【大数据】Hadoop的伪分布式安装
这几天开始学习大数据,这离不开Hadoop这个Apache的经典项目。
由于Hadoop这个项目一般都是以集群方式运作,
自己学习却没有如此庞大的资源,
因此根据官网介绍,
我这里采用伪分布式集群进行安装,即单节点,多个进程扮演不同角色。
准备
虚拟机软件
VMware® Workstation 15 Pro(版本为15.0.0 build-10134415)
这里提供一个链接,自己自行操作下载哈,点我这个链接
Linux系统
CentOS 7 64位系统(这里提供下载地址)
Hadoop框架包
这里采用3.3.0版本(这里提供下载地址)
一些常用的FTP、SSH客户端
推荐采用FileZilla Client(FTP客户端)【下载地址】、MobaXterm(SSH客户端)【下载地址】
环境搭建
系统环境搭建
(1)安装Vmware软件,并进行破解,具体过程在给的链接中,这里不赘述。
(2)在Vmware中添加CentOS7系统,下图是我已经安装好的虚拟机界面,安装一个虚拟机就够,可以稍微将该虚拟机的配置调高一些,我给了内存为4G,存储为20G。
(3)将系统镜像源转换为国内,具体操作请见这篇文章
这里插个题外话,因为我们目前已经有了ssh工具以及ftp工具,因此,如果觉得虚拟机界面太丑,可以采用ssh的登陆方式,使用ftp工具向服务器拉取或推送文件,更加方便。具体如何使用,我这里不做赘述,如果不了解的小伙伴,可以下方留言,多了的话我会再写一篇博文普及一下。
(4)安装Java环境,使用如下命令
yum install -y java-1.8.0-openjdk-devel.x86_64
安装后,有如下提示证明安装成功

因为采用yum命令安装java后,会默认保存至/usr/lib/jvm/中,因此在配置环境变量的时候需要用到。
输入命令:
vim /etc/profile
在最后添加如下语句
#set java environment JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/ JRE_HOME=$JAVA_HOME/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH
退出vim编辑器后,输入命令:
source /etc/profile
(5)关闭centos7系统防火墙
systemctl stop firewalld #关闭防火墙服务网
systemctl disable firewalld #设置防火墙服务开机不启动
Hadoop环境搭建
(1)使用sftp程序将下载后的hadoop压缩文件上传至/root目录下,可新建一个文件叫hadoop_files,然后对该文件进行解压,命令如下:
mkdir /hadoop_files tar -zxvf hadoop-3.3.0.tar.gz -C /hadoop_files/
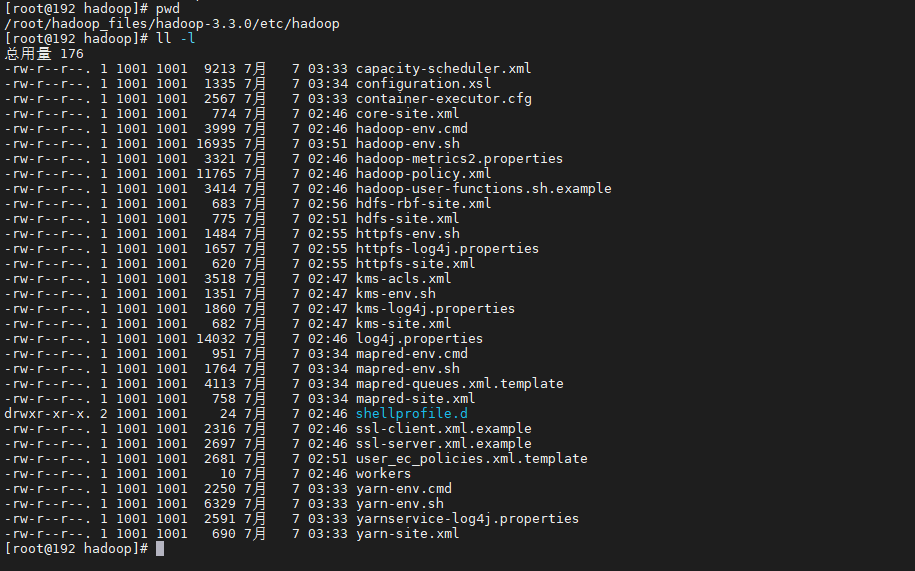
(2)进入解压后的文件,再进入/etc/hadoop的子目录,修改配置文件。
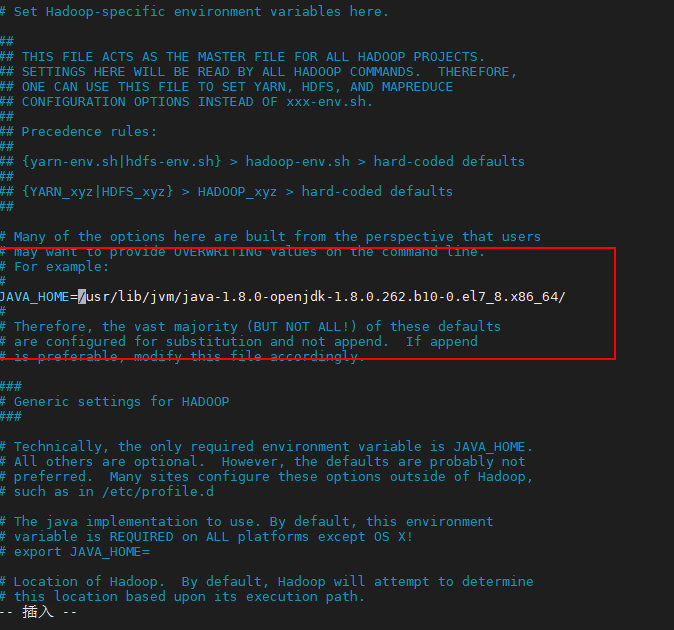
(3)找到hadoop-env.sh,该文件是Hadoop的环境变量配置文件,在该配置文件中指定JAVA_HOME的路径。
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/
(4)找到core-site.xml文件,具体配置信息如下(可参照官网对应版本配置)
<configuration>
<!-- 指定hdfs的nameservice的地址,端口为9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop存储数据的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop_files/hadoop-3.3.0/data</value>
</property>
</configuration>
(5)找到hdfs-site.xml文件,具体配置信息如下(可参照官网对应版本配置)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(6)找到mapred-site.xml文件,具体配置信息如下
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(7)找到yarn-site.xml文件,具体配置信息如下
<configuration>
<!-- 分别指定ResouceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- 分别指定MapReduce的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(8)将hadoop添加至系统环境变量中
vim /etc/profile
#打开文件后添加(之前已经添加了JAVA_HOME,因此不需要再次添加)
export HADOOP_HOME=/root/hadoop_files/hadoop-3.3.0/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source /etc/profile初始化Hadoop
执行命令,初始化HDFS系统
hdfs namenode -format
若见到下图,

