Docker:InfluxDB的UI界面使用教程
网络上的InfluxDB Studio客户端工具只适用于1.8之前的版本,所以为了更好的操作influxDB需要借助其自带的Web UI界面,本机部署访问地址:http://localhost:8086
首页

常用功能:
Data:数据加载模块(Load Data),他包含策略桶管理、文件导入库、Telegraf、主动抓取任务、生成访问Token等功能
Explore:数据查询模块(Data Explore),通过编写Flux语法或选择条件去查询库内的数据,数据展示结果也会有多种形式
Books:工作流处理模块(NoteBooks),通过在工作流内插入开发、文档编写、运行代码等组件对数据进行采样清洗或者回写到存储桶等操作
Tasks:定时任务管理模块(Tasks),针对创建的定时任务做管理的页面
Load Data(数据加载)
Sources(文件上传)
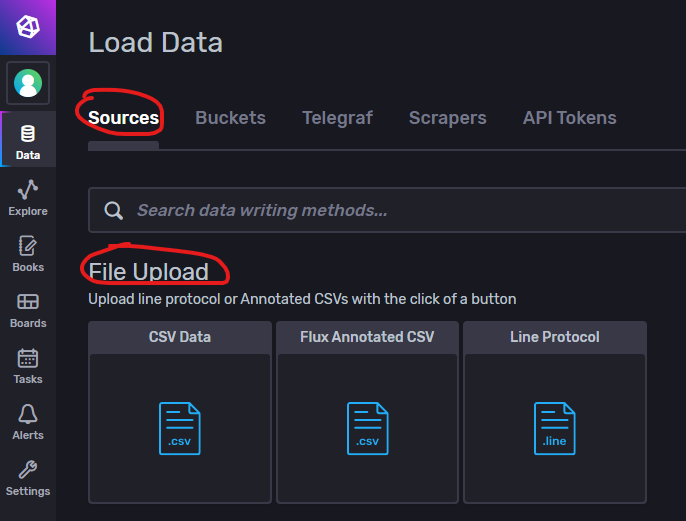
