Kafka:大白话讲解 kafka 架构原理 ( 转载 )
前言
本文转载至 https://blog.csdn.net/yuanlong122716/article/details/104825604
大家可以多多关注此文章博主,此博主发布的文章质量都很不错,本文只是抄录一份方便自己学习。
一、kafka简介
Kafka最初由Linkedin公司开发,是一个分布式的、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志、消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
二、kafka的特性
- 高吞吐量、低延迟: kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性: kafka集群支持热扩展;
- 持久性、可靠性: 消息被持久化到本地磁盘,并且支持数据备份防止丢失;
- 容错性: 允许集群中的节点失败(若副本数量为n,则允许n-1个节点失败);
- 高并发: 单机可支持数千个客户端同时读写;
三、kafka的应用场景
- 日志收集: 一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口开放给各种消费端,例如hadoop、Hbase、Solr等。
- 消息系统: 解耦生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索记录、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标: Kafka也经常用来记录运营监控数据。
- 流式处理
四、kafka架构( 重点 )
先介绍下Kafka中非常重要的术语。下面是一个kafka架构图:
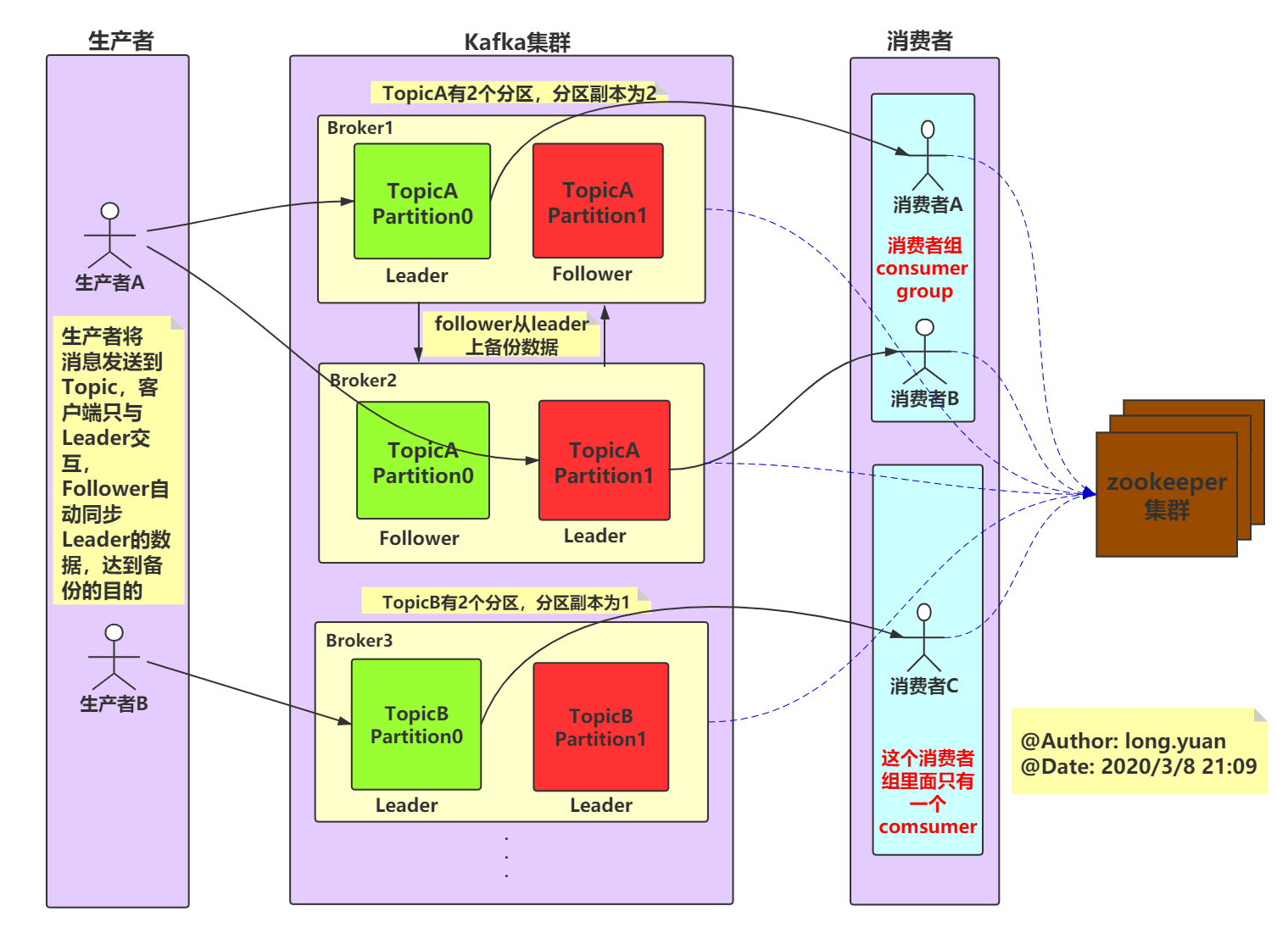
kafka架构中包含四大组件:生产者、消费者、kafka集群、zookeeper集群。
1、broker
kafka 集群包含一个或多个服务器,每个服务器节点称为一个broker。
2、topic
每条发布到kafka集群的消息都有一个类别,这个类别称为topic,其实就是将消息按照topic来分类,topic是逻辑上的分类,同一个topic的数据既可以在同一个broker上也可以在不同的broker结点上。
3、partition