执行命令,启动hadoop

出现错误的原因是Hadoop3.x不建议使用root用户启动HDFS,因为使用root启动HDFS会出现一系列隐患问题,如果就是想用root用户启动,需要在Hadoop的安装目录sbin的start-dfs.sh命令的最前面添加如下配置。
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
建议创建一个用户账户专门用于Hadoop
执行命令,创建普通用户用于hadoop生产
useradd hadoop passwd hadoop
切换用户并启动hadoop,并解决一些坑!
su hadoop start-dfs.sh
你可能会遇到

那是因为hadoop是放置在/root的目录下,普通用户无法访问。因此需要对/root目录以及有关hdfs目录的权限进行松绑,让普通用户hadoop能够访问。
切换至root用户,输入以下命令
su root chmod a+rx /root
chmod 777 /root/hadoop
然后切换回hadoop,重新启动即可。
然后,你可能会遇到如下情况
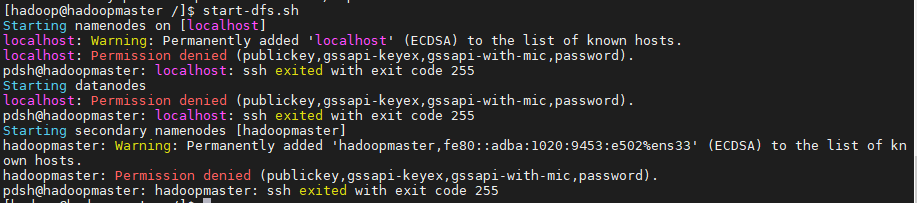
那是由于没有配置ssh免密钥登录。
执行命令,并连续敲击三个回车
ssh-keygen -t rsa
然后执行,并输入当前hadoop用户密码,完成SSH免密码登录配置
ssh-copy-id localhost
继续执行命令
start-dfs.sh
出现下图则说明安装完毕!

执行命令
jps
出现下图说明hdfs启动成功!

