:\mongoDB\testItme\log\mongodb.log --replSet myreplace\192.168.12.1:27018
mongod.exe --port 27018 --dbpath D:\mongoDB\testItme\data2 --logpath D:\mongoDB\testItme\log\mongodb.log --replSet myreplace\192.168.12.1:27019
mongod.exe --port 27019 --dbpath D:\mongoDB\testItme\data3 --logpath D:\mongoDB\testItme\log\mongodb.log --replSet myreplace\192.168.12.1:27017
连上任意节点,执行复制集的初始化(这边连接的27107)
use admin
rs.initiate({
_id : "myreplace",
members : [
{_id : 0,host : "192.168.12.1:27017","priority":10},
{_id : 1,host : "192.168.12.1:27018"},
{_id : 2,host : "192.168.12.1:27019"}]
});
注意:
1、在连上mongod时,必须要指定 ip ,因为这个参数是在mongodb的配置文件2701*.conf中的bind_ip指定的。
2、复制集的初始化必须要先使用 use admin,即必须要在admin集合上进行操作。
3、最外层 _id 的值为复制集中 replSet 的值,里面members中的 _id 的值不可重复。
4、priority(0-1000)属性的默认值为1,此值越大越有可能成为主节点。
这个时候副本集就算搭建完成了
复制集的基本操作方法
rs.initiate({}) 初始化复制集
1、use admin
rs.reconfig() 重新初始化复制集
rs.isMaster() 返回副本集的配置和状态子集
rs.status() 查看副本集的状态
rs.config() 查看副本集的配置
rs.stepDown(秒1,秒2) 将主节点变成从节点
rs.add({}) 添加复制集成员
1、rs.add("host:port")
2、rs.add({"host":"",....})
3、rs.add("host:port",true) 添加仲裁节点
rs.addArb("host:port")
添加仲裁成员
rs.remove("host:port")
删除复制集成员
1、建议先将需要删除的复制集成员关闭,然后再删除。
2、该命令会短暂的断开并强制重连
注意:
rs.slaveOk(true) 允许复制集上的该成员读取数据(在4.XX版本以前是这个命令,现在我用的是6.XX 在从节点想要查询数据 rs.secondaryOk() 这个命令就可以了 )
整合springboot
打完收工,后续会把mongodb的分片也记录一下