分区,每个topic被物理划分为一个或多个分区,每个分区在物理上对应一个文件夹,该文件夹里面存储了这个分区的所有消息和索引文件。在创建topic时可指定parition数量,生产者将消息发送到topic时,消息会根据 分区策略 追加到分区文件的末尾,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
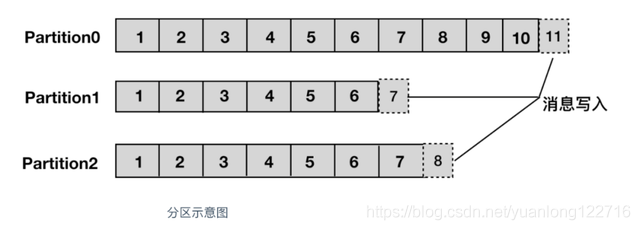
上面提到了分区策略,所谓分区策略就是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。kafka允许为每条消息设置一个key,一旦消息被定义了 Key,那么就可以保证同一个 Key 的所有消息都进入到相同的分区,这种策略属于自定义策略的一种,被称作"按消息key保存策略",或Key-ordering 策略。
同一topic的多个分区可以部署在多个机器上,以此来实现 kafka 的伸缩性。同一partition中的数据是有序的,但topic下的多个partition之间在消费数据时不能保证有序性,在需要严格保证消息顺序消费的场景下,可以将partition数设为1,但这种做法的缺点是降低了吞吐,一般来说,只需要保证每个分区的有序性,再对消息设置key来保证相同key的消息落入同一分区,就可以满足绝大多数的应用。
4、offset
partition中的每条消息都被标记了一个序号,这个序号表示消息在partition中的偏移量,称为offset,每一条消息在partition都有唯一的offset,消息者通过指定offset来指定要消费的消息。
正常情况下,消费者在消费完一条消息后会递增offset,准备去消费下一条消息,但也可以将offset设成一个较小的值,重新消费一些消费过的消息,可见offset是由consumer控制的,consumer想消费哪一条消息就消费哪一条消息,所以kafka broker是无状态的,它不需要标记哪些消息被消费过。
5、producer
生产者,生产者发送消息到指定的topic下,消息再根据分配规则append到某个partition的末尾。
6、consumer
消费者,消费者从topic中消费数据。
7、consumer group
消费组,每个consumer属于一个特定的consumer group,可以通过consumer.propertise文件中的group.id属性指定,如果不指定,默认是"test-consumer-group"。
一个consumer可以消费多个partition,但是同一个partition只能被同一个consumer group里面的一个consumer消费。一个consumer占用该partition的消费后,本消费组中的其他消费者将不能再消费,但其他消费组的消费者仍然可以消费。
