

Pandas——数据处理对象
Pandas中的数据结构
Series: 一维数组,类似于Python中的基本数据结构list,区别是Series只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。就像数据库中的列数据;DataFrame: 二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器;Panel:三维的数组,可以理解为DataFrame的容器。
Series是一个一维的类似的数组对象,包含一个数组的数据(任何NumPy的数据类型)和一个与数组关联的数据标签,被叫做索引 。最简单的Series是由一个数组的数据构成:
from pandas import Series,DataFrame import pandas as pd a = Series([1,4,7,9]) print(a)
运行结果:

Series的交互式显示的字符串表示形式是索引在左边,值在右边。因为我们没有给数据指定索引,一个包含整数0到N-1(这里N是数据的长度)的默认索引被创建。你可以分别的通过它的values和index属性来获取 Series的数组表示和索引对象:
from pandas import Series,DataFrame import pandas as pd a = Series([1,4,7,9]) #print(a) print(a.values) print(a.index)
运行结果:

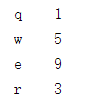
创建一个带有索引来确定每一个数据点的Series。
b = Series([1,5,9,3],index=['q','w','e','r']) print(b)
运行结果:
字典类型转换成Series,Series中的索引是排列后的字典的键。
data = {'湖北':"武汉","四川":"成都","湖南":"长沙"}
c = Series(data)
print(c)
运行结果:

DataFrame是一个表格型的数据结构,是以一个或多个二维块存放的数据表格(层次化索引),DataFrame既有行索引还有列索引,它有一组有序的列,每列既可以是不同类型(数值、字符串、布尔型)的数据,或者可以看做由Series组成的字典。
DataFrame创建:
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = DataFrame(dictionary)
print(frame)
结果:

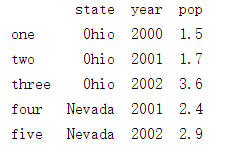
修改行名:
frame = DataFrame(dictionary,index=['one','two','three','four','five'])
结果:
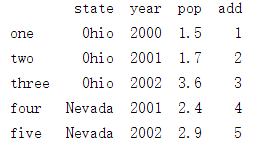
添加修改(等号左边是新加的列索引,右边是值,而且值的个数一定要和原来一样):
frame['add']=[1,2,3,4,5]
结果:
添加Series类型(Series中的索引名要和原来的相同):
frame=DataFrame(dictionary,index=['one','two','three','four','five']) # value = Series([1,3,1,4,6],index = [0,1,2,3,4])(这种会出错) # frame['add1'] = value value = Series([1,3,1,4,6],index=['one','two','three','four','five']) frame['add1'] = value print(frame)
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号