我们可以用文件的方式上传数据,前提是文件中的数据符合InfluxDB支持的类型,包括CSV、带Flux注释的CSV和InfluxDB行协议等。
CSV Data
可用于创建策略桶信息。
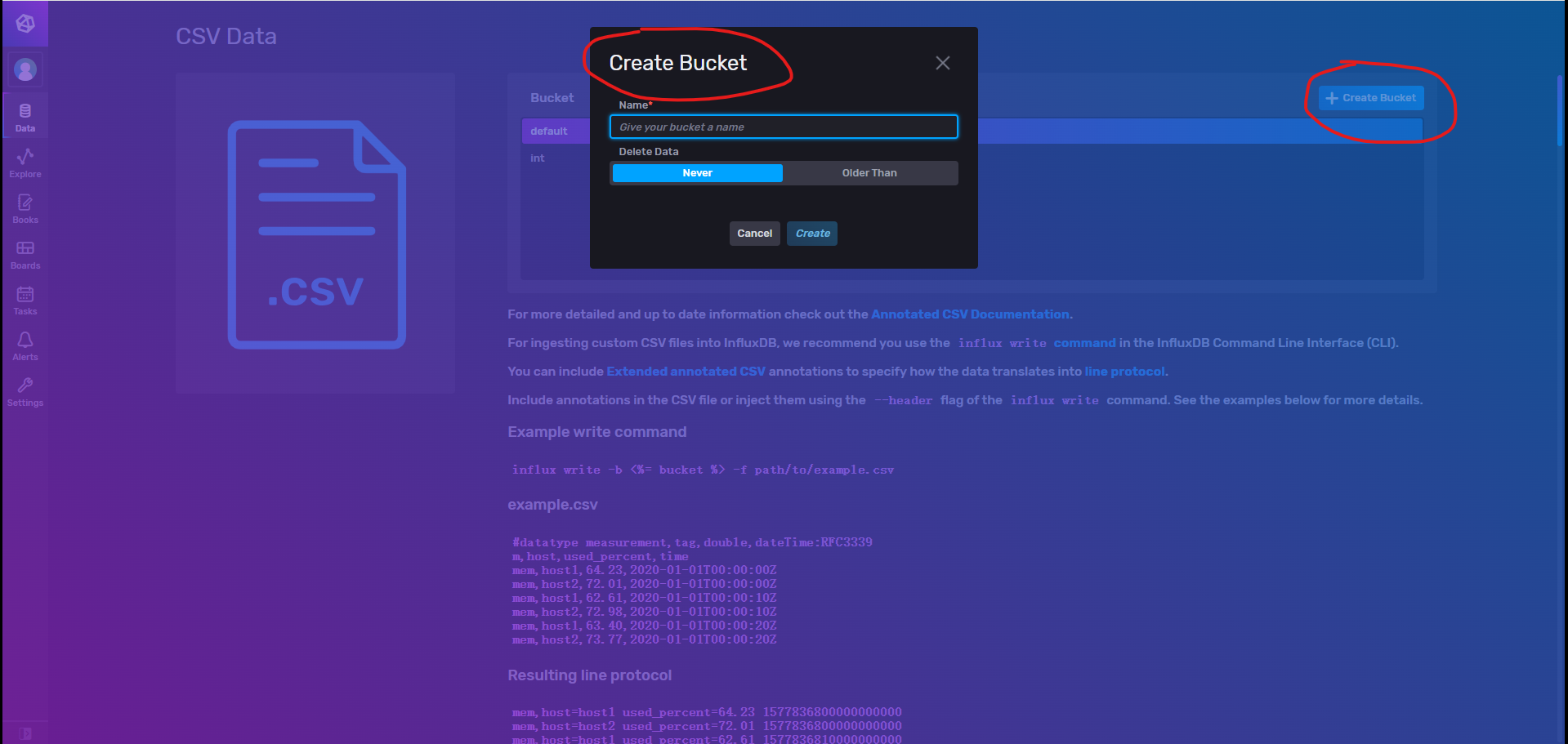
Flux Annotated CSV
通过选择策略桶并上传Flux结构的数据文件进行导入到库中
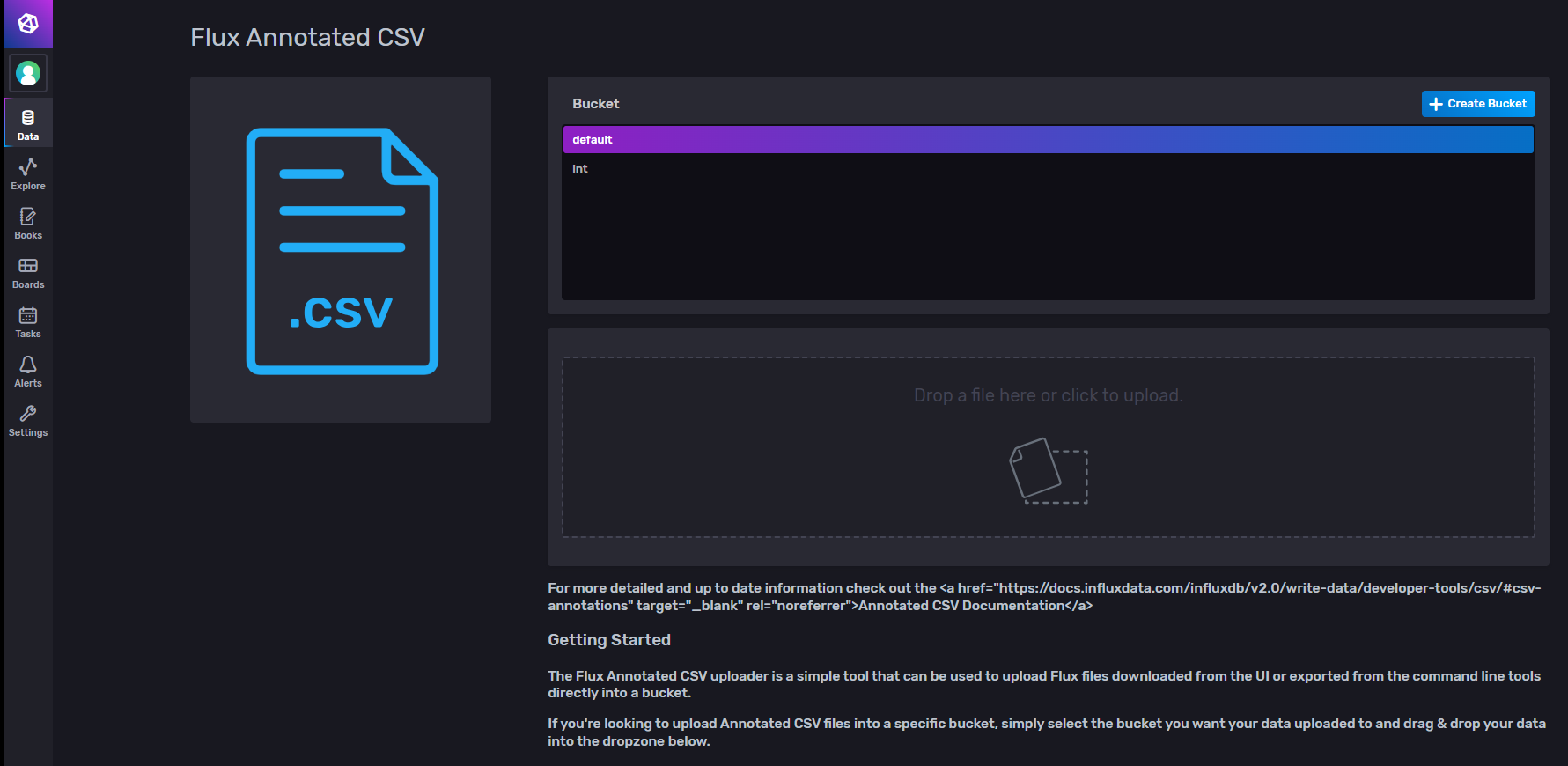
Line Protocol
通过选择策略桶并上传influxdb行格式文件进行导入库。
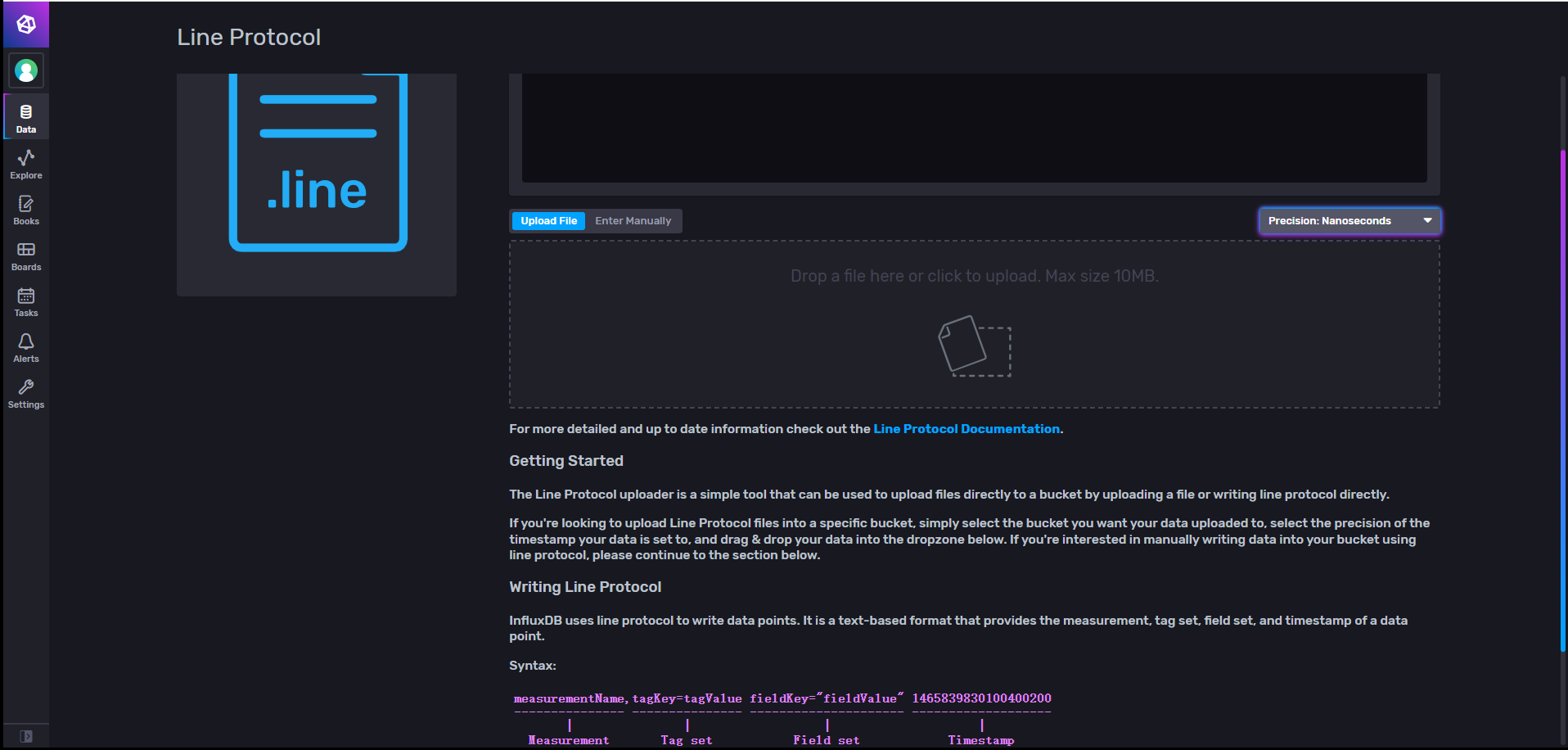

时间精度包括:纳秒、微秒、毫秒和秒。
people,name=tony age=12
people,name=xiaohong age=13
people,name=xiaobai age=14
people,name=xiaohei age=15
people,name=xiaohua age=12当前我们写的数据格式叫做InfluxDB 行协议,保存后回出现如下提示,这就表明数据添加成功。

