



上一篇Tajo--一个分布式数据仓库系统(概述)废话了一通,下面介绍一下Tajo的体系结构、以及官方的实验成果吧
一、体系架构
Tajo采用了Master-Worker架构(下图虚线框目前还在计划中),Master-Worker-Client之间的RPC通信是使用Protocol buffer + Netty来实现的,具体如下:
(1) TajoMaster:为客户端提供查询服务和管理各个QueryMaster(也可以说是Tajo Worker),解析Query并协调QueryMaster,目前还内置了catalog服务器。大致可以分为四个组件:Cluster Manager、Catalog、Global Query Engine以及History Manager。
- Catalog 的工作是管理诸如tables、schemas、partitions,functions,indices及statistics等各种metadata。这些元数据信息一般都是Global Query Engine来操作,为了低延迟考虑跟hive一样都是存在RDBMS(目前支持Derby和MySQL),默认是保存在内置的Derby数据库中。后面可能会考虑使用hive的HCatalog来完成这块功能。
- Cluster Manager 主要是管理集群中各个节点之间的通信信息及资源(内存/CPU/Disk)信息,每个节点定期发送资源信息,交给Master来管理将用于查询计划的分配等,这一块是依赖Yarn的ResourceManager来管理。
- Global Query Engine 当一条query提交到master,GQE就会依据表的metadata以及集群资源信息(依赖于Catalog和Cluster Manager两个模块提供的信息)生成一个全局的查询计划。对于一个分布式执行环境,全局的查询计划将会被分片,划分成各个查询单元分配给各个worker去执行,在这些worker执行过程中GQE会监控每一个查询单元的运行状况并实时去优化和容错。在这一块目前的语法解析是用ANTLR 4生成AST(抽象语法树),这个以后可能会使用Tenzing的SQL Query Engine。
- History Manager 收集各个query job状态信息包括查询语句,划分的查询单元等,通过web ui(默认端口号:26080)可以查询。
(2) QueryMaster:负责一个query的解析、优化与执行,它参与多个task runner worker协同工作,完成一个query的计算。每个Query Master可以生成多个TaskRunner来执行master的查询单元,这些task runner都是由yarn中的NodeManager来管理。
