day_03:匿名函数、内置函数与匿名函数的应用、闭包函数、装饰器、装饰器应用




一:匿名函数的使用:
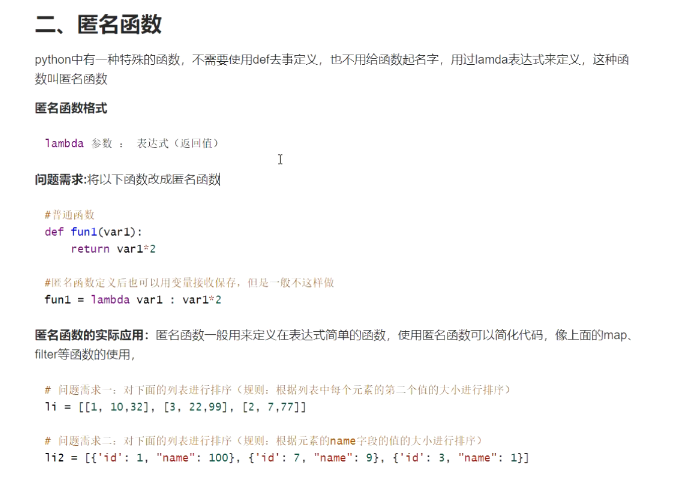
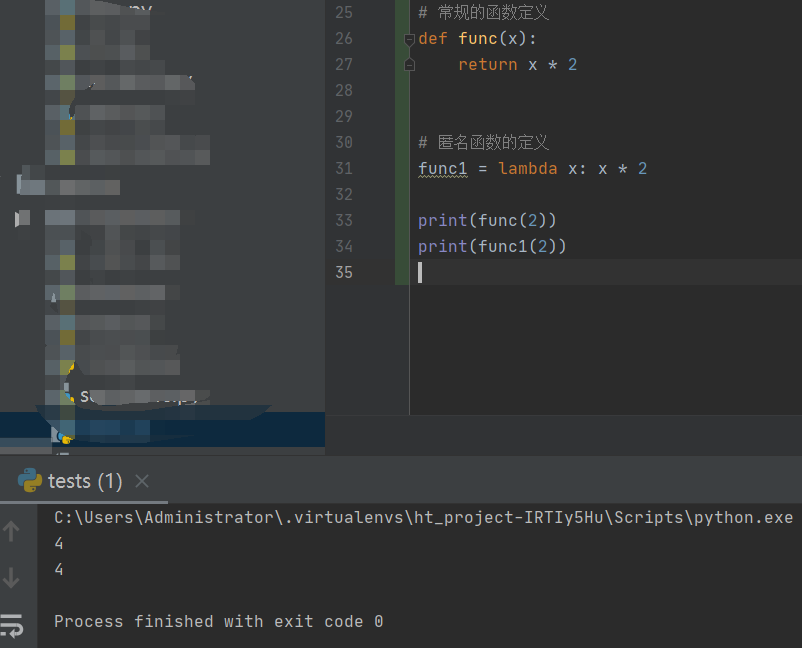
1)匿名函数的定义
# 常规的函数定义
def func(x):
return x * 2
# 匿名函数的定义
func1 = lambda x: x * 2
print(func(2))
print(func1(2))
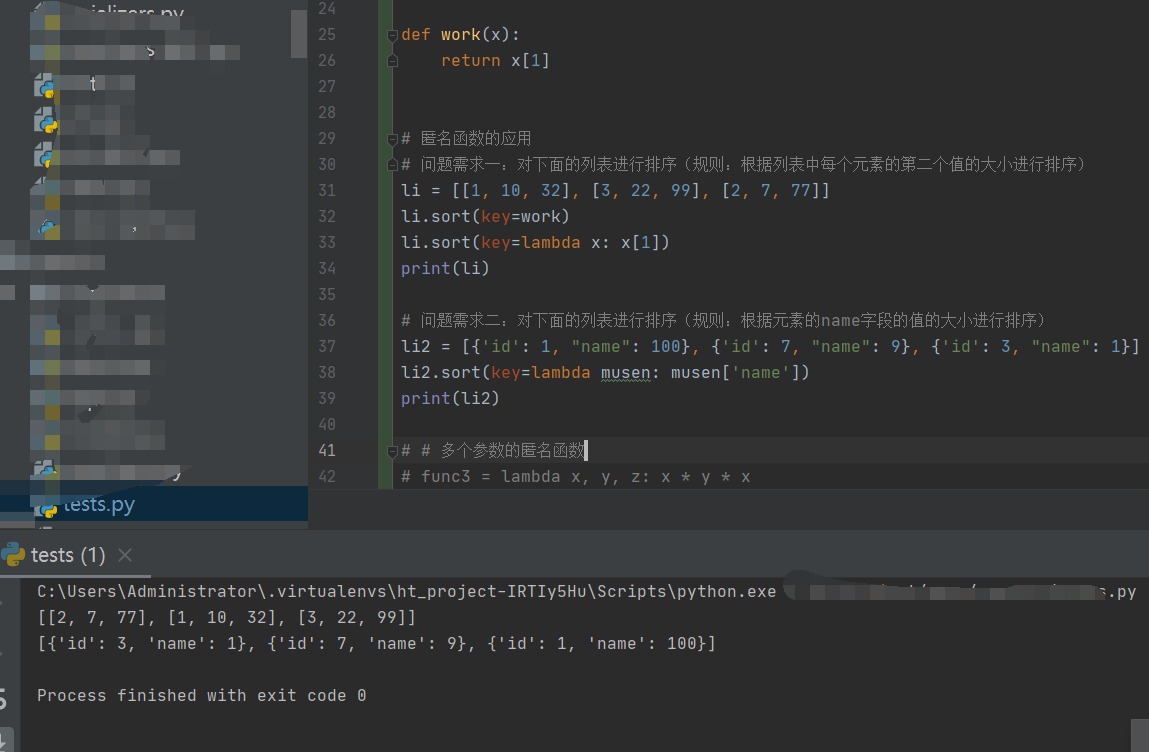
2)匿名函数的应用:
def work(x):
return x[1]
# 匿名函数的应用
# 问题需求一:对下面的列表进行排序(规则:根据列表中每个元素的第二个值的大小进行排序)
li = [[1, 10, 32], [3, 22, 99], [2, 7, 77]]
li.sort(key=work)
li.sort(key=lambda x: x[1])
# print(li)
# 问题需求二:对下面的列表进行排序(规则:根据元素的name字段的值的大小进行排序)
li2 = [{'id': 1, "name": 100}, {'id': 7, "name": 9}, {'id': 3, "name": 1}]
li2.sort(key=lambda musen: musen['name'])
# print(li2)
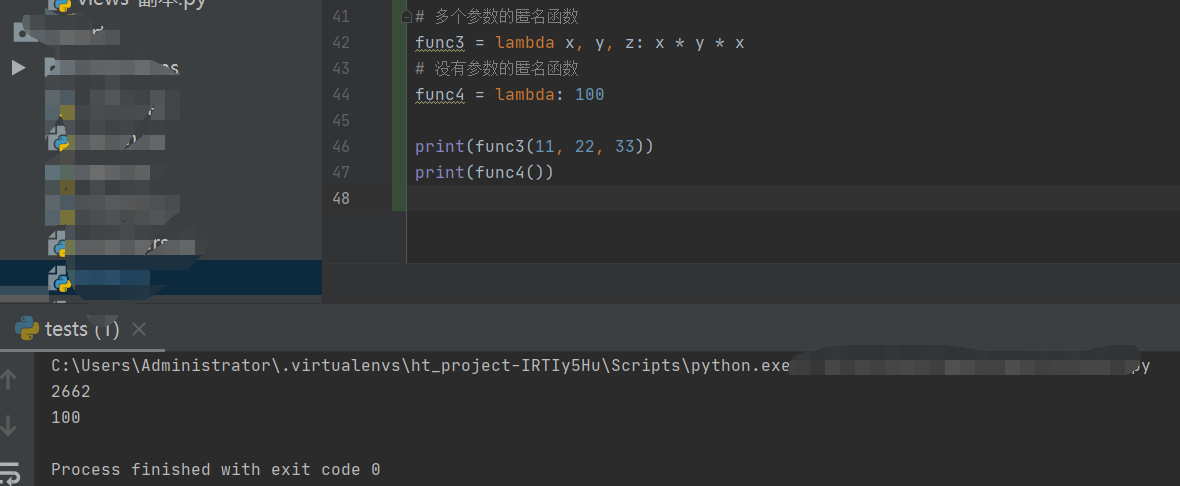
# 多个参数的匿名函数
func3 = lambda x, y, z: x * y * x
# 没有参数的匿名函数
func4 = lambda: 100
print(func3(11, 22, 33))
print(func4())
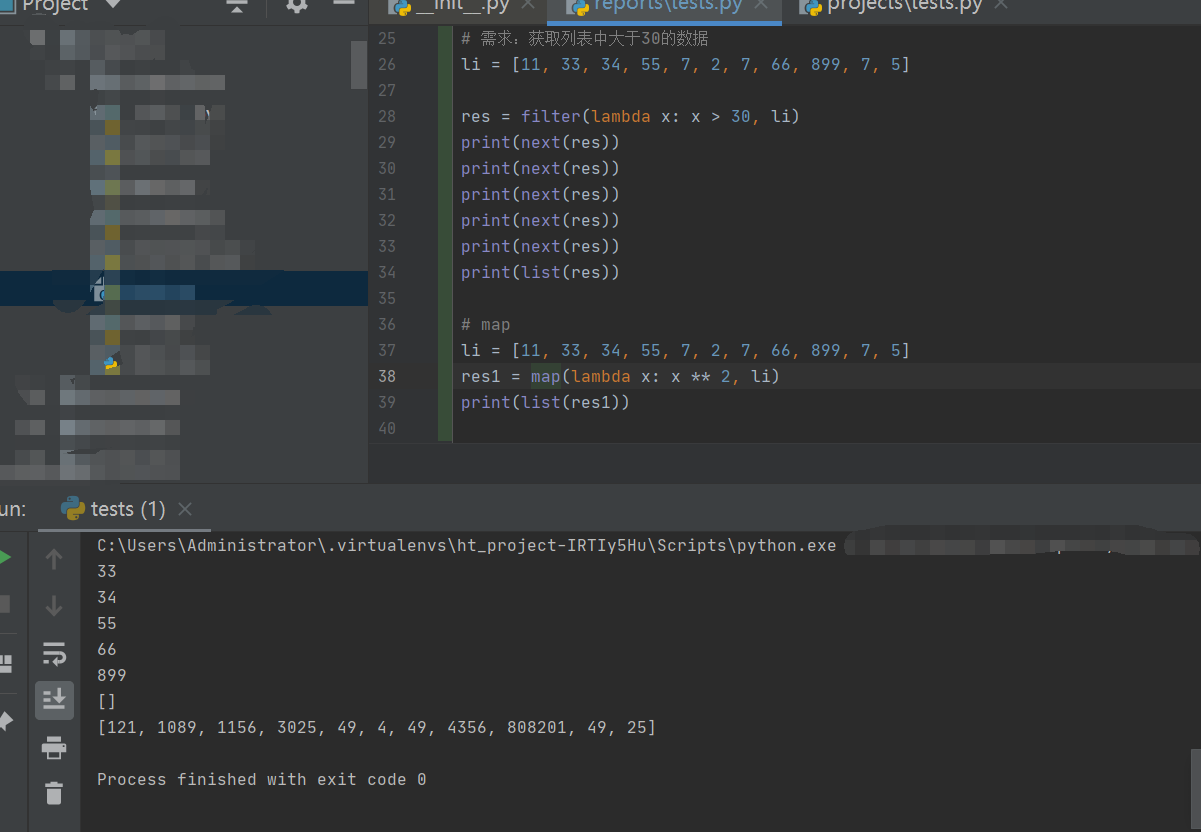
二。内置函数结合匿名函数的使用(filter、map):
# 需求:获取列表中大于30的数据
li = [11, 33, 34, 55, 7, 2, 7, 66, 899, 7, 5]
