
hadoop/hbase/hive单机扩增slave
原来只有一台机器,hadoop,hbase,hive都安装在一台机器上,现在又申请到一台机器,领导说做成主备,
要重新配置吗?还是原来的不动,把新增的机器做成slave,原来的当作master?网上找找应该有这种配置操作,先试试看
原来搭单机hadoop,单机hadoop搭建
原来搭建单机hbase,单机hbase搭建
原来搭建单机zookeeper三个节点,单机伪zookeeper集群
1.申请到机器了,先把主机名改成slave
vim /etc/sysconfig/network
HOSTNAME=slave
2.添加2台机器信任关系
1),进入master机器的/root/.ssh目录,
检查该目录下是否有id_rsa和id_rsa.pub文件,
如果没有,执行ssh-keygen -t rsa 命令,生成私钥和公钥。
2)在主机master中添加自己的私钥:ssh-add id_rsa
注:很多介绍中都少了第二步,所以经常出现测试时不通过的情形。
ssh-add id_rsa
# 如果提示 could not open a connection to your authentication agent
终端做如下操作:
ssh-agent bash
ssh-add id_rsa
3)将主机master中的公钥id_rsa.pub拷贝到主机slave的.ssh目录下,authorized_keys文件中。
scp -r /root/.ssh/id_rsa.pub 192.168.1.197:/root/.ssh/authorized_keys
4)将主机slave 中的authorized_keys改为只有当前用户有读写权限:chmod 600 authorized_keys
5)在master中登录slave
>ssh 192.168.1.197 果然不需要密码直接登录了
将id_rsa.pub加入到授权的key中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
就可以自己登录自己了:
> ssh master
6)在slave机器中生成私钥和公钥
进入slave机器的/root/.ssh目录,
检查该目录下是否有id_rsa和id_rsa.pub文件,
如果没有,执行ssh-keygen -t rsa 命令,生成私钥和公钥
7)在主机slave中添加自己的私钥:ssh-add id_rsa
注:很多介绍中都少了第二步,所以经常出现测试时不通过的情形。
ssh-add id_rsa
# 如果提示 could not open a connection to your authentication agent
终端做如下操作:
ssh-agent bash
ssh-add id_rsa
8)将主机slave中的公钥id_rsa.pub拷贝到主机master的.ssh目录下,authorized_keys文件中。
scp -r /root/.ssh/id_rsa.pub 192.168.1.166:/root/.ssh/authorized_keys
9)在slave主机上登录master
>ssh 192.168.1.166 果然不需要密码
3.将master上安装配置的hadoop拷贝到slave上一份
scp -r /hadoop root@ 192.168.1.197:/
修改slave:/hadoop/hadoop-2.8.4/etc/hadoop中相关配置文件
1)hadoop-env.sh 不改
2)yarn-env.sh 不改
3)修改 core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>hadoop tmp dir</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://slave:9000</value>
</property>
</configuration>
4)hdfs-site.xml 不改,但要创建
/root/hadoop/dfs/name
/root/hadoop/dfs/data
目录
5)修改mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>slave:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6)修改slaves
>vi slaves
master slave
4.master和slave配置
在master和slave上都配置hosts
>vi /etc/hosts 内容如下
192.168.1.166 master 192.168.1.197 slave
发现slave机器上的java版本跟master不同,把master上安装的java拷贝到slave上,配置下环境变量就OK
5.hadoop集群如何启动?