(3) Tajo Worker 每个节点就是一个worker角色,每个worker包含存储模块管理和一个Local模式的Query Engine,这个local模式的Query Engine就是来接受master分配的查询单元。每个查询单元包含一个逻辑查询计划和一个分片(输入数据关系的信息块),在执行过程中worker定期向master汇报查询进度和资源信息,master可以很灵活地面对非异常的错误。
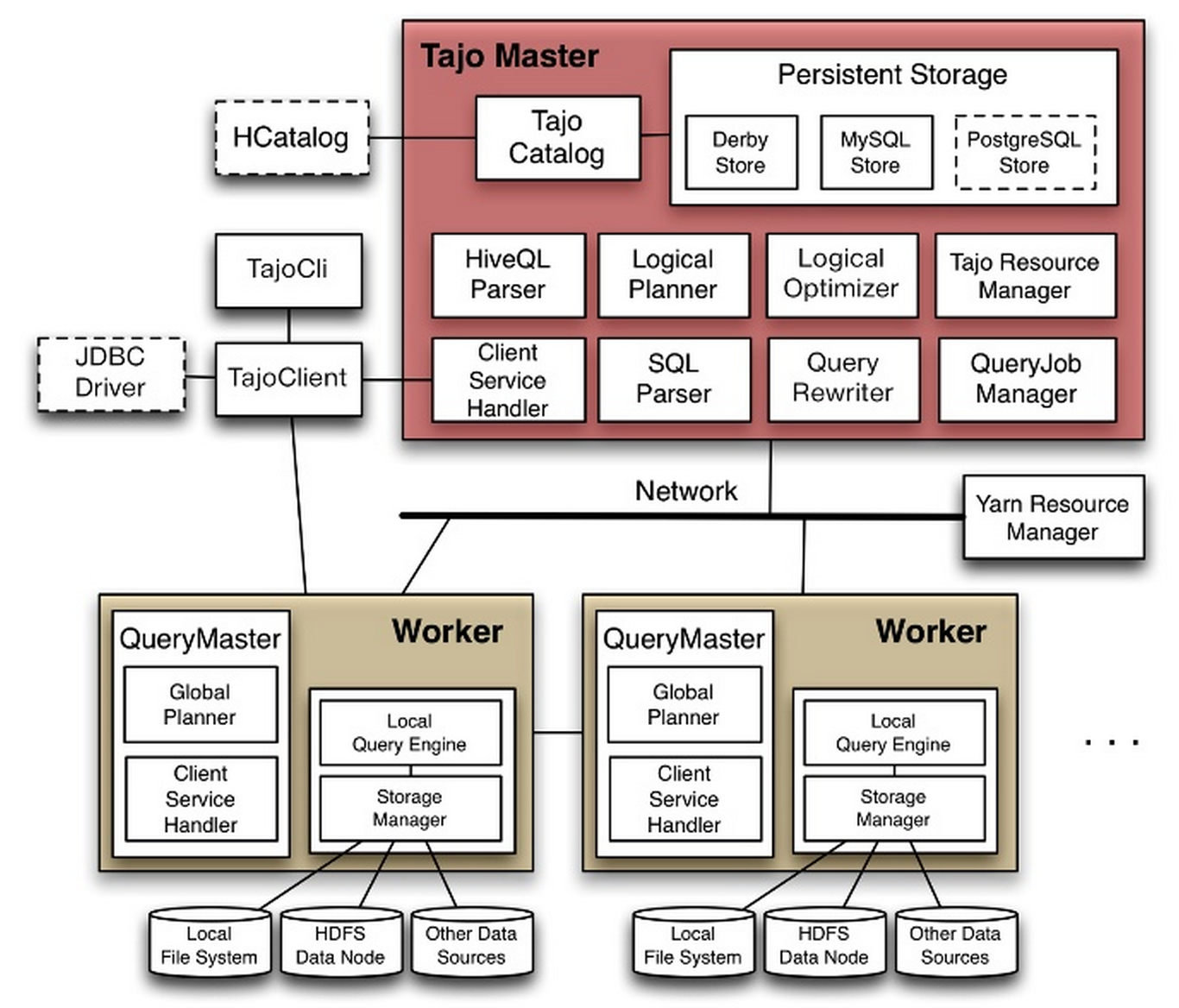
图 1 Tajo体系架构
如图1所示,Tajo采用传统数据库技术开发了SQL解析器,包括SQL解析、生成查询计划、优化查询计划、执行查询技术等。但与传统的数据库技术不同,Tajo最终执行查询技术时借鉴了MapReduce的设计思想,它将查询计划转化为一系列任务,这样,执行查询计划实际上就是执行这些任务,而每一个任务就是一个计算单位,同时Map Task和Reduce Task一样。
二、查询请求的处理
Tajo定义了一套类SQL的查询语言(Tajo Query Language TQL),支持大多数的DML,如:select, from, where, join, group-by, order-by, union, and cube。TQL支持可以用两种变量来表示Scala value(应该是一种内存对象)和Temporary table, 可以为它们赋值。这种特性,可以让用户很容易地处理复杂查询中间结果是生成Scala value还是临时表。处理流程和Tenzing都差不多,都是先生成查询计划,然后再分到各个worker上去执行,都省去了hive在map之后对生成的数据进行shuffle和sort的过程,而且对无需写文件的中间结果支持直接放内存中交给下一个流程去处理,这应该就是它性能高出hive的主要优化吧。
查询计划
将一个查询语句解析成若干个底层的物理执行计划有以下几个步骤,如下图所示。首先是Global Query Engine将语句转化成一个抽象语法树AST(使用Antlr 4实现)并且编译成一个逻辑计划。根据catalog中的信息,查询优化器使用基于cost的算法(贪婪方式)处理join找到一种最优的逻辑计划等同于原始的查询计划,同时使用基于规则的算法处理其他方式,最终会生成一种优化后的全局查询计划。下一步就是将全局查询计划划分成若干个查询单元提交到worker上去执行。

图 2查询转化流程图
执行查询
针对执行过程中的输入输出,Tajo提供了一系列的Scanners和Appenders。Scanner负责从HDFS或者本地读取数据,而Appender将数据写入HDFS或者本地磁盘。当前版本支持csv和基于行的二进制文件格式,系统设计的时候开放了Scanner和Appender接口,用户可以针对不同的文件格式自定义Scanner和Appender来应对不同的应用场景。