res = filter(lambda x: x > 30, li)
print(next(res))
print(next(res))
print(next(res))
print(next(res))
print(next(res))
print(list(res))
# map
li = [11, 33, 34, 55, 7, 2, 7, 66, 899, 7, 5]
res1 = map(lambda x: x ** 2, li)
print(list(res1))
三、内置函数(exec、all、any、zip):
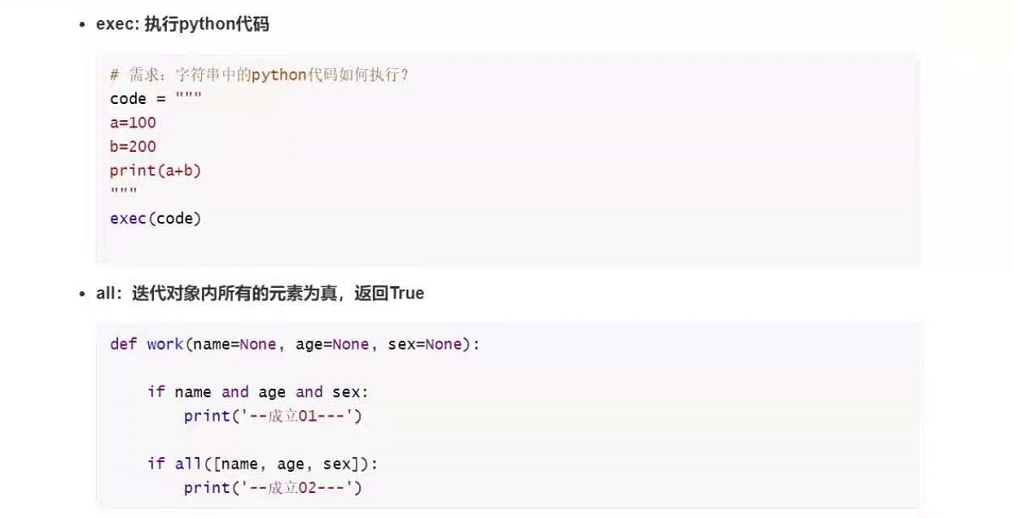
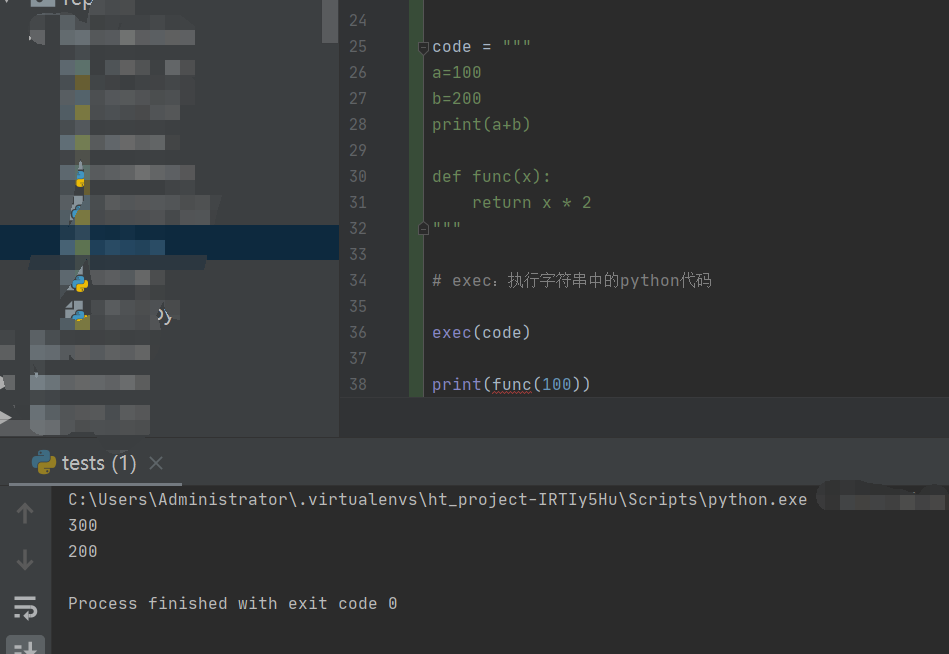
1)exec:
code = """
a=100
b=200
print(a+b)
def func(x):
return x * 2
"""
# exec:执行字符串中的python代码
exec(code)
print(func(100))
2)all:
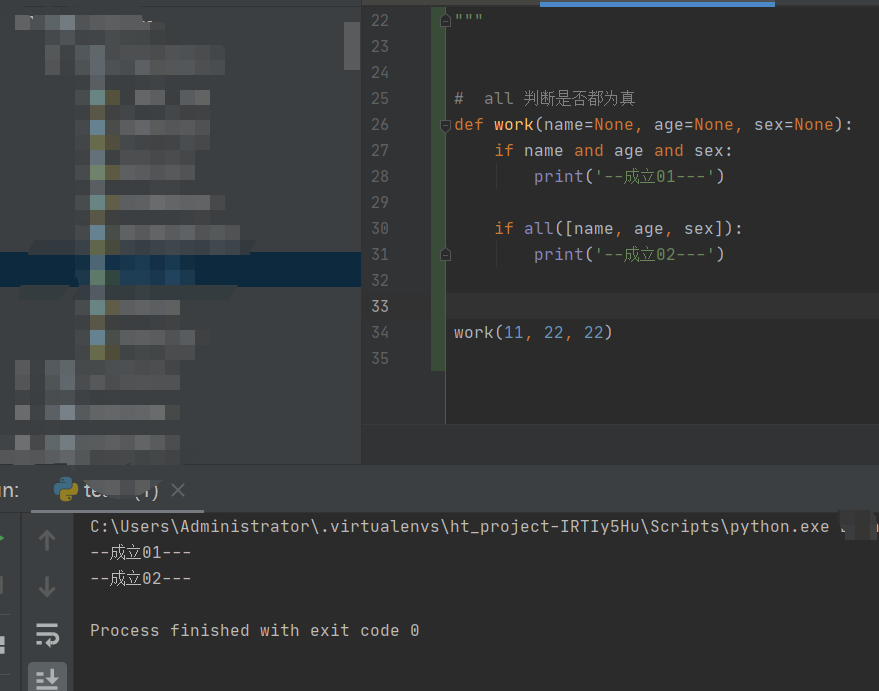
# all 判断是否都为真
def work(name=None, age=None, sex=None):
if name and age and sex:
print('--成立01---')
if all([name, age, sex]):
print('--成立02---')
work(11, 22, 22)
3)any:
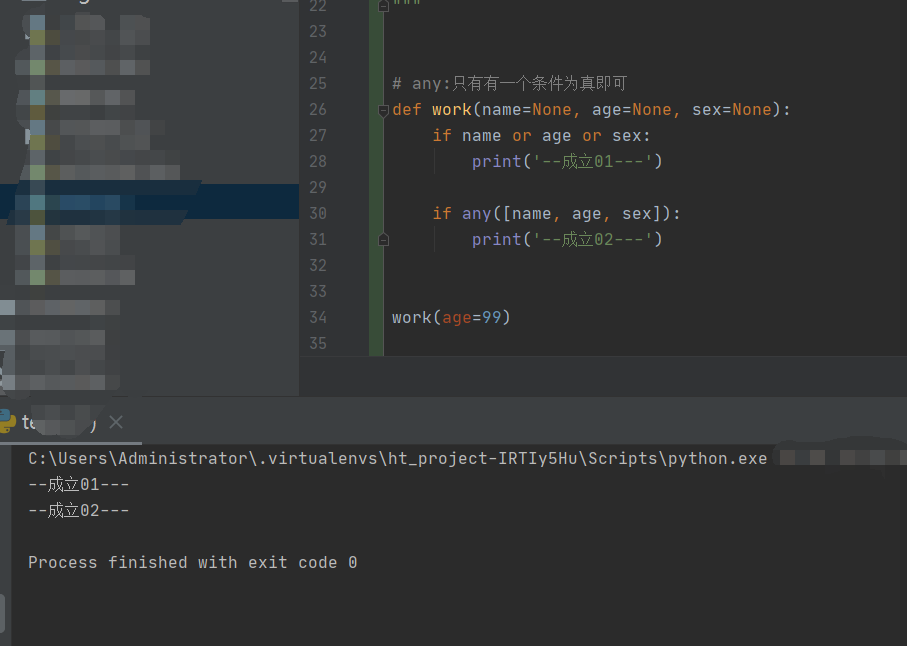
# any:只有有一个条件为真即可
def work(name=None, age=None, sex=None):
if name or age or sex:
print('--成立01---')
if any([name, age, sex]):
print('--成立02---')
work(age=99)
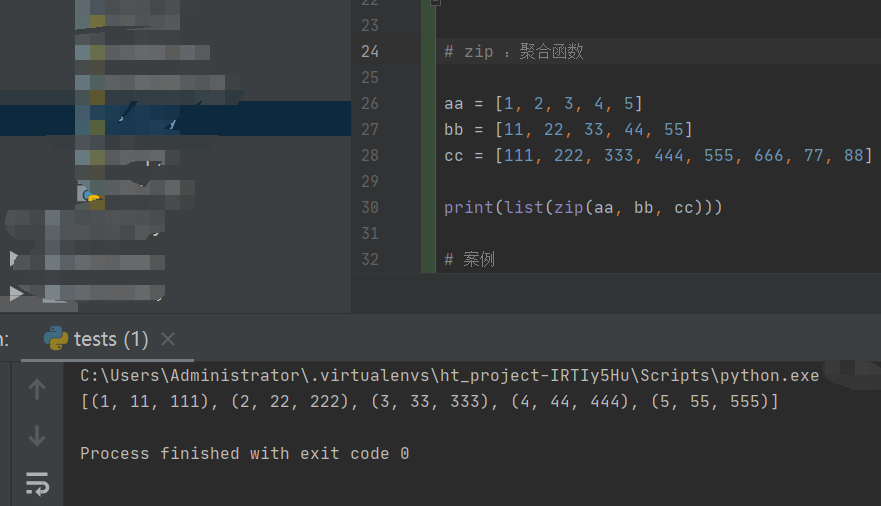
4)zip:
方式一:两组数据聚合
