

MySQL进阶实战3,mysql索引详解,上篇
一、索引
索引是存储引擎用于快速查找记录的一种数据结构。我觉得数据库中最重要的知识点,就是索引。
存储引擎以不同的方式使用B-Tree索引,性能也各有不同,各有优劣。例如MyISAM使用前缀压缩技术使得索引更小,但InnoDB则按照原数据格式进行存储。MyISAM索引通过数据的物理位置引用被索引的行,而InnoDB则根据主键引用被索引的行。
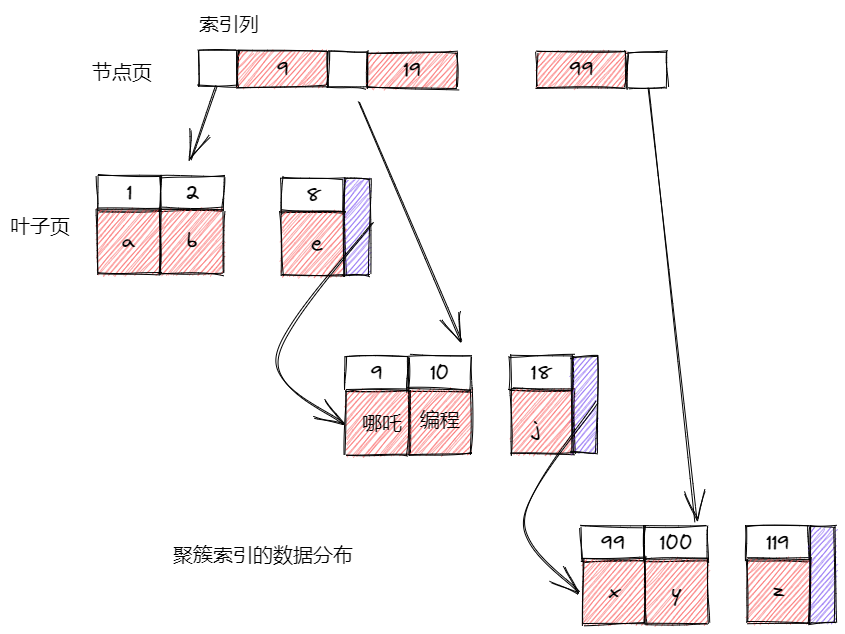
B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同。
B-Tree索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据,取而代之的是从索引的根结点开始进行搜索。根结点的槽中存放了指向子结点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。最终存储引擎要么找到对应的值,要么该记录不存在。
叶子节点比较特别,它们的指针指向的是被索引的数据,而不是其他的节点页。B-Tree对索引列是顺序组织存储的,所有很适合查找范围数据。B-Tree适用于全键值、键值范围或键前缀查找。
因为索引树中的节点是有序的,所以除了按值查找之外,索引还可以用于查询中的order by操作。一般来说,如果B-Tree可以按照某种方式查找到值,那么也可以按照这种方式用于排序。
二、索引的优点
- 索引大大减少了服务器需要扫描的数据量;
- 索引可以帮助服务器避免排序和临时表;
- 索引可以将随机IO变为顺序IO;
三、哈希索引
哈希索引是基于哈希表实现的,只有精确匹配索引所有列的查询才会生效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时哈希表中保存指向每个数据行的指针。
因为索引自身只需存储对应的哈希值,所以索引的结构十分紧凑,这也让哈希索引查找的速度非常快。
哈希索引的缺点:
- 哈希索引无法用于排序;
- 哈希索引不支持最左前缀原则;
- 哈希索引只支持等值比较,不支持范围查询,比如where salary > 5000;
InnoDB引擎有一个特殊的功能叫“自适应哈希索引”。当InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引之上再创建一个哈希索引,这就让B-Tree索引也具有哈希索引的一些优点。这是一个完全自动的、内部的行为,用户无法控制或配置。
四、哈希索引实例
如果一个表需要存储大量的URL,并需要根据URL进行搜索查找,如果使用B-Tree来存储URL,存储的内容就会很大,因为URL本身就很长,正常情况下会有如下查询:
select id,name from url where url = "http://www.baidu.com";
若删除原来URL列上的索引,而新增一个被索引的url-src列,使用SRC32做哈希,就可以使用下面的方式查询:
select id,name from url where url = "http://www.baidu.com" and url_crc = CRC32("http://www.baidu.com");
这样做的话,性能会提高很多,通过url_crc列进行哈希查找。
这样实现的缺点是需要维护哈希值,可以手动维护,也可以使用触发器实现。
五、前缀索引
1、独立的列
独立的列是指索引列不能是表达式的一部分,也不能是函数的参数,必须是等号前单独的列存在。
2、前缀索引和索引选择性
通常可以拿字符串开始的部分字符当索引,这样可以大大节约索引空间,从而提高索引效率。索引的选择性越高则查询效率越高,选择性高的索引可以让MySQL在查找时过滤掉更多的行。