容错
Tajo的容错机制是与MapReduce中的容错类似,将失败的任务分配给其他的worker,也就是说,当master检测到一个查询单元失败了就会将该查询单元分配到其他的worker节点重新执行。与
三、官方实验结果
作者在一次官方的演讲中汇报了tajo-0.8 vs. Impala1.1.1 vs.hive0.10的比较结果。
实验说明
实验数据:TPC-H 数据集 100G
硬件设备:10G network、6 cluster nodes、each machine: Intel Xeon CPU E5 2640 2.5GHZ x 4,64G内存,6 SATA2 磁盘。
实验结果
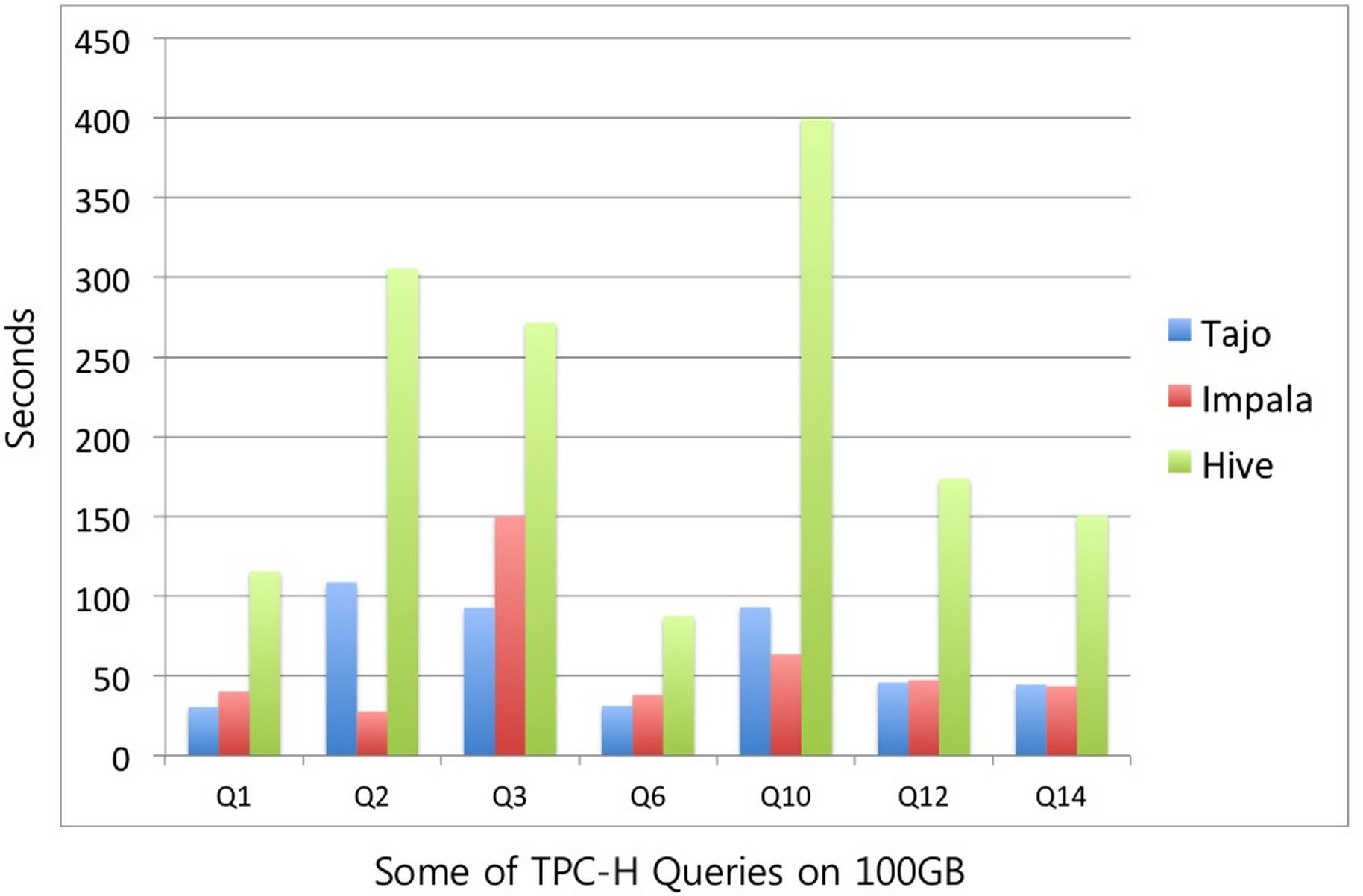
图 3 tajo vs. impala vs. hive结果对比图
四、目前存在的问题
下面介绍一下目前还存在哪些问题:
metric 系统
目前还没有metric系统,系统监控和状态信息还不能很好地收集
异常处理
对于错误处理机制还不够健全,一个query job挂了之后,中间的工作目录还有job都不能很好地退出。Master不能处理down的worker等等。
文档不健全
Java Api、系统使用文档、支持的SQL示例、代码压根就没有什么注释,也没有什么trouble shotting之类的,不过在jira上还是能及时得到回复的。
活跃度
目前社区活跃度太低,发展状况还是不错的,一直再更新,不断会有其他业余的加入。前景个人感觉还是良好的,是死是活还要看Tajo的造化了。
五、发展规划
根据官方文档和jira上总结了一下Tajo几个核心模块未来的发展规划(部分属于个人的一点点看法):
主目录服务
目前是tajo自开发的catalog管理服务器,分为catalog client和catalog server两个模块。目前支持Derby和MySQL数据存储,后续会支持对PostgresQL的支持。开发计划中会将Hive的HCatalog集成进来,来做Tajo的数据表和存储管理服务。
数据存储
Tajo目前是以hdfs作为主要存储模块,对于一个数据仓库系统来说,应该支持各种各样的存储数据源,下一个开发计划会支持HBase和其他的数据源。
查询引擎
Tajo自己开发的SQL执行引擎包括SQL解析成抽象语法树(AntLR 4)、生成执行计划、执行计划的优化器、代价评估等模块。目前支持绝大部分的SQL92的操作,以后会考虑Tenzing的实现方案,支持更多的数据源。
表partition
目前的版本没有对表做partition,后续会参照hive的方式对表进行分区分表。