# zip :聚合函数
title = ['a', 'b', 'c']
value = [11, 22, 33]
# 正常实现
dic = {}
for i in range(len(title)):
dic[title[i]] = value[i]
print(dic)
# zip 实现
print(dict(zip(title, value)))
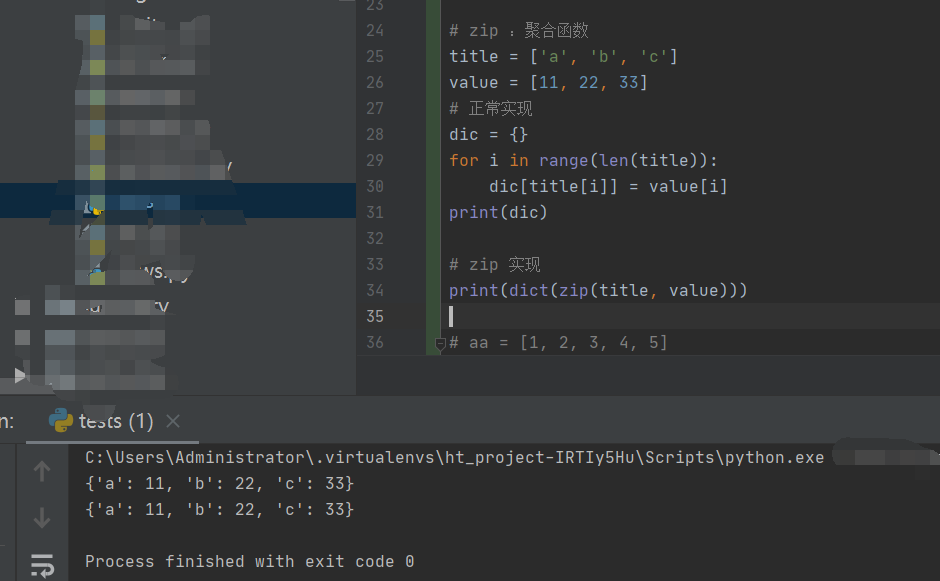
方式二:多组数剧聚合,以最短的数据长度为准
aa = [1, 2, 3, 4, 5]
bb = [11, 22, 33, 44, 55]
cc = [111, 222, 333, 444, 555, 666, 77, 88]
print(list(zip(aa, bb, cc)))
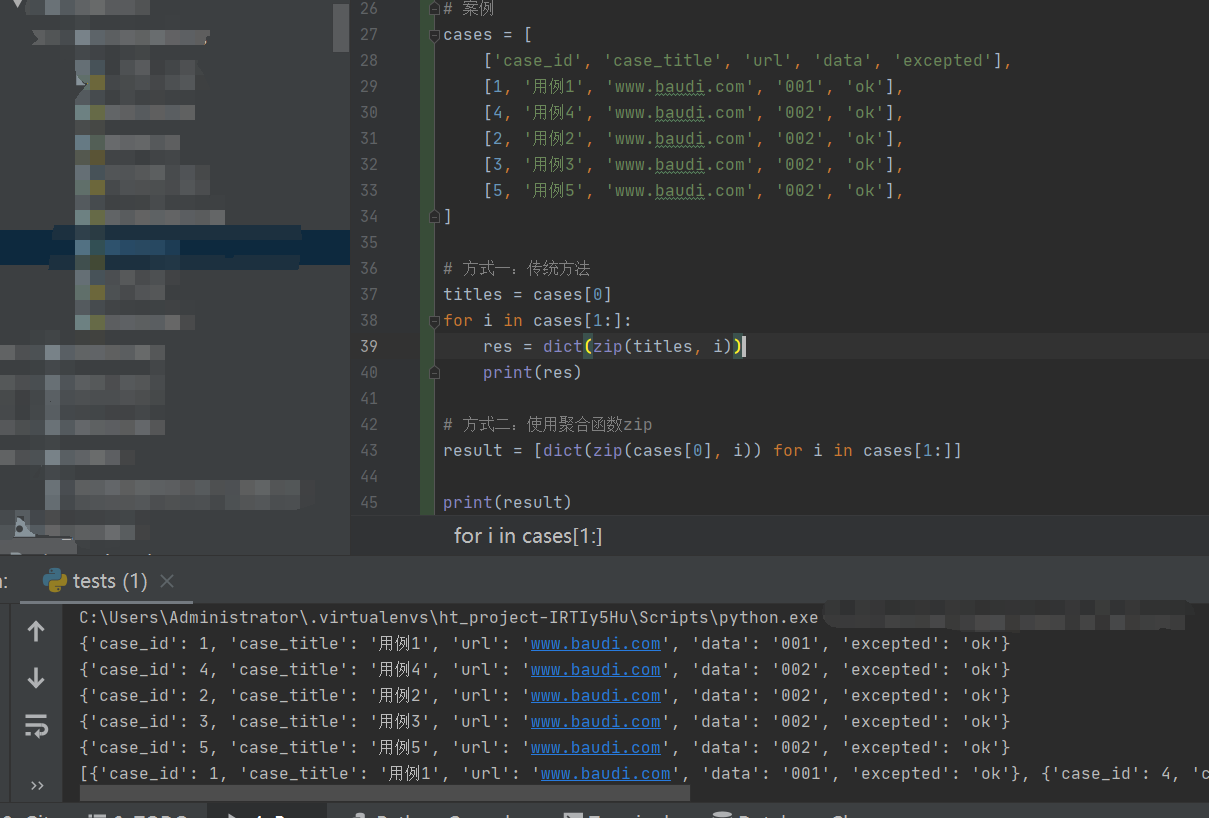
案例:把数据第一行作为标题,以后的行作为数据,把标题和数据以字典的形式对应起来
# 案例
cases = [
['case_id', 'case_title', 'url', 'data', 'excepted'],
[1, '用例1', 'www.baudi.com', '001', 'ok'],
[4, '用例4', 'www.baudi.com', '002', 'ok'],
[2, '用例2', 'www.baudi.com', '002', 'ok'],
[3, '用例3', 'www.baudi.com', '002', 'ok'],
[5, '用例5', 'www.baudi.com', '002', 'ok'],
]
# 方式一:传统方法
titles = cases[0]
for i in cases[1:]:
res = dict(zip(titles, i))
print(res)
# 方式二:使用聚合函数zip
result = [dict(zip(cases[0], i)) for i in cases[1:]]
print(result)
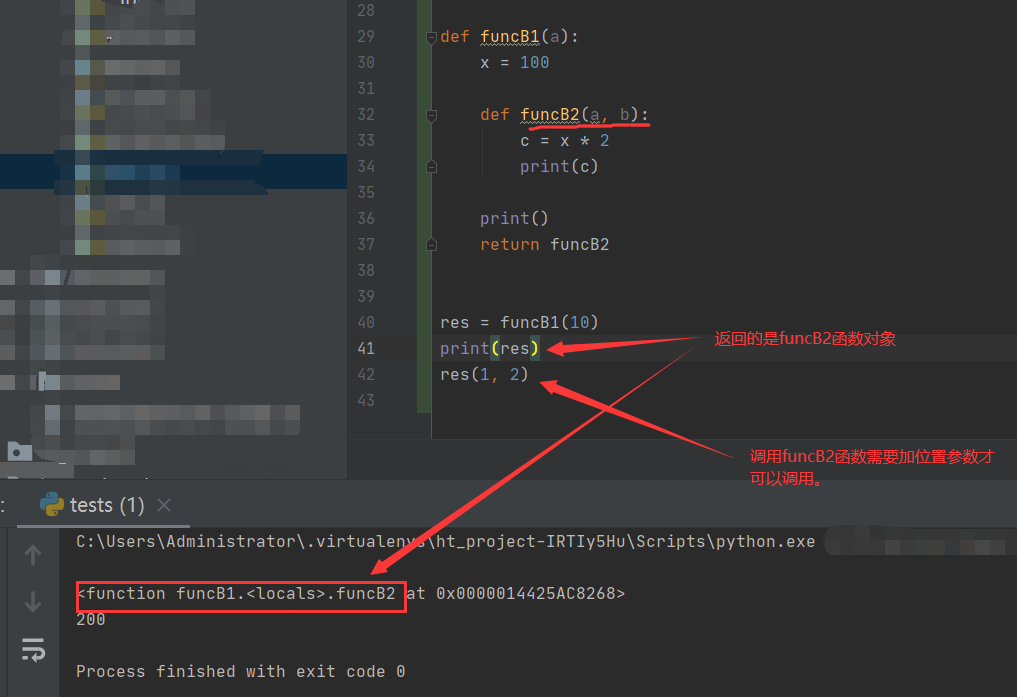
四:闭包函数
def funcB1(a):
x = 100
def funcB2(a, b):