继续执行命令
start-yarn.sh
jps
出现下图说明yarn启动成功!

测试Hadoop环境
这里说明一下,Hadoop的2.x版本和3.x版本中,端口发生了变化,具体变化请看下图:


或者访问网址查看:https://blog.csdn.net/qq_31454379/article/details/105439752
首先查询虚拟机的ip地址
ip addr

在chrome浏览器上,输入192.168.206.128:9870,这是HDFS的管理界面
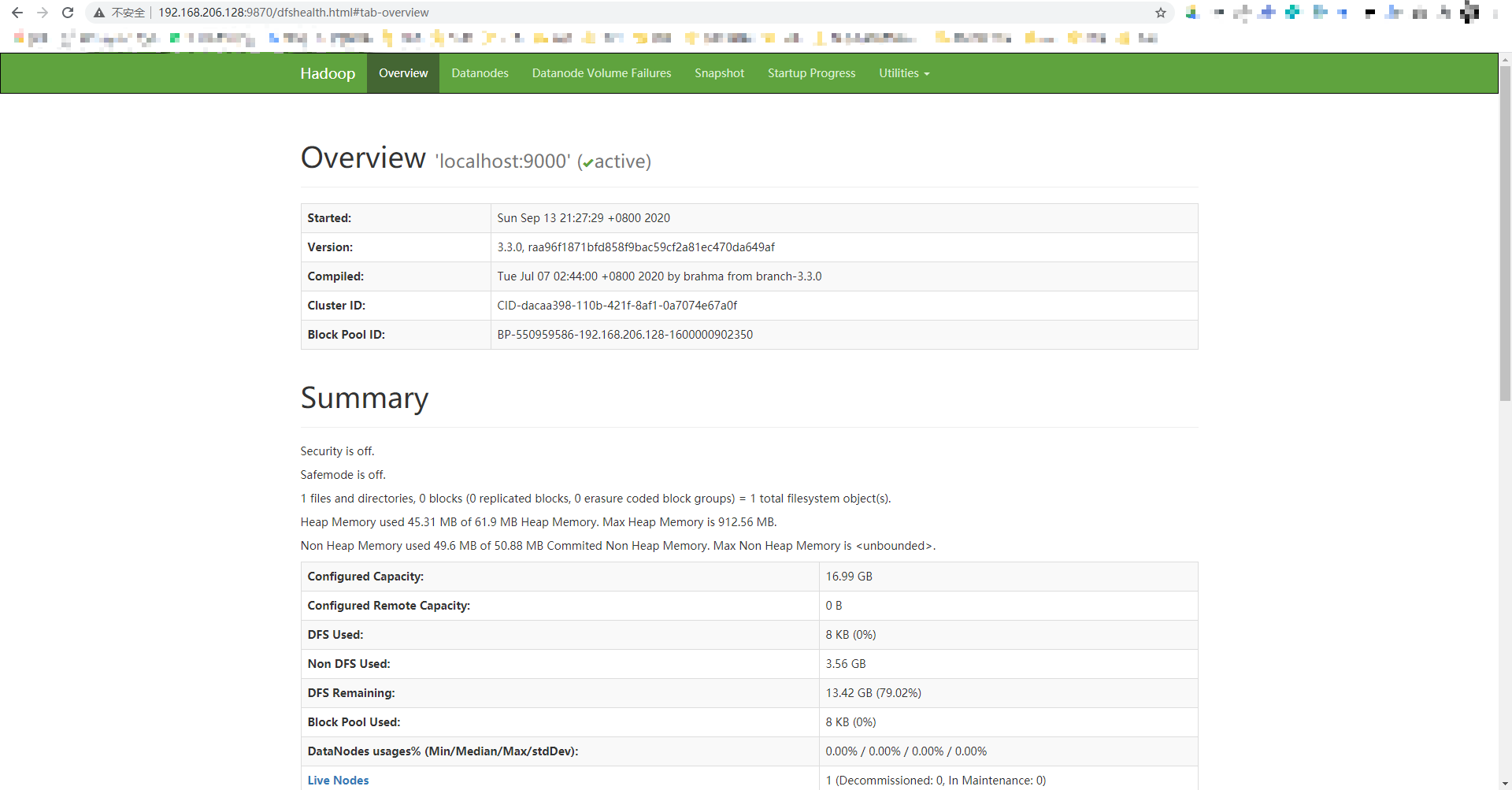
然后输入http://192.168.206.128:8088/
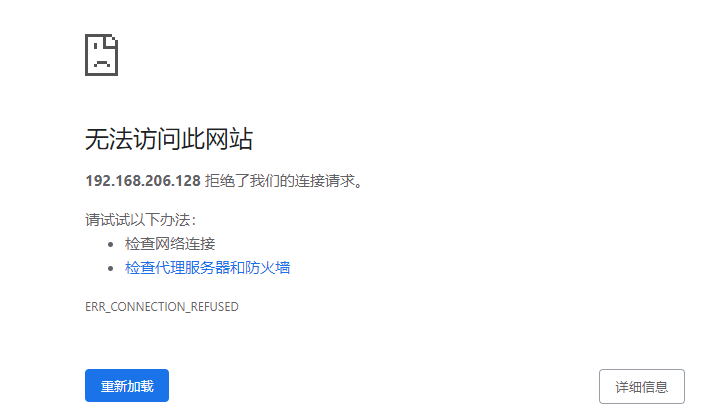
发现无法访问,我对此问题进行了排查,输入命令
netstat -nltp|grep 8088

