

2022-2023-1 20221318 《计算机基础和程序设计》第六周学习总结
作业信息
这个作业属于那个班级 https://edu.cnblogs.com/campus/besti/2022-2023-1-CFAP
作业要求 https://www.cnblogs.com/rocedu/p/9577842.html#WEEK03
作业目标 学习《计算机科学概论》第七章
作业正文 https://i.cnblogs.com/posts/edit;postId=16751223
教材内容总结
在第七章“问题求解与算法设计”中,
- 如何解决问题
分析总结——列出主要问题——编写其余的模块——根据需要进行重组和改写 - 有简单变量的算法
1.带有选择的算法

2.带有循环的算法:计数控制循环、事件控制循环、嵌套结构
3.抽象步骤、具体步骤 - 复杂变量
1.数组

2.记录:集合中可以包括整数、实数、字符串或其它类型的数据 - 搜索算法
1,顺序搜索

2.有序数组里的顺序搜索


3.二分检索 - 排序
1.选择排序
2.冒泡排序

3.插入排序

- 递归算法
1.子程序语句
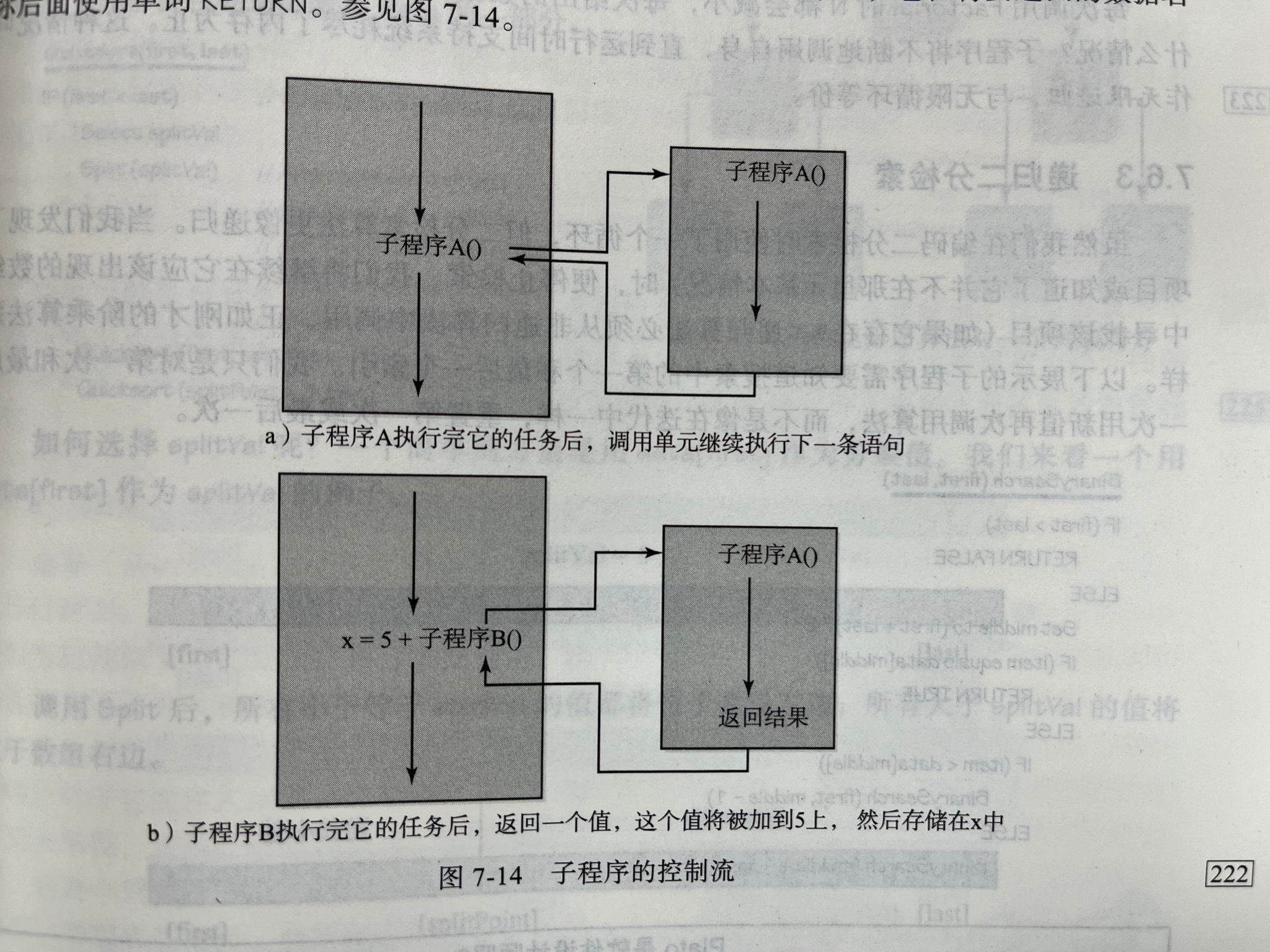
2.递归阶乘

3.递归二分检索

4.快速排序 - 几个重要思想:信息隐藏、抽象
学习中遇到的问题
Q:二分检索法和顺序搜索的性能比较
A: 从时间复杂度上来看顺序查找的时间复杂度为O(n),二分法查找的时间复杂度为O(log_2n),很明显二分查找所耗费的时间比顺序查找少了很多很多。数据量越大,越能体现出二分法的快速性;相反数据量小的话,两者都可以使用。