c = x * 2
print(c)
print()
return funcB2
res = funcB1(10)
print(res)
res(1, 2)
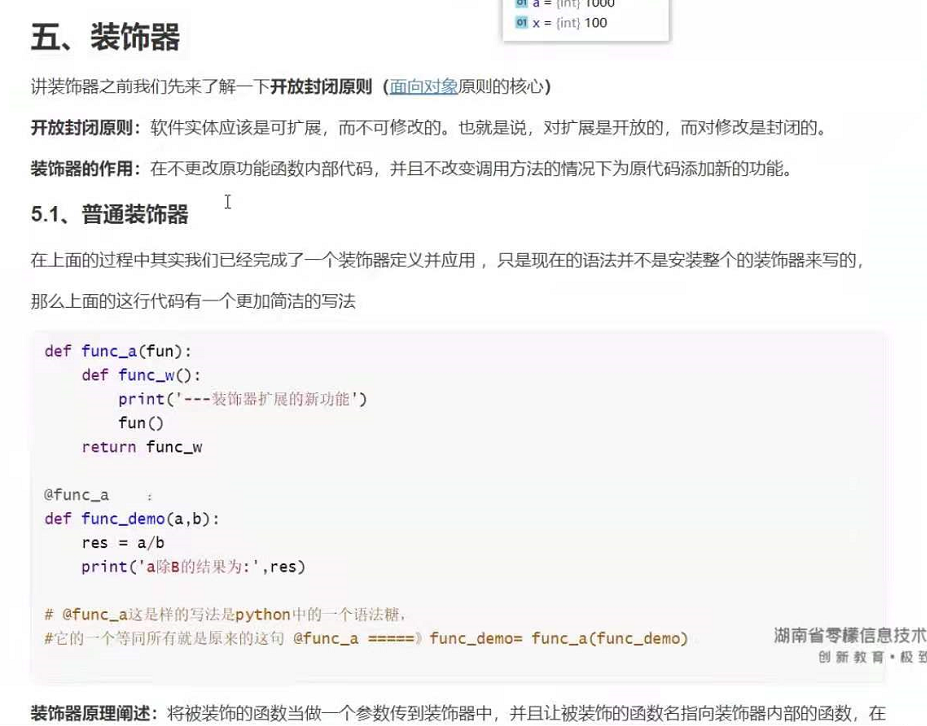
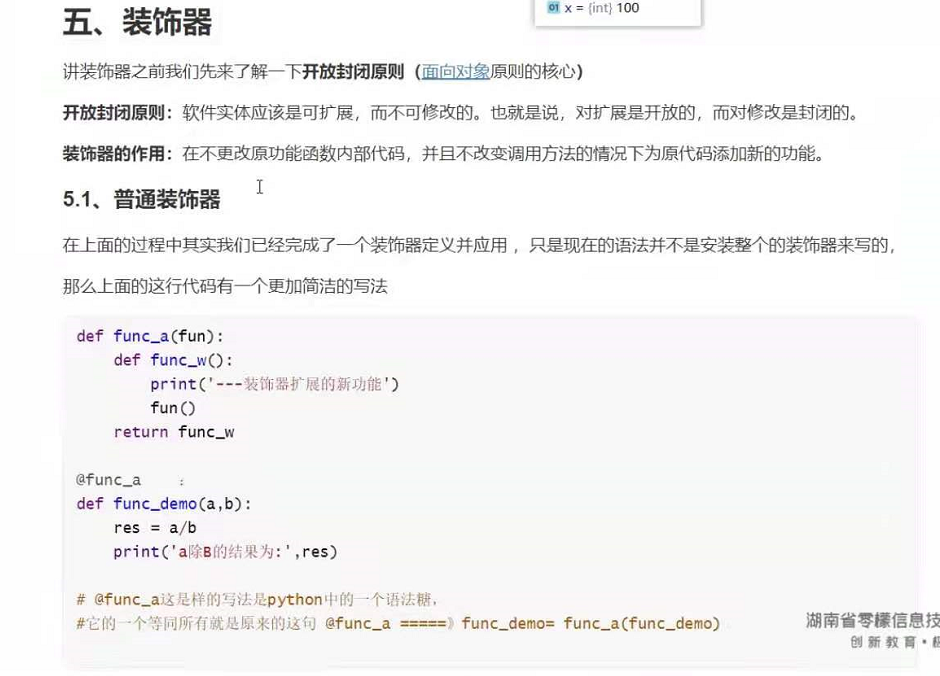
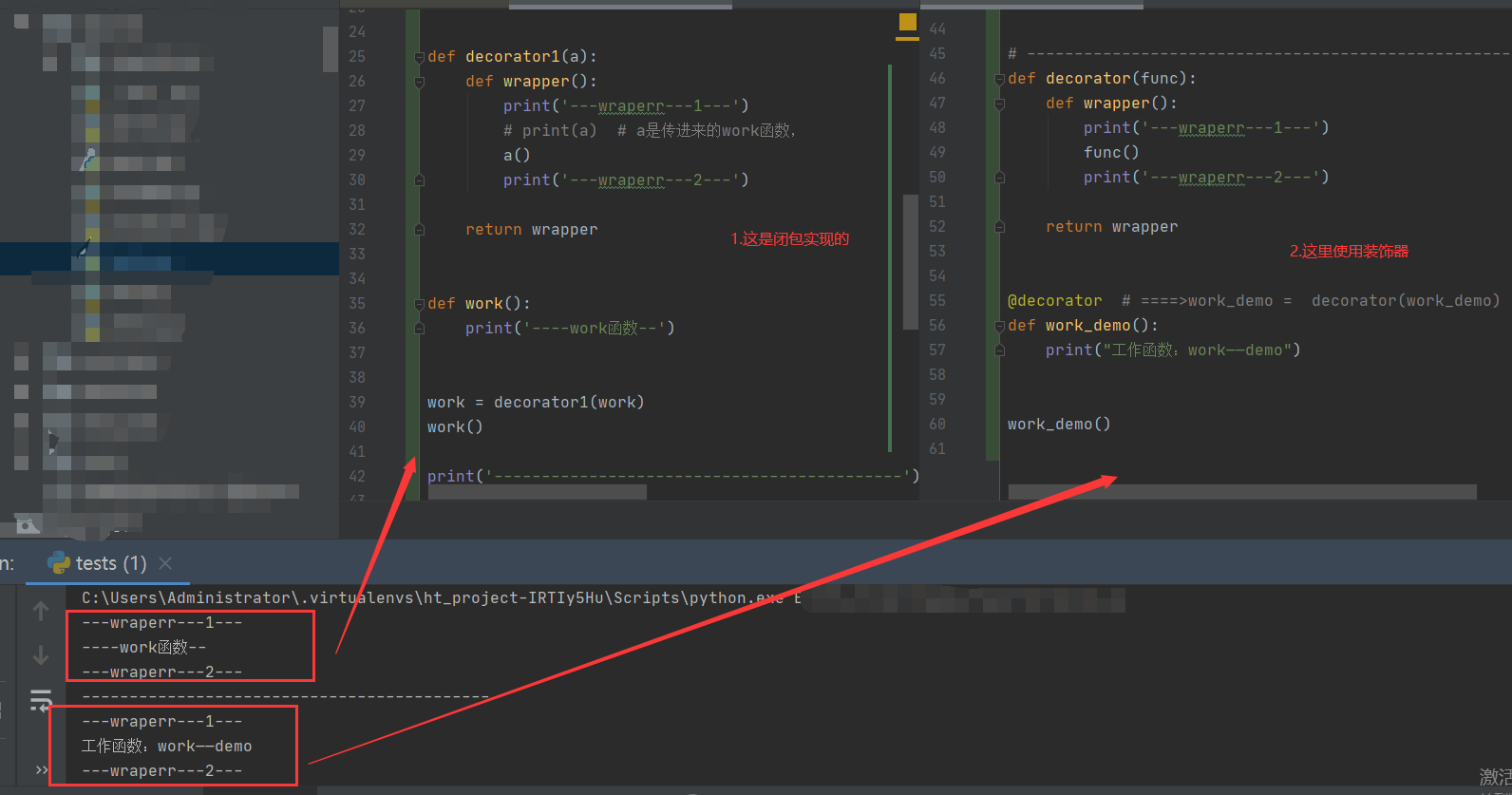
五。装饰器:
def decorator1(a):
def wrapper():
print('---wraperr---1---')
# print(a) # a是传进来的work函数,
a()
print('---wraperr---2---')
return wrapper
def work():
print('----work函数--')
work = decorator1(work)
work()
print('-------------------------------------------')
# ---------------------------------------------------
def decorator(func):
def wrapper():
print('---wraperr---1---')
func()
print('---wraperr---2---')
return wrapper
@decorator # ====>work_demo = decorator(work_demo)
def work_demo():
print("工作函数:work——demo")
work_demo()
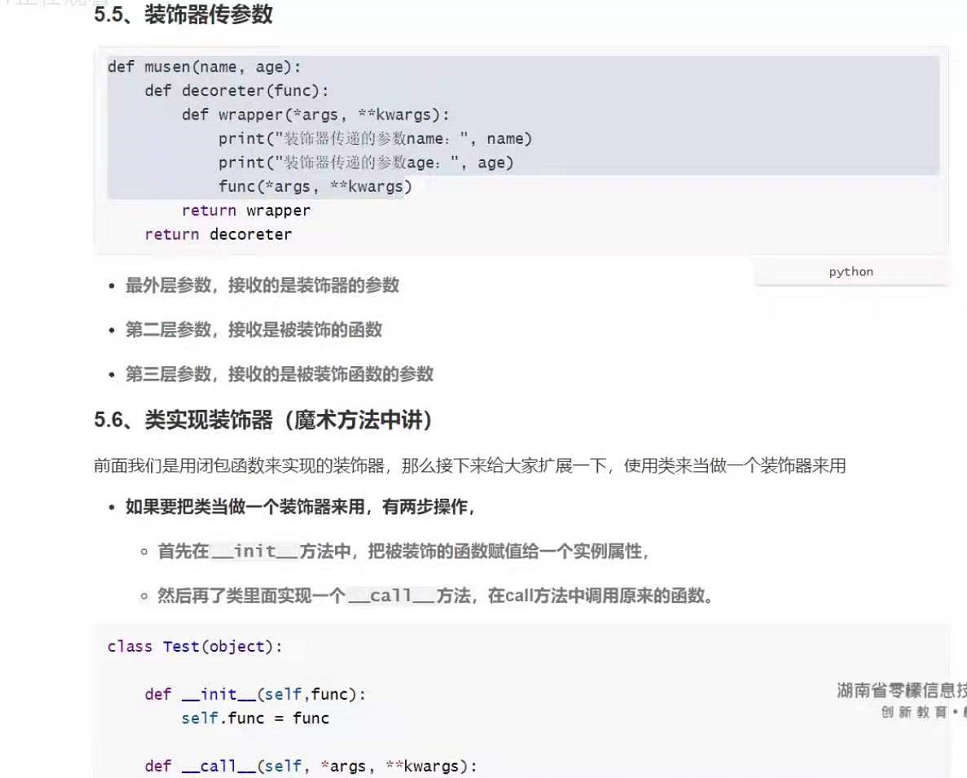
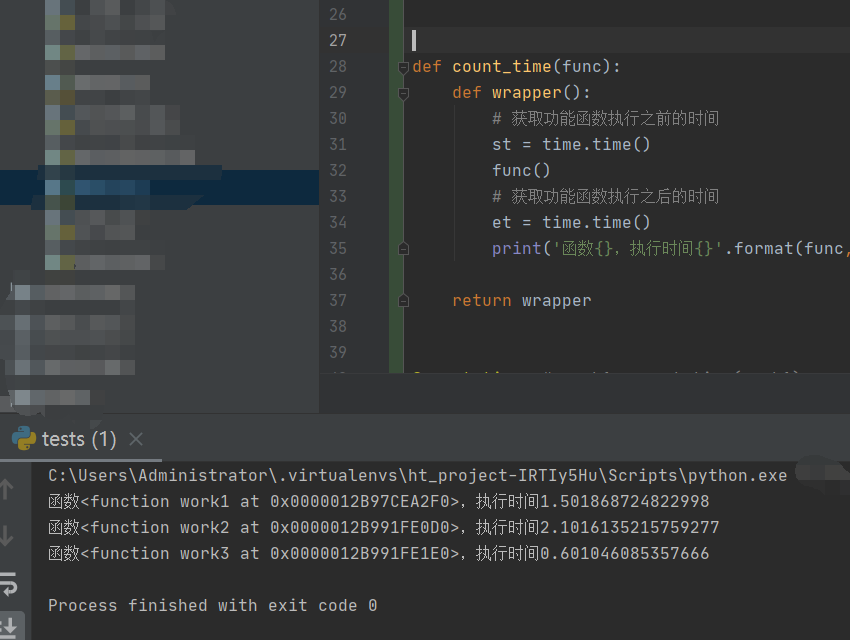
六:装饰器的应用:
# 需求:使用装饰器来统计函数运行的时间
import time
def count_time(func):
def wrapper():
# 获取功能函数执行之前的时间
st = time.time()
func()