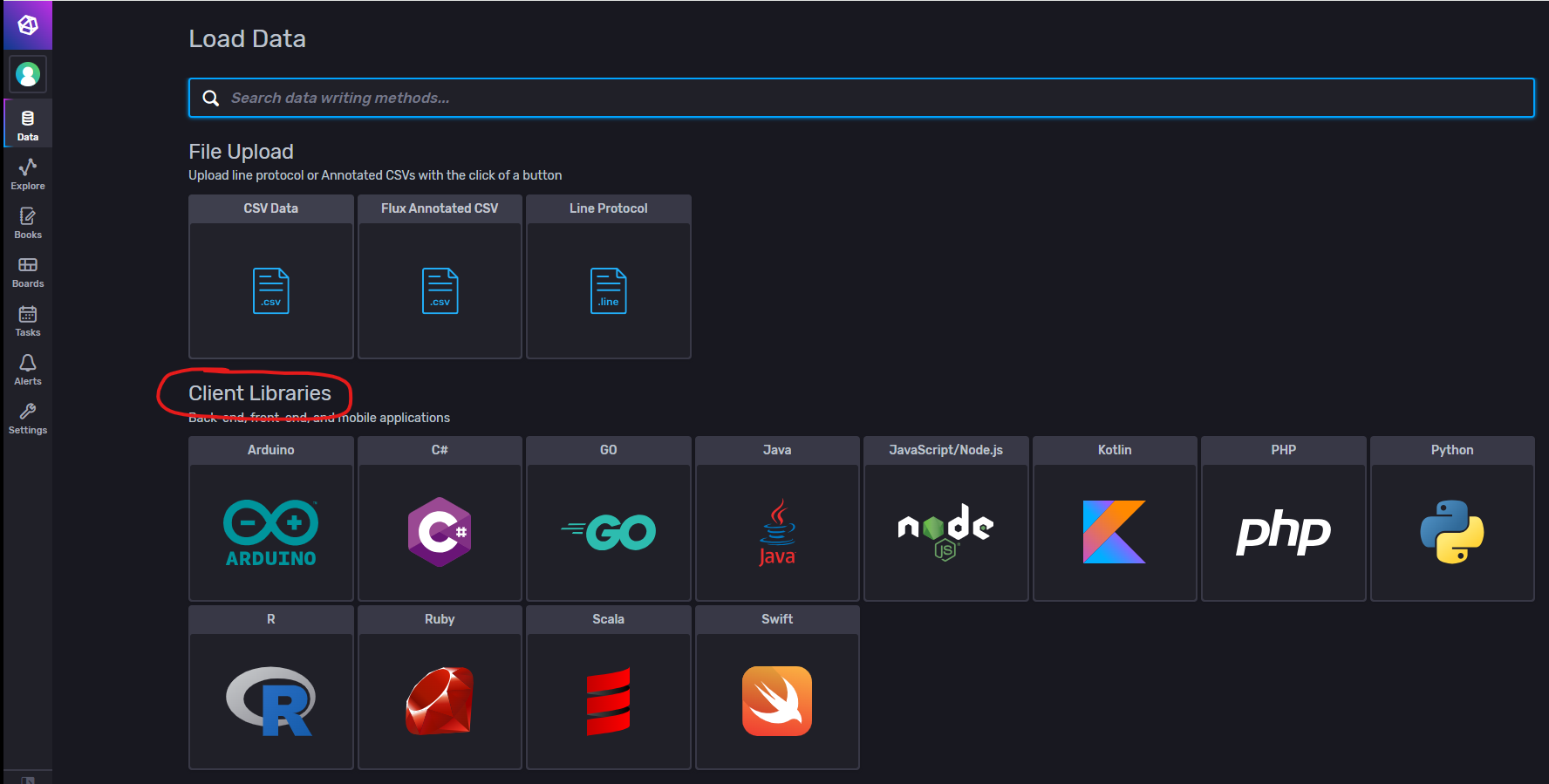
Client Libraries
Sources内还提供了一些不同语言的代码调用示例。
Buckets(策略桶)
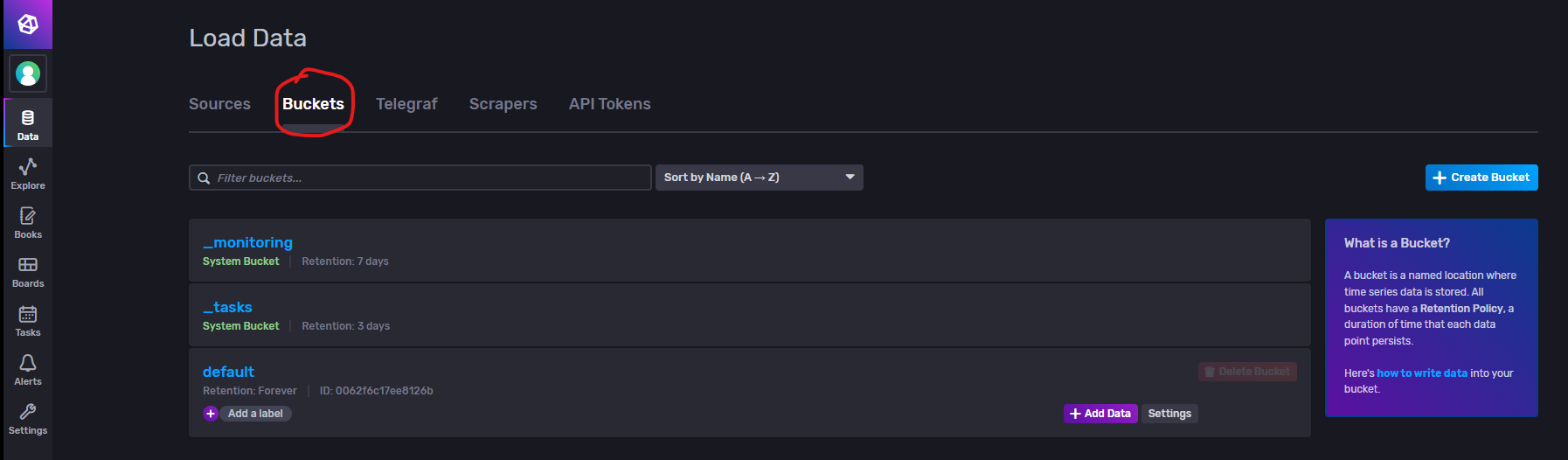
可以将InfluxDB中的bucket理解为普通关系型数据库(Mysql)中的database。
创建策略桶
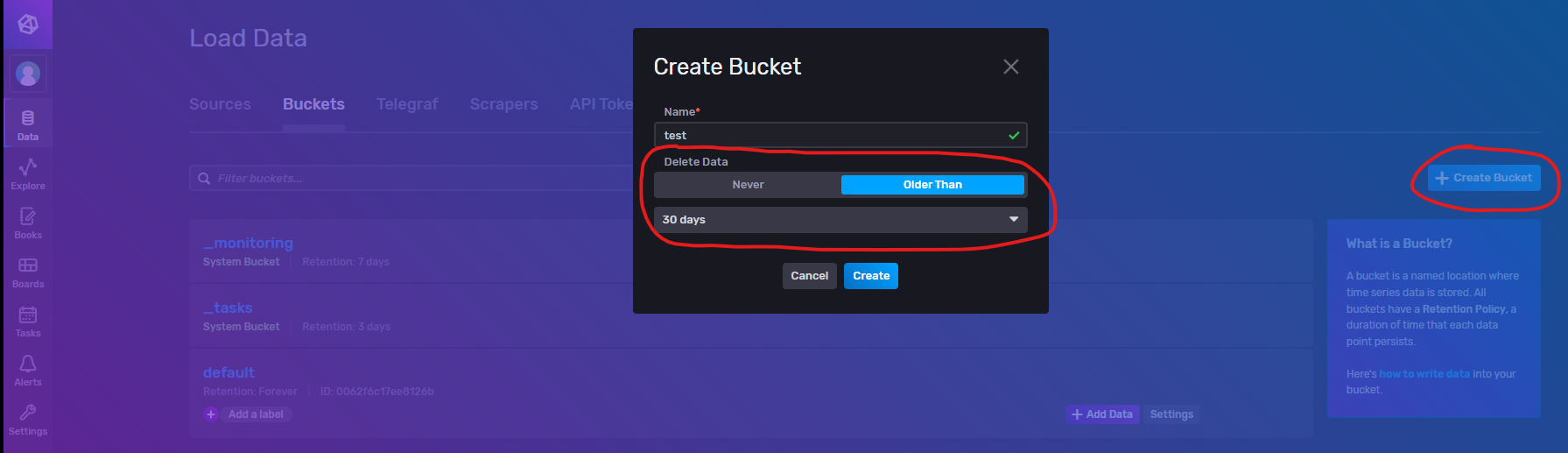
点击右上角的 Create Bucket 按钮进行新增策略桶,有两种策略,Never:从不删除数据; Older Than:删除超出当前时间间隔指定天数(小时数)之前的旧数据
删除策略桶
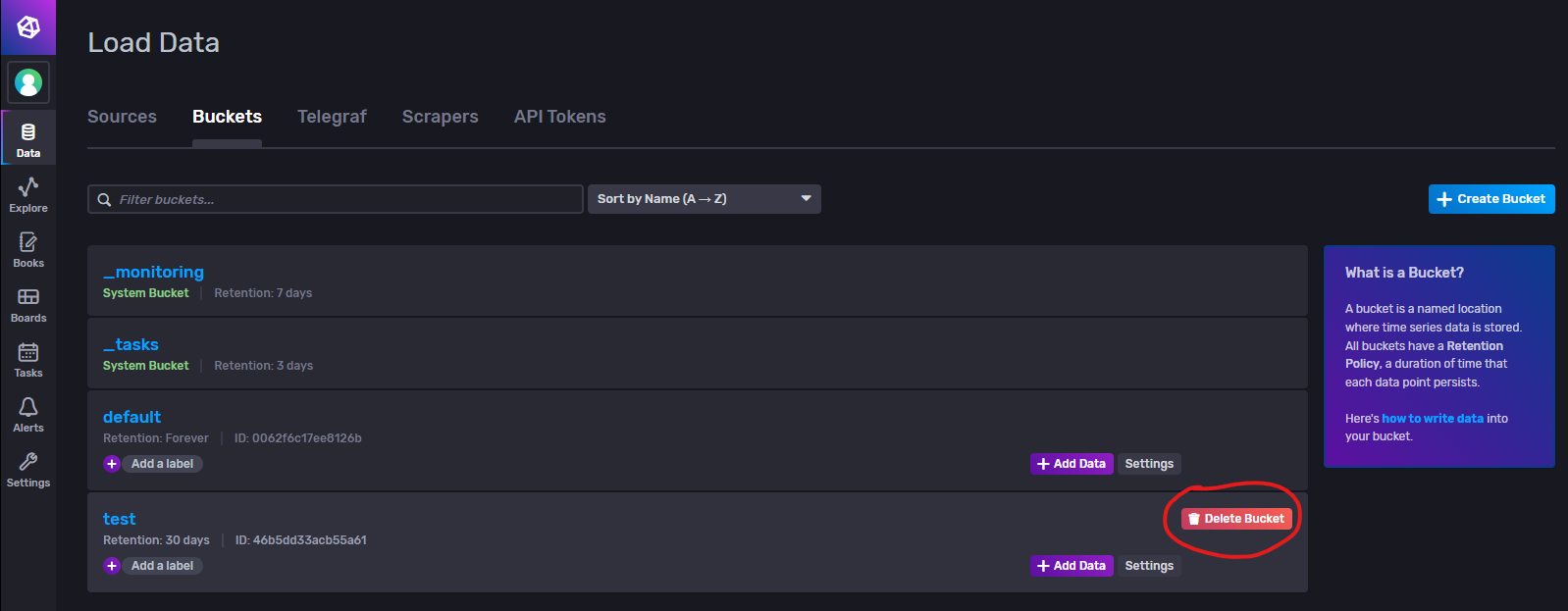
鼠标移动到需要删除的策略桶内,就会出现可删除标识。
编辑策略桶
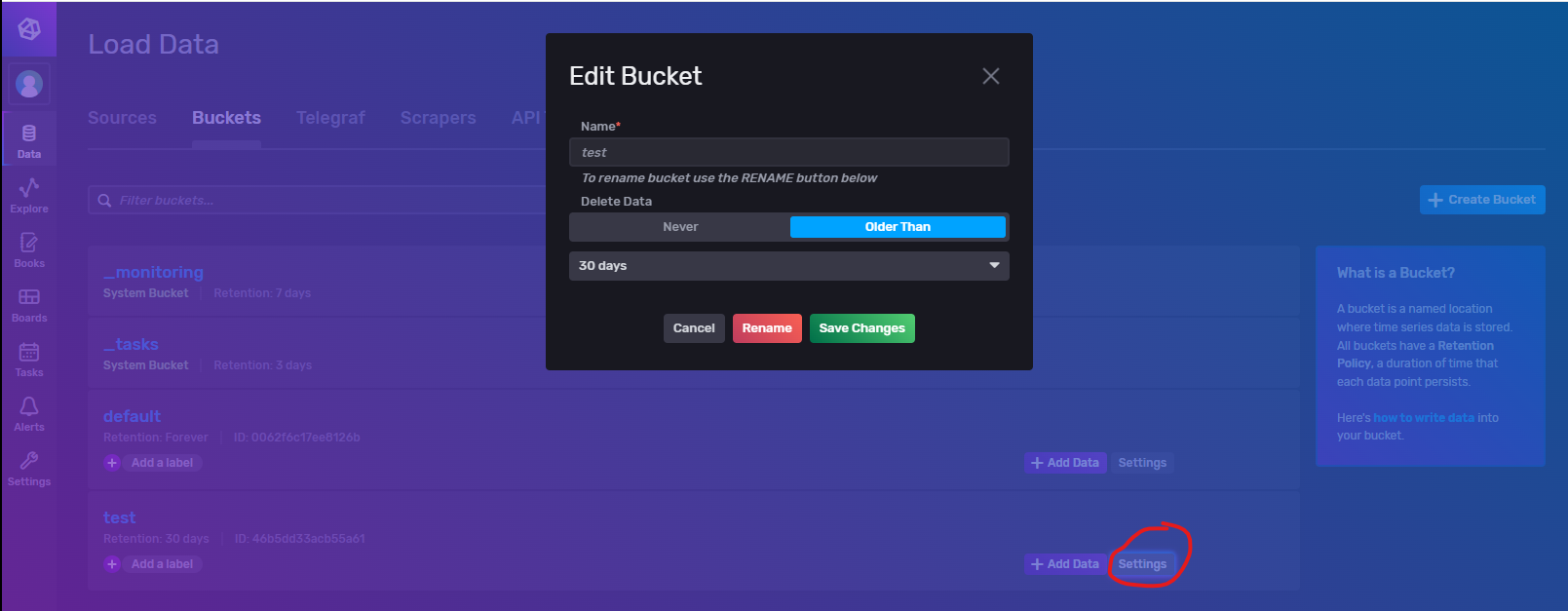
通过Setting可以修改策略配置,其中还提供了改名功能(不推荐这么做,很可能会出问题!!)