进入master:/hadoop/hadoop-2.8.4/sbin目录
>start-dfs.sh 启动HDFS 因为之前已经格式化了,不用再格式化
此命令会启动(master)本机上namenode 、datanode、secondarynamenode 和slave上的datanode
>start-yarn.sh 启动yarn集群 此命令会先启动本地(master)的resourcemanager,在远程到slave上启动nodemanager。
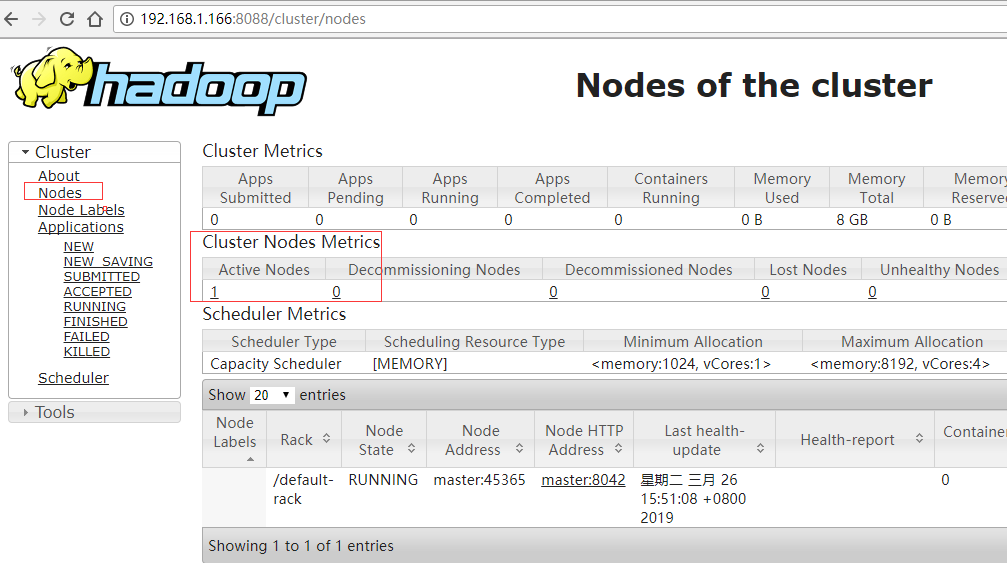
本以为启动成功了,浏览器访问,发现只有一个节点,是不是从节点slave没启动起来呢?
只能继续检查配置文件,一项项检查
1)hadoop-env.sh 不用改,只配置export JAVA_HOME
2)core-site.xml要修改,看错了,原来单机配置
单机配置:
<property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property>
集群配置:
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property>
对应的slave要修改成:
<property> <name>fs.defaultFS</name> <value>hdfs://slave:9000</value> </property>
3)hdfs-site.xml 不修改
4)mapred-site.xml 修改 master / slave 对应主机上修改下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>slave:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5)yarn-site.xml master / slave 对应主机上修改下:
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改完,在master上
> stop-dfs.sh 停止HDFS
>stop-yarn.sh 停止yarn
再启动
> start-dfs.sh 启动HDFS
>start-yarn.sh 停止yarn
访问浏览器,发现还是只有一个存活节点,难道又失败了?
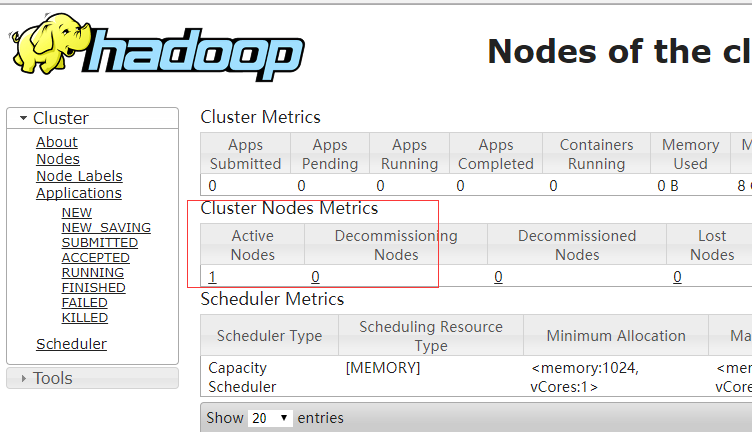
回头看了下启动日志:
start-dfs.sh 启动HDFS时,slave也启动了,并没有失败
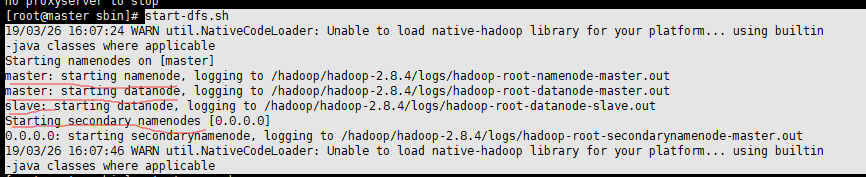
start-yarn.sh 启动yarn时,slave也启动了

为啥nodes节点只有一个呢?
查看master上进程:
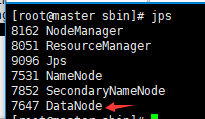
查看slave上进程:
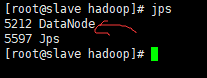
也有一个DataNode,为什么浏览器上只能看到一个节点呢?