这也是kafka用来实现消息的广播和单播的手段,如果需要实现广播,一个consumer group内只放一个消费者即可,要实现单播,将所有的消费者放到同一个consumer group即可。
8、leader
每个partition有多个副本,其中有且仅有一个作为leader,leader会负责所有的客户端读写操作。
9、follower
follower不对外提供服务,只与leader保持数据同步,如果leader失效,则选举一个follower来充当新的leader。当follower与leader挂掉、卡住或者同步太慢,leader会把这个follower从ISR列表中删除,重新创建一个follower。
解释一下ISR:简单来说,分区的所有副本(这里所说的副本包括leader和follower)统称为 AR (Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成 ISR (In Sync Replicas)。生产者发送消息时,消息会先发送到leader副本,然后follower副本才能从leader中拉取消息进行同步,同步期间,follow副本相对于leader副本而言会有一定程度的滞后,前面所说的"一定程度同步"就是指可忍受的滞后范围,这个范围可以通过参数进行配置。于leader副本同步滞后过多的副本(不包括leader副本)将组成 OSR (Out-of-Sync Replied)。
由此可见,AR = ISR + OSR,理想情况下,所有的follower副本都应该与leader 副本保持一定程度的同步,即AR=ISR,OSR集合为空。
10、rebalance
同一个consumer group下的多个消费者互相协调消费工作,我们这样想,一个topic分为多个分区,一个consumer group里面的所有消费者合作,一起去消费所订阅的某个topic下的所有分区(每个消费者消费部分分区),kafka会将该topic下的所有分区均匀的分配给consumer group下的每个消费者,如下图,
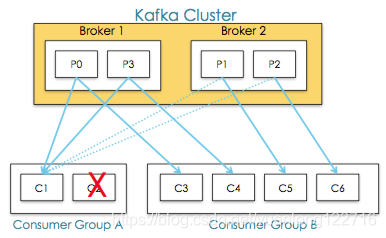
Rebalance表示"重平衡",consumer group内某个消费者挂掉后,其他消费者自动重新分配订阅主题分区的过程,是 Kafka 消费者端实现高可用的重要手段。如下图Consumer Group A中的C2挂掉,C1会接收P1和P2,以达到重新平衡。同样的,当有新消费者加入consumer group,也会触发重平衡操作。