但是因为计算中间项的索引,每个比较操作都需要更多的计算。此外,数组必须是有序的。
Q;冒泡排序、插入排序、选择排序的比较
A:冒泡排序的流程
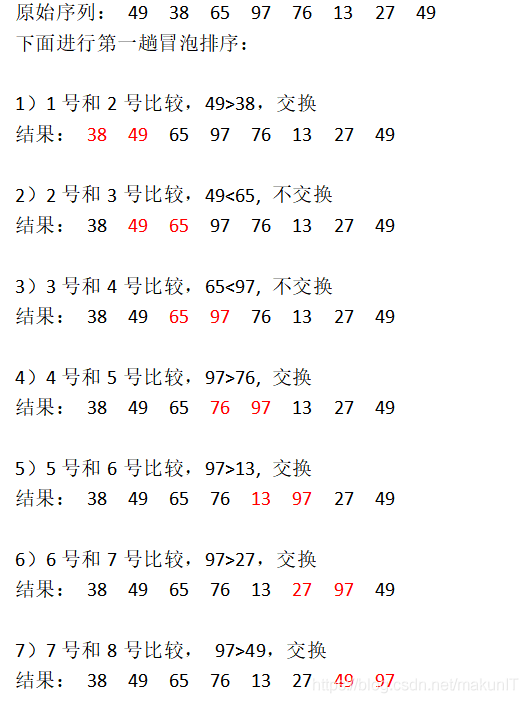
至此一趟气泡排序结束,最大的97被交换到了最后,97到达了它最后的位置。接下来对序列38 49 65 76 13 27 49 按照同样的方法进行第二趟冒泡排序。经过若干趟冒泡排序后,最终序列有序。
插入排序的流程

选择排序的流程

时间、空间复杂度的比较

Q:快速排序的原理及意义:
A:快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
算法步骤:
1.从数列中挑出一个元素,称为 "基准"(pivot)。
2.重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区操作。
3.递归地把小于基准值元素的子数列和大于基准值元素的子数列排序;
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 第一周 | 0/0 | 3/3 | 20/20 | |
| 第二周 | 105/105 | 2/5 | 20/40 | |
| 第三周 | 150/255 | 2/7 | 20/60 | |
| 第四周 | 210/465 | 2/9 | 20/80 | |
| 第五周 | 280/745 | 2/11 | 20/100 | |
| 第六周 | 320/1065 | 1/12 | 20/120 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现