添加数据
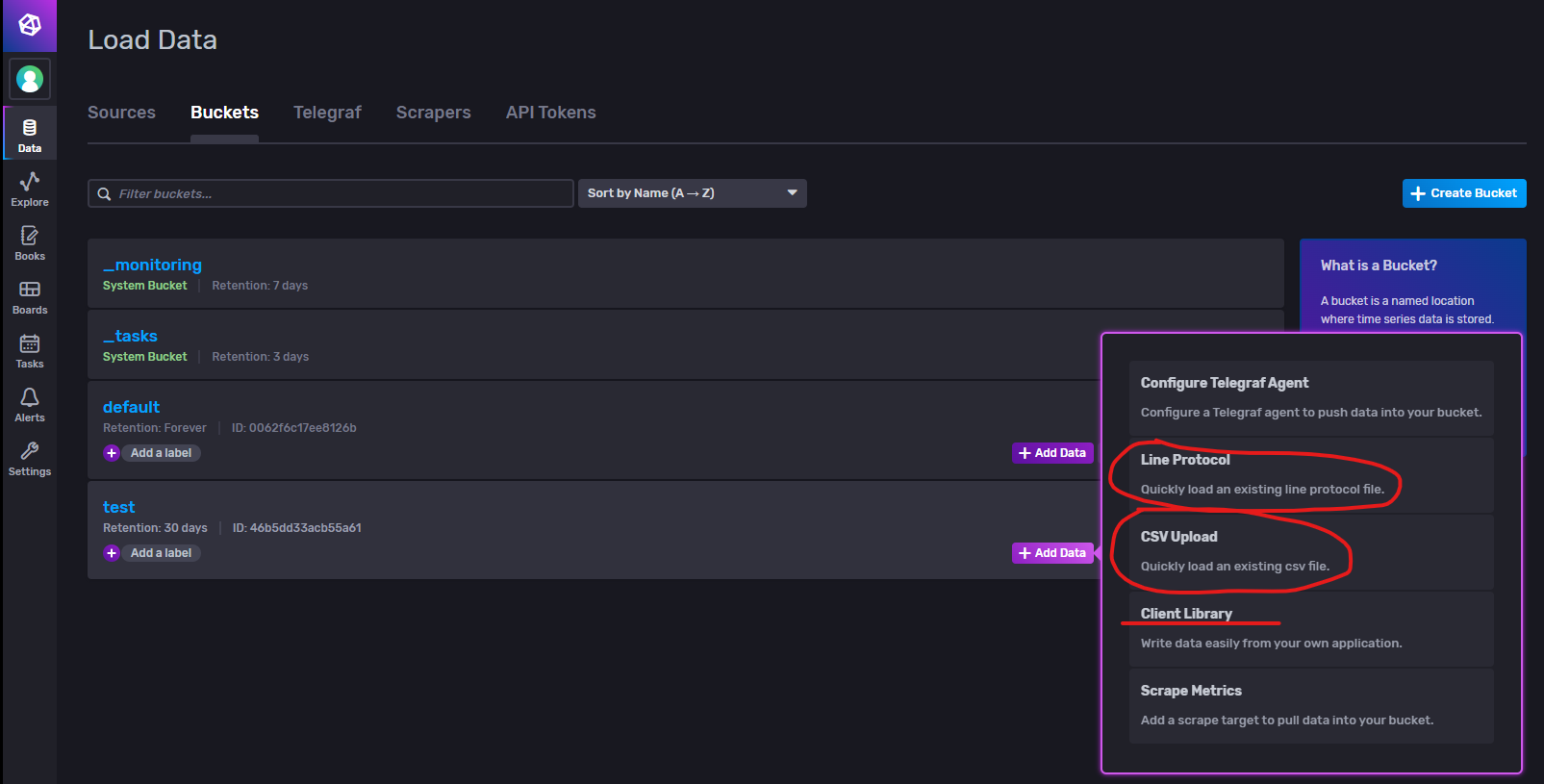
可以看到刚刚学习的数据文件上传在这里也有体现。
Telegraf(数据采集配置)
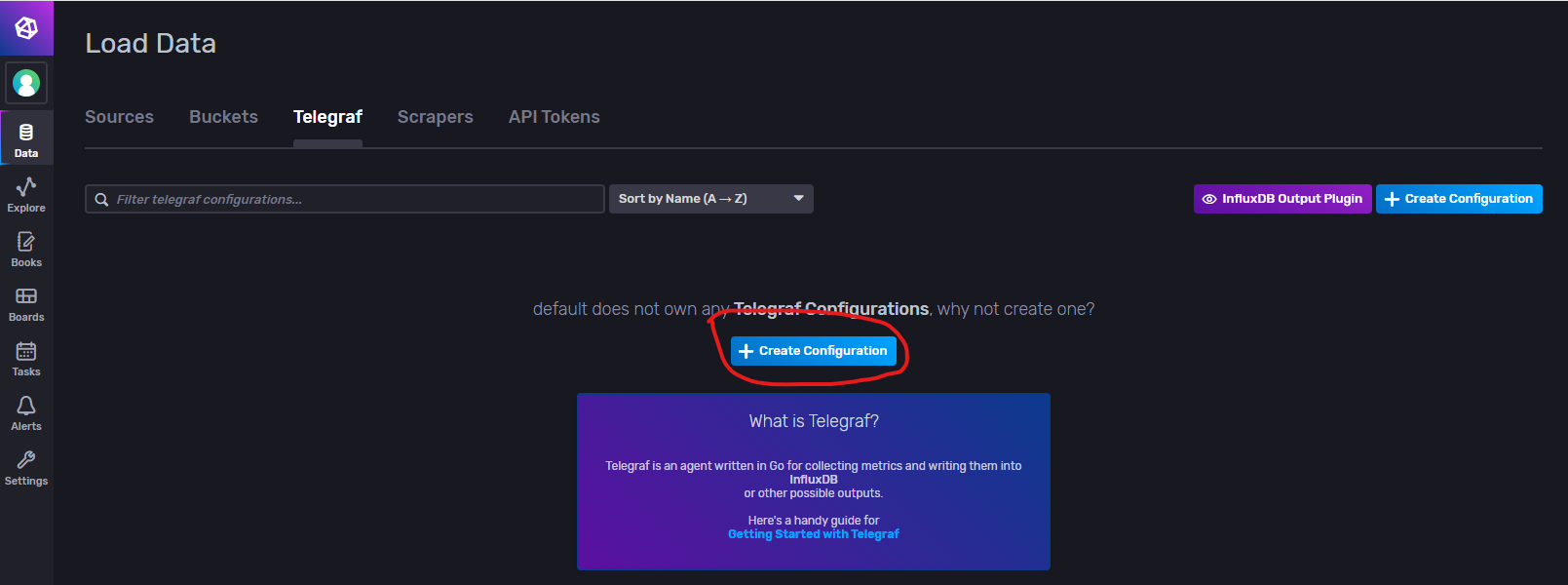
Telegraf是一个数据采集软件,而当前操作页面是生成Telegraf配置文件并生成访问配置文件的接口,当我们自己下载Telegraf软件后可以通过提供的访问配置文件接口去采集指定数据并存储到infludb的策略桶中。
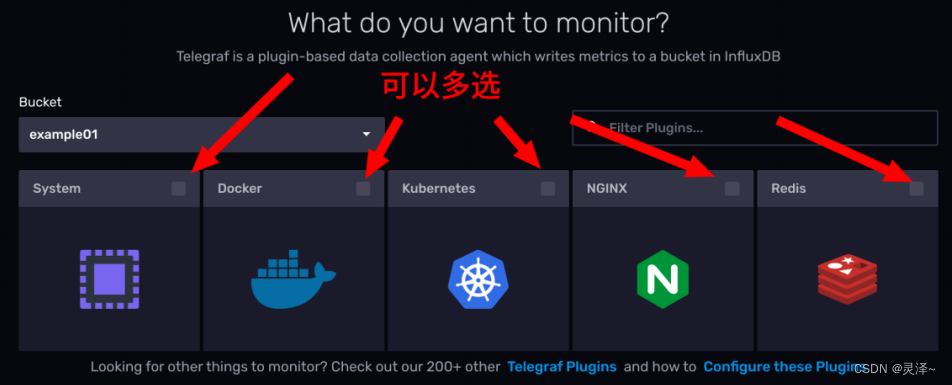
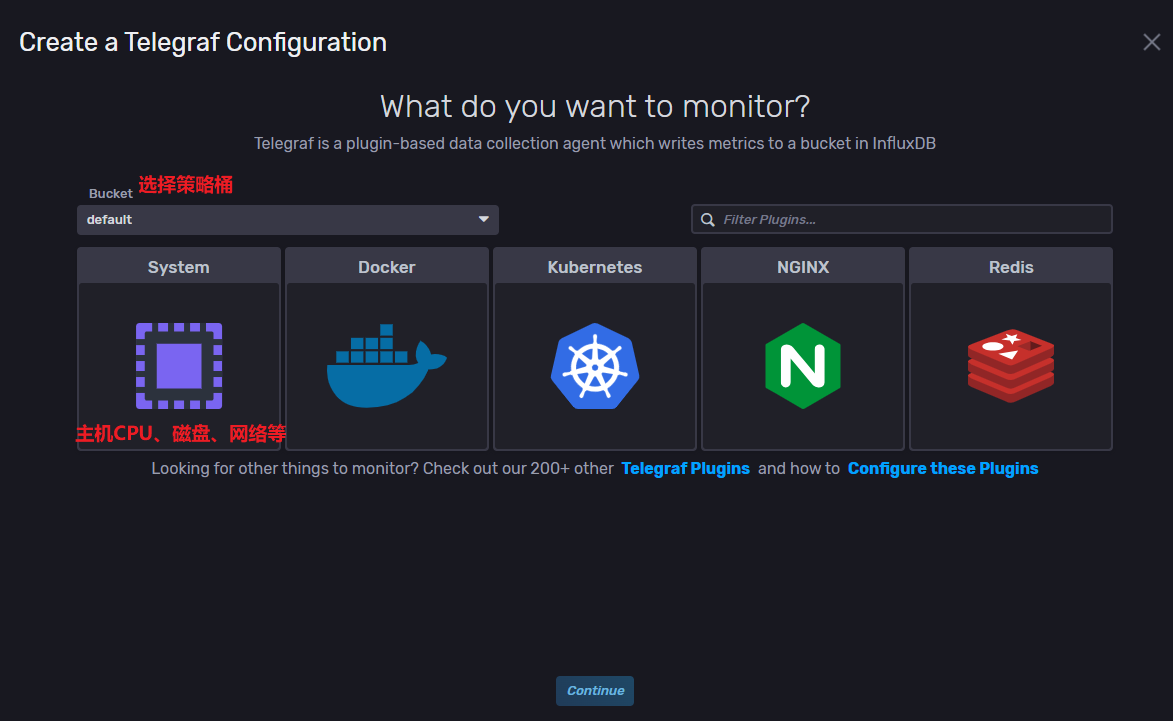
Telegraf搭配influxDB的telegraf配置文件监测服务教程
Scrapers(抓取任务策略)
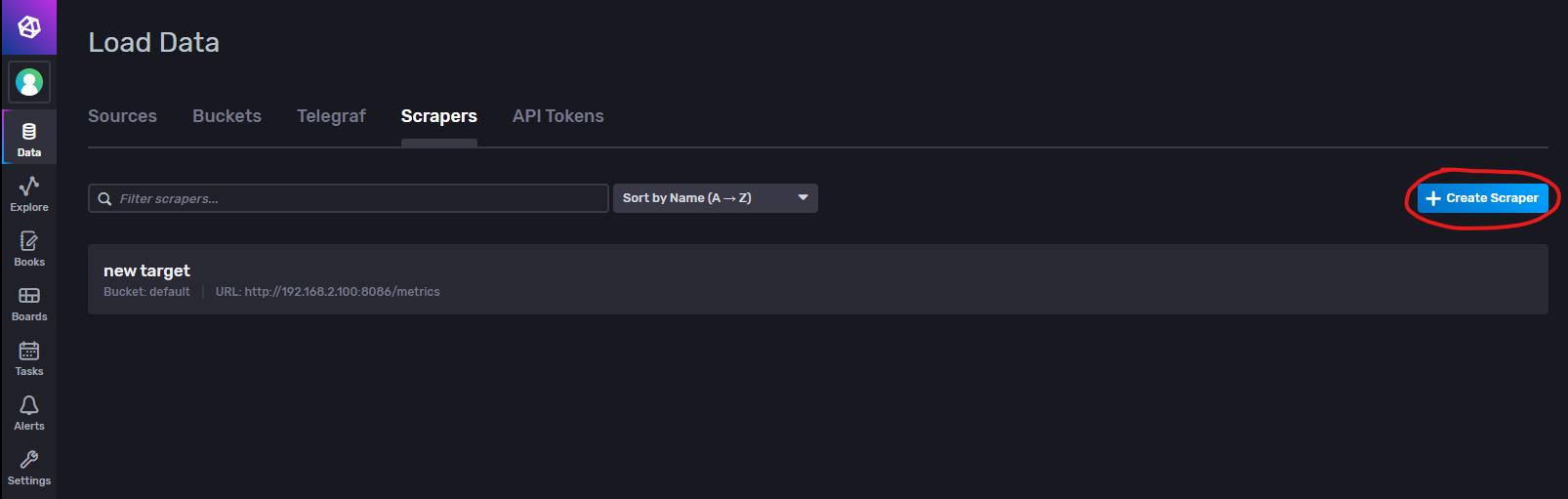
给定一个URL,InfluxDB每隔一段时间去访问这个链接,把访问到的数据入库。在InfluxDB 1.x的时候,类似的任务只能由Telegraf来实现。在InfluxDB 2.x中,内置了抓取功能(但是定制性上不如Telegraf,比如轮询间隔只能是 10 秒);目标 URL 暴露出来的数据格式必须得是Prometheus数据格式!!