五、对kafka架构的几点解释
1、一个典型的kafka集群中包含若干producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干consumer group,以及一个zookeeper集群。kafka通过zookeeper协调管理kafka集群,选举分区leader,以及在consumer group发生变化时进行rebalance。
2、kafka的topic被划分为一个或多个分区,多个分区可以分布在一个或多个broker节点上,同时为了故障容错,每个分区都会复制多个副本,分别位于不同的broker节点,这些分区副本中(不管是leader还是follower都称为分区副本),一个分区副本会作为leader,其余的分区副本作为follower。
leader负责所有的客户端读写操作,follower不对外提供服务,仅仅从leader上同步数据,当leader出现故障时,其中的一个follower会顶替成为leader,继续对外提供服务。
3、对于传统的MQ而言,已经被消费的消息会从队列中删除,但在Kafka中被消费的消息也不会立马删除,在kafka的server.propertise配置文件中定义了数据的保存时间,当文件到设定的保存时间时才会删除。
# 数据的保存时间(单位:小时,默认为7天) log.retention.hours=168
因为Kafka读取消息的时间复杂度为O(1),与文件大小无关,所以这里删除过期文件与提高Kafka性能并没有关系,所以选择怎样的删除策略应该考虑磁盘以及具体的需求。
4、点对点模式 VS 发布订阅模式
传统的消息系统中,有两种主要的消息传递模式:点对点模式、发布订阅模式。
①点对点模式
生产者发送消息到queue中,queue支持存在多个消费者,但是对一个消息而言,只可以被一个消费者消费,并且在点对点模式中,已经消费过的消息会从queue中删除不再存储。
②发布订阅模式
生产者将消息发布到topic中,topic可以被多个消费者订阅,且发布到topic的消息会被所有订阅者消费。而kafka就是一种发布订阅模式。
5、消费端 PULL和PUSH
①Push方式:由消息中间件主动地将消息推送给消费者;
②Pull方式:由消费者主动向消息中间件拉取消息;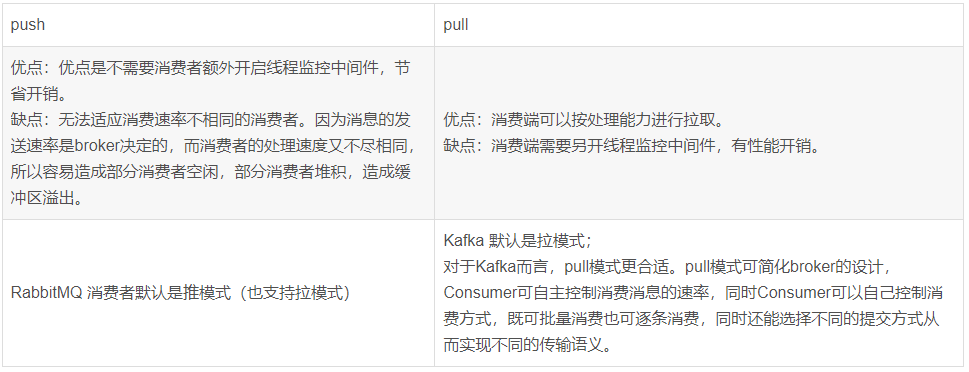
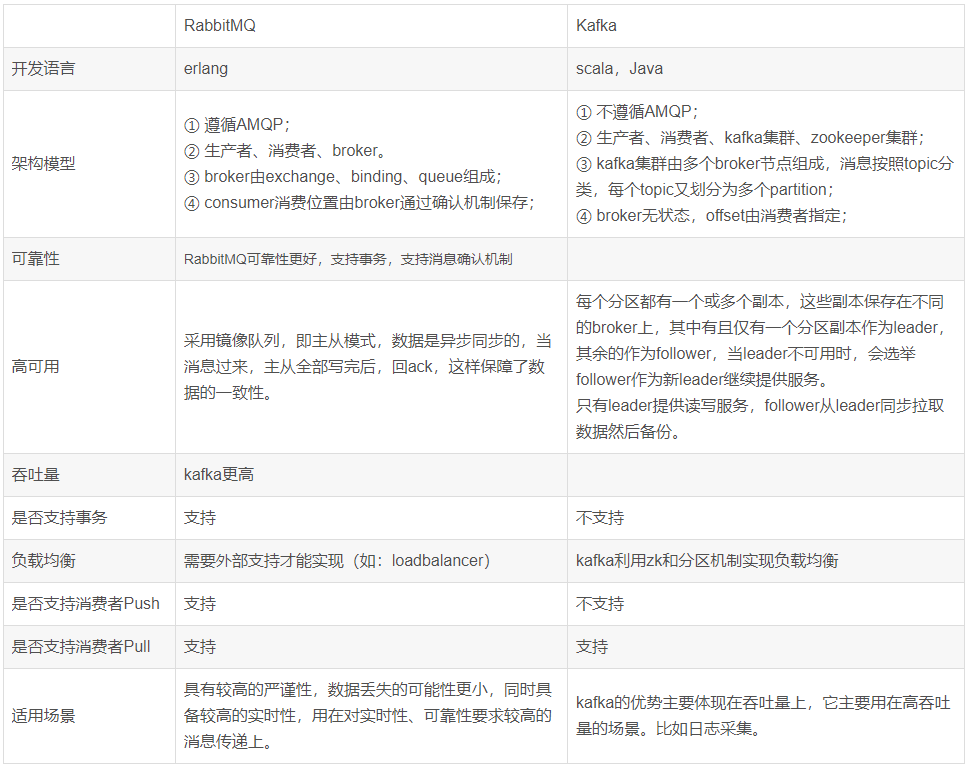
六、kafka和rabbitMQ对比
七、kafka的吞吐量为什么这么高?