一般情况下,对于blob、text、varchar类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。诀窍在于选择足够长的前缀以保证较高的索引选择性,同时又不能太长,最好使得前缀索引的选择性接近于索引整个列。
为了决定前缀的合适长度,需要找到最常见的值的列表,然后和最常见的前缀列表进行比较。
使用MySQL官方数据库提供的表:
CREATE TABLE city (
city_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
city VARCHAR(50) NOT NULL,
country_id SMALLINT UNSIGNED NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (city_id),
KEY idx_fk_country_id (country_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
用city列测试一下如何使用前缀索引。
3、通过sql获取city全列的索引选择性
select count(distinct city) / count(*) FROM city;
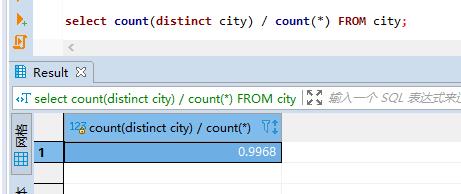
可以看到,结果为 0.9968,说明这一列的值是有重复的。
4、截取city列,获取合适的索引选择性
现在通过截取city列,来测试一下他们的索引选择性,使前缀的选择性接近于完整列的选择性就可以了。
SELECT
COUNT(DISTINCT LEFT(city,3))/COUNT(*) AS pref3,
COUNT(DISTINCT LEFT(city,5))/COUNT(*) AS pref5,
COUNT(DISTINCT LEFT(city,7))/COUNT(*) AS pref7,
COUNT(DISTINCT LEFT(city,9))/COUNT(*) AS pref9,
COUNT(DISTINCT LEFT(city,11))/COUNT(*) AS pref11,
COUNT(DISTINCT LEFT(city,13))/COUNT(*) AS pref13,
COUNT(DISTINCT LEFT(city,14))/COUNT(*) AS pref14,
COUNT(DISTINCT LEFT(city,15))/COUNT(*) AS pref15
FROM city;
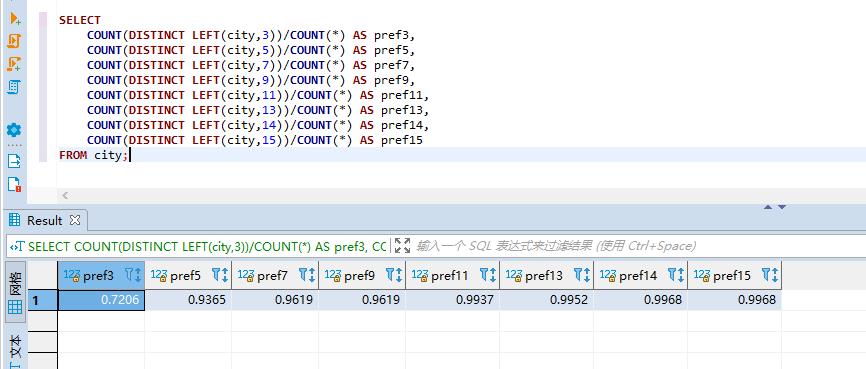
我觉得截取5个的时候就可以了,这个时候再增加前缀长度,选择性的提升已经不明显了。但是如果数据分布很不均匀,可能就会有问题,
5、通过sql测试一下
select count(1) as cnt,left(city,5) as pref from city group by pref order by cnt desc limit 5
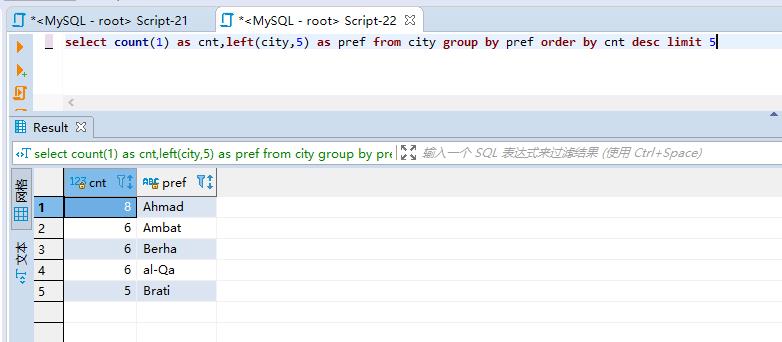
已经找到了合适的前缀长度,下面创建前缀索引:
alter table city add key city_idx(city(5));
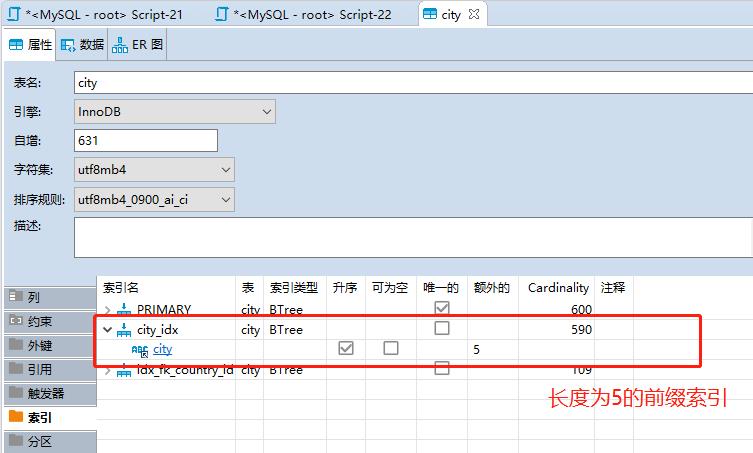
前缀索引是一种能使索引更小、更快的方式,但MySQL中无法使用前缀索引做order by 和group by ,也无法使用前缀索引做覆盖扫描。
6、测试一下是否可以触发索引
explain select city_id,city,last_update from city where city = 'dalian'

触发了city_idx索引。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署