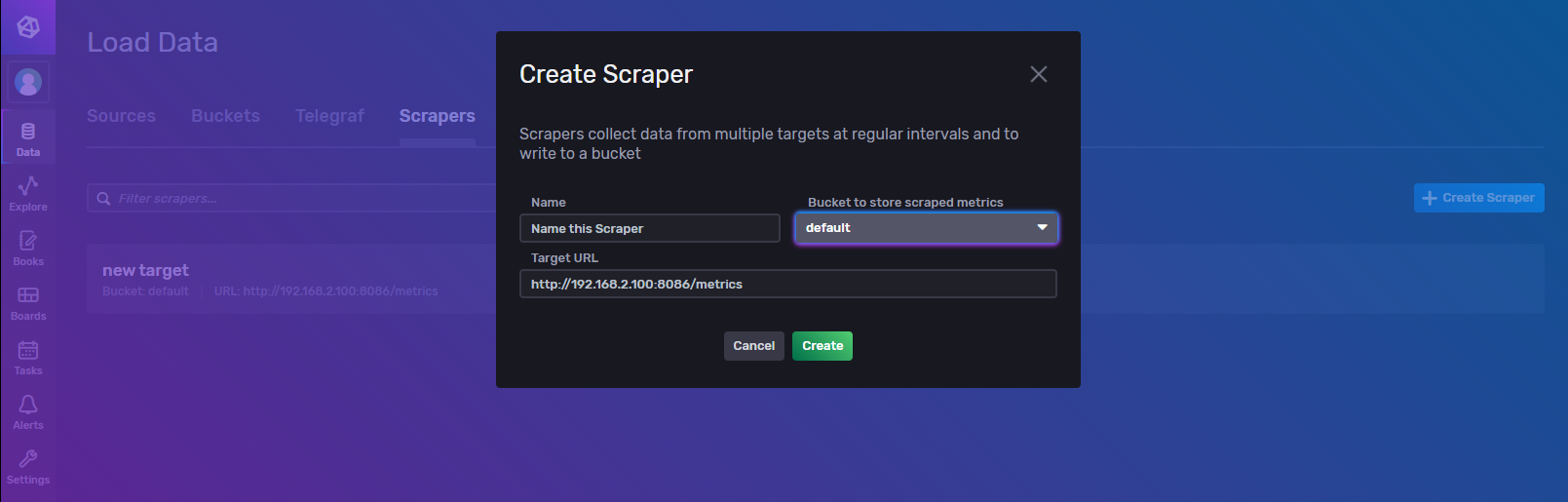
至少截至目前( 2 .4版本),用户无法去自定义抓取间隔。InfluxDB会每隔 10 秒一次去抓取数据,这一点需要注意!!!
Prometheus数据格式
## metric name:指标名称
## label name:标签名
## label value:标签值
<metric name>{<label name>=<label value>, ...}示例
node_cpu_seconds_total{cpu="0",mode="idle"}
node_cpu_seconds_total{cpu="0",mode="iowait"}
node_cpu_seconds_total{cpu="0",mode="irq"}
node_cpu_seconds_total{cpu="0",mode="nice"}
node_cpu_seconds_total{cpu="0",mode="softirq"}
node_cpu_seconds_total{cpu="0",mode="steal"}
node_cpu_seconds_total{cpu="0",mode="system"}
node_cpu_seconds_total{cpu="0",mode="user"} API Tokens(请求访问令牌)