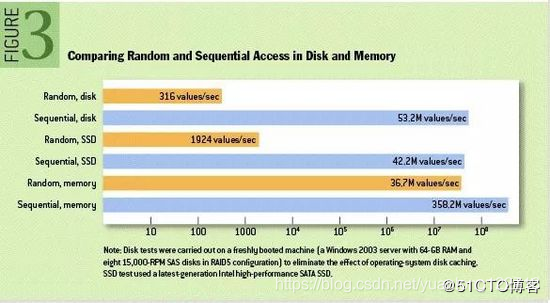
1、顺序读写磁盘
Kafka是将消息持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能提出质疑。实际上不管是内存还是磁盘,快或慢的关键在于寻址方式,磁盘分为顺序读写与随机读写,内存一样也分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但基于磁盘的顺序读写性能却很高,一般而言要高出磁盘的随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写,这里给出著名学术期刊 ACM Queue 上的一张性能对比图:
2、page cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做是因为,
> JVM中一切皆对象,对象的存储会带来额外的内存消耗;
> 使用JVM会受到GC的影响,随着数据的增多,垃圾回收也会变得复杂与缓慢,降低吞吐量;
另外操作系统本身对page cache做了大量优化,通过操作系统的Page Cache,Kafka的读写操作基本上是基于系统内存的,读写性能也得到了极大的提升。
3、零拷贝
零拷贝是指Kafka利用 linux 操作系统的 "zero-copy" 机制在消费端做的优化。首先来看一下消费端在消费数据时,数据从broker磁盘通过网络传输到消费端的整个过程:
> 操作系统从磁盘读取数据到内核空间(kernel space)的page cache;
> 应用程序读取page cache的数据到用户空间(user space)的缓冲区;
> 应用程序将用户空间缓冲区的数据写回内核空间的socket缓冲区(socket buffer);
> 操作系统将数据从socket缓冲区复制到硬件(如网卡)缓冲区;
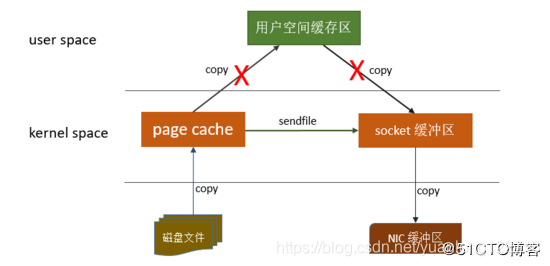
整个过程如上图所示,这个过程包含4次copy操作和2次系统上下文切换,而上下文切换是CPU密集型的工作,数据拷贝是I/O密集型的工作,性能其实非常低效。零拷贝就是使用了一个名为sendfile()的系统调用方法,将数据从page cache直接发送到Socket缓冲区,避免了系统上下文的切换,消除了从内核空间到用户空间的来回复制。从上图可以看出,"零拷贝"并不是说整个过程完全不发生拷贝,而是站在内核的角度来说的,避免了内核空间到用户空间的来回拷贝。
4、分区分段
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。
总之,Kafka采用顺序读写、Page Cache、零拷贝以及分区分段等这些设计,再加上在索引方面做的优化,另外Kafka数据读写也是批量的而不是单条的,使得Kafka具有了高性能、高吞吐、低延时的特点。
文章转载至:https://blog.csdn.net/yuanlong122716/article/details/104825604

 浙公网安备 33010602011771号
浙公网安备 33010602011771号