# 获取功能函数执行之后的时间
et = time.time()
print('函数{},执行时间{}'.format(func, et - st))
return wrapper
@count_time # work1 =count_time(work1)
def work1():
for i in range(3):
time.sleep(0.5)
@count_time # c = count_time(work3)
def work2():
for i in range(3):
time.sleep(0.7)
@count_time
def work3(): # work3 = count_time(work3)
for i in range(3):
time.sleep(0.2)
work1()
work2()
work3()
联系题目:

"""
1、通过上述上课所学内置函数和推导式的语法,读取附件中excel文件,转换为如下的格式:
res1 = [ {'case_id': 1, 'case_title': '用例1', 'url': 'www.baudi.com', 'data': '001', 'excepted': 'ok'},
{'case_id': 4, 'case_title': '用例4', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 2, 'case_title': '用例2', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 3, 'case_title': '用例3', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 5, 'case_title': '用例5', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'} ]
2、对第一题读取出来的数据,安装case_id字段进行排序。
3、将读取出来的数据中的method字段值 统一修改为GET(不需要修改excel,只对读出来的数据进行修改)
"""
参考答案:
""" 1、通过上述上课所学内置函数和推导式的语法,读取附件中excel文件,转换为如下的格式: res1 = [ {'case_id': 1, 'case_title': '用例1', 'url': 'www.baudi.com', 'data': '001', 'excepted': 'ok'}, {'case_id': 4, 'case_title': '用例4', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'}, {'case_id': 2, 'case_title': '用例2', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'}, {'case_id': 3, 'case_title': '用例3', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'}, {'case_id': 5, 'case_title': '用例5', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'} ] 2、对第一题读取出来的数据,按case_id字段进行排序。 3、将读取出来的数据中的method字段值 统一修改为GET(不需要修改excel,只对读出来的数据进行修改) """ import openpyxl print('-----------------------------第一题-------------------------------------') # 方式一:常规语法 # # # 加载excel文件,选取login表单 # sh = openpyxl.load_workbook('data.xlsx')['login'] # # 按行获取所有的数据 # rows = sh.rows # # 获取表头 # title = [i.value for i in next(rows)] # result1 = [] # for item in rows: # values = [i.value for i in item] # data = dict(zip(title, values)) # result1.append(data) # print(result1) # 方式二: # rows = openpyxl.load_workbook('data.xlsx')['login'].rows # title = [i.value for i in next(rows)] # result1 = [dict(zip(title, [i.value for i in item])) for item in rows] # print(result1) # 方式三: # rows = list(openpyxl.load_workbook('data.xlsx')['login'].rows) # result1 = [dict(zip([i.value for i in rows[0]], [i.value for i in item])) for item in rows[1:]] # print(result1) # 方式四: rows = list(openpyxl.load_workbook('data.xlsx')['login'].rows) result1 = [dict(zip(map(lambda x: x.value, rows[0]), map(lambda x: x.value, item))) for item in rows[1:]] print(result1) print('-----------------------------第二题-------------------------------------') result1.sort(key=lambda x: x['case_id']) print(result1) print('-----------------------------第三题--------------------------------------') # 方式一: 常规语法 # for item in result1: # item['method'] = 'GET' # print(result1) # 方式二:修改原数据 # map(lambda x: exec("x['method'] = 'GET'"), result1) # print(result1) # 方式三:修改原数据 # map(lambda x: x.update({"method": "GET"}), result1) # print(result1) # 方式四: 修改之后,返回一个新的列表 # result3 = [item.update({"method": "GET"}) or item for item in result1] # print(result3) # -------------------------------------------通过装饰器实现(扩展)------------------------------------------- def work2_sort(func): """第二题:通过装饰器对读取出来的数据按照case_id排序""" def wrapper(): result = func() # 对读取出来的数据排序 result.sort(key=lambda x: x['case_id']) # 返回数据 return result return wrapper def work3_update(func): """第三题:通过装饰器修改method字段的值""" def wrapper(): result = func() # 修改method字段的值 for item in result: item['method'] = 'GET' # 返回数据 return result return wrapper # @work2_sort # @work3_update def work1(): """第一题""" rows = openpyxl.load_workbook('data.xlsx')['login'].rows title = [i.value for i in next(rows)] return [dict(zip(title, [i.value for i in item])) for item in rows] if __name__ == '__main__': print(work1())
爱折腾的小测试