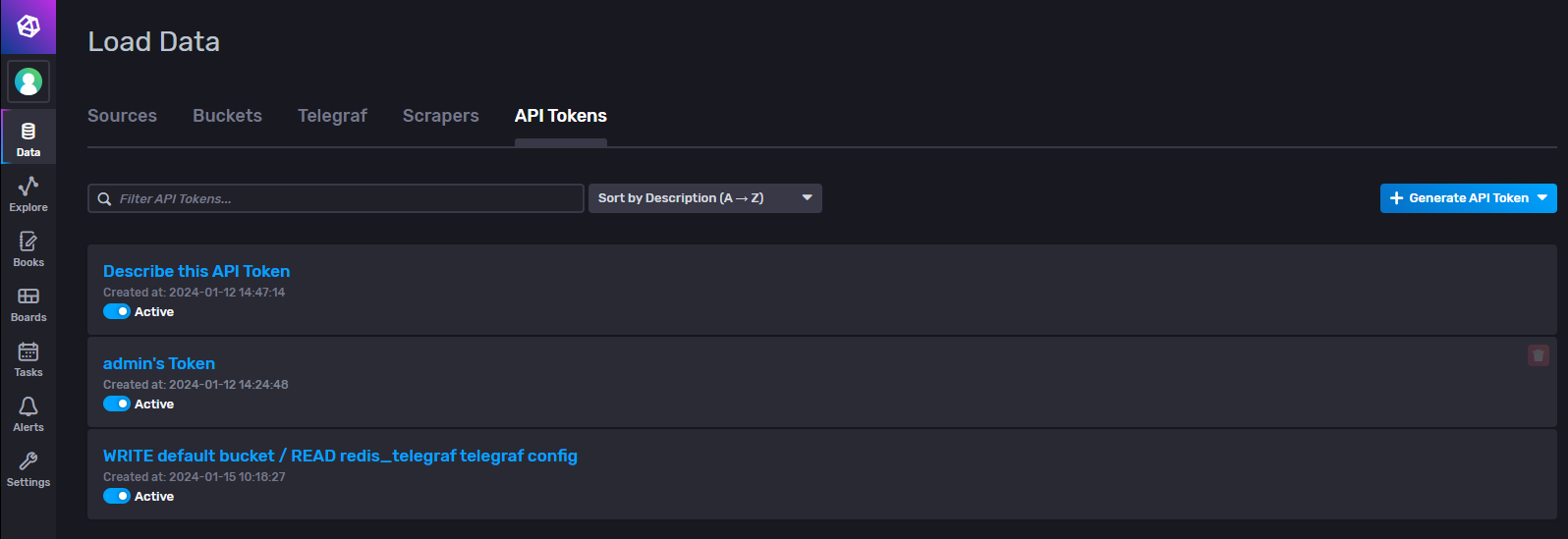
在InfluxDB中,对权限的管理主要就体现在API的Tokens上,客户端会将token放到http的请求头上,influxdb 服务端会根据客户端发来的请求头部的token,来判断你能不能对某个存储桶读写,能不能删除存储桶,创建仪表盘等;包括influxDB的命令行操作工具等,其实都是封装的对 influxdb 的http请求,所以必须携带API Token。
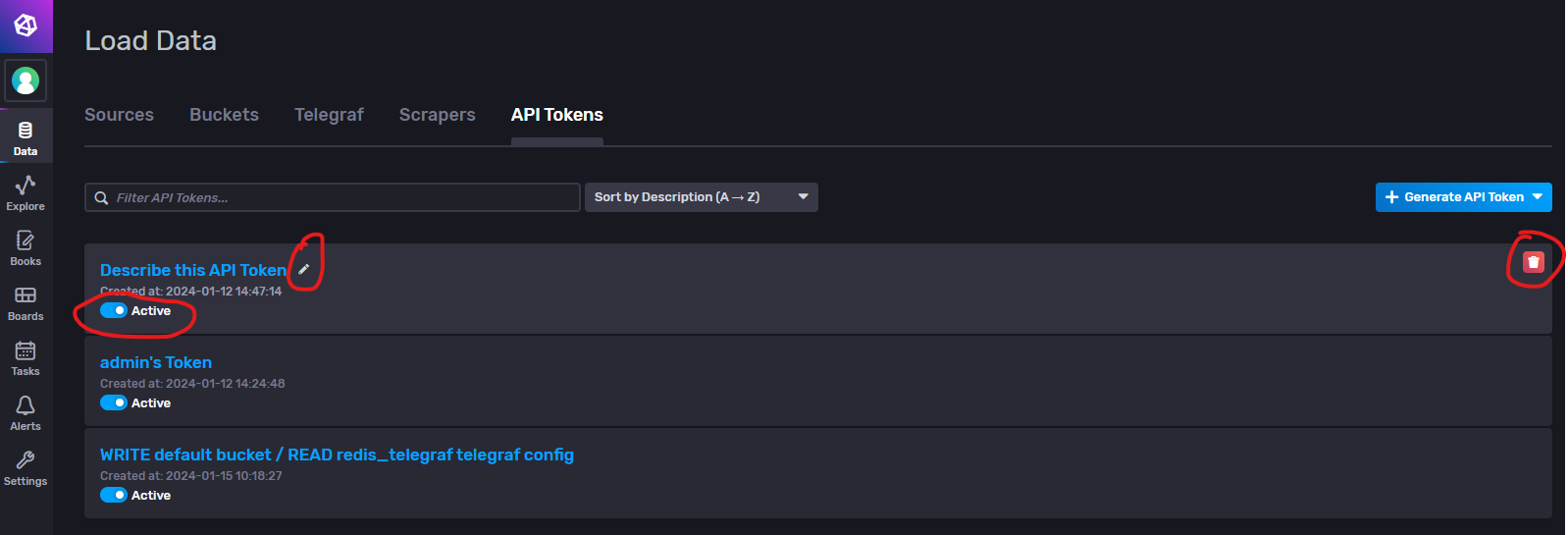
鼠标放到token名上,名称右侧会有编辑的铅笔图表,最右侧则是删除操作,token名称下方的Active则表示这个token是否生效。
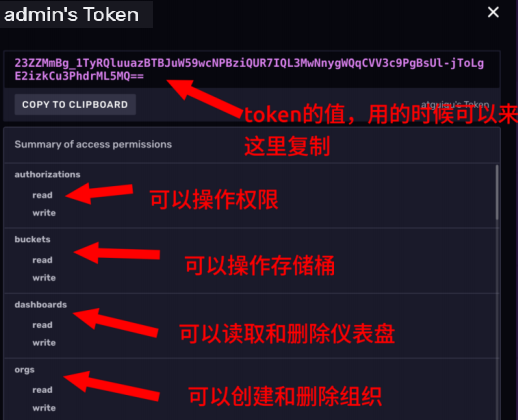
点击token名称就能看到当前token的权限范围
创建新的Token
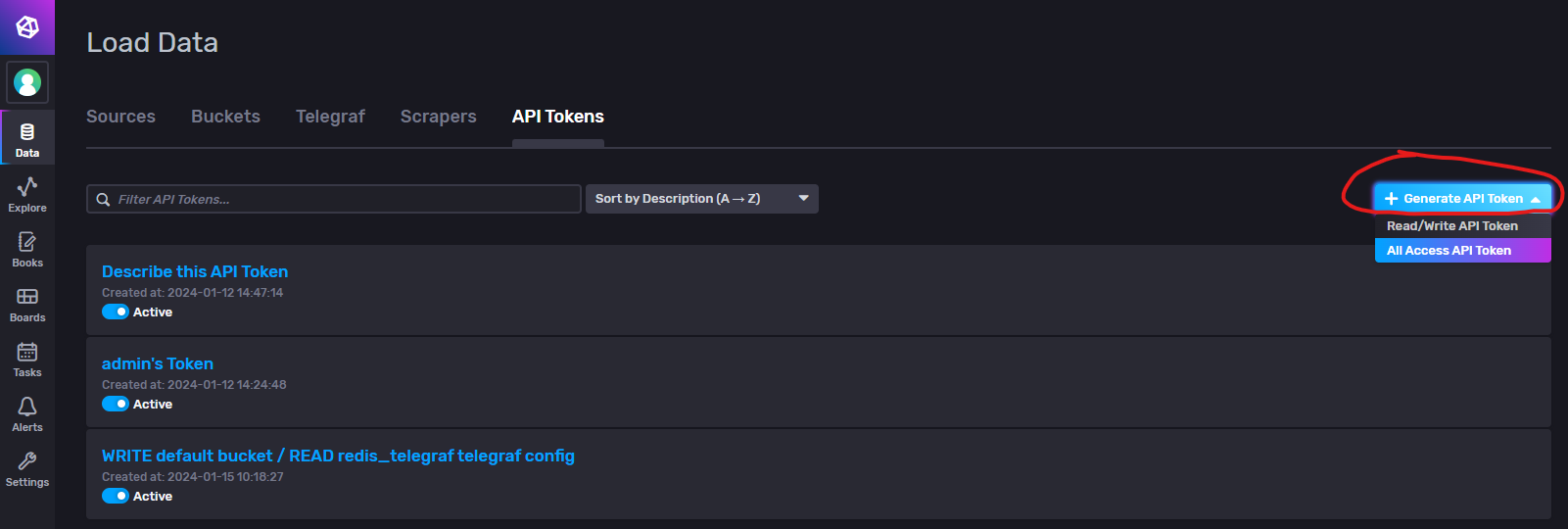
点击右侧 创建Token 按钮,会有两个选项,Read/Write API Token:读写权限 All Access API Token:最大权限
Data Explorer(数据查询)
操作页面
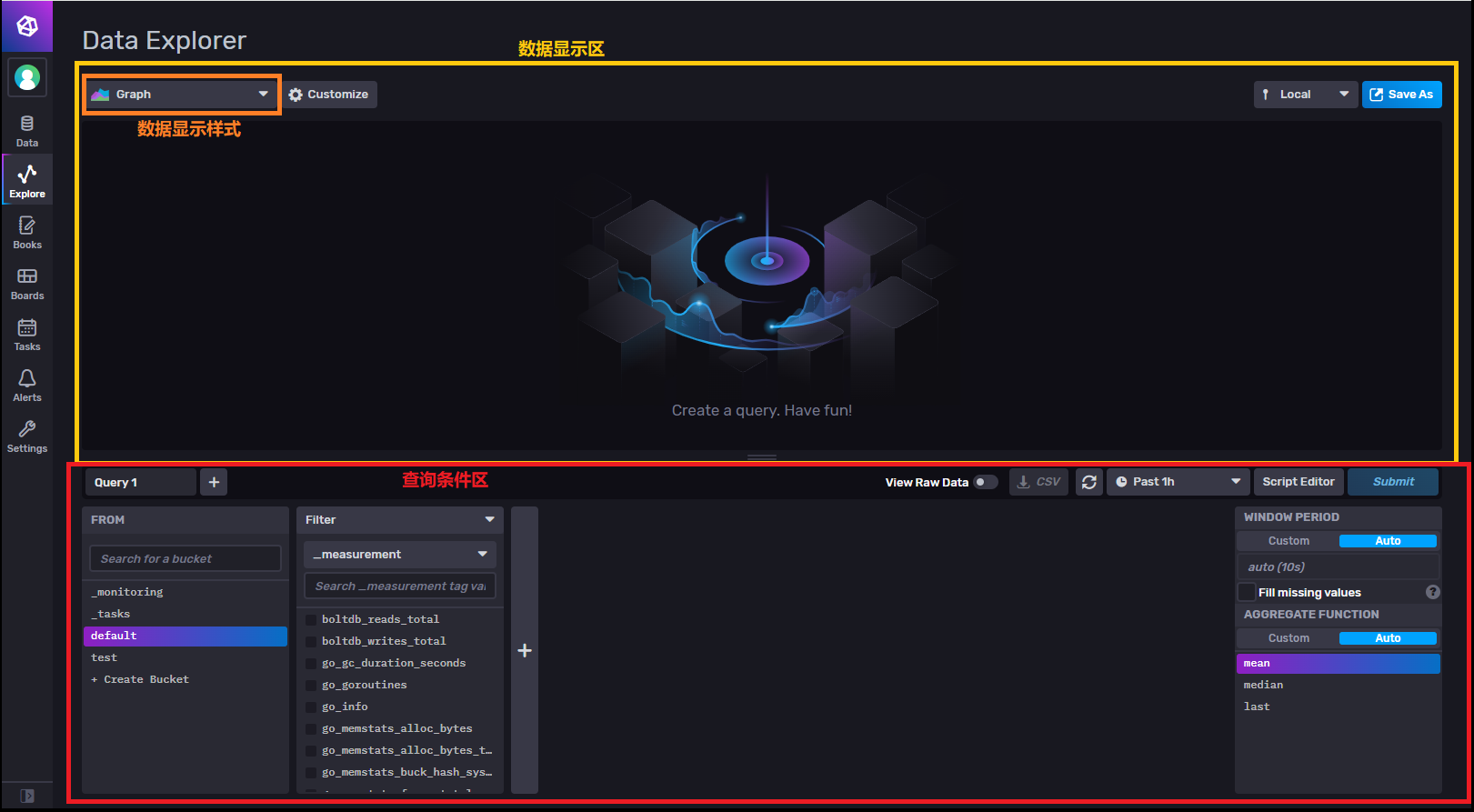