继续输入命令
9870

发现问题!!!一个是0.0.0.0,一个是127.0.0.1!!!!
解决方案是进入hadoop安装目录下修改yarn的配置文件。
vim /root/hadoop_files/hadoop-3.3.0/etc/hadoop/yarn-site.xml
添加如下配置
<property> <name>yarn.resourcemanager.webapp.address</name> <value>0.0.0.0:8088</value> </property>
重新启动yarn
stop-yarn.sh start-yarn.sh
正常了

然后在chrome中输入http://192.168.206.128:8088,访问正常!
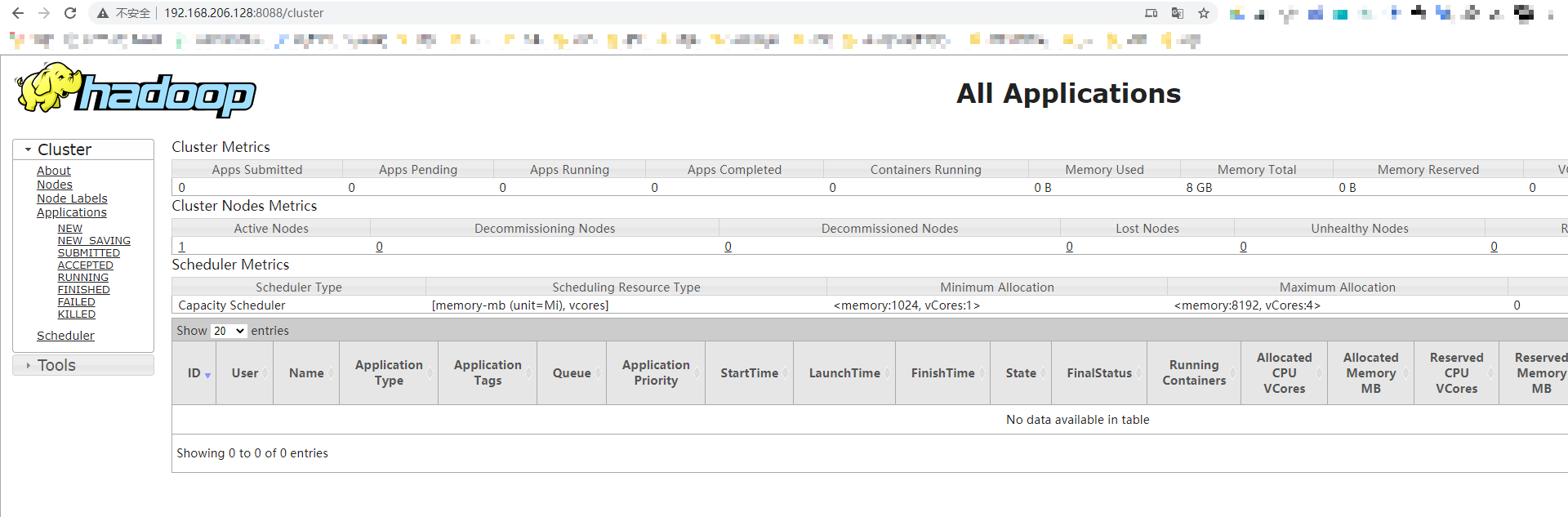
至此,一个伪分布式的Hadoop集群就安装完毕!!!!