示例查询
一键查看原数据
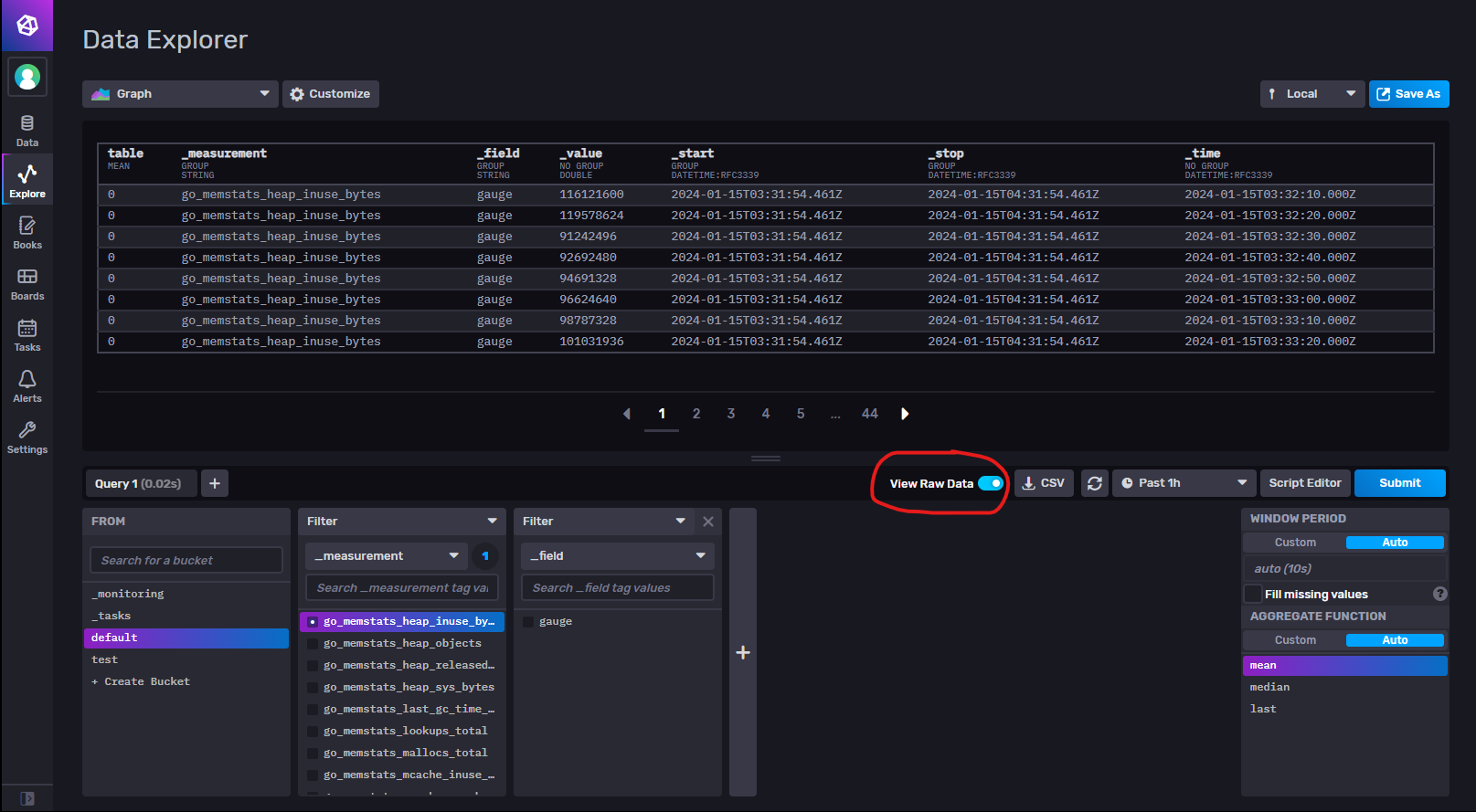
生成定时任务
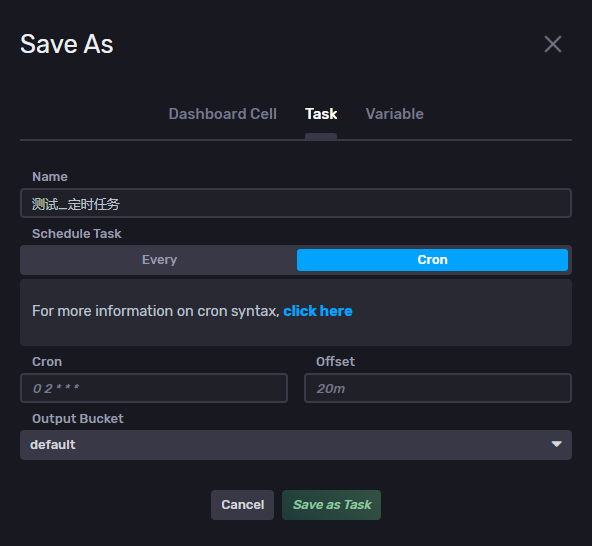
点击右上角 Save As 按钮,选择Task可以将当前查询操作保存为定时任务,TASK其实是FLUX语言写的一个定时执行脚本。因为FLUX是一个脚本语言,所以它其实有一定的IO能力。可以使用http与外面的系统进行通信,还可以将计算完的数据回写给InfluxDB。所以通常TASK有两种使用场景:
( 1 )数据检查与报警。对查询后的结果进行一下条件判断,如果不合规,就使用http向外通知报警。
( 2 )聚合操作。在InfluxDB里开窗完成聚合计算,计算后的数据再写回到InfluxDB,这样下游 BI(数据看板)可以直接去查询聚合后的数据了,而不是每次都把数据从InfluxDB里拉出来重新计算。这样可以减少IO,不过会增加InfluxDB的压力;生产环境下需要根据实际情况进行取舍。
Notebooks(工作流处理)
操作页面
个人理解:每个新建的NoteBook都可以理解为一个工作流程,例如:先查询符合条件1的数据,然后清洗出这批数据的某几个时间点的数据,最后将数据存入某个策略桶内;如果我们只是通过前面的功能操作的话,首先需要查符合条件1的数据,然后将这批记录下来,然后根据需要的某几个时间点数据进行多次查询并记录,最后将整合的数据文件导入到指定策略桶内;这样就很繁琐和麻烦,NoteBook则提供了一套工作流程的操作,通过在工作流程内设置每一步的操作构成整体的流程,只需要运行此流程就可以得到需要的结果。
如下示例
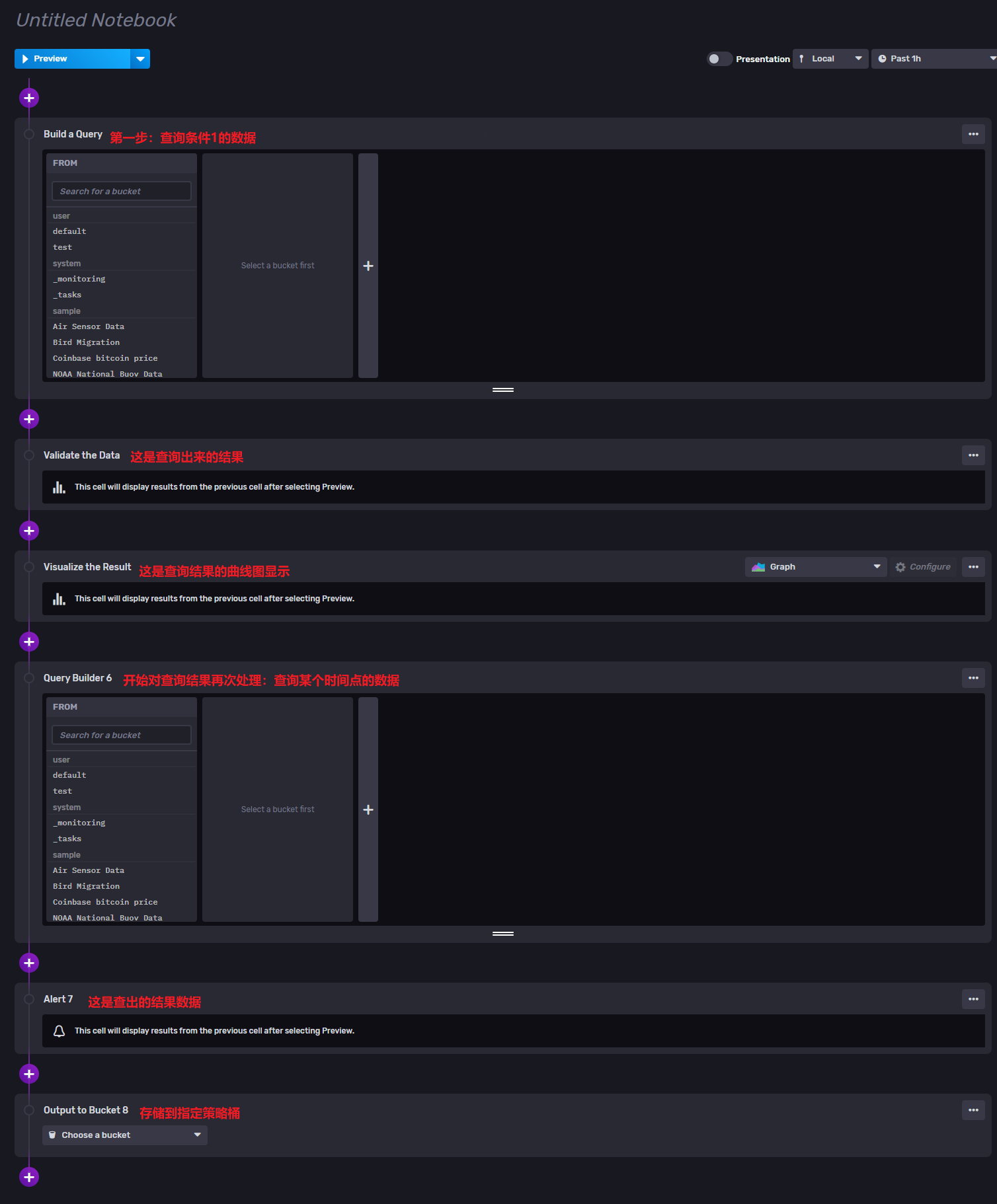
点击运行后会自动保存
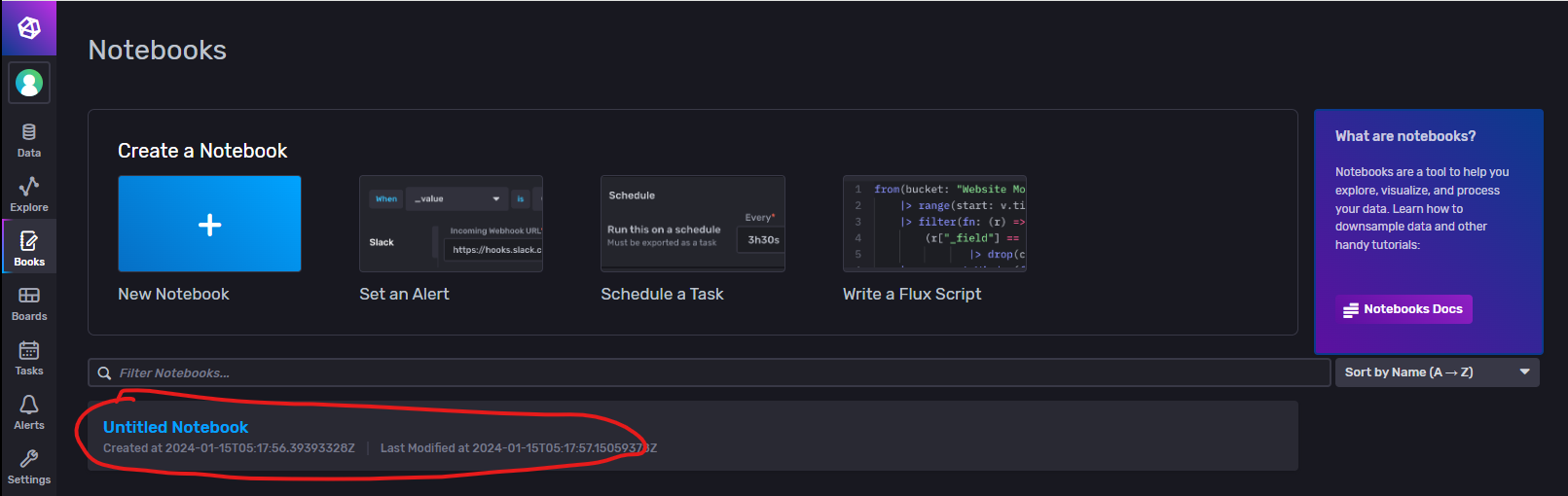
工作流就类似将我们每一步的操作具现化,我们根据自己的工作流程创建自己的工作流,后续就可以直接执行创建的工作流记录即可。
Tasks(定时任务管理)
操作页面
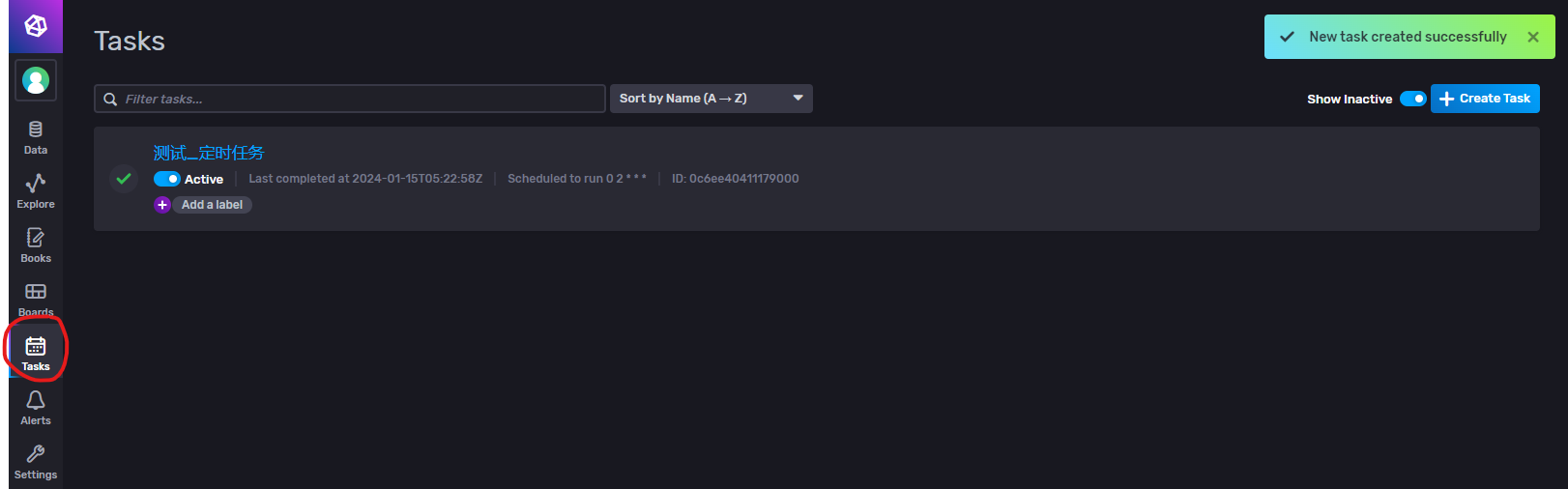
我们操作 数据查询 时,创建了一个定时任务,此时就可以在Tasks界面查看定时任务信息。
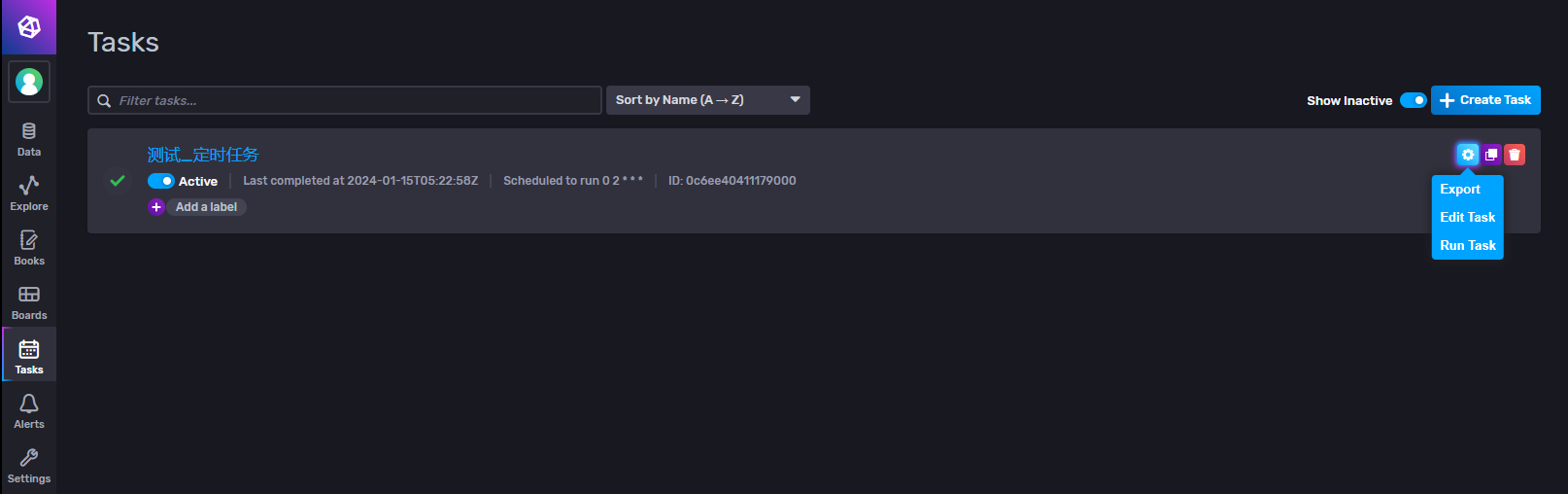
我们也可以对定时任务做修改、删除、运行任务等操作。
文章整合至:https://blog.csdn.net/qq_38263083/article/details/131913120

 浙公网安备 33010602011771号
浙公网安备 33010602011771号